Redis进阶学习
什么是Redis?
Redis是一个key-value结构的非关系型数据库,将数据存储在内存中,结构简单(五种数据结构:string、list、set、zset、hash),数据读写速度快,还可以将数据持久化到硬盘上。
先来了解Redis的使用场景
1、作为缓存
2、计数器,如:点赞功能
3、排行榜,zset可以排序
4、数据排重,set不能存储重复数据
5、消息队列,list先进先出,先进后厨
6、分布式锁共享数据
以上场景是我们常见的使用场景,不单单只有这几个场景。
Redis线程模型
redis6.x之前是真正意义上的单线程,对外提供的键值存储服务的主要流程是单线程。也就是网络IO和数据读写是单个线程来完成的。
redis6.x引入的多线程是指的是网络请求过程采用多线程,而键值对的读写命令仍然是单线程处理的,所以redis依然是并发安全的。
为什么设计为单线程模型读取速度也很快?
1、操作都是在内存中的。redis中存储的数据都是存储在内存中的,所以所有的运算都是内存级别的,因此性能非常长高。
2、底层是一个哈希表,可以通过key的哈希值快速定位到存储的位置。hash可以在O(1)的时间内计算出哈希值,找到对象entry,entry里是一个个key指针和value指针,还有其他信息。这也是redis性能高的原因之一。
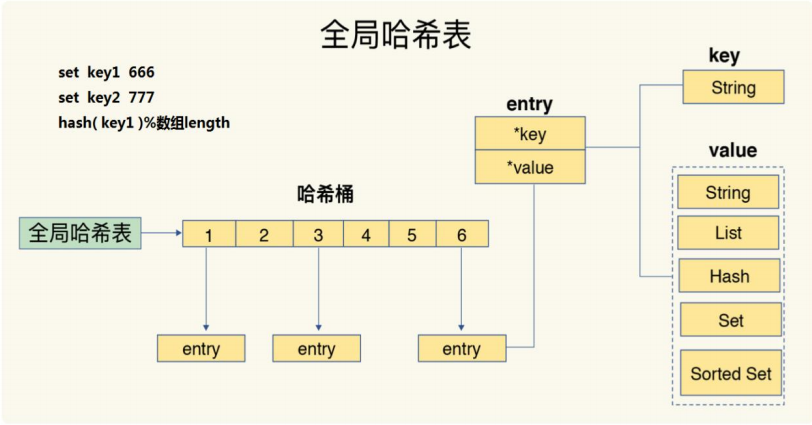
3、由于是单线程模型,所以不存在上下文切换的,节省了线程切换的开销。而且单线不会导致死锁的问题发生。
redis持久性
将内存中的数据可以持久化的保存到硬盘上。
redis持久化的两种机制:RDB(redis database)和AOF(append only file)
1、RDB
一快照的形式将数据存储到rdb文件中(加入redis中存储10个key-value,是把10个k-v存储到rdb文件中,服务下次启动时,可以将rdb文件数据进行恢复)。
rdb方式是redis默认使用的持久化机制,在redis.conf文件中可以配置触发持久化的规则
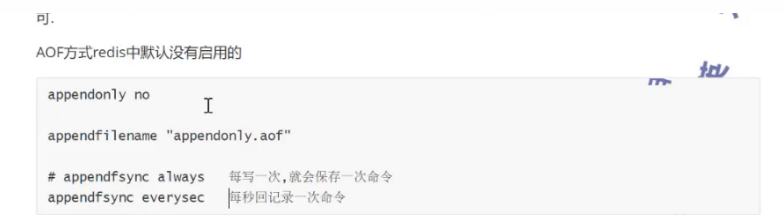
2、AOF:
以日志的形式记录写操作命令,不断的在日志文件中追加内容,只需要执行日志文件即可,默认是没有使用的
Redis事务
redis中的事务相对来说是比较简单的
,主要是为了让我们能够实现一次操作的多条命令能够作为一个整体执行,执行中间不被其他命令执行,就需要开启事务
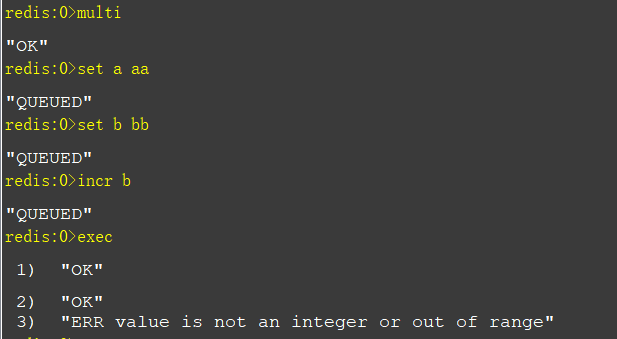
multi 命令事务开启(只是命令组队,并不执行命令)
命令1
命令2
....
exec 命令,才会执行事务中的多条命令
但是不保证命令执行的原子性,多条命令中,如果某条命令执行失败了,执行成功的命令仍然是有效的
Key过期策略
key可以设置一个过期的时间,时间到了redis会自动销毁key。
自动销毁策略:
1、定时删除
在设置键的过期时间,同时创建一个定时器(timer),让定时器,在键的过期时间来临时,立即执行对键的删除操作。
优点:键过期时会立即删除,内存及时释放。
缺点:在过期键比较多的情况下,删除键会占用大量的cpu,影响redis的性能
2、惰性删除
key会维护一个状态,当过期时,不会立即删除过期key,会在下次访问时,发现过期的key,此时才会删除过期key。
好处:不需要及时的扫描跟踪,对cpu友好,只有访问键的时候才会检查是否过期,不会额外消耗cpu。
缺点:会浪费一定的内存空间,大量过期键不被访问,它们会一直占用内存。
3、定期删除
定期扫秒redis中过期的key,需要消耗一定的资源。
好处:是定时删除和惰性删除的折中,既可以避免消耗定时删除策略对cpu的过多占用,也可以避免惰性删除策略对内存的过度浪费。
缺点:要制定合理的删除操作的执行频率和执行时长,如果设置不合理,可能会退化为定时删除策略或者惰性删除策略。
redis和mysql如何保持数据一致性?
三种方式:
1、先更新mysql数据,然后再更新redis,在实际开发中,有可能更新redis时出现问题,导致redis数据没有更新,用户继续还是从redis中查询数据,查询到的还是旧数据。
2、先删除redis中的数据,然后再更新mysql数据,虽然可以解决方式1问题,但是也是可能出现问题,线程1删除了redis数据,正在更新mysql,此时线程2查询数据,那么就会再次把mysql中的旧数据又查到redis中。
3、延时双删,更新前先删除redis数据,然后更新mysql,更新后再次删除redis中的数据。
redis缓存问题
1、缓存穿透
key对应的数据在数据库中并不存在,每次查询时redis中没有此数据,还是要去mysql中查询,从而可能会击垮数据库。
解决方案:
1、可以在redis设置一对为key-null,下次再请求的时候,就可以缓存里边获取值为null。这种情况我们一般会将空对象设置一个较短的过期时间。
2、对参数进行校验不合法参数进行拦截。例如 id=1,数据库中压根就没有这样的值,先进性验证。
3、使用布隆过滤器
布隆过滤器就是一个数组,里面默认存储的都是0,主要用来判断某个元素是否存在,我们可以把数据向布隆过滤器中冗余的进行存放,把一个值用多个哈希函数进行计算,算出多个位置,将对应位置的值改为1。
判断一个元素是否存在时,只需要通过哈希函数算出位置,如果位置上都是1,则元素有可能存储,如果某个位置上的位置为0,那么该元素一定不存在。
2、缓存击穿
某个key对应的数据库中是存在的,某个一个时间节点上key刚好过期了,此时有大量的请求同时到达,都去mysql查询了,就会有可能击垮mysql。
解决方案;
1、热点数据key设置较长时间
2、为查询mysql的方法加锁,让线程一个一个的去查询数据库。
3、缓存雪崩
大量的key过期或者redis服务出现问题,大量的请求访问到mysql
解决方案:
1、随机设置key失效时间,避免大量的key集体失效。
2、集群,部署多台redis,主从结构,一台宕机,其他服务还可以正常使用
3、跑定时任务,当key快失效时,更新失效时间