机器学习 Day13 Boosting集成学习方法: Adaboosting和GBDT
大多数优化算法可以分解为三个主要部分:
-
模型函数:如何组合特征进行预测(如线性加法)
-
损失函数:衡量预测与真实值的差距(如交叉熵、平方损失)
-
优化方法:如何最小化损失函数(如梯度下降、前向分步)
我们来学习一下这些部分,以此作为基础去进一步理解要讲的优化算法。我们这节要讲的优化算法要套用这三个模版。以后的所有的算法都逃不过这三大步骤
1.模型函数,我们这里已经学过逻辑回归,决策树,一会还有要讲的集成学习模型。

2.损失函数 ,损失函数(Loss Function)是机器学习的核心组件,它量化了模型预测与真实值之间的差异(就是第一部分和真实值的差距),为模型优化提供方向,以后去使用优化方法去不断优化这个函数(第三节介绍)

还有其他损失函数,具体我们可以设置任何损失函数。我们看我们了解过的算法的损失函数:
2.1决策树的损失函数:

我们构造决策树的时候要最优化以上的损失函数,因为这个损失函数很简单,我们只需要去遍历特征就可以得到最优的取值参数(分割点),所以并未涉及到算法。
2.2逻辑回归

3.优化方法(运筹里讲了很多,这里我们只介绍基于参数的梯度下降法,和基于函数的分布向前算法)
核心目标在于找到参数空间使得最小化损失函数。

算法流程:


梯度下降法前面优化逻辑回归的损失函数的时候讲过,它有很多变式,
分布向前下降,就是一步一步去优化损失,比如说当损失是MSE的时候,我每次去求一个基学习器让MSE最小,然后再去优化这个加法模型的参数,这个参数就是相当于学习率,基学习器相当于我们的方向(比如在以下的算法中是损失函数负梯度方向,而MSE的负梯度就是残差,所以让基学习器去拟合残差了。),这样一步一步的去求得一个最优的,分布向前算法就好像一个大的框架,你可以任意给定损失函数,然后每一步都去固定上一个最优的基学习器,去寻找当前步的最优参数和模型。
其实向前分布算法更像是一个框架,提供一种思路,其中具体如何优化损失函数会产生许多算法。

4. 提升树其实就是向前分布算法的一种实现特例,它要求学习器是一个决策树,并且权重一般都是1,而且损失函数一般对于回归问题是平方误差损失函数,对于分类问题,如果是二分类使用指数损失,对于多分类问题使用交叉熵,一般问题可以定义损失函数。
提升树也是一个框架,具体损失函数不同,对应算法不同。

5.Boosting集成学习
Boosting 是一种集成学习技术,通过组合多个弱学习器来构建一个强学习器(本节讲的是加法模型),以提高模型的预测性能。以下从原理、常见算法、应用场景等方面对其进行介绍:
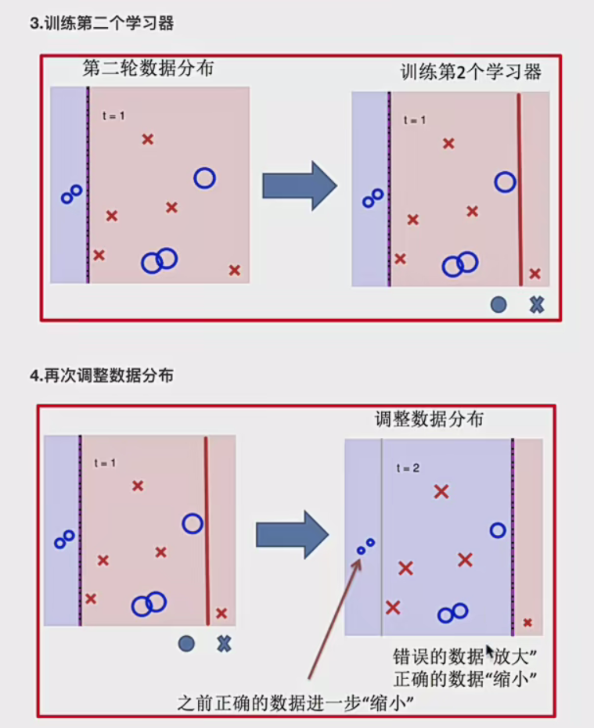
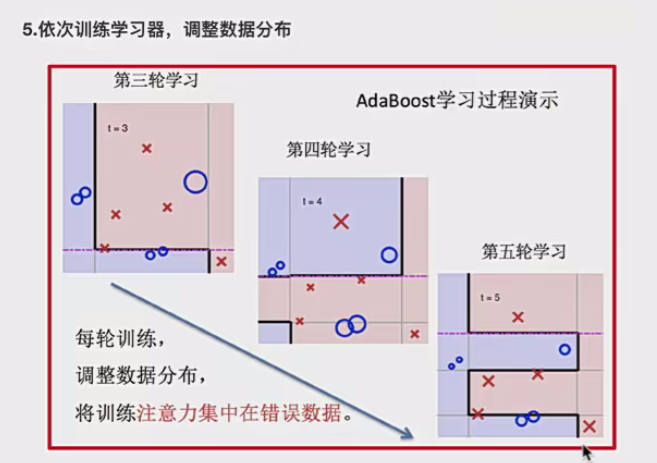
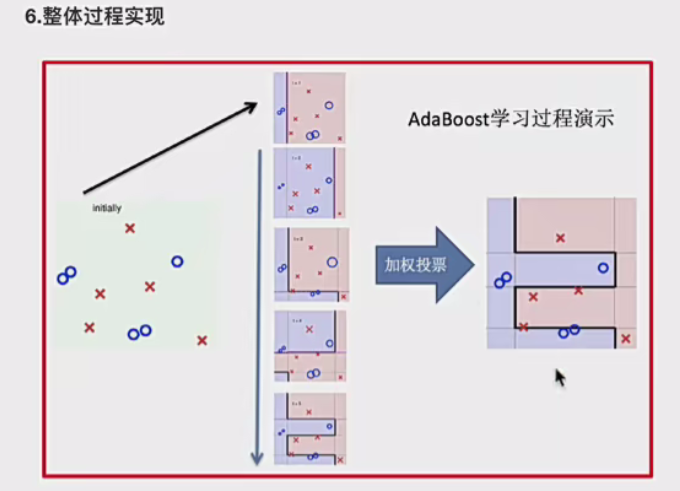
Boosting 的核心思想是迭代地训练一系列弱学习器,每个弱学习器都在上一个弱学习器的基础上进行改进。具体来说,在训练过程中,会为每个训练样本赋予一个权重,初始时所有样本的权重通常是相等的。然后,依次训练各个弱学习器,对于每个弱学习器,它会根据当前样本的权重分布来进行学习,更关注那些被之前的弱学习器错误分类的样本,即增加这些错误样本的权重,降低正确分类样本的权重。这样,后续的弱学习器就会更加注重纠正前面弱学习器的错误,从而逐步提升整个模型的性能。最后,将这些弱学习器按照一定的方式进行组合,通常是通过加权投票(分类问题)或加权平均(回归问题)等方法,得到最终的强学习器。
所以Boosting技术中最重要的是两个:如何提高错误数据的圈子,并且降低正确数据的权重;如何计算每个学习器的占比权重

 Bagging和Boosting的区别
Bagging和Boosting的区别
6.Adaboosting算法(解决二分类问题)
有了以上基础,其实一句话就能说清楚Adaboosting算法是什么玩意:其实就是以线性加法为目标函数,以指数损失为损失函数,以向前分布算法为优化方法的一类算法。(如果我们要求基学习器是树的话,其实就是提升树的特殊情况了,但经典AdaBoost的基学习器一般是弱分类器(如决策树桩、单层决策树),而非任意树),我们先将他的流程,再将它的原理,再讲它是如何做到Boosting的(即如何体现重要的两个点)。

手写所有步骤:



 至此我们手写了该算法的构造原理,其中设计到许多求和号的转变。
至此我们手写了该算法的构造原理,其中设计到许多求和号的转变。
6.3如何体现Boosting集成思想
首先,利用指数损失作为概率,很完美的实现了数据集的重新赋值。
其次,我们使用错误率构造了权重公式,显然,公式是一个减函数,即错误率越高权重越小
以上两点就是说明了Adaboosting算法的归属问题。
7.我们来看一些提升树的案例,以此引出GBDT(梯度下降提升树)
7.1二分类问题的提升树
二分类问题的预测函数是权值为1的分类决策树的组合,损失函数是指数损失(只要是指数损失,就可以通过损失来调整样本数据的权重),优化方法是分布向前方法,它相当于Adaboosting算法的特殊情况:就是权重为一并且基学习器是一个二分类树的特殊情况,它的算法流程很简单,就是Adaboosting算法,不需要求权重。
7.2回归问题的提升树

由![]() 知道,只要第m次回归树距离残差越小。损失函数就越小,所以在分布向前算法里,我们只需要去构造每一步的决策树去拟合残差(即使用残差去改变数据的权值)即可得到这一论的基学习器,然后一直循环下去,以下是算法流程:
知道,只要第m次回归树距离残差越小。损失函数就越小,所以在分布向前算法里,我们只需要去构造每一步的决策树去拟合残差(即使用残差去改变数据的权值)即可得到这一论的基学习器,然后一直循环下去,以下是算法流程:

以上两种以指数函数和平方误差为损失函数的很容易去进行优化,那么对于一般回归问题的的损失函数该如何去优化呢,这就是我们要讲的GBDT算法。
8.GBDT算法
接上表述GBDT核心在于提升树的损失函数不同,用于处理通用的损失函数问题,其他就是提升树的本质,那么思想是什么?
首先它的预测函数和回归提升树是一样的。即
他的损失函数是一般的损失函数,我们用L(y,f(x))表示 ,GBDT的核心目标是:确保每增加一个学习器,总损失不会增加,即第m步比第m-1步的总损失不大。所以GBDT本质上去优化的目标函数是: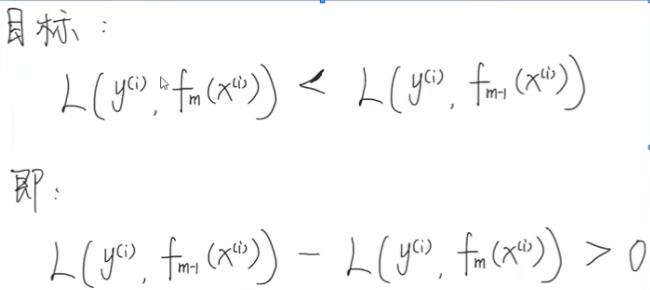
我们进行一系列推导:

所以让我们每一步的回归决策树去拟合损失函数的负梯度即可(即使用负梯度去改变数据的权重值),所以又叫做梯度提升树。

于是有如下算法: 注意这里的初始化函数并不是0,而是先求得一个常数c,c使得总损失最小。(b)步骤就是我们以前讲过的回归决策树的构造,(c)步骤的意思就是在求解第m个决策树第j个节点上的回归值,是通过最小化损失函数计算得到的,观察那个式子,就是我们把在这个节点上的样本回归值都用c表示,c可以是得在这个节点上的总损失最小,那个fm-1(x)+c,就是表示我上一轮的值加上这个c与真实值的损失最小。不是我们之前讲的c是叶子结点的平均了,这个平均我们用于初始化了。
注意这里的初始化函数并不是0,而是先求得一个常数c,c使得总损失最小。(b)步骤就是我们以前讲过的回归决策树的构造,(c)步骤的意思就是在求解第m个决策树第j个节点上的回归值,是通过最小化损失函数计算得到的,观察那个式子,就是我们把在这个节点上的样本回归值都用c表示,c可以是得在这个节点上的总损失最小,那个fm-1(x)+c,就是表示我上一轮的值加上这个c与真实值的损失最小。不是我们之前讲的c是叶子结点的平均了,这个平均我们用于初始化了。
当给定一个数据的时候它的回归结果是这样的:

我们把这个通用的流程带入7.2以MSE为损失函数的提升树里,对应的是拟合该损失函数的负梯度方向,我们计算会发现这个负梯度带入后就是我们的残差。
注意:
GBDT(Gradient Boosting Decision Tree,梯度提升决策树)的基学习器通常是回归决策树,即使是在解决分类问题时也是如此。以下是详细解释:
1. GBDT 的基学习器:回归树
回归问题:
直接使用回归树(CART 回归树)作为基学习器,每个叶结点输出一个连续值(即 cmjcmj),最终预测值是所有树输出的累加。分类问题(就是我之前说的,逻辑回归其实就是回归+激活函数):
二元分类:通过逻辑回归的链接函数(如 sigmoid)将累加结果映射为概率,但每棵树本身仍是回归树,拟合的是对数几率(log-odds)的梯度。
多分类:采用类似逻辑回归的 Softmax 形式,但对每棵树的训练仍基于回归树拟合残差。
核心原因:
梯度提升的每一步需要拟合的是连续值(负梯度/残差),而分类树的离散输出无法直接实现这一点。因此,回归树更通用。
2. 为什么用回归树而非分类树?
梯度提升的本质:
通过加法模型逐步优化损失函数,每一步需要计算损失函数对当前模型的梯度(即伪残差 rmirmi),而梯度是连续值,必须用回归树拟合。灵活性:
回归树可以输出任意连续值(如 cmjcmj),能更精细地调整模型,而分类树只能输出离散类别。统一框架:
回归树可以同时处理回归和分类任务(通过调整损失函数),而分类树无法直接用于回归。GBDT可以用来分类,只要把回归结果转化一下就行,也可以回归问题,但是Adaboosting只能用于二分类问题,它其实就是二分类提升树的一个推广