(cvpr2025) LSNet: See Large, Focus Small

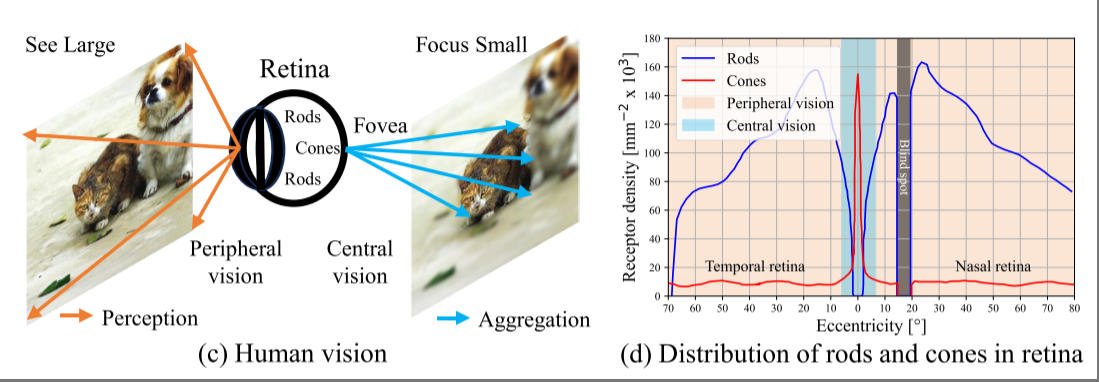
作者指出,人类视觉系统遵循两步机制:(1) 通过周边视觉的大视场感知(See large)捕捉全景。(2) 注意力可以被引导到场景的特定元素上,通过中央视觉的小视野聚集(Focus small)理解细节。这种特征源于视网膜中两种感光细胞的空间分布和视觉能力不同,即视杆细胞和视锥细胞。
这种“See large, focus small”的方法使人类视觉系统能够快速、熟练地处理视觉信息。
受人类视觉感知的启发,作者提出了 Large-Small (LS)卷积,使用大核静态卷积进行 large-field perception,使用小核动态卷积进行 Small-field aggregation。结构如下图(a)所示,包括两个步骤:
- 第一步:Large-kernel perception,结合图示非常容易理解,首先使有和1x1卷积进行通道降维,然后用大核卷积获得大感受野的空间上下文信息,最后两再通道升维。
- 第二步: Small kernel aggregation,本质是分组动态卷积。特征分为G组,每组使用的卷积核是Large-kernel perception生成的。这样可以有效地表示自适应细粒度特征,使模型对不同环境下的动态复杂变化敏感。
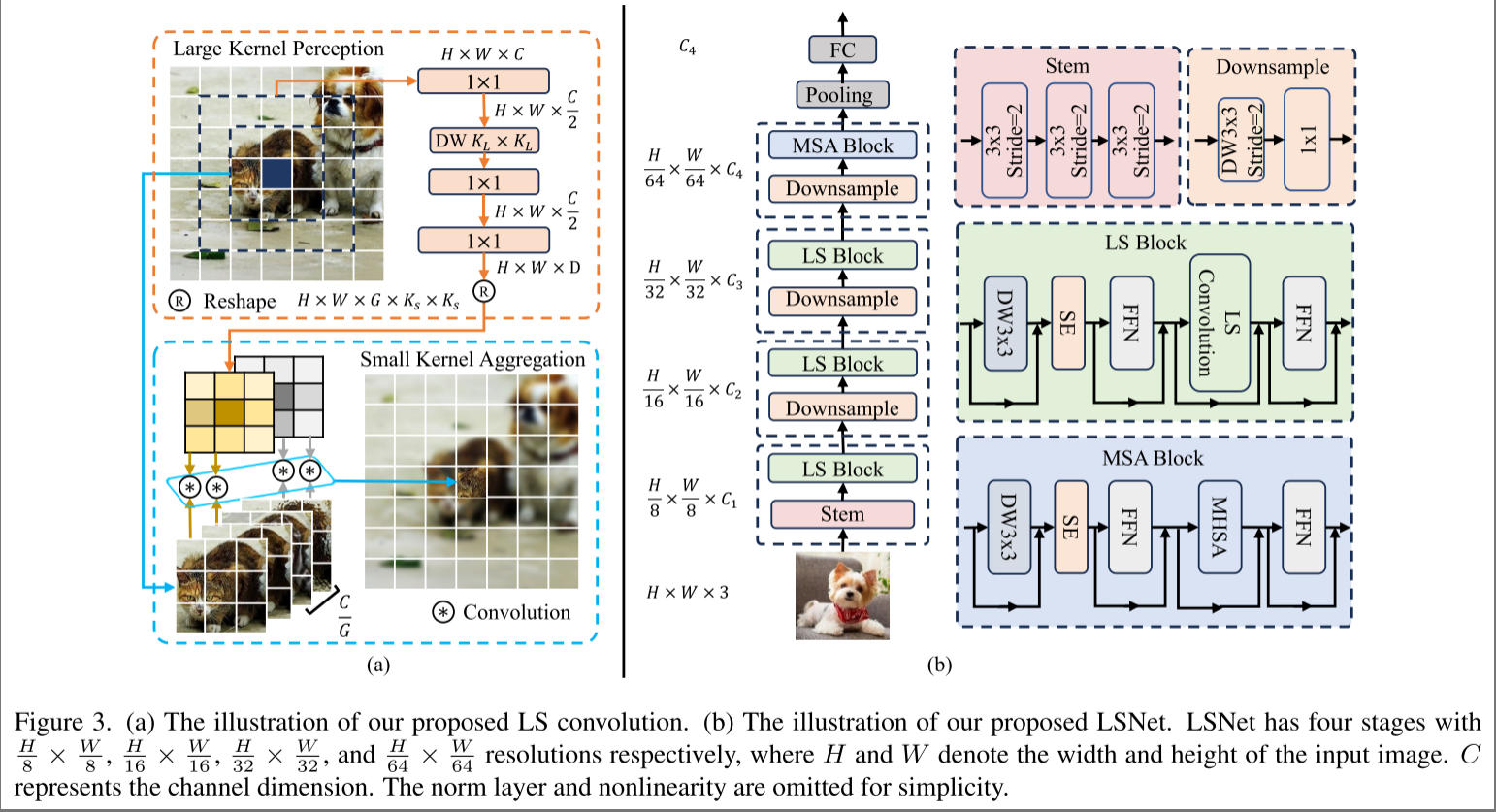
以 LS 卷积为基础,作者构建了轻量网络 LSNet,如上图(b)中所示,结构也比较简单。作者做了大量实验证明 LS 卷积的效果,可以参考作者论文,这里不过多介绍。