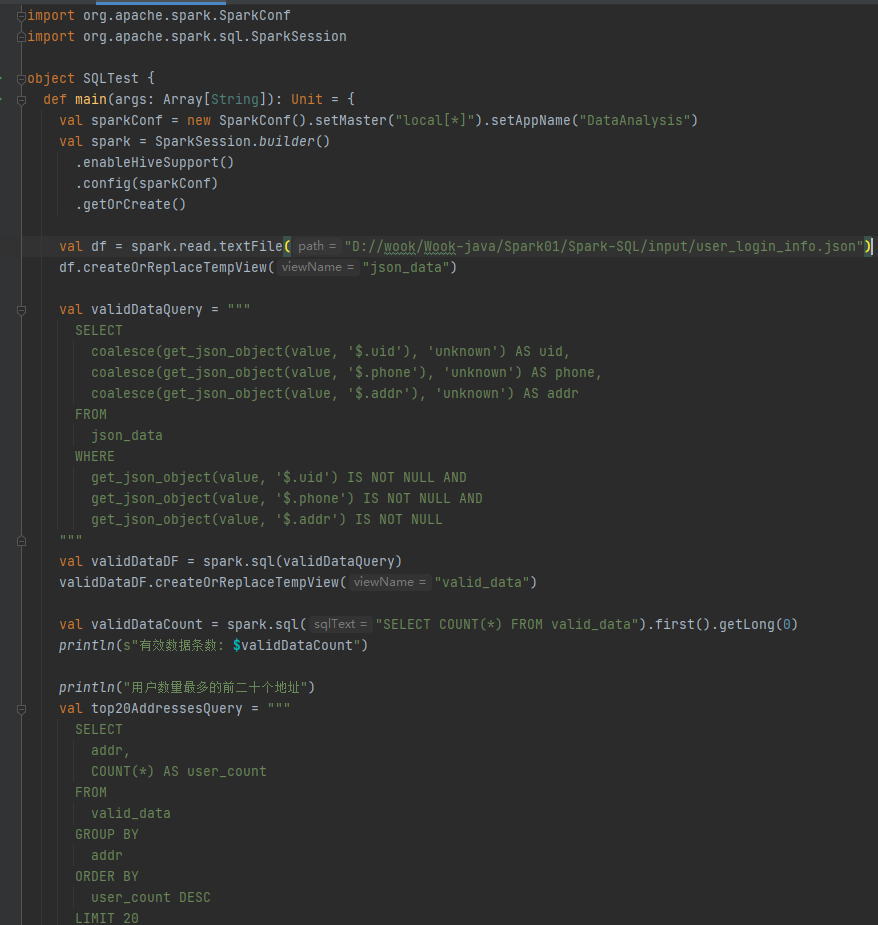
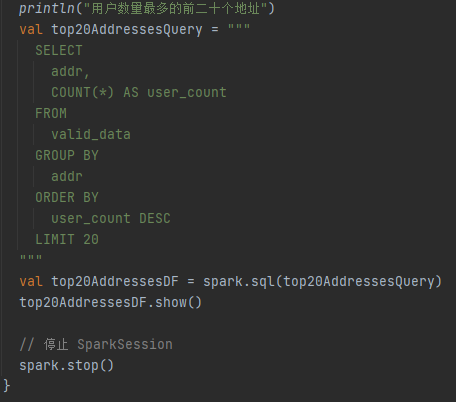
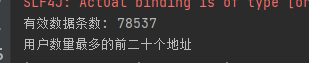
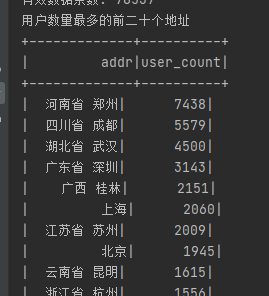
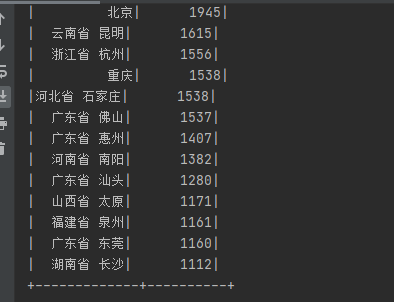
当前位置: 首页 > news >正文 Spark-SQL 四(实验) news 来源:原创 2025/4/22 5:42:22 用idea实验hive的常用代码 将数据放到项目·的目录下 代码实现 运行结果: 实验 统计有效数据条数及用户数量最多的前二十个地址 将数据放到Spark-SQL/input目录下 代码实现: 运行结果: 相关文章: opcua批量读取变量 FlaskRestfulAPI接口的初步认识 Android开发中的复制和粘贴 关于springmvc的404问题的一种猜测解决方案 蓝桥杯 17.发现环 uniapp微信小程序:WIFI设备配网之TCP/UDP开发AP配网 mysql的binlog,redolog,undolog的区别 Linux下 REEF3D及DIVEMesh 源码编译安装及使用 【JavaWeb后端开发03】MySQL入门 无需接线!虚幻引擎变量跨次元绑定的无线电奥秘 转化率提升47%?亚马逊用户行为预测模型深度解读 数据结构中的各种排序 量子计算在金融领域的应用与展望 DeepSeek智能时空数据分析(二):3秒对话式搞定“等时圈”绘制 iOS 中的虚拟内存 (理解为什么需要虚拟内存) npm -v npm : 无法加载文件 C:\Program Files\nodejs\npm.ps1,因为在此系统上禁止运行脚本。来看看永久修改执行策略! 【手机】vivo手机应用声音分离方案 【Spring】深入解析 Spring AOP:切面优先级、切点表达式、自定义注解并实现、Spring AOP 的几种实现方式 Java 设计模式心法之第3篇 - 总纲:三大流派与导航地图 POSIX多线程,解锁高性能编程 全球在役最大火电厂被通报 外媒:罗马教皇方济各去世 经济日报经世言:不断开创中马关系发展新局面 同程旅行:拟24.97亿元收购万达酒管100%股权 圆桌|艺术院校校长怎么看AI时代的艺术教育 神二十船箭组合体转运至发射区
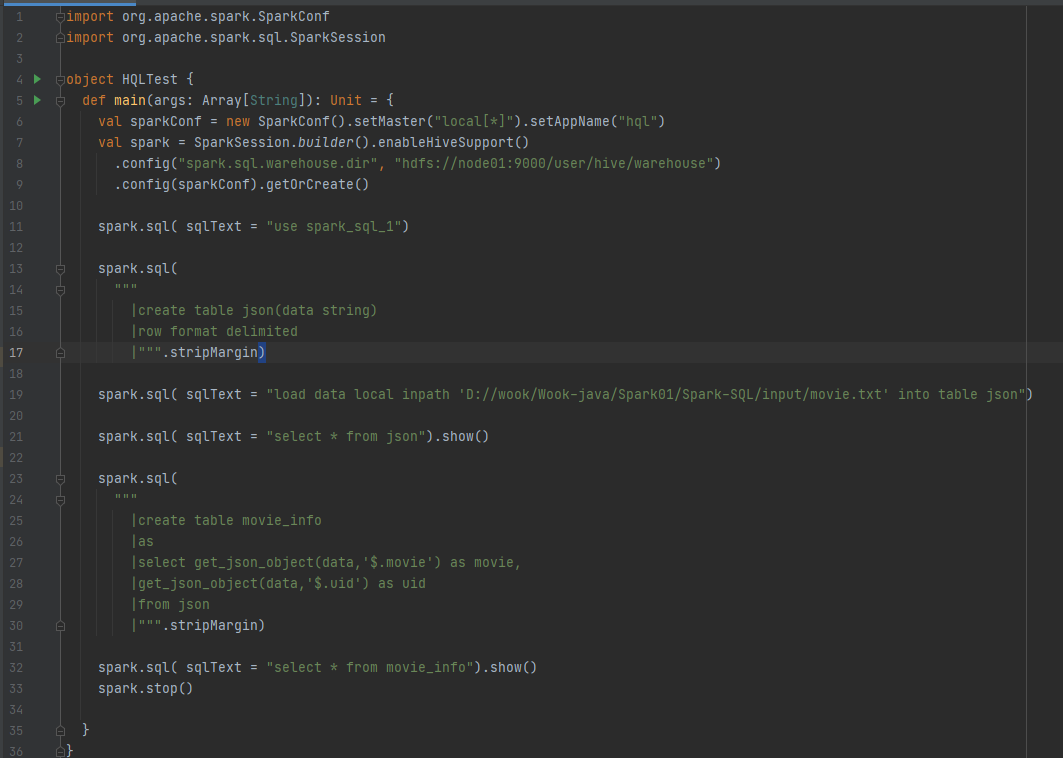
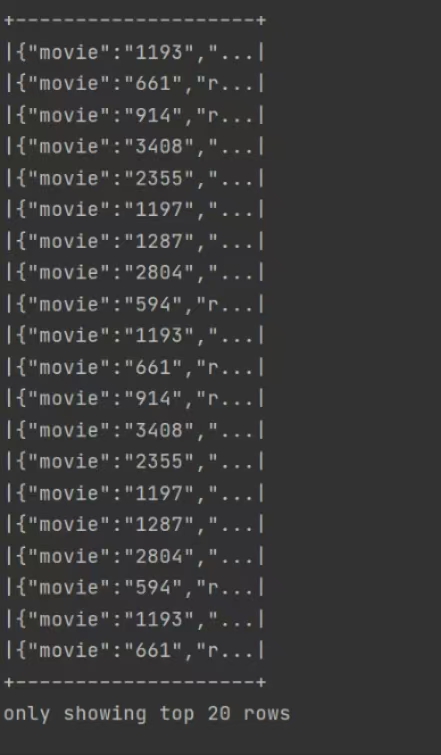
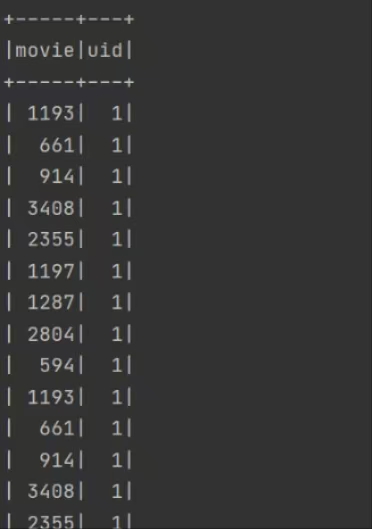
用idea实验hive的常用代码 将数据放到项目·的目录下 代码实现 运行结果: 实验 统计有效数据条数及用户数量最多的前二十个地址 将数据放到Spark-SQL/input目录下 代码实现: 运行结果: