特征提取登上Nature!计算速度为1.0256 TOPS
2025深度学习发论文&模型涨点之——特征提取
《Nature Communications》发表了一篇名为《TOPS-speed complex-valued convolutional accelerator for feature extraction and inference》的论文。介绍了一种万亿次速率的复值光子卷积加速器(CVOCA),它能够高效地处理复值数据并进行特征提取。
特征提取(Feature Extraction)作为机器学习与数据挖掘的核心预处理步骤,在降维、模式识别和可解释性研究中发挥着关键作用。随着高维数据在生物信息学、计算机视觉、自然语言处理等领域的广泛应用,传统的手工特征工程已难以应对复杂的数据结构,而基于深度学习的自动特征提取方法(如自编码器、卷积神经网络和Transformer)逐渐成为研究热点。然而,如何平衡特征的判别性、鲁棒性和可解释性,仍是当前研究的核心挑战。
我整理了一些特征提取【论文+代码】合集,需要的同学公人人人号【AI创新工场】发525自取。
论文精选
论文1:
[Nature子刊] TOPS-speed complex-valued convolutional accelerator for feature extraction and inference
TOPS 速度的复值卷积加速器用于特征提取和推理
方法
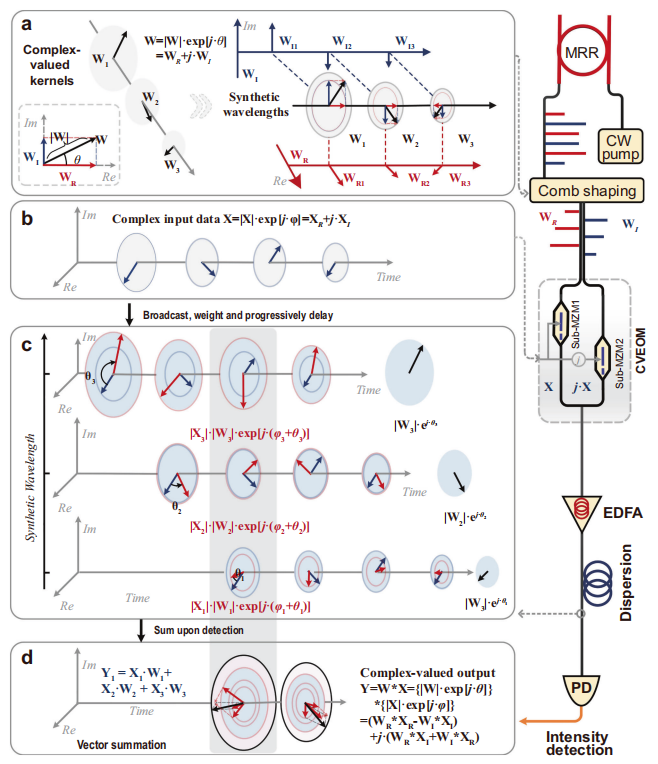
复值卷积加速器(CVOCA):提出了一种复值光学卷积加速器,能够处理高维、超快速的波或复值数据流的特征提取。
合成波长方法:提出了一种“合成波长”方法,用于在稳定和非相干的方式中构建复值权重 W,通过微梳源的光谱合成实现。
复值电光调制器(CVEOM):设计了一种复值电光调制器,用于对复值输入数据和卷积核权重进行电光调制。
时间-波长交织:通过时间-波长交织技术,实现了复值输入数据和权重的快速卷积运算,计算速度超过 2 Tera 操作每秒(TOPS)。
创新点
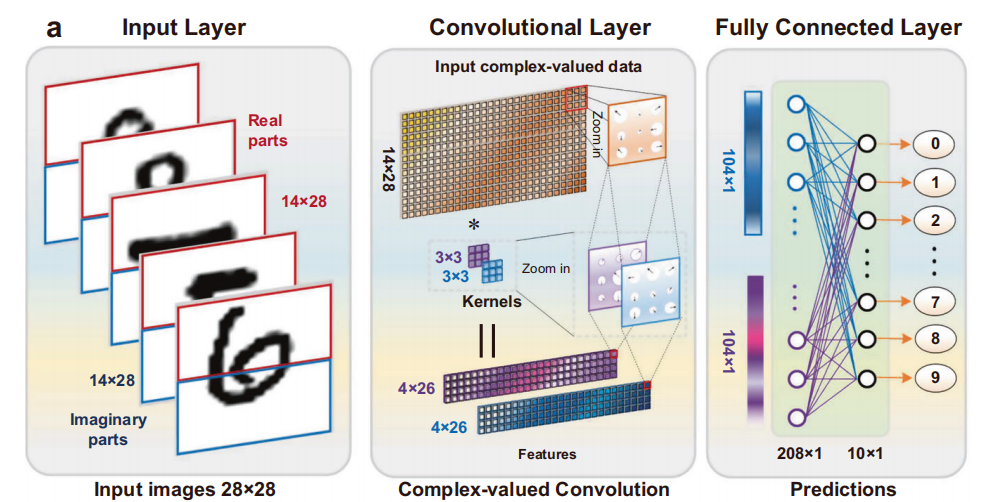
计算速度提升:实现了超过 2 TOPS 的计算速度,比之前的光子卷积加速器快 3 倍以上,能够处理约 1370 万张 100×100 的 SAR 图像每秒。
复值数据处理能力:首次实现了对复值合成孔径雷达(SAR)图像的特征提取,这些图像比光学神经网络之前处理的数据更为复杂。实验测试 500 张图像的识别准确率达到 83.8%,接近计算机模拟结果。
硬件效率优化:通过直接处理复值数据,避免了将复值卷积分解为四个实值卷积的复杂过程,降低了系统的复杂性和功耗。
实际应用验证:不仅在手写数字识别任务中验证了 CVOCA 的性能,还在 SAR 图像识别任务中展示了其处理复杂复值数据的能力,证明了其在实际应用中的潜力,如地球观测和遥感领域。
论文2:
LEFormer: A Hybrid CNN-Transformer Architecture for Accurate Lake Extraction from Remote Sensing Imagery
LEFormer:一种用于从遥感影像中准确提取湖泊的混合CNN-Transformer架构
方法
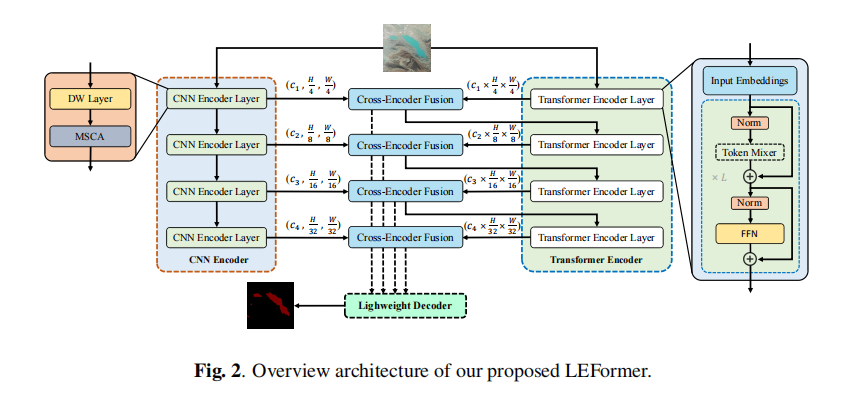
CNN编码器:设计了一个基于深度可分离卷积和多尺度空间通道注意力(MSCA)的CNN编码器,用于提取精确的局部空间信息。
Transformer编码器:提出了一种轻量级的Transformer编码器,通过有效自注意力(Efficient Self-Attention)和重叠Patch嵌入来捕获长距离依赖关系和全局上下文信息。
交叉编码器融合模块:设计了一个轻量级的交叉编码器融合模块,将CNN编码器提取的局部特征和Transformer编码器提取的全局特征进行融合,以改善掩膜预测。
轻量级解码器:使用SegFormer中的轻量级解码器,将融合后的特征图转换为最终的分割掩膜。
创新点
性能提升:在Surface Water数据集上达到了90.86%的mIoU,在Qinghai-Tibet Plateau Lake数据集上达到了97.42%的mIoU,参数量仅为3.61M,比之前的最佳湖泊提取方法小20倍。
混合架构优势:结合CNN的局部特征提取能力和Transformer的全局特征捕获能力,实现了高精度和低计算成本的统一。
轻量级设计:通过轻量级的Transformer编码器和交叉编码器融合模块,显著降低了模型的参数量和计算量,提高了模型的效率。
多尺度特征融合:通过MSCA模块和交叉编码器融合模块,有效地融合了多尺度特征,提升了对复杂湖泊形状的分割精度。
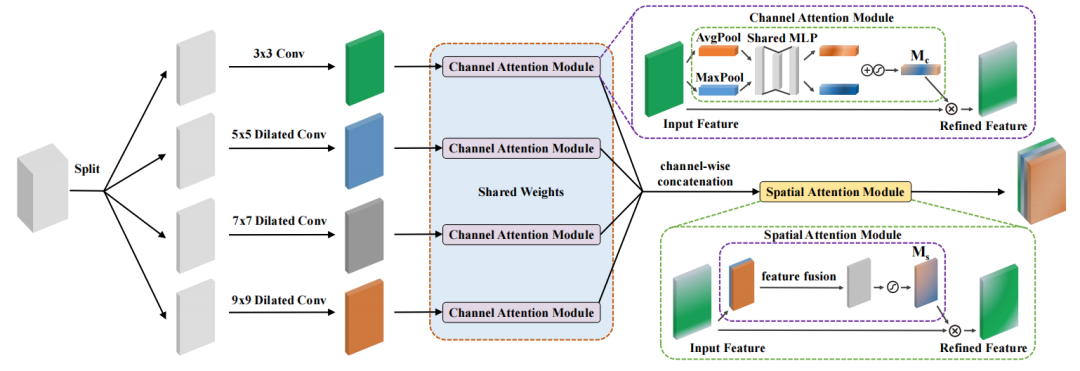
论文3:
Progressive Classifier and Feature Extractor Adaptation for Unsupervised Domain Adaptation on Point Clouds
点云无监督域适应的渐进式分类器和特征提取器适应
方法
渐进目标风格特征增强(PTFA):提出了一种新的渐进目标风格特征增强策略,通过构建一系列中间域,使模型逐步适应目标域。
中间域特征提取器适应(IDFA):开发了一种中间域特征提取器适应策略,通过紧凑的特征对齐来鼓励目标风格的特征提取。
分类器适应:通过PTFA策略,使分类器逐步适应目标风格的源特征,从而提高分类器的适应能力。
特征提取器适应:通过IDFA策略,使特征提取器逐步对齐到中间域的分布,从而提高特征提取的准确性。
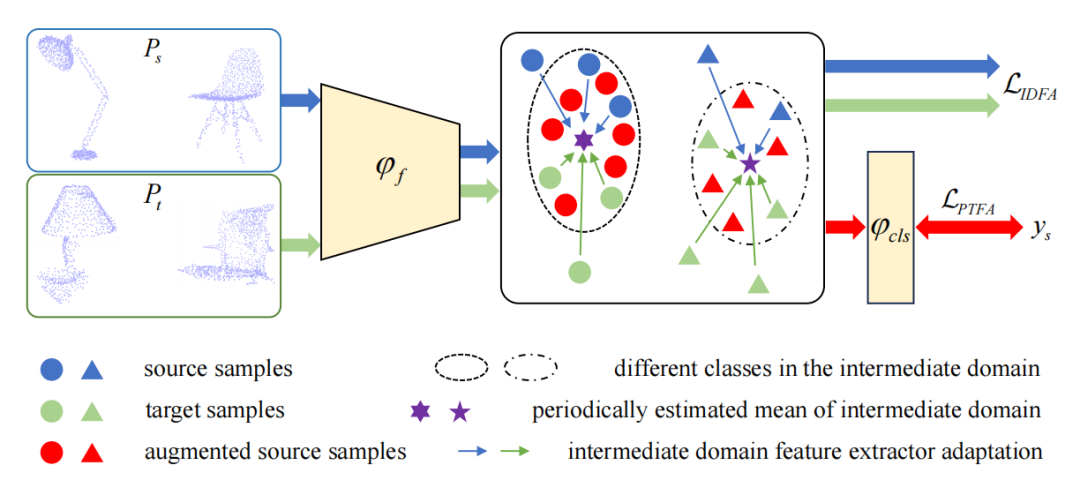
创新点
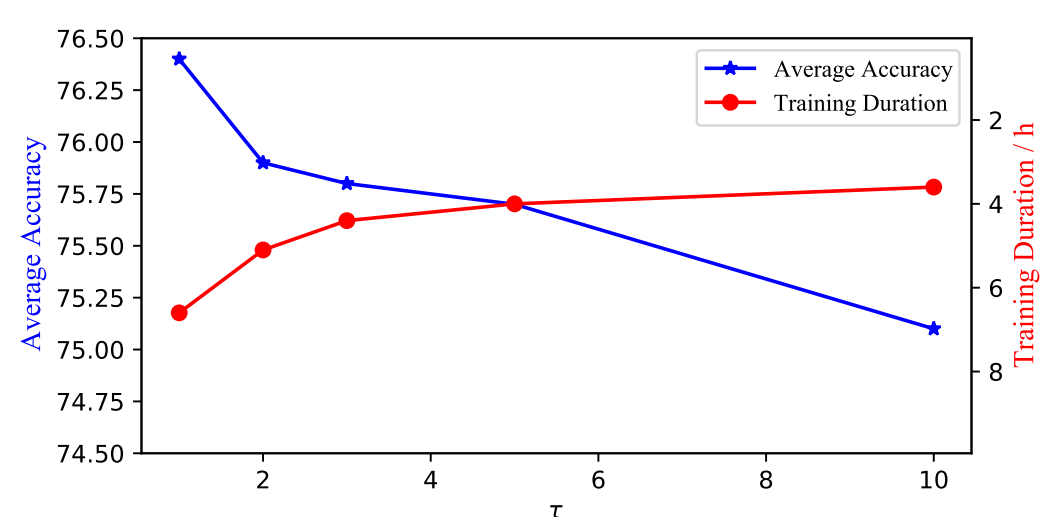
性能提升:在PointDA-10数据集上,平均识别准确率达到了76.5%,比之前的最佳方法DAS提高了2.9%;在GraspNetPC-10数据集上,平均识别准确率达到了87.6%,比之前的最佳方法DAS提高了1.9%。
渐进适应策略:通过逐步构建中间域,使模型能够逐步适应目标域,避免了直接跨大域差距适应带来的问题。
特征提取器和分类器的深度耦合:PTFA和IDFA策略相互促进,PTFA为IDFA提供了更准确的分布估计,而IDFA为PTFA提供了更紧凑的特征对齐,从而提高了整体适应性能。
样本独特性考虑:首次在3D UDA中考虑样本的独特性,通过选择部分源
和目标样本构建中间域,提高了模型对目标域的适应能力。