递归神经网络
递归神经网络RNN
专门用于处理序列数据的神经网络结构,RNN具有循环连接,能够捕捉序列数据中的时间依赖关系。使RNN在自然语言处理、语音识别、时间序列预测等任务中表现出色。
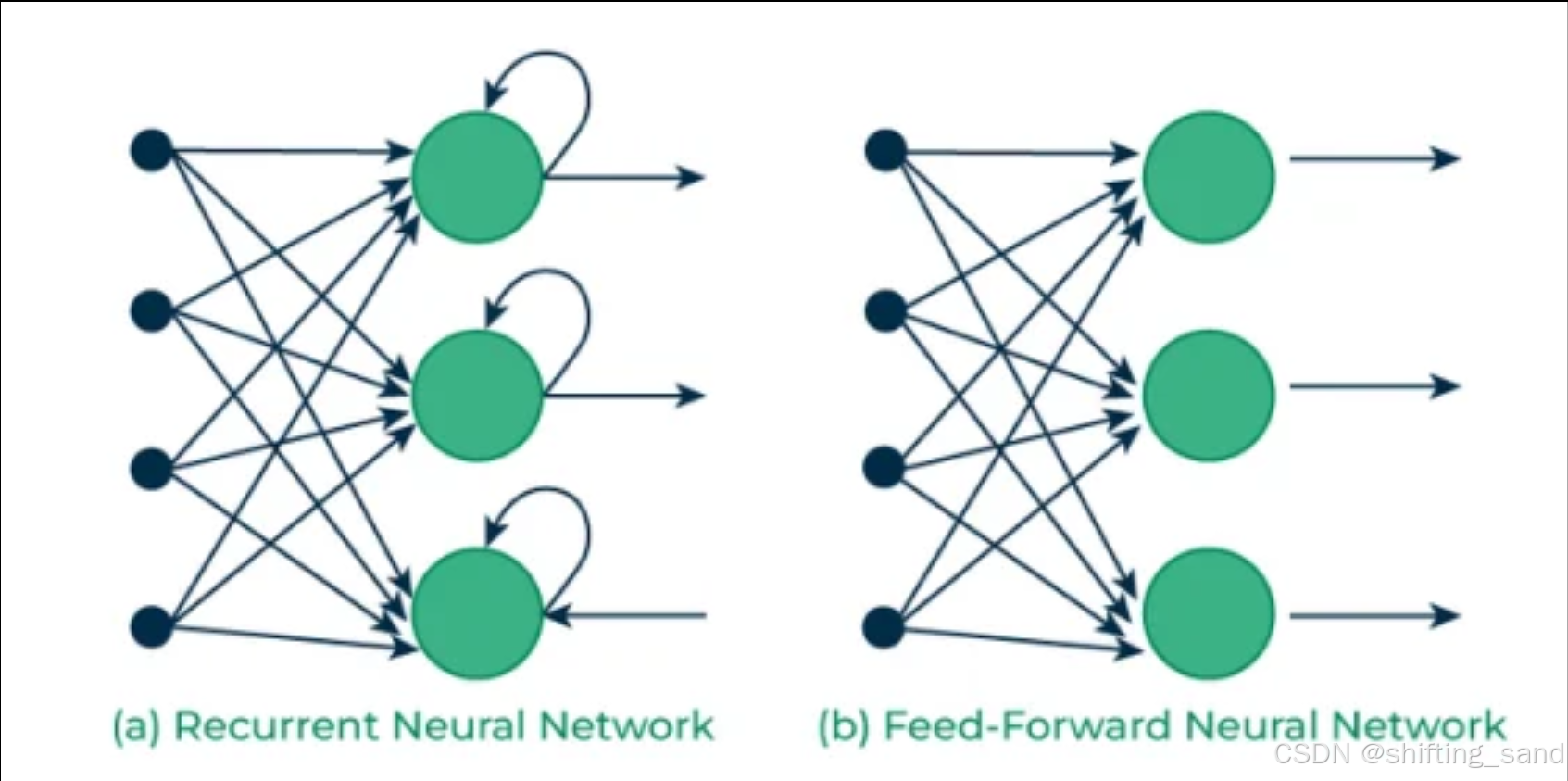
核心思想
通过循环结构在时间步之间传递信息。每个时间步的输入不仅包括当前时刻的数据,还包括前一时刻的隐藏状态。
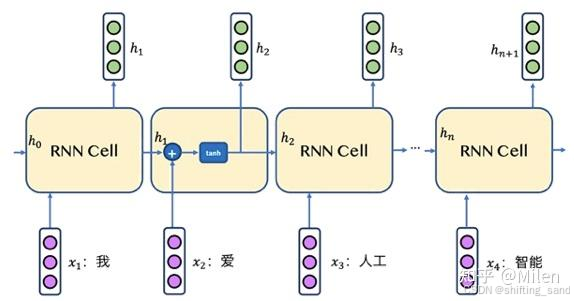
- 隐藏状态
每个时间步t的隐藏状态 h t h_t ht由当前输入 x t x_t xt和前一状态 h t − 1 h_{t-1} ht−1共同决定
h t = f ( W h h ⋅ h t − 1 + W x h ⋅ x t + b h ) h_t = f(W_{hh}·h_{t-1} + W_{xh}·x_t +b_h) ht=f(Whh⋅ht−1+Wxh⋅xt+bh)
- h t − 1 h_{t-1} ht−1:上一时刻的隐藏状态
- x t x_t xt:当前时刻的输入
- W h h W_{hh} Whh和 W x h W_{xh} Wxh:权重矩阵
- b h b_h bh:偏置
- f f f:激活函数(tanh或ReLU)
参数共享:所有时间步共享同一组权重( W x h 、 W h h W_{xh}、W_{hh} Wxh、Whh),大幅减少参数量并增强对变长序列的泛化能力。
- 输出公式: y t = g ( W h ⋅ h t + b y ) y_t = g(W_h·h_t + b_y) yt=g(Wh⋅ht+by)
W y W_y Wy:输出权重矩阵
b y b_y by:输出偏置
g g g:输出激活函数
特点
- 时间依赖性:可以捕捉序列数据不同时间步之间依赖关系
- 可变长度输入:可以处理任意长度的序列数据
- 循环结构:通过隐藏状态的传递,RNN在时间步直接共享信息
局限性
- 梯度消失和梯度爆炸:反向传播过程中,RNN的梯度可能随着时间步的增加而指数级衰减或增长,导致训练困难
- 长距离依赖问题:难以捕捉序列中较长时间步之间的依赖关系。
- 所有词都进行训练,没有重点
变体
- 长短期记忆网络LSTM(Long Shot-Term Memory)
特殊RNN,通过引入门控制机制(输入门,遗忘门,输出门)来解决梯度消失问题,并更好地捕捉长距离依赖。
- 门控制循环单元GRU(Gated Recurrent Unit)
LSTM的简化版本,通过合并部分门控机制,减少参数数量,同时保持良好性能。
- 双向RNN
BiRNN通过同事考虑正向和反向的时间步信息,增强对序列数据的建模能力。
- 堆叠RNN
堆叠多层RNN,增强模型的表达能力
应用
- 自然语言处理(NLP):语言建模、机器翻译、文本生成、情感分析
- 语音识别:处理语音信号的时间序列数据
- 时间序列预测:股票价格预测、天气预测
- 视频分析:动作识别、视频描述生成
其他概念
- 负采样:处理大规模分类问题时,用于优化模型训练过程。目的通过减少计算复杂度来提高训练效率
正样本:上下文中出现的词或者推荐系统中用户选择的商品
负样本:随机选择的词或者推荐系统中用户未交互的商品
核心思想:从大量负样本中随机选择小部分,而不是所有负样本进行计算。
- hard训练:通过引入更具挑战性的样本或任务来提高模型性能。
词向量模型
一种将词语或短语映射到低位向量空间的技术。核心:通过数学表示捕捉词语之间的语义和语法关系,使语义相似的词语在向量空间中距离较近,有了向量就可以计算相似度。
基本概念
- 词向量:每个词语被表示为一个固定长度的实数向量。(如300维)
- 低维空间:通常映射到低维连续向量空间(如50维、100维),而不是传统高维系数表示(One-Hot编码)
- 语义相似性:在向量空间中,语义相似的词语距离较近,可通过余弦相似度等度量方法计算。
发展
- 早期方法
- One-Hot Encoding:每个词用一个高维稀疏向量表示,维度等于词汇表大小,但无法捕捉语义信息。
- 共现矩阵:通过统计词语在上下文中的共线频率构建矩阵,但维度高难以扩展。
高维稀疏向量:一个向量具有非常高的维度(即特征数量),但其中大部分元素的值为零。
- 现代词向量模型
- Word2Vec(2013,Goole):通过神经网络学习词向量,包括CBOW(通过上下文预测中心词)和Skip-Gram(通过中心词预测上下文)两种模型。训练速度快,能捕捉语义关系,无法处理未登录词。
- GloVe(2014,斯坦福):基于全局词共现矩阵,结合矩阵分解技术学习词向量。训练效率高,能捕捉词语间线性关系。
- FastText(2016,Facebook):将词语分解为字符级别的n-gram,可以通过字符组合推断语义,能处理未登录词(OOV)。德语、土耳其语表现优异。
- ELMo(2018,Allen Institute for AI):基于双向LSTM的上下文相关词向量模型。同一个词在不同上下文中向量不同。
- BERT(2018,Goole):基于Transformer的预训练模型,推断语义,生成上下文相关的词向量。预训练任务包括掩码语言模型(MLM)和下一句预测(NSP)。
未登录词:指在词向量模型或语言模型的词汇表中不存在的词语。当模型遇到一个不在其训练词汇表中的词时,就会将其视为未登录词。
- 应用
文本分类、情感分析、机器翻译、信息检索、推荐系统
- 优缺点
- 能捕捉词语的语义和语法关系
- 降低维度,提高计算效率
- 可扩展性强,适用于多种NLP任务
- 传统模型(Word2Vec、GloVe)无法处理未登录词
- 上下文无关的模型(如Word2Vec、GloVe)无法捕捉词语在不同上下文中的语义变化。
- 训练需要大规模语料,计算资源消耗较大。
- 发展方向
- 上下文相关词向量:BERT、GPT等模型,能生成动态词向量
- 多语言词向量:支持跨语言语义表示
- 轻量化模型:降低训练和推理计算成本,提高效率
- 领域自适应:针对特定领域(医学、法律)优化词向量