突破传统!SEARCH-R1如何让LLM与搜索引擎协同推理?
大语言模型(LLMs)虽强大,但在复杂推理和获取最新信息方面存在局限。本文介绍的SEARCH-R1框架,通过强化学习让LLMs能自主与搜索引擎交互,在多个问答数据集上性能大幅提升。想知道它是如何做到的吗?快来一探究竟!
论文标题
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
来源
arXiv:2503.09516v3 [cs.CL] + http://arxiv.org/abs/2503.09516
文章核心
研究背景
大语言模型在自然语言处理方面成果显著,但在复杂推理和获取外部最新信息时面临挑战,目前整合LLMs与搜索引擎的方法存在不足。
研究问题
- 现有整合LLMs与搜索引擎的方法,如检索增强生成(RAG)和将搜索引擎视为工具的方法,存在LLMs与搜索引擎交互不佳、依赖大量标注数据等问题。
- 将强化学习应用于搜索和推理场景时,面临如何有效整合搜索引擎到RL方法以确保稳定优化、实现多轮交错推理和搜索、设计有效奖励函数等挑战。
主要贡献
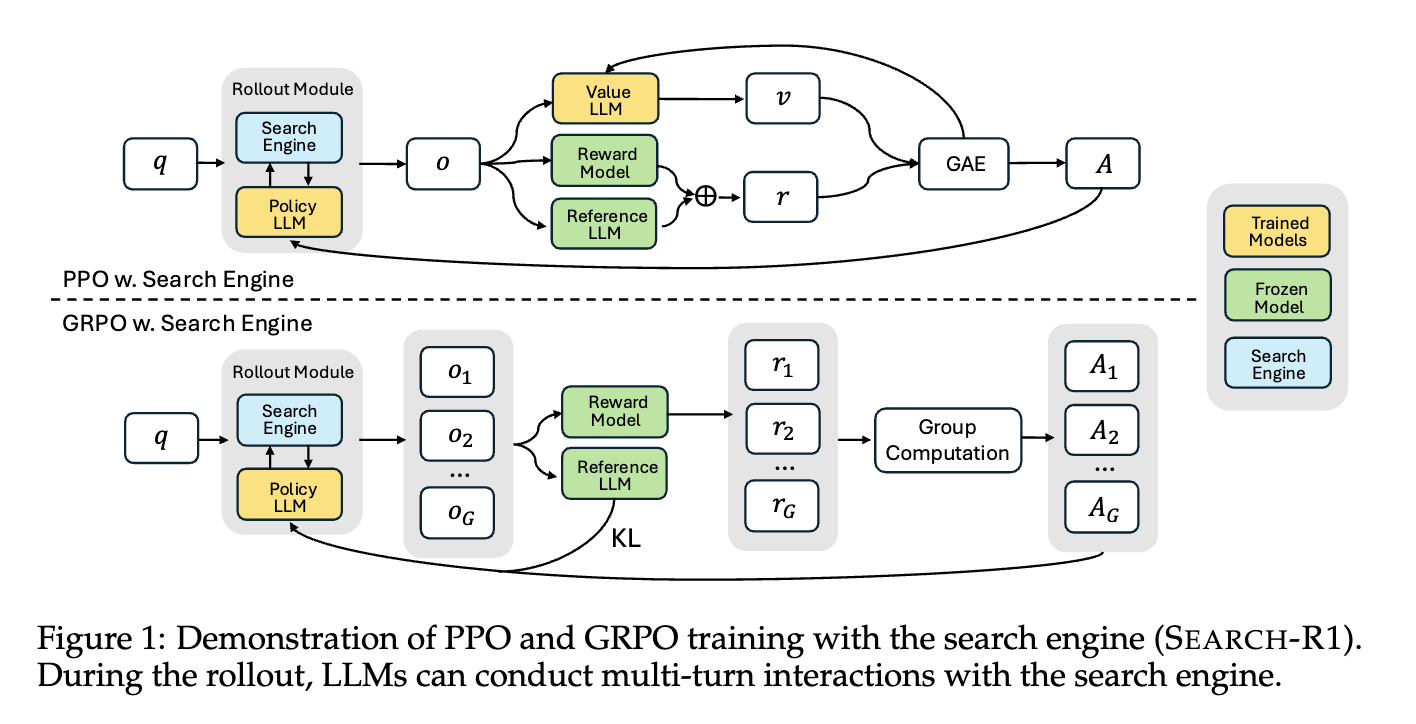
- 提出创新框架:引入SEARCH-R1框架,使LLMs能与搜索引擎交错推理,优化推理轨迹,提升复杂推理任务的表现。
- 创新训练方法:通过检索令牌掩码稳定RL训练,支持多轮交错推理和搜索,采用简单的基于结果的奖励函数,避免复杂奖励设计。
- 验证框架有效性:在七个问答数据集上进行实验,SEARCH-R1相比各种RAG基线在相同设置下性能显著提升,Qwen2.57B提升41%,Qwen2.5-3B提升20% ,并对RL优化方法等进行了实证分析。
方法论精要

- 核心算法/框架:采用强化学习框架,将搜索引擎建模为环境的一部分,兼容PPO和GRPO等RL算法,支持LLMs与搜索引擎多轮交互。
- 关键参数设计原理:在PPO和GRPO中,通过对检索令牌进行损失掩码,确保策略梯度仅在LLM生成的令牌上计算,稳定训练。PPO通过广义优势估计$ GAE 计算优势估计 计算优势估计 计算优势估计 A_{t} , G R P O 则利用多个采样输出的平均奖励作为基线计算优势 ,GRPO则利用多个采样输出的平均奖励作为基线计算优势 ,GRPO则利用多个采样输出的平均奖励作为基线计算优势 \hat{A}_{i, t} $。
- 创新性技术组合:结合LLMs推理与搜索引擎检索,在LLMs推理过程中,通过特定令牌和)触发搜索引擎调用,检索结果用和包裹作为后续推理的上下文,实现多轮交错推理和搜索。
- 实验验证方式:使用七个基准数据集,包括通用问答(如NQ、TriviaQA、PopQA)和多跳问答(如HotpotQA、2WikiMultiHopQA等)数据集。对比基线涵盖无检索推理(直接推理、思维链推理)、有检索推理(RAG、IRCoT等)以及基于微调的方法(监督微调、无搜索引擎的RL微调),在相同的检索模型、训练数据和预训练LLMs等设置下进行公平比较。
实验洞察
- 性能优势:在七个数据集上,SEARCH-R1相比基线方法表现出色。以Qwen2.5-7B模型为例,相比RAG基线,在NQ数据集上绝对提升约13.1%(从0.349提升到0.480) ,平均相对提升41%;Qwen2.5-3B模型平均相对提升20% ,在多个数据集上均有显著性能提升。
- 效率突破:论文未明确提及SEARCH-R1在训练/推理速度上的优化程度,但从整体框架设计来看,其多轮交错推理和搜索机制可能在一定程度上提高推理效率,不过这需要进一步的实验验证。
- 消融研究:对检索令牌损失掩码进行实验,发现使用该掩码的模型性能更优。如在Qwen2.5-7b-base模型上,使用掩码的SEARCH-R1在NQ数据集上的EM值为0.480 ,无掩码时为0.388,平均得分也从0.343提升到0.431,证明了该模块的有效性。
本文由AI辅助完成。