全排列问题cpp
题目如下
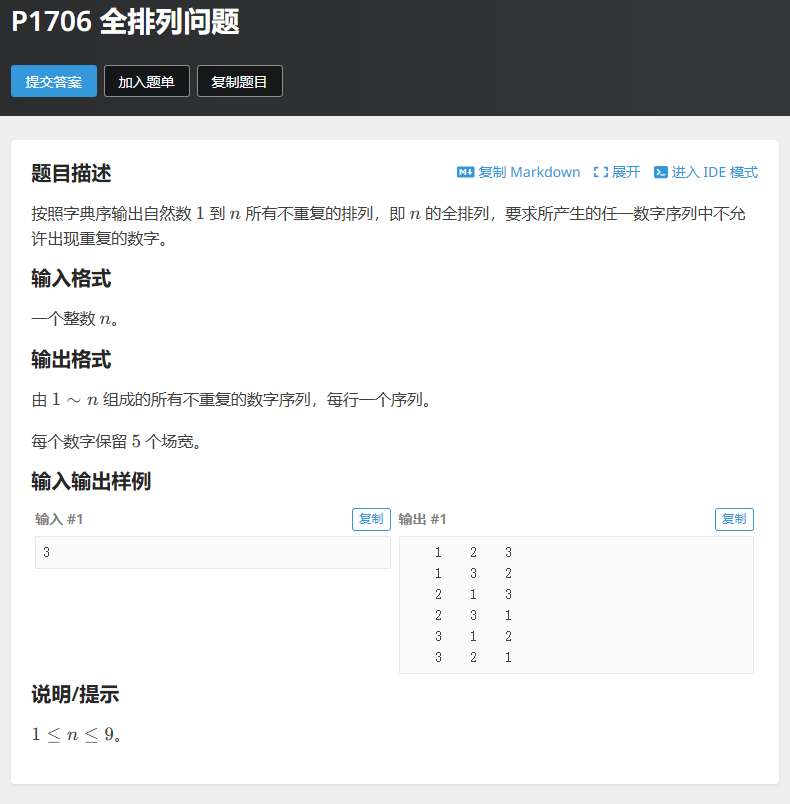
dfs做法
全局变量
used:一个布尔类型的vector,用于标记数字是否已经在当前排列中使用过。used[i]为true表示数字i已经被使用,为false表示未被使用。
permutation:一个整数类型的vector,用于存储当前正在生成的全排列。
dfs函数:
递归终止条件:当permutation的大小等于n时,说明已经生成了一个完整的全排列,此时遍历permutation并按照每个数字保留5个场宽的格式输出该排列,然后返回。
递归过程:遍历从1到n的数字,如果某个数字i未被使用(即used[i]为false),则将其标记为已使用(used[i] = true),加入到当前排列中(permutation.push_back(i)),然后递归调用dfs继续生成下一个数字。递归返回后,进行回溯操作,将刚才加入的数字从排列中移除(permutation.pop_back()),并将其标记为未使用(used[i] = false),以便在后续的循环中可以再次使用该数字。
main函数:
读取输入的整数n。
初始化used数组,将所有元素设置为false,表示所有数字都未被使用。
调用dfs函数开始生成全排列。
库函数方法(next_permutation)更为方便
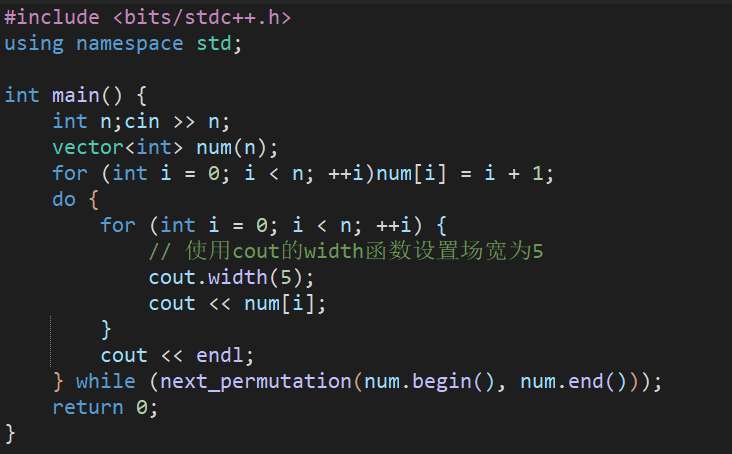
解释
next_permutation函数:
它是 C++ 标准库<algorithm>头文件中的一个函数,用于生成给定序列的下一个字典序排列。
函数接受两个迭代器参数,nums.begin() 和 nums.end(),这两个迭代器指定了要进行全排列操作的序列范围,即[nums.begin(), nums.end())(左闭右开区间)。
该函数的工作原理是:首先从序列的末尾向前查找,找到第一个满足*(i - 1) < *i 的位置i - 1;然后再从序列末尾向前查找,找到第一个大于*(i - 1) 的元素*j;接着交换*(i - 1) 和*j;最后将位置i 及其之后的元素进行反转,从而得到下一个字典序排列。
next_permutation函数的返回值是一个布尔值:如果存在下一个排列(即成功生成了下一个字典序排列),则返回true;如果当前排列已经是字典序最大的排列(不存在下一个排列),则返回false。
while循环:
while循环的条件是next_permutation(nums.begin(), nums.end()),即只要next_permutation函数返回true(表示成功生成了下一个排列),就会继续执行循环体中的代码。
在循环体中,通常会对生成的新排列进行一些处理,比如输出排列中的元素。在前面生成全排列的代码示例中,循环体内部的代码用于遍历并输出当前排列中的每个数字,每个数字保留 5 个场宽。
当next_permutation函数返回false时,说明已经遍历完了所有可能的排列(当前排列是字典序最大的排列),此时while循环结束。
综上所述,while (next_permutation(nums.begin(), nums.end())) 这行代码的作用是不断调用next_permutation函数生成序列nums 的下一个字典序排列,并在每次成功生成新排列后执行循环体中的代码,直到遍历完所有可能的排列为止。