RSS 2025|苏黎世提出「LLM-MPC混合架构」增强自动驾驶,推理速度提升10.5倍!
论文题目:Enhancing Autonomous Driving Systems with
On-Board Deployed Large Language Models
论文作者:Nicolas Baumann,Cheng Hu,Paviththiren Sivasothilingam,Haotong Qin,Lei Xie,Michele Magno,Luca Benini
论文地址:
[2504.11514] Enhancing Autonomous Driving Systems with On-Board Deployed Large Language Models
代码地址:https://github.com/ForzaETH/LLMxRobot
引言
随着技术持续进步,自动驾驶从概念逐步迈向现实,为未来出行勾勒出全新的图景。然而,这条发展之路并非一帆风顺,传统数据驱动的自动驾驶技术在面对现实世界中复杂多样的驾驶场景时,遭遇了严峻的挑战。基于机器学习的自动驾驶系统,尽管在大量常见场景的训练下能够展现出一定的智能性,但在处理极端情况时却显得力不从心。这是因为现实中的驾驶场景情况复杂,难以通过有限的数据集覆盖所有可能性。例如,遇到道路临时施工、动物突然闯入等情况,这些系统往往无法做出准确且合理的决策。
与此同时,大语言模型(LLMs)在自然语言处理领域取得了突破性进展,其强大的知识理解、推理和生成能力令人瞩目。这一技术的崛起,为自动驾驶领域带来了新的曙光。LLMs可以理解复杂的自然语言指令,基于广泛的知识储备进行推理,这与自动驾驶中对复杂场景的理解和决策需求有着高度的契合性。然而,将LLM直接应用于自动驾驶等安全关键系统,尤其是依赖云端模型的做法,带来了延迟、连接稳定性、数据隐私和安全等多重隐患。此外,LLM自身存在的“幻觉”问题也限制了其直接控制车辆行为的应用范围。
针对这些挑战,论文《Enhancing Autonomous Driving Systems with On-Board Deployed Large Language Models》提出了一种创新的混合架构,巧妙地将强大的大语言模型(LLMs)与经典的低层模型预测控制器(MPC)相结合,并强调在车辆本地(On-Board)部署LLM,旨在增强自动驾驶系统的决策能力、人机交互(HMI)体验和控制适应性。
主要方法
为解决自动驾驶系统中数据驱动方法处理极端情况的局限,论文提出将低级模型预测控制器(MPC)与本地部署的大语言模型(LLMs)相结合的混合架构,综合运用多种技术实现高效决策和人机交互。该系统由两个关键的、相互协作的模块构成——负责理解人类意图和评估车辆状态的DecisionxLLM,以及负责将高层指令转化为具体MPC参数调整的MPCxLLM。这种设计旨在融合LLM的认知智能与MPC的控制优势,实现更安全、更智能、更具适应性的自动驾驶体验。
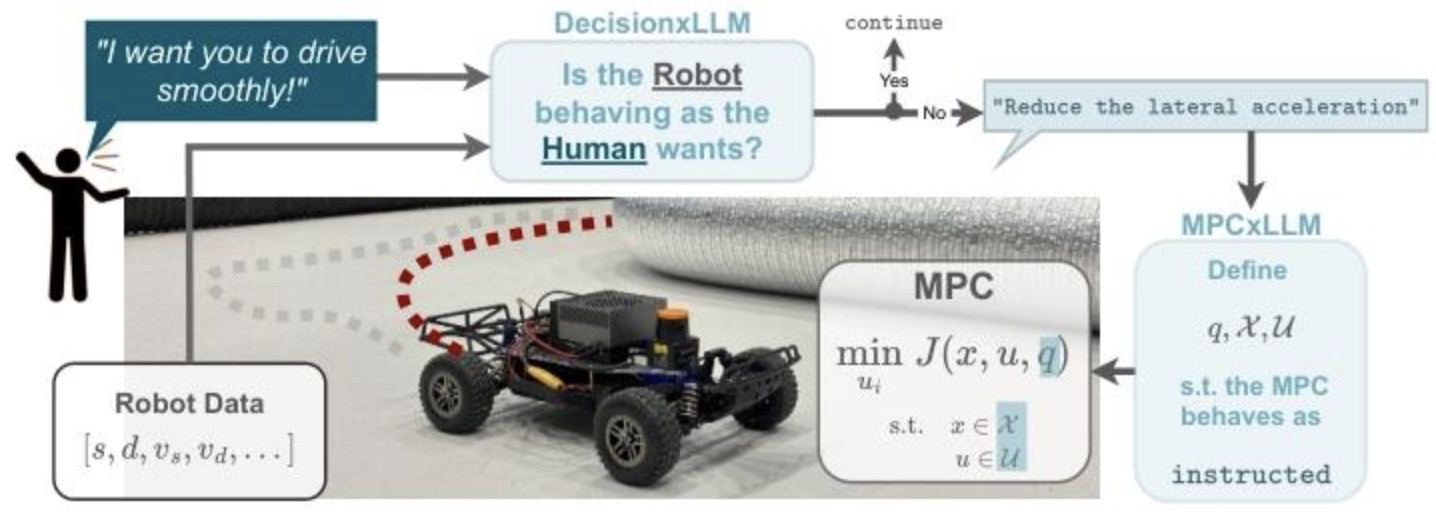
图1 系统总体框架
DecisionxLLM 模块
该模块作为系统的"感知与决策中心", 负责理解人类的意图并评估车辆行为。它接收人类通过自然语言下达的驾驶指令或偏好, 并结合从车辆传感器获取的近期状态数据,包括路径坐标、横向偏差
、纵向速度
、横向速度
等信息, 可表示为时序数据
。LLM利用其强大的理解和推理能力,判断车辆当前的实际运行状态是否与人类的期望一致。为了增强LLM在特定机器人任务上的推理能力和对上下文的理解,该模块可以选择性地集成检索增强生成(RAG),通过检索相关的背景知识来丰富LLM的输入信息。最终,DecisionxLLM输出一个判断结果,并在必要时生成一句简洁的、描述期望行为变化的自然语言指令,传递给下一环节。
MPCxLLM 模块
此模块是连接高层语义理解与底层控制执行的关键桥梁。它接收来自DecisionxLLM的自然语言调整指令。模块内的LLM被设计为能够理解这些指令,并且知晓底层MPC控制器的数学形式及其可调参数。基于这种理解(同样可由MPC相关的RAG知识库增强),LLM的任务是将抽象的驾驶行为要求转化为对MPC具体参数的修改建议。这些可调整的参数主要包括MPC优化问题中的成本函数权重
(横向偏差权重
、速度误差权重
、航向误差权重
、控制输入变化权重
),以及车辆运行必须遵守的状态约束集
和输入约束集
。LLM输出一组新的参数值
这些值随后被动态配置给底层MPC控制器。这一机制实现了通过自然语言对车辆控制特性进行灵活调整,同时将LLM的推理延迟与MPC的实时控制循环分离开。
MPC模块
系统的基础控制由一个模型预测控制器(MPC)承担,论文中具体实现了一个基于车辆运动学模型 (Kinematic Model) 的MPC。该模型描述了车辆状态如何随时间和控制输入变化,关键状态变量的动态方程如:
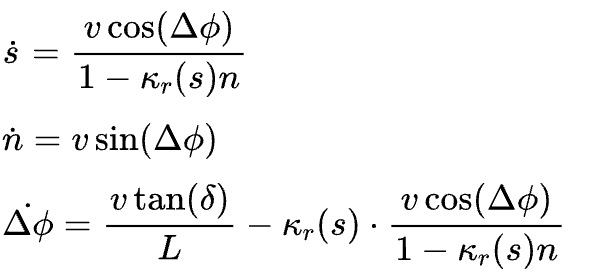
其中是沿参考轨迹的弧长,
是横向偏差,
是相对于参考路径的航向角误差,
是车辆速度,
是前轮转角,
是参考轨迹在
处的曲率,
是车辆轴距。MPC的状态向量
包含这些状态变量以及用于平滑控制的输入量,即
。控制输入
主要由转向角变化量
和纵向加速度
组成,即
。
MPC 的核心是在每个控制周期内求解一个优化问题,目标是最小化一个预测时域内累积的成本函数
。该成本函数通常是对期望行为(如跟踪参考路径和速度)的偏离以及控制输入的惩罚,形式如下:
此优化过程必须满足系统动力学约束,状态约束和输入约束。正是 MPCxLLM 模块根据高层指令进行调整的对象,以此在保证安全的前提下,灵活地改变车辆的驾驶行为(如更平稳、更激进、保持特定速度或距离等)。
车载部署优化技术
为了让通常计算量庞大的LLM能够在资源受限的车载硬件上高效运行,该方法综合运用了多种优化策略。RAG通过在推理时注入相关上下文信息,提高了小模型在特定任务上的表现,减少了对超大模型的依赖。LoRA作为一种参数高效微调技术,允许研究人员使用相对较少的数据和计算资源来适配预训练LLM,使其更好地理解机器人状态和MPC参数。最后,模型量化技术通过降低模型参数的精度,显著减小了模型的内存占用和计算需求,大幅提升了LLM在嵌入式平台上的推理速度(吞吐量),使其满足自动驾驶场景的实时性需求。这些技术的结合使得在端侧部署功能强大的LLM成为可能。
实验结果
论文通过一系列定量和定性实验,全面验证了所提出的车载大语言模型(LLM)增强型自动驾驶框架的有效性。在推理决策能力方面,对DecisionxLLM模块的评估如下图所示,结合检索增强生成(RAG)和LoRA微调技术能够显著提升本地部署LLM(如Qwen2.5-7b)判断车辆状态是否符合人类自然语言指令的准确性,相较于基础模型最高获得了10.45%的绝对精度提升。实验还表明,RAG普遍提高了各模型的决策性能,而对于实际部署至关重要的模型量化对准确率的影响甚微,证明了优化后模型在保持性能的同时具有高效性。
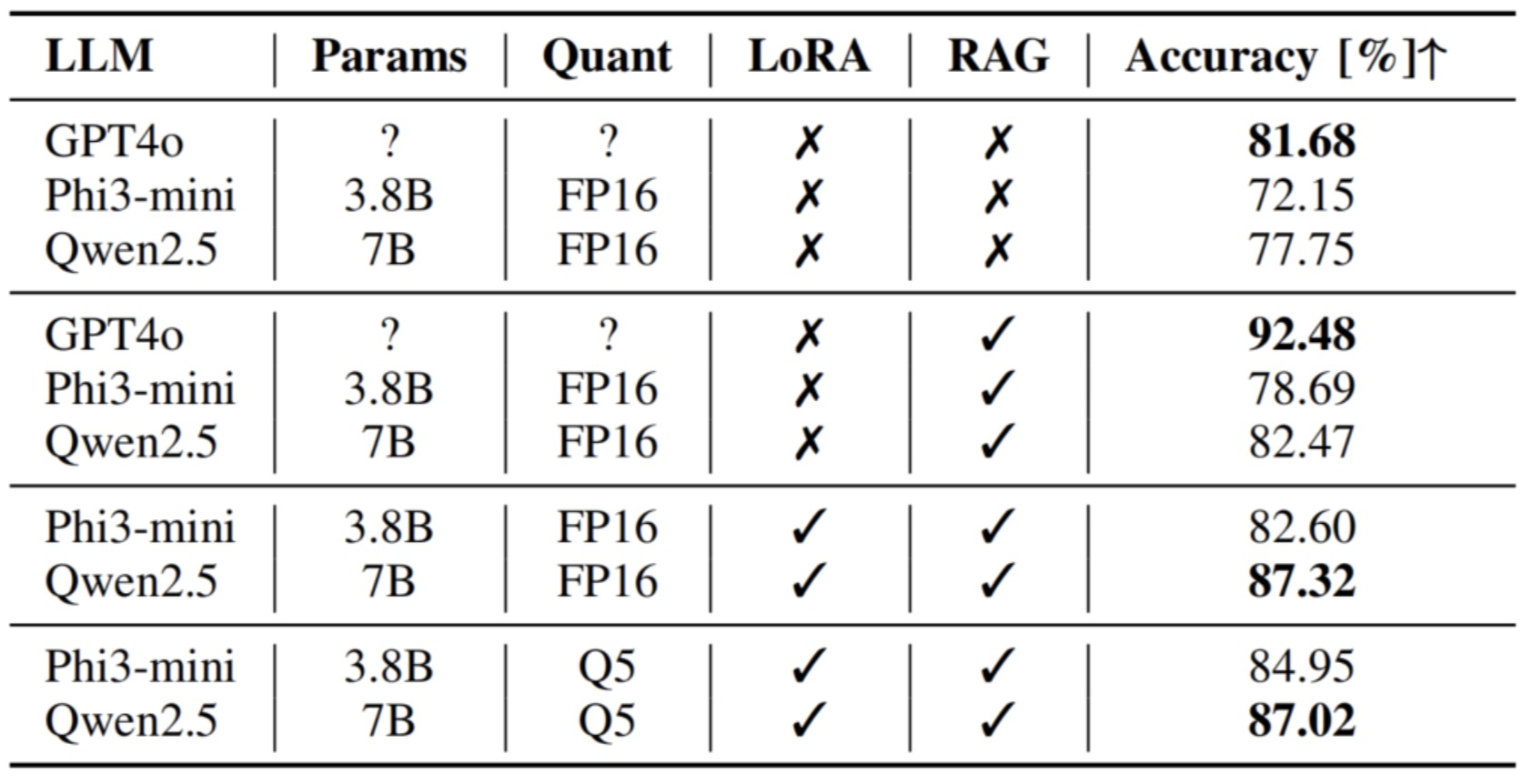
图2 DecisionxLLM模块评估对比

图3 DecisionxLLM模块对话效果
在控制适应性方面,研究者在仿真环境中评估了MPCxLLM模块通过调整底层MPC参数来响应不同驾驶指令的能力。结果如下图所示,与采用固定参数的基线MPC相比,经过RAG和LoRA优化的LLM能够根据指令(如“保持车道中心”、“更平稳地驾驶”或“倒车”)显著改变车辆的闭环行为特性,在多个衡量控制效果的指标(如路径跟踪、速度跟踪、加速度平滑度等RMSE)上取得了平均高达52.2%的改善(以Qwen2.5为例),充分展示了该框架利用自然语言进行灵活控制调整的潜力。
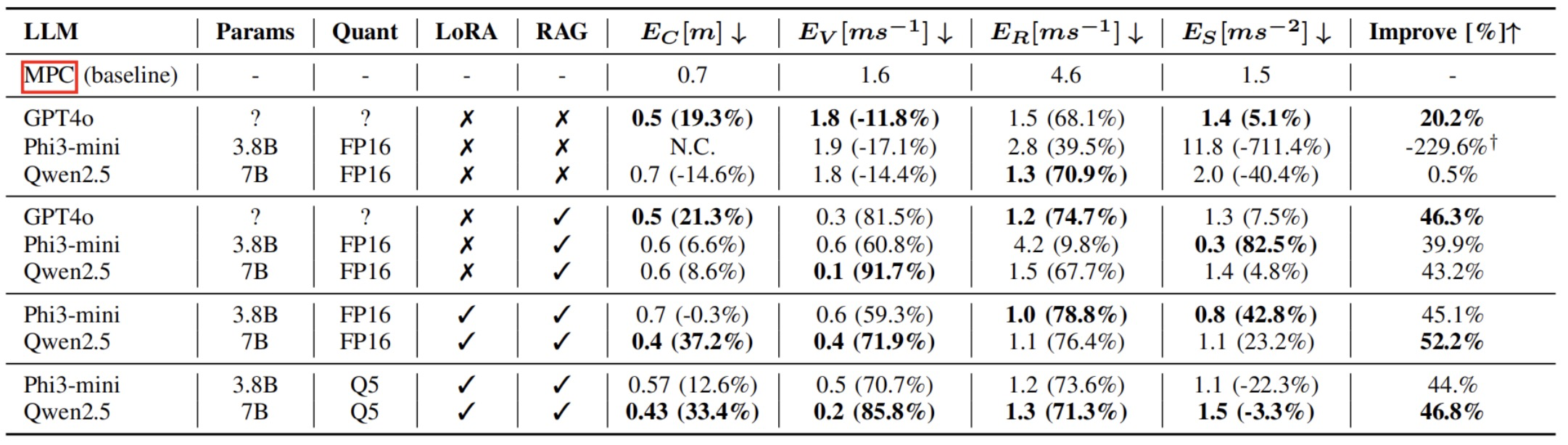
图4 MPCxLLM模块评估对比

图5 MPCxLLM模块对话效果
如下图所示,在1:10比例的物理机器人平台上进行实验,成功展示了系统在真实世界中的运作情况,例如,机器人能够根据指令“离墙远一点”来调整其横向位置,或是在模拟发生碰撞后,自主决策执行倒车操作以脱困,并随后恢复正常循迹行驶,证明了该方法在实际硬件上的可行性和鲁棒性。
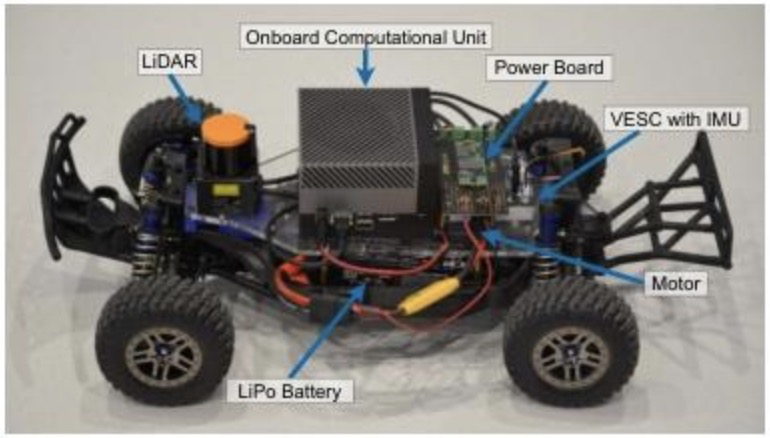
图6 1:10比例的物理小车结构

图7 无人车在真实世界的运作情况
总结
为解决自动驾驶系统在边缘场景处理上的局限性以及云端大模型应用的延迟与隐私问题,该研究提出了一种创新的混合架构,将大语言模型(LLM)部署在车辆本地,并与经典的模型预测控制器(MPC)相结合。该架构通过DecisionxLLM模块理解人类自然语言指令并评估车辆状态,再利用MPCxLLM模块将高层意图转化为对底层MPC成本函数与约束参数的调整,从而在确保MPC提供安全保障的前提下,实现了灵活的人机交互与自适应控制。为了保证LLM在资源受限的车载硬件上高效运行,研究采用了RAG、LoRA微调和量化等关键优化技术。实验结果表明,该方法显著提升了系统的决策准确性(最高10.45%)、控制适应性(最高52.2%),并且通过量化等手段实现了在嵌入式平台上高达10.5倍的推理速度提升,验证了该框架在增强自动驾驶智能性、交互性的同时,具备了实际部署的可行性和高效性。这种将高级别人工智能在本地安全集成的探索,预示着未来自动驾驶汽车将更加“善解人意”,能够通过自然对话满足用户的个性化偏好,使人机交互更加直观、舒适,有助于提升公众对自动驾驶技术的接受度并加速其普及应用。