强化学习框架verl源码学习-快速上手之如何跑通PPO算法
veRL简介
veRL 是由字节跳动火山引擎团队开源的一个灵活、高效且可用于生产环境的强化学习(RL)训练框架,专为大型语言模型(LLMs)的后训练设计。 该框架是论文 HybridFlow 的开源实现,旨在为 LLM 的强化学习训练提供高效支持。
- github仓库链接:https://github.com/volcengine/verl
- 文档链接:https://verl.readthedocs.io/en/latest/index.html

安装
# install verl together with some lightweight dependencies in setup.py
pip3 install torch==2.6.0 --index-url https://download.pytorch.org/whl/cu126
pip3 install flash-attn --no-build-isolation
git clone https://github.com/volcengine/verl.git
cd verl
pip3 install -e .
源码部分截图如下:
如果顺利的话,上面命令是可以安装,不过可能会遇到版本问题,flash-attn编译问题,或者网络问题等,这个安装问题我们不在这里赘述了
PPO算法
快速上手:如何跑通PPO算法
快速入门:在 GSM8K 数据集上进行 PPO 训练
这部分,主要参考官方文档的quickstart,链接🔗如下:
https://verl.readthedocs.io/en/latest/start/quickstart.html
不过我们在跑通实例的同时,尝试通过源码搞明白数据处理、模型架构以及运行逻辑
GSM8k数据集处理
GSM8k简介
GSM8K(Grade School Math 8K)是一个包含8,500个高质量、语言多样的小学数学文字问题的数据集。该数据集旨在支持需要多步推理的基础数学问题解答任务。
关键特性
- 问题复杂度:每个问题需要2至8个步骤解决
- 数学范围:
- 解决方案主要涉及基础算术运算(加减乘除)
- 所有问题不超过初级代数水平
- 大多数问题无需显式定义变量即可解决
- 答案格式:
- 使用自然语言描述多步推理过程(而非纯数学表达式)
- 包含计算器标注(如
<<48/2=24>>) - 最终答案以
#### 72格式标注
设计目的
- 测试语言模型的逻辑和数学能力
- 研究大语言模型的"内部独白"特性
支持任务与排行榜
- 主要用途:语言模型的数学推理能力基准测试
- 知名应用:LLM Leaderboard等多项评测
语言信息
- 文本语言:英语(BCP-47代码:
en)
数据实例
- main
{"question": "Natalia四月份向48个朋友出售了发夹,五月份的销量减半。问四五月总共销售多少发夹?","answer": "五月销售数量:48/2 = <<48/2=24>>24个\n总销售量:48+24 = <<48+24=72>>72个\n#### 72"
}
- socratic
{"question": "Natalia四月份向48个朋友出售了发夹,五月份的销量减半。问四五月总共销售多少发夹?","answer": "五月销售多少?** 48/2 = <<48/2=24>>24个\n总共销售多少?** 48+24 = <<48+24=72>>72个\n#### 72"
}
数据字段
| 字段名 | 描述 |
|---|---|
question | 小学数学问题文本 |
answer | 包含多步推理、计算标注和最终答案的解决方案 |
数据划分
| 配置类型 | 训练集 | 验证集 |
|---|---|---|
| 标准配置(main) | 7,473 | 1,319 |
| 苏格拉底式(socratic) | 7,473 | 1,319 |
适用场景
- 适合能够解决基础代数问题的初中学生
- 可用于测试模型的多步数学推理能力
- 支持自然语言与数学符号的混合理解研究
源码位置:examples/data_preprocess/gsm8k.py
数据集格式处理与转换
# examples/data_preprocess/gsm8k.py"""
Preprocess the GSM8k dataset to parquet format
"""import argparse
import os
import reimport datasetsfrom verl.utils.hdfs_io import copy, makedirsdef extract_solution(solution_str):solution = re.search("#### (\\-?[0-9\\.\\,]+)", solution_str)assert solution is not Nonefinal_solution = solution.group(0)final_solution = final_solution.split("#### ")[1].replace(",", "")return final_solutionif __name__ == "__main__":parser = argparse.ArgumentParser()parser.add_argument("--local_dir", default="data/procssed/gsm8k")parser.add_argument("--hdfs_dir", default=None)args = parser.parse_args()# data_source = "openai/gsm8k"data_source = "data/gsm8k"dataset = datasets.load_dataset(data_source, "main")train_dataset = dataset["train"]test_dataset = dataset["test"]instruction_following = 'Let\'s think step by step and output the final answer after "####".'# add a row to each data item that represents a unique iddef make_map_fn(split):def process_fn(example, idx):question_raw = example.pop("question")question = question_raw + " " + instruction_followinganswer_raw = example.pop("answer")solution = extract_solution(answer_raw)data = {"data_source": data_source,"prompt": [{"role": "user","content": question,}],"ability": "math","reward_model": {"style": "rule", "ground_truth": solution},"extra_info": {"split": split,"index": idx,"answer": answer_raw,"question": question_raw,},}return datareturn process_fntrain_dataset = train_dataset.map(function=make_map_fn("train"), with_indices=True)test_dataset = test_dataset.map(function=make_map_fn("test"), with_indices=True)local_dir = args.local_dirhdfs_dir = args.hdfs_dirtrain_dataset.to_parquet(os.path.join(local_dir, "train.parquet"))test_dataset.to_parquet(os.path.join(local_dir, "test.parquet"))if hdfs_dir is not None:makedirs(hdfs_dir)copy(src=local_dir, dst=hdfs_dir)print(train_dataset.to_pandas())
这段代码主要对原始数据集转了提取和转换
首先就是question添加了一个推理指令,用来增强按部推理的效果:
"Let's think step by step and output the final answer after '####'."
第二个就是extract_solution用来提取答案,提取后的结果如下:
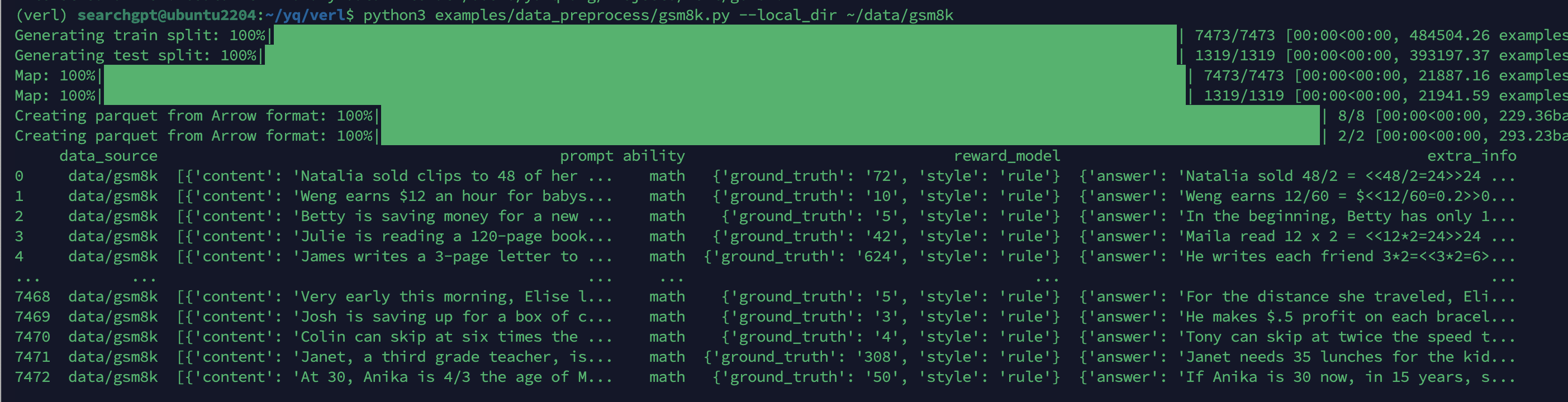
运行PPO
通过verl在gsm8k上运行ppo算法比较简单,就是下面运行脚本,我们对应修改数据集路径即可:
PYTHONUNBUFFERED=1 python3 -m verl.trainer.main_ppo \data.train_files=/data/users/searchgpt/yq/verl/data/gsm8k/train.parquet \data.val_files=/data/users/searchgpt/yq/verl/data/gsm8k/test.parquet \data.train_batch_size=256 \data.max_prompt_length=512 \data.max_response_length=256 \actor_rollout_ref.model.path=/data/users/searchgpt/pretrained_models/Qwen2.5-0.5B-Instruct \actor_rollout_ref.actor.optim.lr=1e-6 \actor_rollout_ref.actor.ppo_mini_batch_size=64 \actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=4 \actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=8 \actor_rollout_ref.rollout.tensor_model_parallel_size=1 \actor_rollout_ref.rollout.gpu_memory_utilization=0.4 \actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=4 \critic.optim.lr=1e-5 \critic.model.path=Qwen/Qwen2.5-0.5B-Instruct \critic.ppo_micro_batch_size_per_gpu=4 \algorithm.kl_ctrl.kl_coef=0.001 \trainer.logger=['console'] \trainer.val_before_train=False \trainer.default_hdfs_dir=null \trainer.n_gpus_per_node=1 \trainer.nnodes=1 \trainer.save_freq=10 \trainer.test_freq=10 \trainer.total_epochs=15 2>&1 | tee verl_demo.log
输出日志如下
(verl) searchgpt@ubuntu2204:~/yq/verl/recipe/ppo$ sh run_ppo_qwen2.5_0.5b.sh
2025-04-21 08:03:52,381 INFO worker.py:1832 -- Started a local Ray instance. View the dashboard at http://127.0.0.1:8265
(TaskRunner pid=176928) {'actor_rollout_ref': {'actor': {'checkpoint': {'contents': ['model',
(TaskRunner pid=176928) 'optimizer',
(TaskRunner pid=176928) 'extra']},
(TaskRunner pid=176928) 'clip_ratio': 0.2,
(TaskRunner pid=176928) 'clip_ratio_c': 3.0,
(TaskRunner pid=176928) 'clip_ratio_high': 0.2,
(TaskRunner pid=176928) 'clip_ratio_low': 0.2,
(TaskRunner pid=176928) 'entropy_coeff': 0,
(TaskRunner pid=176928) 'fsdp_config': {'fsdp_size': -1,
(TaskRunner pid=176928) 'optimizer_offload': False,
(TaskRunner pid=176928) 'param_offload': False,
(TaskRunner pid=176928) 'wrap_policy': {'min_num_params': 0}},
(TaskRunner pid=176928) 'grad_clip': 1.0,
(TaskRunner pid=176928) 'kl_loss_coef': 0.001,
(TaskRunner pid=176928) 'kl_loss_type': 'low_var_kl',
(TaskRunner pid=176928) 'loss_agg_mode': 'token-mean',
(TaskRunner pid=176928) 'optim': {'lr': 1e-06,
(TaskRunner pid=176928) 'lr_warmup_steps': -1,
(TaskRunner pid=176928) 'lr_warmup_steps_ratio': 0.0,
(TaskRunner pid=176928) 'min_lr_ratio': None,
(TaskRunner pid=176928) 'total_training_steps': -1,
(TaskRunner pid=176928) 'warmup_style': 'constant',
(TaskRunner pid=176928) 'weight_decay': 0.01},
(TaskRunner pid=176928) 'ppo_epochs': 1,
(TaskRunner pid=176928) 'ppo_max_token_len_per_gpu': 16384,
(TaskRunner pid=176928) 'ppo_micro_batch_size': None,
(TaskRunner pid=176928) 'ppo_micro_batch_size_per_gpu': 4,
(TaskRunner pid=176928) 'ppo_mini_batch_size': 64,
(TaskRunner pid=176928) 'shuffle': False,
(TaskRunner pid=176928) 'strategy': 'fsdp',
(TaskRunner pid=176928) 'ulysses_sequence_parallel_size': 1,
(TaskRunner pid=176928) 'use_dynamic_bsz': False,
(TaskRunner pid=176928) 'use_kl_loss': False,
(TaskRunner pid=176928) 'use_torch_compile': True},
(TaskRunner pid=176928) 'hybrid_engine': True,
(TaskRunner pid=176928) 'model': {'enable_gradient_checkpointing': True,
(TaskRunner pid=176928) 'external_lib': None,
(TaskRunner pid=176928) 'override_config': {},
(TaskRunner pid=176928) 'path': '/data/users/searchgpt/pretrained_models/Qwen2.5-0.5B-Instruct',
(TaskRunner pid=176928) 'use_liger': False,
(TaskRunner pid=176928) 'use_remove_padding': False},
(TaskRunner pid=176928) 'ref': {'fsdp_config': {'param_offload': False,
(TaskRunner pid=176928) 'wrap_policy': {'min_num_params': 0}},
(TaskRunner pid=176928) 'log_prob_max_token_len_per_gpu': 16384,
(TaskRunner pid=176928) 'log_prob_micro_batch_size': None,
(TaskRunner pid=176928) 'log_prob_micro_batch_size_per_gpu': 4,
(TaskRunner pid=176928) 'log_prob_use_dynamic_bsz': False,
(TaskRunner pid=176928) 'strategy': 'fsdp',
(TaskRunner pid=176928) 'ulysses_sequence_parallel_size': 1},
(TaskRunner pid=176928) 'rollout': {'disable_log_stats': True,
(TaskRunner pid=176928) 'do_sample': True,
(TaskRunner pid=176928) 'dtype': 'bfloat16',
(TaskRunner pid=176928) 'enable_chunked_prefill': True,
(TaskRunner pid=176928) 'enforce_eager': True,
(TaskRunner pid=176928) 'engine_kwargs': {'swap_space': None},
(TaskRunner pid=176928) 'free_cache_engine': True,
(TaskRunner pid=176928) 'gpu_memory_utilization': 0.4,
(TaskRunner pid=176928) 'ignore_eos': False,
(TaskRunner pid=176928) 'load_format': 'dummy_dtensor',
(TaskRunner pid=176928) 'log_prob_max_token_len_per_gpu': 16384,
(TaskRunner pid=176928) 'log_prob_micro_batch_size': None,
(TaskRunner pid=176928) 'log_prob_micro_batch_size_per_gpu': 8,
(TaskRunner pid=176928) 'log_prob_use_dynamic_bsz': False,
(TaskRunner pid=176928) 'max_model_len': None,
(TaskRunner pid=176928) 'max_num_batched_tokens': 8192,
(TaskRunner pid=176928) 'max_num_seqs': 1024,
(TaskRunner pid=176928) 'n': 1,
(TaskRunner pid=176928) 'name': 'vllm',
(TaskRunner pid=176928) 'prompt_length': 512,
(TaskRunner pid=176928) 'response_length': 256,
(TaskRunner pid=176928) 'temperature': 1.0,
(TaskRunner pid=176928) 'tensor_model_parallel_size': 1,
(TaskRunner pid=176928) 'top_k': -1,
(TaskRunner pid=176928) 'top_p': 1,
(TaskRunner pid=176928) 'use_fire_sampling': False,
(TaskRunner pid=176928) 'val_kwargs': {'do_sample': False,
(TaskRunner pid=176928) 'n': 1,
(TaskRunner pid=176928) 'temperature': 0,
(TaskRunner pid=176928) 'top_k': -1,
(TaskRunner pid=176928) 'top_p': 1.0}}},
(TaskRunner pid=176928) 'algorithm': {'adv_estimator': 'gae',
(TaskRunner pid=176928) 'gamma': 1.0,
(TaskRunner pid=176928) 'kl_ctrl': {'horizon': 10000,
(TaskRunner pid=176928) 'kl_coef': 0.001,
(TaskRunner pid=176928) 'target_kl': 0.1,
(TaskRunner pid=176928) 'type': 'fixed'},
(TaskRunner pid=176928) 'kl_penalty': 'kl',
(TaskRunner pid=176928) 'lam': 1.0,
(TaskRunner pid=176928) 'norm_adv_by_std_in_grpo': True,
(TaskRunner pid=176928) 'use_kl_in_reward': False},
(TaskRunner pid=176928) 'critic': {'checkpoint': {'contents': ['model', 'optimizer', 'extra']},
(TaskRunner pid=176928) 'cliprange_value': 0.5,
(TaskRunner pid=176928) 'forward_max_token_len_per_gpu': 32768,
(TaskRunner pid=176928) 'forward_micro_batch_size': None,
(TaskRunner pid=176928) 'forward_micro_batch_size_per_gpu': 4,
(TaskRunner pid=176928) 'grad_clip': 1.0,
(TaskRunner pid=176928) 'model': {'enable_gradient_checkpointing': True,
(TaskRunner pid=176928) 'external_lib': None,
(TaskRunner pid=176928) 'fsdp_config': {'fsdp_size': -1,
(TaskRunner pid=176928) 'optimizer_offload': False,
(TaskRunner pid=176928) 'param_offload': False,
(TaskRunner pid=176928) 'wrap_policy': {'min_num_params': 0}},
(TaskRunner pid=176928) 'override_config': {},
(TaskRunner pid=176928) 'path': '/data/users/searchgpt/pretrained_models/Qwen2.5-0.5B-Instruct',
(TaskRunner pid=176928) 'tokenizer_path': '/data/users/searchgpt/pretrained_models/Qwen2.5-0.5B-Instruct',
(TaskRunner pid=176928) 'use_remove_padding': False},
(TaskRunner pid=176928) 'optim': {'lr': 1e-05,
(TaskRunner pid=176928) 'lr_warmup_steps_ratio': 0.0,
(TaskRunner pid=176928) 'min_lr_ratio': None,
(TaskRunner pid=176928) 'total_training_steps': -1,
(TaskRunner pid=176928) 'warmup_style': 'constant',
(TaskRunner pid=176928) 'weight_decay': 0.01},
(TaskRunner pid=176928) 'ppo_epochs': 1,
(TaskRunner pid=176928) 'ppo_max_token_len_per_gpu': 32768,
(TaskRunner pid=176928) 'ppo_micro_batch_size': None,
(TaskRunner pid=176928) 'ppo_micro_batch_size_per_gpu': 4,
(TaskRunner pid=176928) 'ppo_mini_batch_size': 64,
(TaskRunner pid=176928) 'rollout_n': 1,
(TaskRunner pid=176928) 'shuffle': False,
(TaskRunner pid=176928) 'strategy': 'fsdp',
(TaskRunner pid=176928) 'ulysses_sequence_parallel_size': 1,
(TaskRunner pid=176928) 'use_dynamic_bsz': False},
(TaskRunner pid=176928) 'custom_reward_function': {'name': 'compute_score', 'path': None},
(TaskRunner pid=176928) 'data': {'custom_cls': {'name': None, 'path': None},
(TaskRunner pid=176928) 'filter_overlong_prompts': False,
(TaskRunner pid=176928) 'filter_overlong_prompts_workers': 1,
(TaskRunner pid=176928) 'image_key': 'images',
(TaskRunner pid=176928) 'max_prompt_length': 512,
(TaskRunner pid=176928) 'max_response_length': 256,
(TaskRunner pid=176928) 'prompt_key': 'prompt',
(TaskRunner pid=176928) 'return_raw_chat': False,
(TaskRunner pid=176928) 'return_raw_input_ids': False,
(TaskRunner pid=176928) 'reward_fn_key': 'data_source',
(TaskRunner pid=176928) 'shuffle': True,
(TaskRunner pid=176928) 'tokenizer': None,
(TaskRunner pid=176928) 'train_batch_size': 256,
(TaskRunner pid=176928) 'train_files': '/data/users/searchgpt/yq/verl/data/processed/gsm8k/train.parquet',
(TaskRunner pid=176928) 'truncation': 'error',
(TaskRunner pid=176928) 'val_batch_size': None,
(TaskRunner pid=176928) 'val_files': '/data/users/searchgpt/yq/verl/data/processed/gsm8k/test.parquet',
(TaskRunner pid=176928) 'video_key': 'videos'},
(TaskRunner pid=176928) 'ray_init': {'num_cpus': None},
(TaskRunner pid=176928) 'reward_model': {'enable': False,
(TaskRunner pid=176928) 'forward_max_token_len_per_gpu': 32768,
(TaskRunner pid=176928) 'max_length': None,
(TaskRunner pid=176928) 'micro_batch_size': None,
(TaskRunner pid=176928) 'micro_batch_size_per_gpu': None,
(TaskRunner pid=176928) 'model': {'external_lib': None,
(TaskRunner pid=176928) 'fsdp_config': {'fsdp_size': -1,
(TaskRunner pid=176928) 'param_offload': False,
(TaskRunner pid=176928) 'wrap_policy': {'min_num_params': 0}},
(TaskRunner pid=176928) 'input_tokenizer': '/data/users/searchgpt/pretrained_models/Qwen2.5-0.5B-Instruct',
(TaskRunner pid=176928) 'path': '~/models/FsfairX-LLaMA3-RM-v0.1',
(TaskRunner pid=176928) 'use_remove_padding': False},
(TaskRunner pid=176928) 'reward_manager': 'naive',
(TaskRunner pid=176928) 'strategy': 'fsdp',
(TaskRunner pid=176928) 'ulysses_sequence_parallel_size': 1,
(TaskRunner pid=176928) 'use_dynamic_bsz': False},
(TaskRunner pid=176928) 'trainer': {'balance_batch': True,
(TaskRunner pid=176928) 'critic_warmup': 0,
(TaskRunner pid=176928) 'default_hdfs_dir': None,
(TaskRunner pid=176928) 'default_local_dir': 'checkpoints/verl_examples/gsm8k',
(TaskRunner pid=176928) 'del_local_ckpt_after_load': False,
(TaskRunner pid=176928) 'experiment_name': 'gsm8k',
(TaskRunner pid=176928) 'log_val_generations': 0,
(TaskRunner pid=176928) 'logger': ['console'],
(TaskRunner pid=176928) 'max_actor_ckpt_to_keep': None,
(TaskRunner pid=176928) 'max_critic_ckpt_to_keep': None,
(TaskRunner pid=176928) 'n_gpus_per_node': 1,
(TaskRunner pid=176928) 'nnodes': 1,
(TaskRunner pid=176928) 'project_name': 'verl_examples',
(TaskRunner pid=176928) 'ray_wait_register_center_timeout': 300,
(TaskRunner pid=176928) 'resume_from_path': None,
(TaskRunner pid=176928) 'resume_mode': 'auto',
(TaskRunner pid=176928) 'save_freq': 10,
(TaskRunner pid=176928) 'test_freq': 10,
(TaskRunner pid=176928) 'total_epochs': 15,
(TaskRunner pid=176928) 'total_training_steps': None,
(TaskRunner pid=176928) 'val_before_train': False}}
(TaskRunner pid=176928) [validate_config] All configuration checks passed successfully!
中间日志
下面是训练第287步数时候的输出日志:
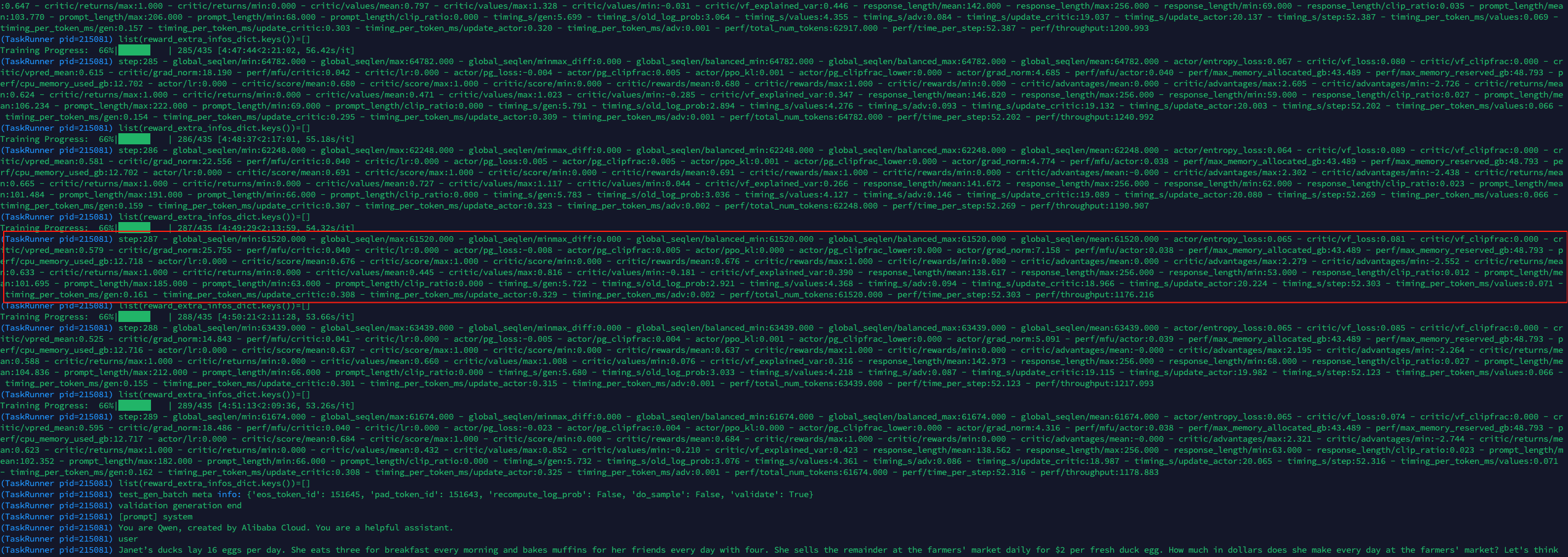
之前稍微了解过ppo原理,但是这个指标还是比较多的,有几十个,为了方便我们先用gpt4o来解释一下:
基本训练信息
- step: 287 - 当前训练的步数或迭代次数
- global_seqlen/mean: 61520.000 - 批次中序列的平均长度(token数量)
Actor(策略网络)相关指标
- actor/pg_loss: -0.008 - 策略梯度损失,负值表示策略在改进
- actor/entropy_loss: 0.065 - 熵损失,用于鼓励探索和多样性
- actor/pg_clipfrac: 0.005 - 被裁剪的策略梯度比例,PPO算法特有的指标
- actor/ppo_kl: 0.000 - 新旧策略之间的KL散度,衡量策略更新的幅度
- actor/grad_norm: 7.158 - Actor网络梯度的范数,表示梯度大小
- actor/lr: 0.000 - Actor网络的学习率
Critic(价值网络)相关指标
- critic/vf_loss: 0.081 - 价值函数损失,衡量Critic预测准确度
- critic/vf_clipfrac: 0.000 - 被裁剪的价值函数比例
- critic/vpred_mean: 0.579 - 价值预测的平均值
- critic/grad_norm: 25.755 - Critic网络梯度的范数
- critic/vf_explained_var: 0.390 - 价值函数解释方差,衡量预测质量
奖励相关指标
- critic/score/mean: 0.676 - 平均得分或奖励
- critic/score/max: 1.000 - 最高得分
- critic/score/min: 0.000 - 最低得分
- critic/advantages/mean: 0.000 - 平均优势函数值
- critic/advantages/max: 2.279 - 最大优势函数值
- critic/advantages/min: -2.552 - 最小优势函数值
- critic/returns/mean: 0.633 - 平均回报值
性能指标
- perf/mfu/actor: 0.038 - Actor网络的模型FLOPS利用率
- perf/mfu/critic: 0.040 - Critic网络的模型FLOPS利用率
- perf/max_memory_allocated_gb: 43.489 - 分配的最大GPU内存(GB)
- perf/max_memory_reserved_gb: 48.793 - 保留的最大GPU内存(GB)
- perf/cpu_memory_used_gb: 12.718 - 使用的CPU内存(GB)
- perf/throughput: 1176.216 - 吞吐量,每秒处理的token数
时间相关指标
- timing_s/gen: 5.722 - 生成文本所用的时间(秒)
- timing_s/update_critic: 18.966 - 更新Critic网络所用的时间(秒)
- timing_s/update_actor: 20.224 - 更新Actor网络所用的时间(秒)
- timing_s/step: 52.303 - 每步训练的总时间(秒)
序列和响应长度统计
- response_length/mean: 138.617 - 生成的响应的平均长度
- response_length/max: 256.000 - 生成的响应的最大长度
- response_length/clip_ratio: 0.012 - 被截断的响应比例
- prompt_length/mean: 101.695 - 输入提示的平均长度
这些指标共同反映了PPO强化学习训练的状态、质量和性能,特别是在训练语言模型时非常有用。
中间问题
- ray启动报错
[2025-01-25 08:22:57,421 E 759 759] core_worker.cc:496: Failed to register worker to Raylet: IOError: [RayletClient] Unable to register worker with raylet. Failed to read data from the socket: End of file worker_id=01000000ffffffffffffffffffffffffffffffffffffffffffffffffhttps://github.com/Jiayi-Pan/TinyZero/issues/7
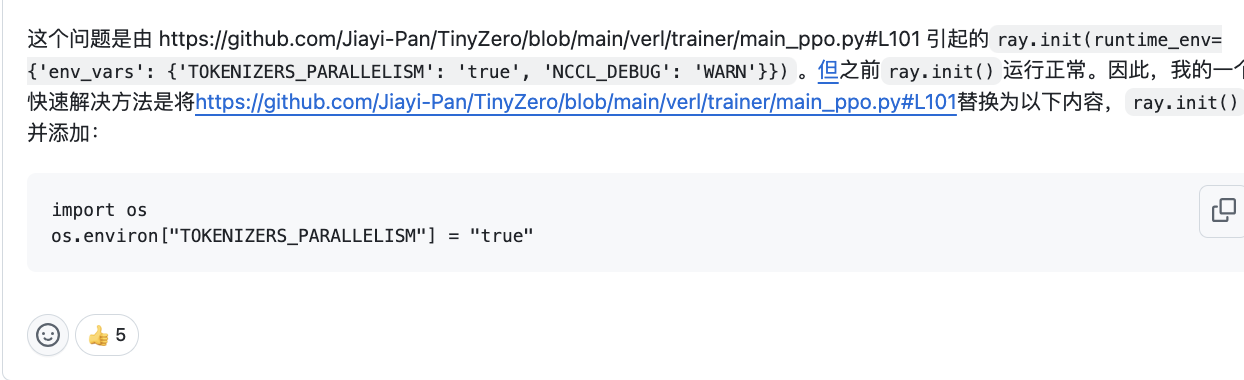
https://github.com/Jiayi-Pan/TinyZero/blob/main/verl/trainer/main_ppo.py#L101
- Qwen2ForCausalLM failed to be inspected
ValueError: Model architectures ['Qwen2ForCausalLM'] failed to be inspected. Please check the logs for more details.
安装低版本vllm
pip install vllm==0.6.3.post1