研究夜间灯光数据在估计出行需求方面的潜力
研究夜间灯光数据在估计出行需求方面的潜力
原文:Investigating the Potential of Nighttime Light Data to Estimate Travel Demand
1.摘要
以共享单车出行需求(BSTD)为例,探讨夜间灯光(NTL)数据在优化预测性能和替代土地利用因素方面的潜力。通过逐步回归确定自变量集合,并使用五种集成学习和决策树驱动的机器学习算法进行预测分析,得出以下结论:Adaboost和GBDT算法在预测效果上优于其他算法;引入NTL数据后,所有方法的预测性能均明显优化,GBDT在减少均方误差(MSE)方面表现最佳;在引入NTL数据后,土地利用因素在预测BSTD时不再起作用,NTL数据已涵盖土地利用因素的作用。
2.引言
- 研究背景:出行需求预测是一个不断发展和创新的领域,对于多种交通模式和不同地区的应用具有重要意义。随着城市计算和数据收集技术的进步,城市交通大数据的数量和质量不断提高,出行需求预测本质上是时空数据预测。
- 研究现状:传统的出行需求预测方法包括离散选择模型、回归模型等,但这些方法在处理大数据时代的需求时存在局限性。机器学习方法如增强型KNN、高斯条件随机场模型等被引入,而深度学习在捕捉出行需求的非线性特征方面具有更强的能力。然而,深度学习的“黑箱”属性使其在解释输入变量方面存在不足。
- 研究意义:土地利用因素是生成出行需求的基础,但其复杂性、不确定性和非线性关系使得传统方法难以准确揭示需求与土地利用之间的深层关系。此外,土地利用数据的实时获取复杂且耗时。因此,探索能否用简单易得的数据(如NTL数据)替代复杂土地利用因素,对于提高预测精度和模型的适用性具有重要意义。
3.文献综述
- 旅行需求预测方法:
- 基于传统方法:普通回归模型是早期出行需求预测建模中最受欢迎的方法,如嵌套逻辑模型、多元回归模型等。此外,结合回归模型和空间相关性的方法(如地理加权回归、时空加权回归等)也在出行需求预测中发挥重要作用。
- 基于机器学习方法:机器学习方法在出行需求预测中的应用日益增多,如增强型KNN算法、高斯条件随机场模型等。这些方法通过组合传统机器学习算法的变体来提高预测精度和稳定性。
- 基于深度学习方法:深度学习在捕捉出行需求的非线性特征方面具有显著优势,如神经网络在预测短期汽车共享需求、交通流量和供需差距方面发挥重要作用。此外,图算法在深度学习中的应用也受到越来越多的关注。
- NTL数据的应用:
- 经济水平估算:NTL数据可用于估算社会经济指标,如人口、GDP、贫困程度等。
- 城市空间结构感知:NTL数据能够反映不同区域的人类活动强度,帮助识别单中心和多中心城市结构的变化,并为未来城市扩张监测提供参考。
- 安全事件评估:NTL数据在安全事件发生前后的变化可以反映事件的程度和范围,如自然灾害后的损失和恢复情况。
4. 数据和方法
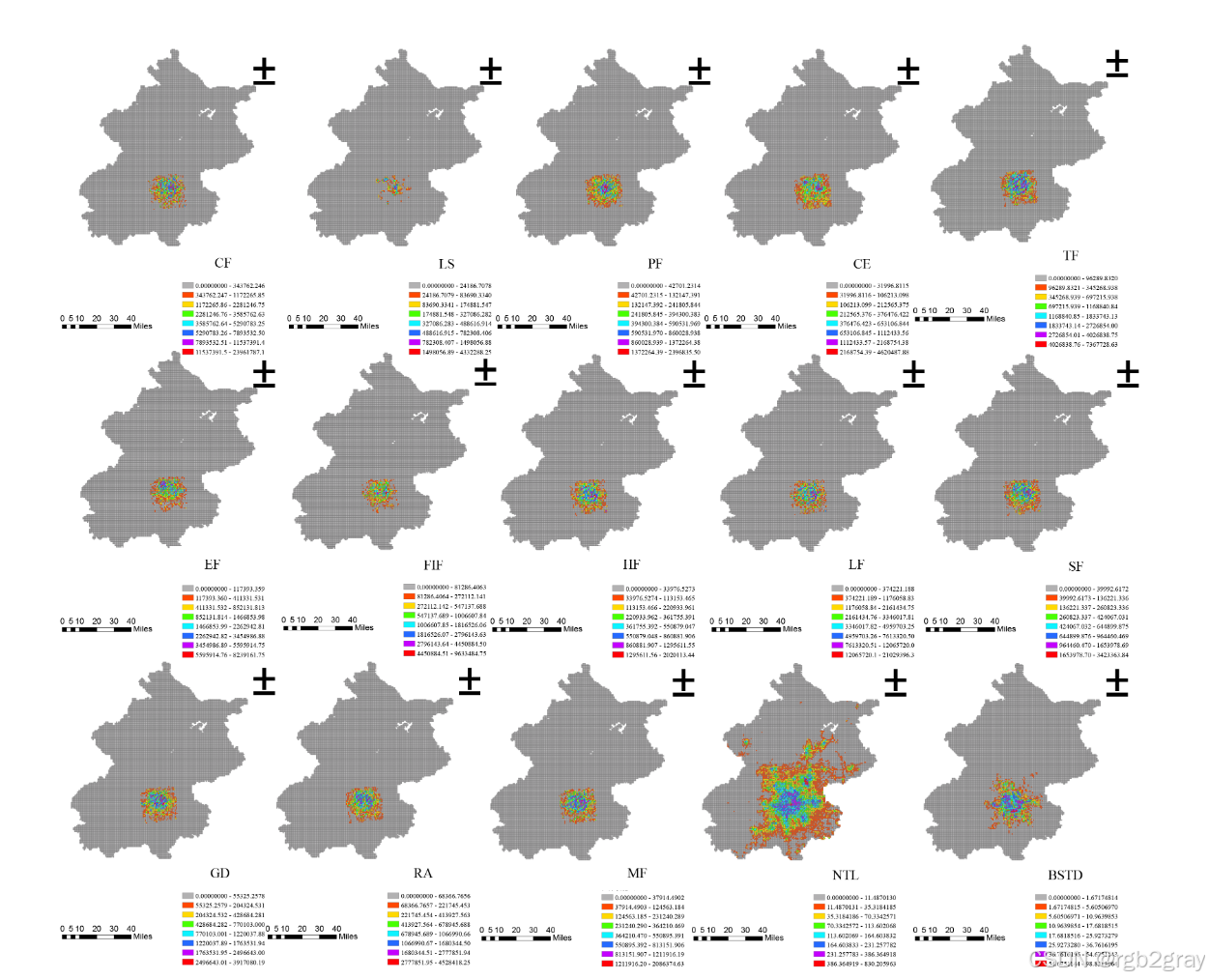
- 数据收集与描述:
- 土地利用数据:使用地理兴趣点(POI)来表达土地利用,将POI分为13类,以500×500米网格单元内POI的数量作为分析单位,用不同POI之间的量化关系来代表土地利用类型的差异。
- NTL数据:从国家地球系统科学数据中心收集,数据类型为栅格,分辨率500米。对原始数据进行标准化处理、投影转换和合并等操作,以实现最终数据的集成。
- 机器学习预测方法:介绍了五种机器学习算法(随机森林、Adaboost、GBDT、ExtraTrees、Catboost)的预测步骤和原理,这些算法可以解释交通需求影响因素在预测性能中的相对重要性,从而提高出行需求预测模型的可解释性。
接下来我们深入探讨一下第四部分“模型规范和性能指标”和第五部分“模型结果与讨论”的内容。
5. 模型规范和性能指标
模型规范
为了获得最佳模型,作者通过基于遗传算法的启发式优化方法对预测旅行需求的模型性能进行优化。遗传算法的参数设置如下:
- 初始种群数量:50
- 最大迭代次数:150
- 变异概率:0.01
- 交叉概率:0.5
通过训练后,大多数模型的参数如表1所示。表1中列出了五种机器学习算法(RF、Adaboost、GBDT、ExtraTrees、Catboost)的训练时间、数据划分比例、是否进行数据洗牌和交叉验证,以及基本学习器类型。其中,Catboost的训练时间明显长于其他算法,而其他算法的训练时间相对较短。所有算法的数据划分比例均为0.7,即70%的数据用于训练,30%的数据用于测试。此外,所有算法均未进行数据洗牌和交叉验证,基本学习器均为决策树(DT)。
性能指标
作者采用了多种性能指标(PI)来评估预测的旅行需求与实际旅行需求之间的一致性,包括R²、RMSE、MAE、MSE和MAPE。这些指标的计算公式如下:
- R²:表示机器学习算法对旅行需求实际值变化的解释程度。
- MSE:衡量预测值与实际值之间的差异。
- RMSE:均方根误差,显示预测值与实际值之间的差异。
- MAE:平均绝对误差,量化预测值与实际值之间的绝对误差。
- MAPE:平均绝对百分比误差,衡量预测误差相对于实际值的百分比。
为了进一步测试NTL数据优化机器学习方法的潜力,作者引入了性能指标变化率(CPI),通过比较引入NTL数据前后的性能指标值来表示模型优化的相对重要性和替代土地利用因素的能力。CPI的计算公式如下:
CPI = PI after − PI before PI before \text{CPI} = \frac{\text{PI}_{\text{after}} - \text{PI}_{\text{before}}}{\text{PI}_{\text{before}}} CPI=PIbeforePIafter−PIbefore
其中, P I b e f o r e PI_{before} PIbefore表示引入NTL数据前的性能指标值, P I a f t e r PI_{after} PIafter表示引入NTL数据后的性能指标值。
6. 模型结果与讨论
变量筛选结果
作者采用逐步回归方法筛选出对共享单车出行需求(BSTD)有显著影响的土地利用因素。通过逐步回归模型结果表,确定了保留的变量,包括生活设施(LF)、医疗设施(MF)、公共设施(PF)、餐饮设施(CF)、金融和保险设施(FIF)、政府部门(GD)、酒店设施(HF)、教育设施(EF)和景观(LS)。同时,删除了经度、纬度、公司企业(CE)、交通设施(TF)、体育设施(SF)和住宅区(RA)等变量。F检验结果表明,保留变量的显著性p值为0.000***,拒绝了保留土地利用因素回归系数为0的原假设,表明这些保留的POI变量满足要求,可用于进一步研究。
机器学习方法的性能评估
作者比较了五种机器学习算法在训练集上的预测精度和稳定性。结果显示,Adaboost和GBDT在训练数据上的表现优于其他算法,具有最高的R²、最低的RMSE和最低的绝对MAPE。例如,GBDT的平均RMSE为122710,Adaboost为314025,而其他算法的RMSE均高于这些值。在R²方面,Adaboost和GBDT的平均R²均在0.99以上,能够很好地解释实际BSTD的变化趋势,而随机森林(RF)仅能解释82.90%的实际BSTD变化趋势。
在测试集上,尽管这些算法的预测精度和稳定性仍需加强,但Adaboost和GBDT仍然表现出较好的性能。例如,Adaboost和GBDT在测试数据中的RMSE分别为9189420和10512399,MAPE分别为68.3和70.309,均低于其他算法。然而,测试数据中实际值与预测值之间的误差仍然较大,表明这些机器学习方法的稳定性需要进一步提高。
不同土地利用因素的相对重要性
在未考虑NTL数据时,教育设施(EF)在大多数机器学习算法中对预测BSTD的相对贡献最高,尤其在GBDT算法中达到23.10%。金融和保险设施(FIF)在GBDT算法中的贡献为17.10%,在AdaBoost算法中为12.40%。医疗设施(MF)和餐饮设施(CF)在GBDT中的影响超过9%,在AdaBoost中超过12%。相比之下,公共设施(PF)、酒店设施(HF)、生活设施(LF)等的预测能力较弱,它们在GBDT算法中的相对贡献仅约为7%。
在引入NTL数据后,所有土地利用因素的相对贡献在所有机器学习算法中均降低至0或接近0,而NTL数据的相对贡献接近或等于100%。即使在表现最差的算法中,NTL的相对贡献也分别达到84.20%(Catboost)和92.60%(ExtraTrees),表明NTL数据替代了土地利用因素,提高了预测精度和稳定性。
NTL数据优化预测模型的潜力
引入NTL数据后,所有机器学习方法的预测性能均得到显著提高,RMSE、MAPE等指标均有所降低。例如,GBDT在训练集上的RMSE降低至304,Adaboost为6323;在测试集上,GBDT的RMSE降低至3,792,538,Adaboost为3,975,337。MAPE在训练集上变化显著,最大值降低至<1.00,最小值接近0。特别是GBDT在训练集上的MAPE仅为0.0100,在Adaboost中为0.0500。
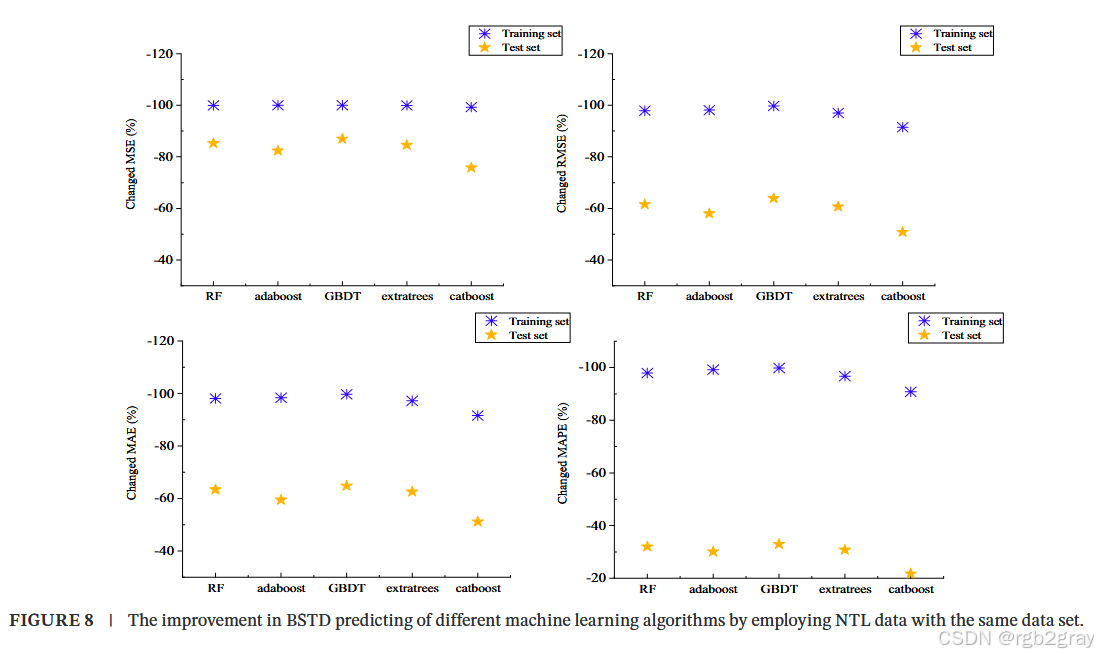
图8量化了引入NTL数据后不同机器学习算法在预测BSTD时的准确性和稳定性的提高。训练集上的性能指标下降幅度均超过90%,例如GBDT在训练集上的MSE减少百分比为-99.99%,在测试集上为-86.985%。尽管测试集上的改进不如训练集显著,但所有算法的预测误差均大幅降低,表明NTL数据在激发机器学习潜力和优化BSTD预测的准确性和稳定性方面发挥了重要作用。
7.结论
- 研究结论:
- 通过逐步回归确定了在引入NTL数据之前的土地利用因素的最优线性回归模型,筛选出重要的土地利用变量。
- 在比较的机器学习算法中,Adaboost和GBDT在网格尺度上的表现优于其他算法,具有最高的R²和最低的RMSE及绝对MAPE,可有效应用于北京市BSTD的估计。
- 在引入NTL数据建模之前,EF在预测共享单车出行需求中起着关键作用,其在GBDT算法中的相对贡献超过20%。
- 引入NTL数据后,五种机器学习方法均能优化BSTD预测,降低RMSE、MAPE等指标。GBDT在减少MSE方面表现最佳。
- 在引入NTL数据后,土地利用因素在预测BSTD时不再起作用,NTL数据取代了土地利用因素,提高了预测精度和稳定性。
- 研究贡献与创新:
- 可靠性提升:使用NTL数据提高了预测模型的精度,为其他交通需求预测提供了提高效率的解决方案。
- 理论创新:首次证明NTL数据可以替代土地利用数据用于BSTD预测,间接表明NTL数据包含土地利用信息和有助于预测交通需求的信息,为交通工程提供了有效补充。
- 数据易得性:与土地利用数据相比,NTL数据是开放且更易获取的,对于未收集土地利用数据的城市或地区,NTL数据使得交通需求预测更加容易。
- 研究局限与展望:
- 需要分析特定影响因素对交通需求预测的机械作用,以解释为何引入NTL变量可以显著提高每个机器模型的预测精度。
- 应关注预测模型中的时间异质性,分析NTL在预测BSTD时在不同季节和工作日/非工作日的准确性是否有所不同。
- 研究仅部署了土地利用和NTL数据来建模BSTD,忽略了其他客观因素(如天气和突发事件)的影响。未来研究可以结合更多因素(如天气紧急情况)使用可解释的机器学习来分析不同时段影响因素的机械作用。
- 本文使用的机器学习模型的泛化能力有限,导致轻微过拟合现象。未来可以使用泛化能力更强的机器学习模型,进一步探讨训练集和测试集预测误差的差异,以确定“前后”实验中轻微过拟合现象的机制。
8. 应用
当然可以!以下是一些与文章相关的Python代码示例,这些代码可以帮助你理解如何使用机器学习算法来预测共享单车出行需求(BSTD),并评估夜间灯光(NTL)数据的作用。我们将使用常见的机器学习库,如scikit-learn,来实现这些算法。
1. 数据预处理和加载
首先,我们需要加载和预处理数据。假设我们有一个包含土地利用因素和NTL数据的数据集。
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler# 加载数据
data = pd.read_csv('bike_sharing_demand.csv')# 假设数据集包含以下列:BSTD, LF, MF, PF, CF, FIF, GD, HF, EF, LS, NTL
X = data[['LF', 'MF', 'PF', 'CF', 'FIF', 'GD', 'HF', 'EF', 'LS', 'NTL']]
y = data['BSTD']# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 标准化特征
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
2. 机器学习模型训练和评估
接下来,我们使用不同的机器学习算法来训练模型,并评估它们的性能。
from sklearn.ensemble import RandomForestRegressor, AdaBoostRegressor, GradientBoostingRegressor, ExtraTreesRegressor
from catboost import CatBoostRegressor
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score# 定义模型
models = {'Random Forest': RandomForestRegressor(n_estimators=100, random_state=42),'AdaBoost': AdaBoostRegressor(n_estimators=100, random_state=42),'GBDT': GradientBoostingRegressor(n_estimators=100, random_state=42),'ExtraTrees': ExtraTreesRegressor(n_estimators=100, random_state=42),'CatBoost': CatBoostRegressor(iterations=100, learning_rate=0.1, depth=6, random_state=42, verbose=False)
}# 训练和评估模型
results = {}
for model_name, model in models.items():# 训练模型model.fit(X_train, y_train)# 预测y_pred_train = model.predict(X_train)y_pred_test = model.predict(X_test)# 评估性能mse_train = mean_squared_error(y_train, y_pred_train)mse_test = mean_squared_error(y_test, y_pred_test)rmse_train = np.sqrt(mse_train)rmse_test = np.sqrt(mse_test)mae_train = mean_absolute_error(y_train, y_pred_train)mae_test = mean_absolute_error(y_test, y_pred_test)r2_train = r2_score(y_train, y_pred_train)r2_test = r2_score(y_test, y_pred_test)results[model_name] = {'MSE (Train)': mse_train,'MSE (Test)': mse_test,'RMSE (Train)': rmse_train,'RMSE (Test)': rmse_test,'MAE (Train)': mae_train,'MAE (Test)': mae_test,'R² (Train)': r2_train,'R² (Test)': r2_test}# 打印结果
for model_name, metrics in results.items():print(f"Model: {model_name}")for metric, value in metrics.items():print(f" {metric}: {value:.4f}")print()
3. 特征重要性分析
我们可以分析不同特征(包括NTL数据)对模型预测的贡献。
import matplotlib.pyplot as plt# 选择一个模型进行特征重要性分析(例如 GBDT)
model = models['GBDT']
feature_importances = model.feature_importances_# 特征名称
feature_names = ['LF', 'MF', 'PF', 'CF', 'FIF', 'GD', 'HF', 'EF', 'LS', 'NTL']# 绘制特征重要性
plt.figure(figsize=(10, 6))
plt.barh(feature_names, feature_importances)
plt.xlabel('Feature Importance')
plt.title('Feature Importance in GBDT Model')
plt.show()
4. 引入NTL数据前后的性能对比
为了评估NTL数据对模型性能的提升,我们可以比较引入NTL数据前后的模型性能。
# 不使用NTL数据
X_no_ntl = data[['LF', 'MF', 'PF', 'CF', 'FIF', 'GD', 'HF', 'EF', 'LS']]
X_train_no_ntl, X_test_no_ntl, y_train_no_ntl, y_test_no_ntl = train_test_split(X_no_ntl, y, test_size=0.3, random_state=42)
X_train_no_ntl = scaler.fit_transform(X_train_no_ntl)
X_test_no_ntl = scaler.transform(X_test_no_ntl)# 训练和评估模型(不使用NTL数据)
results_no_ntl = {}
for model_name, model in models.items():model.fit(X_train_no_ntl, y_train_no_ntl)y_pred_train = model.predict(X_train_no_ntl)y_pred_test = model.predict(X_test_no_ntl)mse_train = mean_squared_error(y_train_no_ntl, y_pred_train)mse_test = mean_squared_error(y_test_no_ntl, y_pred_test)rmse_train = np.sqrt(mse_train)rmse_test = np.sqrt(mse_test)mae_train = mean_absolute_error(y_train_no_ntl, y_pred_train)mae_test = mean_absolute_error(y_test_no_ntl, y_pred_test)r2_train = r2_score(y_train_no_ntl, y_pred_train)r2_test = r2_score(y_test_no_ntl, y_pred_test)results_no_ntl[model_name] = {'MSE (Train)': mse_train,'MSE (Test)': mse_test,'RMSE (Train)': rmse_train,'RMSE (Test)': rmse_test,'MAE (Train)': mae_train,'MAE (Test)': mae_test,'R² (Train)': r2_train,'R² (Test)': r2_test}# 打印结果(不使用NTL数据)
for model_name, metrics in results_no_ntl.items():print(f"Model: {model_name} (Without NTL)")for metric, value in metrics.items():print(f" {metric}: {value:.4f}")print()# 比较引入NTL数据前后的性能
for model_name in models.keys():print(f"Model: {model_name}")print(f" R² (Train) - With NTL: {results[model_name]['R² (Train)']:.4f}, Without NTL: {results_no_ntl[model_name]['R² (Train)']:.4f}")print(f" R² (Test) - With NTL: {results[model_name]['R² (Test)']:.4f}, Without NTL: {results_no_ntl[model_name]['R² (Test)']:.4f}")print(f" RMSE (Test) - With NTL: {results[model_name]['RMSE (Test)']:.4f}, Without NTL: {results_no_ntl[model_name]['RMSE (Test)']:.4f}")print()
5. 性能指标变化率(CPI)
最后,我们可以计算引入NTL数据后的性能指标变化率(CPI)。
# 计算CPI
for model_name in models.keys():mse_train_before = results_no_ntl[model_name]['MSE (Train)']mse_train_after = results[model_name]['MSE (Train)']mse_test_before = results_no_ntl[model_name]['MSE (Test)']mse_test_after = results[model_name]['MSE (Test)']cpi_train = (mse_train_after - mse_train_before) / mse_train_before * 100cpi_test = (mse_test_after - mse_test_before) / mse_test_before * 100print(f"Model: {model_name}")print(f" CPI (MSE) - Train: {cpi_train:.2f}%")print(f" CPI (MSE) - Test: {cpi_test:.2f}%")print()