《Learning Langchain》阅读笔记5-RAG(1)
在上一章中,我们学习了使用 LangChain 创建 LLM 应用程序的重要构建块。
我们还构建了一个简单的 AI 聊天机器人,它由发送给模型的提示和模型生成的输出组成。但是,这个简单的聊天机器人存在一些主要限制。
如果你的使用场景需要模型未曾训练过的知识怎么办?
例如,假设你想使用 AI 询问有关公司的问题,但信息包含在私人 PDF 或其他类型的文档中。
虽然我们已经看到模型提供商正在丰富他们的训练数据集,以包含世界上越来越多的公共信息(无论以何种格式存储),但 LLM 的知识库仍然存在两个主要限制:
-
Private data:私人数据
根据定义,不公开的信息不包含在LLMs的训练数据中。
-
Current events:当前事件
训练 LLM 是一个成本高昂且耗时的过程,可能需要数年时间,其中数据收集是第一步。这导致了所谓的knowledge cutoff知识截止,即 LLM 对于某一日期之后的现实世界事件一无所知。
这个日期通常是训练数据集最终确定的时间点。这个时间点可能距离现在几个月,也可能是几年前,取决于具体的模型。比如最新版的ChatGPT 4o知识截止时间为2024年6月
无论是哪种情况,模型很可能会产生幻觉(即生成误导性或错误的信息),并给出不准确的回答。
仅通过调整提示词prompts无法解决这个问题,因为它依赖于模型当前的知识。
The Goal: Picking Relevant Context for LLMs
目标:为 LLMs 选择相关上下文
假如我们提供给LLM的唯一的私人数据或者当前现实数据只是一到两页的文本,那么我们只需要将整个文本包含在prompts中发送给大模型就好,LLM就能获得这些信息。
但是如果我们需要提供很多数据给LLM呢?假如每次这些数据大小已经超出了LLM每次能收取的token数上限呢?
所以问题在于:
你每次调用模型时,要从大量文本中挑出一小部分最相关的内容,来回答用户的问题。
换句话说:
如何用模型的帮助,从很多信息中挑出最有用的那部分?
这其实是信息筛选的过程,也是构建高效 LLM 应用的关键一步。
所以在本章和下一章,我们将分两步解决这个挑战:
-
为你的文档建立索引,也就是说,对它们进行预处理,这样你的应用程序就可以轻松地找到每个问题最相关的文档。
-
从索引中检索此外部数据,并将其用作 LLM 的上下文,以根据你的数据生成准确的输出
这种技术称为检索增强生成(RAG)。
这一章,我们将重点介绍索引 indexing,这是第一步,包括如何将你的文档预处理为可以被 LLMs 理解和搜索的格式:
让我们假设一个例子:
假设你想使用 LLM 分析特斯拉 2022 年年度报告中的财务表现和风险,该报告以 PDF 格式存储为文本。你的目标是能够提出类似“特斯拉在 2022 年面临哪些关键风险”的问题,并根据文档中风险因素部分的上下文得到类似人类的回答。
要实现这一目标,你需要采取以下四个关键步骤(图2-1):
- 从文档中提取文本。
- 将文本分成可管理的块。
- 将文本转换为计算机可以理解的数字。
- 将这些文本的数字表示存储在某个地方,以便快速检索文档的相关部分以回答给定的问题。
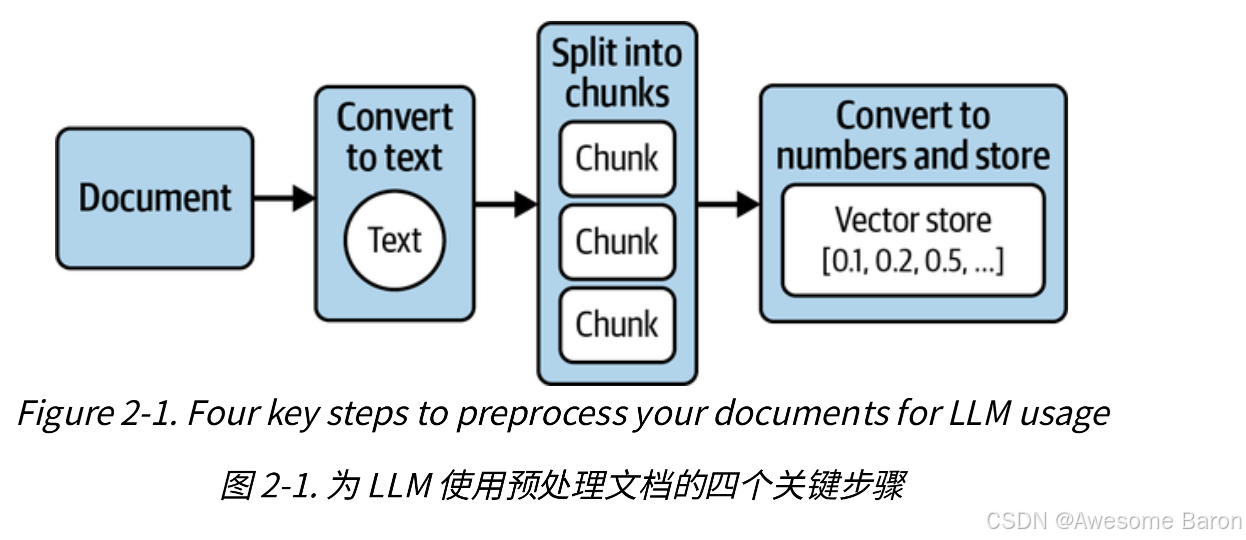
这个过程被称为“ ingestion”。
ingestion就是将文档转换为计算机可以理解和分析的数字,并将它们存储在一种特殊类型的数据库中,以实现高效检索。
这些数字正式称为embeddings,这种特殊类型的数据库称为vector store向量存储。
Embeddings: Converting Text to Numbers 嵌入:将文本转换为数字
Embedding嵌入是指将文本表示为(长)数字序列。这是一种有损表示,
也就是说,你无法从这些数字序列中恢复原始文本,因此通常同时存储原始文本和数字表示。
考虑以下三个词:狮子、宠物和狗。直觉上,哪两个词在第一眼看上去有相似之处?明显的答案是宠物和狗。
但计算机没有能力利用这种直觉或对英语语言的细微理解。为了让计算机区分狮子、宠物或狗,你需要能够将它们翻译成计算机语言,即数字(图2-2)。
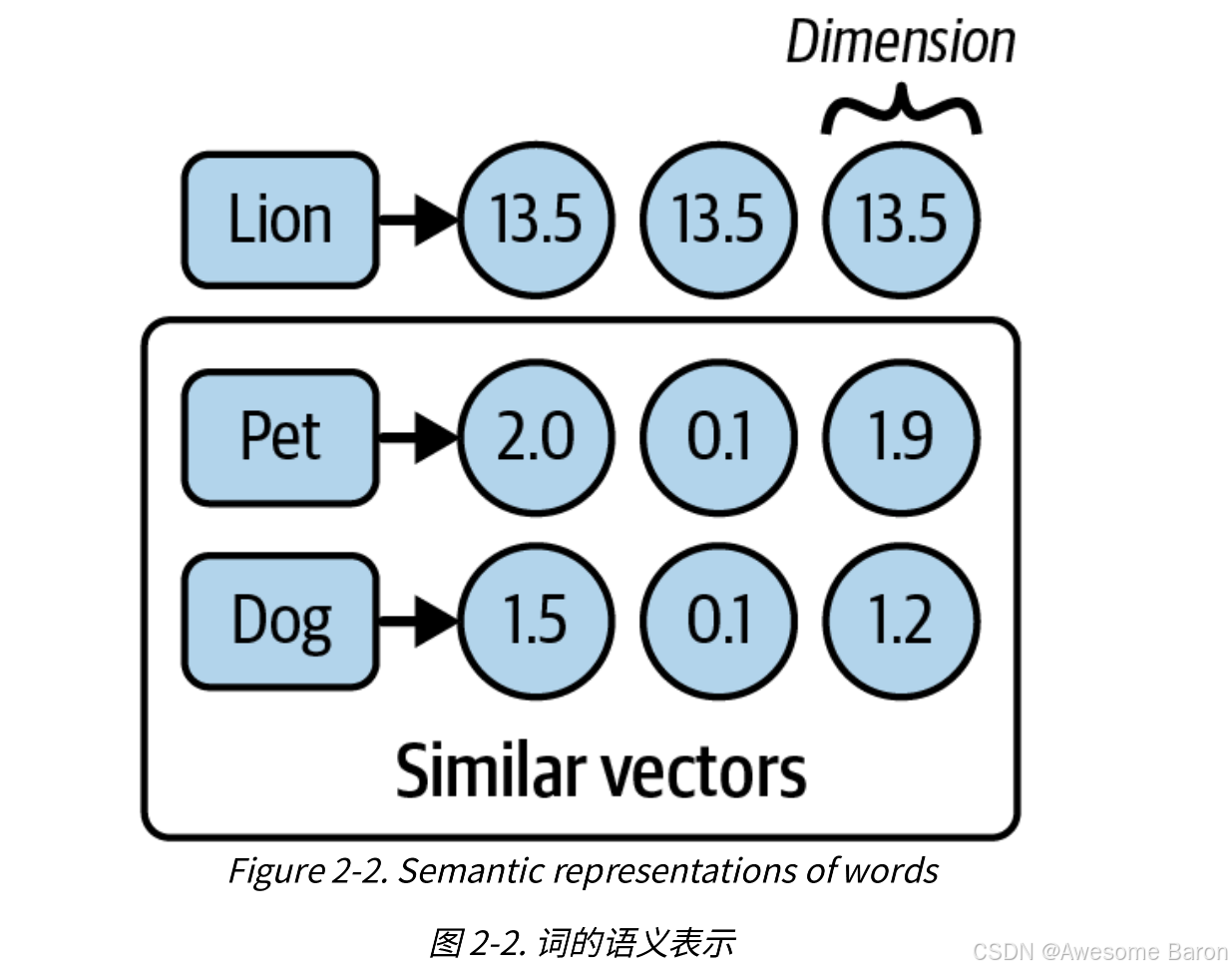
如果我们在三维空间中绘制这些向量,它看起来像图2-3。
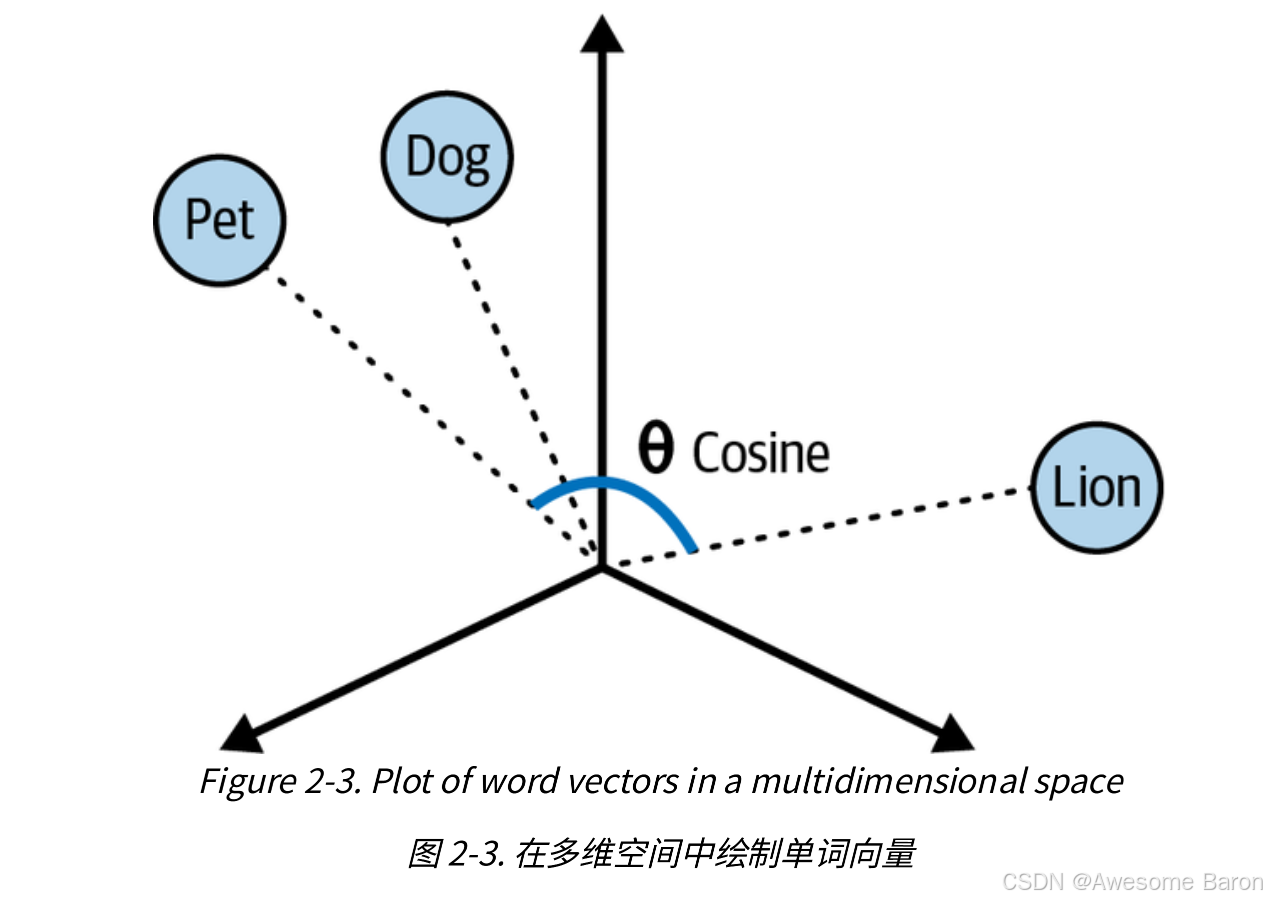
图 2-3 显示宠物和狗的向量之间的距离比狮子的向量更接近彼此。我们还可以观察到,每个向量之间的角度取决于它们之间的相似程度。
例如,单词“宠物”和“狮子”之间的角度比“宠物”和“狗”之间的角度更宽,这表明后两个单词对之间的相似性更大。
两个向量之间的角度越窄或距离越短,它们之间的相似性就越接近。
在多维空间中,计算两个向量之间相似程度的有效方法被称为余弦相似度cosine similarity。
余弦相似度计算向量的点积,并将其除以它们的模的乘积,输出一个在-1和1之间的数字,其中0表示向量之间没有相关性,-1表示它们绝对不相似,1表示它们绝对相似。
下面是余弦相似度公式:
cos ( θ ) = A ⃗ ⋅ B ⃗ ∥ A ⃗ ∥ ∥ B ⃗ ∥ \cos(\theta) = \frac{\vec{A} \cdot \vec{B}}{\|\vec{A}\| \|\vec{B}\|} cos(θ)=∥A∥∥B∥A⋅B因此,在我们的三个单词的情况下,宠物和狗之间的余弦相似度可以是0.75,但宠物和狮子之间的余弦相似度可能是0.1。
Converting Your Documents into Text:将文档转换为文本
正如本章开头提到的,预处理文档的第一步是将其转换为文本。为了实现这一点,你需要构建逻辑来解析并提取文档内容,同时尽可能减少信息损失。
幸运的是,LangChain 提供了名为 document loaders(文档加载器) 的工具,它们可以处理解析逻辑,并使你能够从各种数据源中“加载”数据,转换为一个 Document 类对象,该对象包含文本及其相关的元数据metadata。
举例:一个简单的.txt文件,我们可以简单地导入LangChain TextLoader类来提取文本,如下所示:
from langchain_community.document_loaders import TextLoaderloader = TextLoader("./test.txt")
loader.load()
输出为:
ModuleNotFoundError: No module named 'langchain_community'
看到报错了,原因是:
你使用了 from langchain_community.document_loaders import TextLoader,但你的环境里 没有安装名为 langchain_community 的模块。这个模块是 LangChain 0.1.13(2024年初)之后的新结构,把一些组件拆分到了子模块中(比如 loaders、tools 等),所以要单独安装。
运行以下命令:
pip install -U langchain-community
现在我们来试试:
from langchain_community.document_loaders import TextLoaderloader = TextLoader("./test.txt", encoding="utf-8")
loader.load()
输出为:
[Document(metadata={'source': './test.txt'}, page_content='The previous code block assumes that you have a file named test.txt in your current directory.Usage of all LangChain document loaders follows a similar pattern:上面的代码块假定当前目录中有一个名为 test.txt 的文件。所有 LangChain 文档加载器的用法都遵循类似的模式:')]
前面的代码块假设你在当前目录中有一个名为 test.txt 的文件。所有 LangChain 文档加载器的使用都遵循一个类似的模式:
-
首先,从众多集成integrations选项中选择适合你文档类型的loader加载器。
-
创建loader加载器的实例,并传入相关配置参数,包括文档的位置(通常是文件路径或网址)。
-
通过调用 load() 方法来加载文档,该方法会返回一个文档列表,供下一阶段使用(后面会详细讲解)。
除了 .txt 文件之外,LangChain 还提供适用于其他常见文件类型的加载器,例如 .csv、.json 和 Markdown 文件,并支持与一些流行平台的集成,如 Slack 和 Notion。
需要更多用法,可以自行查看官网:
https://python.langchain.com/docs/integrations/document_loaders/
例如,你可以使用 WebBaseLoader 来加载网页中的 HTML 内容并将其解析为文本。
安装 beautifulsoup4 包即可使用该功能:
!pip install beautifulsoup4 -v
from langchain_community.document_loaders import WebBaseLoaderloader = WebBaseLoader("https://www.langchain.com/")
loader.load()
输出为:
[Document(metadata={'source': 'https://www.langchain.com/', 'title': 'LangChain', 'description': 'LangChain’s suite of products supports developers along each step of their development journey.', 'language': 'en'}, page_content="LangChain\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\nProducts\n\nLangGraphLangSmithLangChainResources\n\nResources HubBlogCustomer StoriesLangChain AcademyCommunityExpertsChangelogDocs\n\n此处省略")]
在我们的特斯拉PDF用例中,我们可以使用LangChain的PDFLoader从PDF文档中提取文本:
# install the pdf parsing library
!pip install pypdf
from langchain_community.document_loaders import PyPDFLoaderloader = PyPDFLoader("./untitled.pdf")
pages = loader.load()# 只打印每页的纯文本内容
for i, page in enumerate(pages):print(f"--- Page {i + 1} ---")print(page.page_content)
输出为:
--- Page 1 ---
u n t i t l e d 11111111111111111111111111222222222222222222222223333333333333333
我们的简单示例中,文本已经从 PDF 文档中提取出来并保存在 Document 类中。
但是,有一个问题。假如加载的文档长度超过 100,000 个字符,不适合大多数 LLM 或嵌入模型的上下文窗口。
为了克服这一限制,我们需要将 Document 拆分为可管理的文本块,以便稍后将其转换为嵌入并进行语义搜索,从而进入第二步(retrieving检索)。
注意:
大语言模型(LLMs)和嵌入模型在输入和输出的token数量上都存在严格的限制。这个限制通常被称为 上下文窗口(context window),它通常适用于输入和输出的总和。也就是说,如果上下文窗口大小为 100(我们稍后会解释单位),而你的输入占用了 90 个 token,那么输出最多只能为 10 个 token。
上下文窗口通常以 token 数量来衡量,例如 8192 个 token。
Token(如前言中提到的)是文本的数值表示,每个 token 通常对应 3 到 4 个英文字符。
[!NOTE] 为什么会有“上下文窗口”(context window)这个限制?
资源限制:计算成本高
每次你和大语言模型对话,它其实是在处理一个非常复杂的数学计算过程,背后是巨大的矩阵运算。
输入越长,占用的 显存(GPU memory) 和 计算时间 就越多。
输入+输出的长度太长,会让显卡扛不住,或者处理速度变得非常慢。
所以模型必须设置一个“上限”——这就是 context window,也叫“上下文窗口”。模型设计:Transformer 架构的限制
大语言模型(如 GPT)基于 Transformer 架构。
Transformer 是靠“注意力机制”处理每一个 token 的。
每加一个 token,就要考虑它和之前所有 token 的关系,所以计算量是平方级别增长的(O(n²))。
这意味着:
上下文越长,注意力机制越慢,成本越高,效果也可能下降。训练方式决定了这个限制
模型训练时,是在固定长度的上下文窗口中学习的,比如 2048、4096 或 8192 个 token。
如果你测试时突然给它一个比训练时长得多的输入,模型可能根本不知道怎么处理。
所以训练时设置了窗口,使用时就要遵守这个规则。
一个简单类比:
想象你在读一本书,但你只能记住最近的一页内容(上下文窗口),太久以前的内容就记不清了。
模型也是这样,它记得的“最近内容”数量是有限的。