DeepSeek R1模型微调怎么做?从入门到实战
此前,我们分享了《个人和企业必看,DeepSeek从1.5B到671B模型的选型与部署指南》,有开发者在卓普云的账号下留言,希望可以了解如何在GPU云服务器上微调 DeepSeek 模型。在此教程中,我们将探索如何利用 DigitalOcean 的 GPU Droplet 云服务器微调 DeepSeek-R1 的蒸馏量化版本,将其转化为专门的推理助手。
由于每个公司的领域不同,使用 DeepSeek 的目的不一样。我们不可能面面俱到。这篇文章是针对如何将 DeepSeek R1 模型微调成一个针对医疗推理 AI 助手的实践过程。这个助手可以帮助医生分析患者病例,提出诊断建议,并提供经过验证的结构化的推断依据与结论。希望这样的一篇DeepSeek R1 模型微调实践,可以作为你在针对其他领域特点微调 DeepSeek R1 模型的参考。
特别鸣谢 : 感谢这篇优秀的DataCamp教程和论文——《HuatuoGPT-o1:基于LLM的医疗复杂推理探索》,它为本教程提供了启发。
预备知识
掌握以下内容将有助于您更好地理解本教程内容:
- Python和PyTorch
- 深度学习基础(如神经网络、超参数等)
- 使用Hugging Face模型和Transformers库的经验
- 对 DigitalOcean 云平台的 GPU Droplet 服务器有大致的了解(可参考卓普云官网的信息来了解)
何时使用微调(Fine-tuning)?
微调是通过在精心准备的数据集上进一步训练预训练模型,使其适应特定任务。它在需要统一格式、特定语气要求或复杂指令的场景中可以获得很好的推理效果,因为它能优化模型在这些特定用例中的行为。相比从头开始训练模型,微调通常需要更少的计算资源和时间。但在开始微调前,开发者也应对比其他替代方案,从中选择最优解,例如提示工程(Prompt Engineering)、检索增强生成(RAG)或从头训练模型。
| 方法 | 何时考虑使用? |
| 提示工程 | 通过现有模型能力设计精确指令来引导模型行为。可参考我们其他的教程《通过DigitalOcean的一键模型部署功能:使用LLM进行社交媒体分析入门》《如何创建电子邮件newsletter生成器》 |
| 检索增强生成(RAG) | 在目标是整合新的或最新的信息时,检索增强生成(RAG)通常是更合适的选择。RAG允许模型访问外部知识,而无需修改其底层参数。 |
| 从头训练模型 | 在需要模型可解释性和可理解性的应用场景中,从头开始训练模型可能会更有益。这种方法让你对模型的架构、数据和决策过程拥有更大的控制权。 |
你可以将不同的方法进行组合,例如微调(fine-tuning)和检索增强生成(RAG)。通过将微调用于建立稳健的基线,同时结合RAG来处理动态更新,系统能够在无需持续重新训练的情况下实现适应性和高效性。归根结底,这取决于你们团队的资源限制和期望的性能表现。
确保输出结果达到预期用途的标准,并在未达到时进行迭代或调整。
在我们确定微调是我们要采取的方法后,我们就需要准备必要的组件。
Tips:DeepSeek R1 是一个开源的先进推理模型,擅长文本生成、总结和翻译任务。作为目前可用的最具性价比的开源大语言模型之一。DigitalOcean的GPU Droplets,提供包括H200、H100、L40s、MI300X在内的多种GPU,并提供云服务器与裸金属服务器可供选择,价格低于传统大厂,并支持多种功能付费方式,详情可扫描文末二维码咨询DigitalOcean中国区独家战略合作伙伴卓普云。
微调模型需要什么?
预训练模型
预训练模型是一个已经在大型通用数据集上训练过的神经网络。Hugging Face 提供了大量开源模型供您使用。
在本教程中,我们将使用非常流行的推理模型 DeepSeek-R1。推理模型在处理复杂的数学或编程问题等高级任务方面表现出色。我们选择 “unsloth/DeepSeek-R1-Distill-Llama-8B-bnb-4bit” 是因为它经过蒸馏和预量化,使其成为一个更节省内存且成本效益更高的模型,适合进行实验。我们特别好奇它在复杂任务(如医学分析)中的潜力。请注意,由于推理模型通常计算成本高且输出冗长,使用它们来处理摘要或翻译等简单任务可能会大材小用。
数据集
Hugging Face 拥有丰富的数据集资源。我们将使用医学 O1 推理数据集。该数据集是通过 GPT-4o 搜索结果生成的,具体方法是搜索可验证的医学问题解决方案,并通过医学验证器进行验证。
我们将使用此数据集进行监督微调(SFT),即在指令和响应数据集上训练模型。为了尽量缩小生成答案与真实答案之间的差距,SFT 会调整大型语言模型中的权重。
GPU
微调模型并不总是需要 GPU。然而,使用 GPU(或多个 GPU)可以显著加快进程,特别是对于本教程中使用的较大模型或数据集。在本文中,我们将向您展示如何利用 DigitalOcean GPU Droplets。
工具和框架
在开始本教程之前,建议您熟悉以下库和工具:
Unsloth
Unsloth 专注于加快大型语言模型(LLM)的训练速度,特别是微调。Unsloth 库中的 FastLanguageModel 类为微调 LLM 提供了简化的抽象。该类可以处理加载训练好的模型权重、预处理输入文本以及执行推理以生成输出。
Transformer Reinforcement Learning(TRL)
Hugging Face 的 TRL 库用于使用强化学习训练转换器语言模型。本教程将使用 SFTTrainer 类。
Transformers
Transformers 同样是 Hugging Face 的一个库。我们将使用 TrainingArguments 类在 SFTTrainer 中指定所需参数。
Weights and Biases
W&B 平台将用于实验跟踪。具体来说,我们将监控损失曲线。
第二部分:实施
步骤1:设置 GPU Droplet 并启动 Jupyter Labs
按照 “为 AI/ML 编码设置 GPU Droplet 环境” 教程,为我们的 Jupyter Notebook 设置 GPU Droplet 环境。
步骤2:安装依赖库
%%capture
!pip install unsloth
!pip install --force-reinstall --no-cache-dir --no-deps git+https://github.com/unslothai/unsloth.git
!pip install --upgrade jupyter
!pip install --upgrade ipywidgets
!pip install wandb
步骤3:配置访问Token
从Hugging Face访问Token页面获取Hugging Face Token(需注册账户):
from huggingface_hub import login
hf_token = "Replace with your actual token"
login(hf_token)
同样需Weights & Biases账户获取 Token:
import wandb
wb_token = "Replace with your actual token"wandb.login(key=wb_token)
run = wandb.init(project='Medical Assistant', job_type="training", anonymous="allow"
)
from unsloth import FastLanguageModel
步骤4:加载模型和分词器
max_seq_length = 2048model, tokenizer = FastLanguageModel.from_pretrained(model_name = "unsloth/DeepSeek-R1-Distill-Llama-8B-bnb-4bit",max_seq_length = max_seq_length,load_in_4bit = True,dtype = None, # 若使用H100,将自动默认为bfloat16token = hf_token,
)
第 5 步:在微调之前测试模型输出
创建系统提示词(System Prompt)
在决定是否需要进行微调之前,验证模型输出是否符合你的格式、质量、准确性等标准是一种良好的实践。由于我们关注的是推理能力,因此我们会设计一个能够引导模型进行思维链(chain of thought)推理的系统提示词。
我们不直接在输入中编写提示词,而是先编写一个包含占位符的提示词模板。
在这个提示词模板中,我们会明确说明自己所期望的内容。
prompt_template= """### Role:
You are a medical expert specializing in clinical reasoning, diagnostics, and treatment planning. Your responses should:
- Be evidence-based and clinically relevant
- Include differential diagnoses when appropriate
- Consider patient safety and standard of care
- Note any important limitations or uncertainties
### Question:
{question}
### Thinking Process:
{thinking}
### Clinical Assessment:
{response}
"""
请注意其中的 {thinking} 占位符。这一步的核心目标是引导大语言模型(LLM)在给出最终答案之前,明确地阐述其推理过程。这正是所谓的“思维链提示”(chain-of-thought prompting)。
在微调前使用系统提示词进行推理
在这一步中,我们使用结构化提示词(prompt_template)对问题进行格式化,以确保模型遵循逻辑推理的过程。接着,我们将输入进行分词,转换为 PyTorch 张量(tensor),并移动到 GPU(cuda)上以加速推理过程。
question = "一位58岁的女性报告在笑、运动或搬重物时有3年的漏尿病史。她否认夜间尿失禁或尿急感。体格检查时,Valsalva动作可见尿液流出,棉签试验显示尿道膀胱连接处活动度增加,偏移角度达45度。尿动力学检查最可能显示其排尿后残余尿量和逼尿肌活动状态如何?"
FastLanguageModel.for_inference(model) # model 在第4步中定义
inputs = tokenizer([prompt_template.format(question,"")], return_tensors="pt").to("cuda")
随后,我们使用模型生成响应,并设定关键参数,例如 max_new_tokens=1200(限制响应长度)。
outputs = model.generate(input_ids=inputs.input_ids,attention_mask=inputs.attention_mask,max_new_tokens=1200,use_cache=True,
)
为了获取最终的可读答案,我们将输出的 tokens 解码为文本。
response = tokenizer.batch_decode(outputs)
print(response[0].split("### Response:")[1])
你可以自由尝试不同的提示词写法,并观察它们对模型输出产生的影响。
第 6 步:加载数据集
我们使用的数据集是 FreedomIntelligence/medical-o1-reasoning-SFT,它包含三列:Question(问题)、Complex_CoT(复杂的思维链)、以及 Response(回答)。
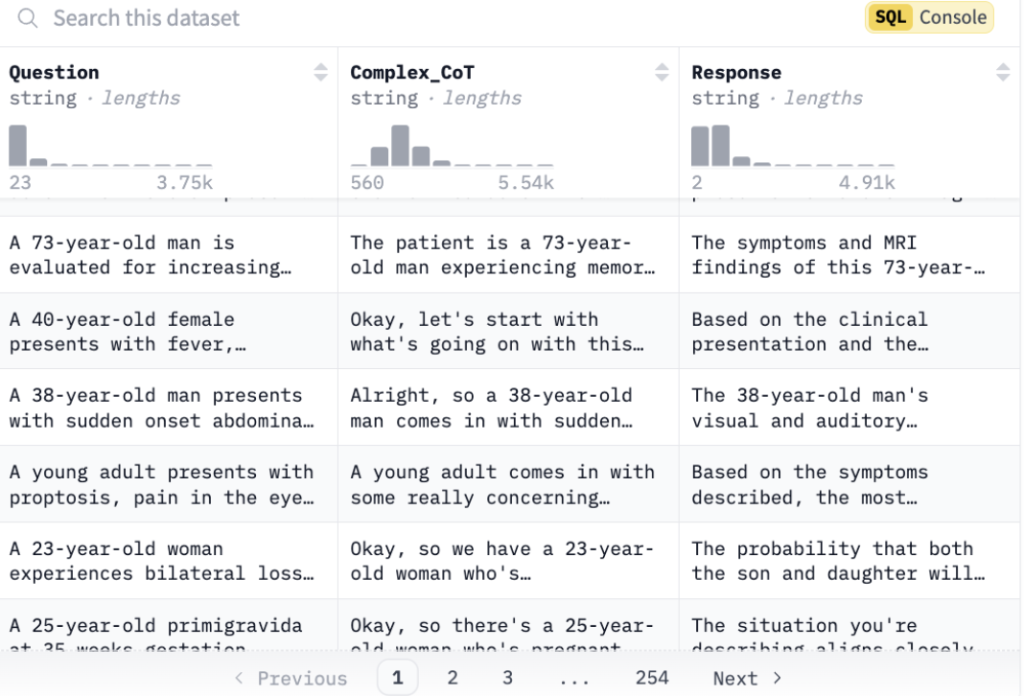
我们将创建一个函数(formatting_prompts_func)来格式化数据集中的输入提示词。
def formatting_prompts_func(examples):inputs = examples["Question"]cots = examples["Complex_CoT"]outputs = examples["Response"]texts = []for input, cot, output in zip(inputs, cots, outputs):text = prompt_template.format(input, cot, output) + tokenizer.eos_tokentexts.append(text)return {"text": texts,}
然后,我们加载数据集并对其应用格式化函数:
from datasets import load_dataset
dataset = load_dataset("FreedomIntelligence/medical-o1-reasoning-SFT", "en", split="train[0:500]", trust_remote_code=True)
dataset = dataset.map(formatting_prompts_func, batched=True)
dataset["text"][0]
第 7 步:为参数高效微调(PEFT)准备模型
与在微调过程中更新模型所有参数不同,PEFT(Parameter Efficient Fine-Tuning)方法通常只修改少量参数,从而节省计算资源和时间。
下面是我们在使用 Unsloth 的 FastLanguageModel 类中的 .get_peft_model 方法时将用到的一些超参数和参数的概览:
| 超参数 | 可能的值 |
|---|---|
| r: LoRA秩。这决定了可训练适配器的数量。 | 选择任何大于0的数字;推荐的数字是8, 16, 32, 64和128。请注意,较高的秩会产生更智能但较慢的模型输出。 |
| target_modules: 这些是将在LoRA中应用的变压器架构内的模块(层)。 | q_proj, k_proj, v_proj: 注意机制中的查询、键和值投影层。微调这些对于使模型注意力适应新任务至关重要。o_proj: 注意机制中的输出投影层。gate_proj, up_proj, down_proj: 变压器块中前馈网络(FFN)部分的投影层。微调这些可以帮助模型在FFN中学习特定于任务的表示形式。 |
| lora_alpha: 这是LoRA更新的比例因子。它有助于控制应用于原始权重的更新幅度。它与学习率有关,调整它可以对性能很重要。 | 通常设置为r的倍数(例如:2r或4r)。 |
| lora_dropout: 这是应用于LoRA更新的dropout概率。Dropout是一种防止过拟合的正则化技术。 | 当设置为0时,不应用dropout。如果您观察到过拟合,您可能会增加这个值。 |
| bias: 偏置参数指示偏置(添加以抵消结果的常数)如何由模型处理。 | 如果不添加偏置,则设置为“none”。其他可能的参数包括“all”或“lora_only”,指定在哪一层添加偏置。 |
| use_gradient_checkpointing: 梯度检查点是一种减少训练期间内存使用的技术,代价是一些额外的计算。它在反向传递过程中重新计算激活而不是存储它们。 | “unsloth”参数可用于Unsloth库中针对长上下文优化实现的梯度检查点。或者,可以将此参数设置为True以启用标准梯度检查点(以节省内存为代价降低反向传递速度),或设置为False以禁用它。 |
| random_state: 设置初始化LoRA权重的随机种子。使用固定的随机种子确保可重复性——只要使用相同的种子再次运行代码,就会得到相同的结果。 | 这个值是什么并不重要,只要在整个代码中保持一致即可。 |
| use_rslora: rsLoRA引入了一个缩放因子来稳定训练过程中的梯度,解决了随着秩的增加,在标准LoRA中可能出现的梯度崩溃问题。 | 当设置为True时应用rsLoRA(将适配器缩放因子设置为lora_alpha/math.sqrt®),这对于较高的r值是推荐的。默认值是False(lora_alpha/r的默认值)。 |
我们这样调用 get_peft_model 方法来配置模型:
model = FastLanguageModel.get_peft_model(model,r=16,target_modules=["q_proj","k_proj","v_proj","o_proj","gate_proj","up_proj","down_proj",],lora_alpha=16,lora_dropout=0,bias="none",use_gradient_checkpointing="unsloth", # 对于很长的上下文可设置为 "unsloth"random_state=522,use_rslora=False
)
现在我们已经评估过模型的输出,是时候使用我们的 SFT 数据集来微调预训练模型了。
第 8 步:使用 SFTTrainer 进行模型训练
SFTTrainer 是 TRL 库中的一个类,用于开发经过监督微调(Supervised Fine-tuning)的模型。
我们将使用以下导入:
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
训练参数
| 超参数 | 可能的值 |
|---|---|
| per_device_train_batch_size: 每个设备/GPU在训练步骤期间处理的样本数量 | 通常是2的幂:1, 2, 4, 7, 16, 32… |
| gradient_accumulation_steps: 在执行反向传递之前要累积的前向传递次数 | 较高的值允许使用更大的有效批次大小。(有效批次大小 = per_device_train_batch_size * gradient_accumulation_steps)。 |
| warmup_steps: 学习率预热阶段的步数 | 非负整数,通常为总训练步数(max_steps)的5-10% |
| max_steps: 需要执行的总训练步数 | 正整数,取决于数据集大小和训练需求 |
| learning_rate: 用于模型权重更新的步长 | 通常在1e-5到1e-3之间(例如:2e-4, 3e-4, 5e-5) |
| fp16: 控制是否使用16位浮点精度 bf16: 控制是否使用brain floating格式 | 启用混合精度训练(fp16或bf16),如果硬件支持,则可以加快训练速度。可能的值包括:not is_bfloat16_supported() 或 is_bfloat16_supported()。 |
| logging_steps: 训练指标的日志记录频率 | 表示在记录训练指标之前要经过的步骤间隔的正整数值。所选值需要在有足够的信息跟踪训练进度和保持日志记录开销可控之间取得平衡。 |
| optim: 训练的优化算法 | adamw 8-bit 的性能与adamw相似(一种流行且强大的优化器),但GPU内存使用减少,因此它是推荐的选择。 |
| weight_decay: 一种防止过拟合的正则化技术,其中的值对应于要应用的权重衰减量。 | 默认为0的一个浮点数值。 |
| lr_scheduler_type: 学习率调整计划 | 默认并建议使用的值是“linear”。其他选择包括“cosine”,“polynomial”等,并且可以选择它们以实现更快的收敛。 |
| seed: 为了结果可重复性的随机种子 | 这个值是什么并不重要,只要在整个代码中保持一致即可。 |
| output_dir: 保存训练输出的位置 | 目录路径的字符串 |
以下代码将启动训练流程:
trainer = SFTTrainer(model=model,tokenizer=tokenizer,train_dataset=dataset,dataset_text_field="text",max_seq_length=max_seq_length,dataset_num_proc=2,args=TrainingArguments(per_device_train_batch_size=2,gradient_accumulation_steps=4,warmup_steps=5,max_steps=60,learning_rate=2e-4,fp16=not is_bfloat16_supported(),bf16=is_bfloat16_supported(),logging_steps=10,optim="adamw_8bit",weight_decay=0.01,lr_scheduler_type="linear",seed=522,output_dir="outputs", # 输出将保存在 Response 列中),
)
启动训练:
trainer_stats = trainer.train()
第 9 步:监控实验过程
可以使用 Weights and Biases 等工具进行实验追踪。核心目标是确保训练损失随着训练进行而逐渐降低,以判断模型性能是否正在提升。如果模型性能下降,可能需要重新尝试调整超参数。
第 10 步:微调后的模型推理
question = "一位 58 岁女性报告在大笑、锻炼或搬重物时有 3 年的漏尿病史。她否认夜间尿失禁或有尿意急迫感。体检时,在做 Valsalva 动作时出现漏尿,Q-tip 测试显示尿道膀胱连接处有 45 度的活动度。压力后残余尿量和逼尿肌活动的尿动力学检查最可能显示什么?"
FastLanguageModel.for_inference(model)
inputs = tokenizer([prompt_template.format(question, "")], return_tensors="pt").to("cuda")
outputs = model.generate(input_ids=inputs.input_ids,attention_mask=inputs.attention_mask,max_new_tokens=1200,use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("### Response:")[1])
第 11 步:将模型保存到本地
new_model_local = "DeepSeek-R1-Medical-COT"
model.save_pretrained(new_model_local)
tokenizer.save_pretrained(new_model_local)
model.save_pretrained_merged(new_model_local, tokenizer, save_method="merged_16bit")
第 12 步:将模型发布到 Hugging Face Hub
如果希望让更多 AI 研究者使用和受益,可以将模型上传至 Hugging Face Hub,这样其他人就可以轻松集成你的模型到自己的项目中。
new_model_online = "HuggingFaceUSERNAME/DeepSeek-R1-Medical-COT"
model.push_to_hub(new_model_online)
tokenizer.push_to_hub(new_model_online)
model.push_to_hub_merged(new_model_online, tokenizer, save_method="merged_16bit")
结语
微调是将预训练模型转变为能够解决具体问题的精准工具的关键过程。在这个过程中,我们并不是在“重新发明轮子”,而是在对其进行精准调校,让它更好地为我们的目标服务。虽然预训练模型功能强大,但它们的输出往往缺乏结构性和专业度,而微调正是解决这一问题的关键。
我们希望本教程不仅帮助你理解了何时以及如何使用推理模型进行微调,也为你今后更深入地打磨这项技术提供了一些灵感。
最后,如果你还在寻找价格实惠、性能可靠、算力充足的 GPU 服务器,欢迎点击下方按钮,扫描二维码,联系DigitalOcean中国区独家战略合作伙伴卓普云,了解DigitalOcean GPU Droplet服务器。