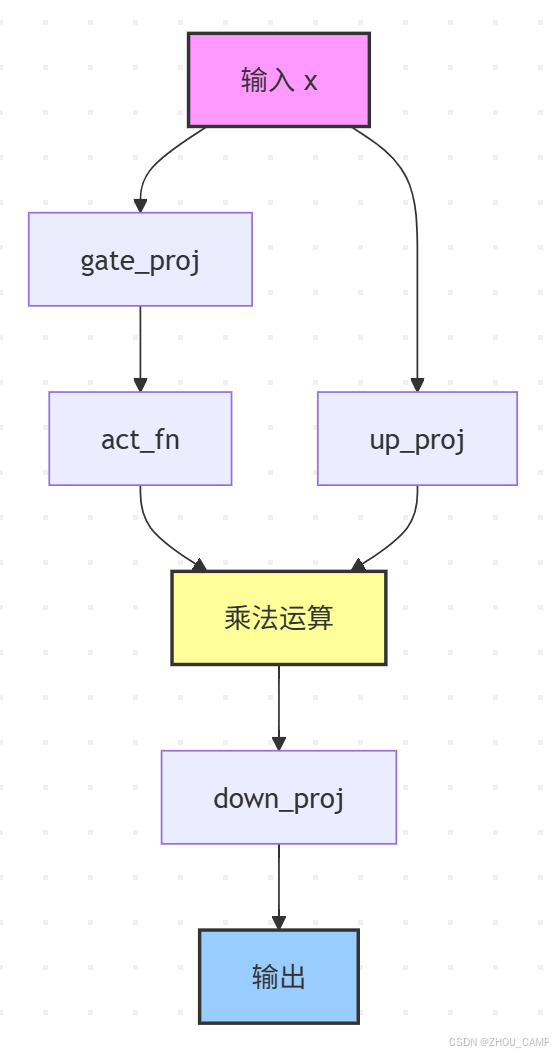
DeepseekV3MLP 模块
目录
- 代码
- 代码解释
- 导入和激活函数
- 配置类
- 初始化方法
- 前向传播方法
- 计算流程
- 代码可视化
代码
import torch
import torch.nn as nn
import torch.nn.functional as F# 定义激活函数字典
ACT2FN = {"relu": F.relu,"gelu": F.gelu,"silu": F.silu,"swish": lambda x: x * torch.sigmoid(x),"gelu_new": lambda x: 0.5 * x * (1.0 + torch.tanh(math.sqrt(2.0 / math.pi) * (x + 0.044715 * torch.pow(x, 3.0)))),
}# 简单的配置类
class ModelConfig:def __init__(self, hidden_size=768, intermediate_size=3072, hidden_act="gelu"):self.hidden_size = hidden_sizeself.intermediate_size = intermediate_sizeself.hidden_act = hidden_actclass DeepseekV3MLP(nn.Module):def __init__(self, config, hidden_size=None, intermediate_size=None):super().__init__()self.config = configself.hidden_size = config.hidden_size if hidden_size is None else hidden_sizeself.intermediate_size = config.intermediate_size if intermediate_size is None else intermediate_sizeself.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)self.act_fn = ACT2FN[config.hidden_act]def forward(self, x):# 打印输入张量的维度print(f"输入 x 的维度: {x.shape}")# 步骤1: 通过gate_proj线性层gate_output = self.gate_proj(x)print(f"gate_proj(x) 的维度: {gate_output.shape}")# 步骤2: 应用激活函数gate_activated = self.act_fn(gate_output)print(f"act_fn(gate_proj(x)) 的维度: {gate_activated.shape}")# 步骤3: 通过up_proj线性层up_output = self.up_proj(x)print(f"up_proj(x) 的维度: {up_output.shape}")# 步骤4: 元素级乘法gated_up = gate_activated * up_outputprint(f"act_fn(gate_proj(x)) * up_proj(x) 的维度: {gated_up.shape}")# 步骤5: 通过down_proj线性层down_proj = self.down_proj(gated_up)print(f"down_proj(act_fn(gate_proj(x)) * up_proj(x)) 的维度: {down_proj.shape}")return down_proj
代码解释
导入和激活函数
首先导入了必要的 PyTorch 库,并定义了一个激活函数字典 ACT2FN,包含了多种常用的激活函数:
relu: 修正线性单元激活函数gelu: 高斯误差线性单元激活函数silu: Sigmoid线性单元激活函数swish: Swish激活函数 (x * sigmoid(x))gelu_new: GELU激活函数的另一种实现方式
配置类
ModelConfig 类用于存储模型的基本配置参数:
hidden_size: 隐藏层大小,默认为768intermediate_size: 中间层大小,默认为3072hidden_act: 使用的激活函数类型,默认为"gelu"
初始化方法
def __init__(self, config, hidden_size=None, intermediate_size=None):
初始化方法接收配置对象和可选的隐藏层大小和中间层大小参数,创建了三个线性层:
gate_proj: 门控投影层,将输入从 hidden_size 映射到 intermediate_sizeup_proj: 上投影层,同样将输入从 hidden_size 映射到 intermediate_sizedown_proj: 下投影层,将中间结果从 intermediate_size 映射回 hidden_size
前向传播方法
前向传播方法实现了 SwiGLU 激活机制的变体,具体步骤如下:
- 输入张量 x 通过
gate_proj线性层 - 对
gate_proj的输出应用激活函数 - 输入张量 x 通过
up_proj线性层 - 将激活后的
gate_proj输出与up_proj输出进行元素级乘法 - 将乘法结果通过
down_proj线性层映射回原始维度
这种设计是 SwiGLU 激活的一种变体,通过门控机制增强了模型的表达能力。每一步都打印了张量的维度,便于调试和理解数据流。
计算流程
假设输入张量维度为 [batch_size, seq_length, hidden_size],例如 [2, 10, 768]:
- 通过 gate_proj 和 up_proj 后,维度变为 [2, 10, 3072]
- 激活函数和元素级乘法保持维度不变
- 最后通过 down_proj 将维度映射回 [2, 10, 768]
这种设计允许模型在中间层扩展维度以增加表达能力,然后再压缩回原始维度,是现代大型语言模型中常用的技术。
代码可视化
def main():# 创建配置config = ModelConfig(hidden_size=768, intermediate_size=3072, hidden_act="gelu")# 实例化模型model = DeepseekV3MLP(config)# 创建一个随机输入张量进行测试batch_size = 2seq_length = 10input_tensor = torch.rand(batch_size, seq_length, config.hidden_size)# 前向传播output = model(input_tensor)# 打印输入和输出的形状print(f"模型参数总数: {sum(p.numel() for p in model.parameters())}")if __name__ == "__main__":main()输入 x 的维度: torch.Size([2, 10, 768])
gate_proj(x) 的维度: torch.Size([2, 10, 3072])
act_fn(gate_proj(x)) 的维度: torch.Size([2, 10, 3072])
up_proj(x) 的维度: torch.Size([2, 10, 3072])
act_fn(gate_proj(x)) * up_proj(x) 的维度: torch.Size([2, 10, 3072])
down_proj(act_fn(gate_proj(x)) * up_proj(x)) 的维度: torch.Size([2, 10, 768])
模型参数总数: 7077888