基于RK3588+FPGA+AI YOLO的无人船目标检测系统(一)概述
无人船在海洋监测、资源勘测、海上安全和科学研究等领域扮演着关键角色,
提升了海上任务的执行效率和安全性。在这一过程中,环境感知技术和目标检测
技术相辅相成,共同构建了系统的核心功能。随着人工智能行业的迅速发展,各
种智能芯片、传感器、处理器和嵌入式系统得以广泛部署,形成了一个相对完善
的生态系统。然而,通过国外平台进行环境感知存在信息安全的问题,使用国产
化平台成为解决这一问题的关键手段之一。因此,本文致力于研究基于国产化平
台的水面目标检测系统,并构建一套完整的开发工具链,主要工作如下:
( 1 )针对 YOLOv5s 和 YOLOv8s 在 RK3588 平台上存在检测精度和速度不
高的问题,提出了一种基于轻量化卷积和注意力机制改进的方法,可以在降低模
型参数量的情况下实现准确快速的检测。分别使用 PAGCP 和 LAMP 剪枝算法对
改进的 YOLOv5s 和 YOLOv8s 模型进行剪枝,使得在参数量和浮点运算量分别
下降的基础上,精度 mAP50 仅损失 0.045 和 0.057 。
( 2 )针对当前目标检测系统多为国外平台的问题,设计了一套基于国产平
台的水面目标检测系统。以国产 RK3588 芯片作为核心计算平台,搭载高性能
NPU ,能够在芯片内部进行神经网络模型的推理运算,从而加速深度学习任务的
执行速度,提高系统的性能;为确保高效的数据采集与传输,设计了基于国产
Logos2 FPGA 的数据采集传输方案,使用 PCIe3.0 接口与 RK3588 进行通信,极
大提高了数据传输速度,为后续目标检测算法提供了高质量的数据支持。
( 3 )针对部署时存在帧率不高的问题,使用 INT8 和 INT16 的方式对模型
进行了量化操作,使得改进后的 YOLOv5s 模型量化后的体积仅为原模型的
26.25% ,改进后的 YOLOv8s 模型量化后的体积仅为原模型的 16.51% 。同时还对
推理过程进行多线程加速,成功将改进后的 YOLOv8s 模型帧率提升至 110FPS 。
针对 NPU 利用率不高的问题,对 RK3588 的 CPU 和 GPU 进行了定频处理,充
分发挥 RK3588 多核处理的能力,从而提高了 NPU 的利用率。
随着无人驾驶技术的飞速发展,近些年来无人机和无人车已经在各种场景
得到广泛应用。与此同时,无人船( Unmanned Surface Vehicles , USV )作为一
种新兴技术,正迎来广阔的发展前景。在过去几年中, USV 已广泛应用于军事
和民用领域,包括但不限于港口安全、舰船护卫、海上监视、水上救援、后勤补
给、水文采样以及海洋环境勘测等任务。但是 USV 在环境感知方面面临一个严
峻的问题,即如何实现准确停靠岸和精准避障,解决这个问题的关键在于确保
USV 具备优越的目标检测能力 [1] ,而实现这一目标就需要合适的硬件平台与目
标检测算法作为支撑。
近 15 年来,基于深度学习的目标检测算法研究取得了巨大的进步,成为了
主流的研究方向 [2-3] ,并在本地 GPU 和云端服务器的训练与部署上取得了突破,
但在实际应用时,二者都存在一定的局限性。本地 GPU 体积和功耗较大,难以
部署在嵌入式平台上;云端服务器的传输速度受限于网络带宽的影响,也难以满
足实时性的需求。而人工智能( Artificial Intelligence , AI )芯片在架构设计之初
就专门结合了视觉和语言运算特征进行优化,便于进行目标检测算法的部署。 AI
芯片能够模拟大脑神经元和突触的功能,采用一组神经元处理一组指令的计算
模式,在进行图像和音频处理等任务时具有更快的速度和更低的功耗。
在国内,深度学习算法部署平台一直是科学研究和工业应用中备受关注的
领域。目前常用的平台多依赖于国外的软硬件技术,例如赛灵思公司的 ZYNQ [4]
系列和 NVIDIA 公司的 Jetson [5-6] 系列。虽然这些硬件平台在深度学习应用中取
得了显著的成就,但是却涉及到对底层推理框架、开发环境和生态链的依赖,因
此使用国产化平台能够更有效地保护信息安全。 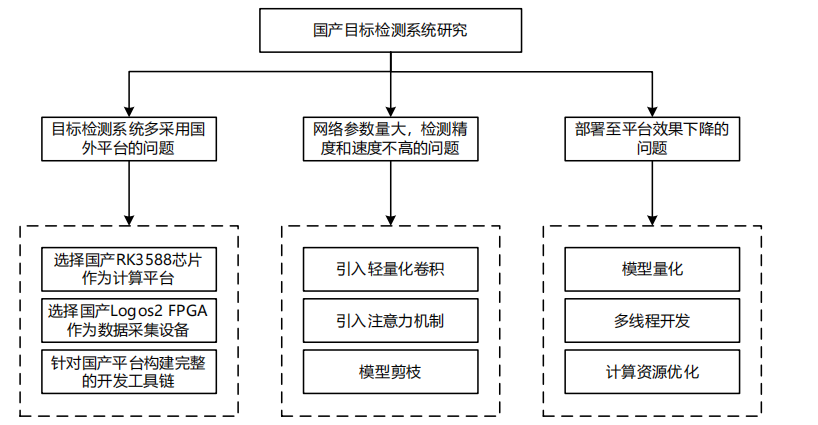
( 1 )基于国产化、实时采集和快速推理的需求,合理选择了国产化硬件,
其中 RK3588 用来推理计算, Logo2 FPGA 负责数据采集。该平台的整体平均功
耗仅 20W 左右,能够做到长续航。同时在此基础上设计了一套全新的开发工具
链。
( 2 )提出一种基于改进的 YOLOv5s 和 YOLOv8s 的目标检测算法。通过对
原模型引入轻量化卷积结构,提高了计算效率,在硬件资源受限的情况下能够更
快地执行推理。同时这些轻量化卷积结构占用更少的存储空间和内存,因此适用
于移动设备、嵌入式系统和边缘设备。此外由于模型过大导致的高功耗问题,也
能通过轻量化卷积结构来缓解,改进后的模型更易于算法的部署和维护。
( 3 )采取了一系列有效方法来提高模型在资源受限的国产 AI 平台上的推
理速度。首先使用了模型量化技术,通过减少模型参数量来降低模型的计算复杂
度,从而提高推理速度,在保持精度不受影响的情况下,成功地减少了模型的体
积,从而节省了存储空间。其次采用了线程池技术,通过并行化处理模型的推理
任务,充分利用了国产 AI 平台的多核心处理器,提高了推理效率。最后实施了
硬件定频操作,通过调整 CPU 和 GPU 的工作频率,使其在不同负载下能够以最
佳性能运行,进一步提升了推理速度和效率。这些措施为实现在资源受限环境下
的高效推理提供了可行的解决方案。