240421 leetcode exercises
240421 leetcode exercises
@jarringslee
文章目录
- 240421 leetcode exercises
- [31. 下一个排列](https://leetcode.cn/problems/next-permutation/)
- 什么是字典序?
- 🔁二次遍历查找
- [82. 删除排序链表中的重复元素 II](https://leetcode.cn/problems/remove-duplicates-from-sorted-list-ii/)
- 🔁遍历 & 去重
31. 下一个排列
整数数组的一个 排列 就是将其所有成员以序列或线性顺序排列。
- 例如,
arr = [1,2,3],以下这些都可以视作arr的排列:[1,2,3]、[1,3,2]、[3,1,2]、[2,3,1]。整数数组的 下一个排列 是指其整数的下一个字典序更大的排列。更正式地,如果数组的所有排列根据其字典顺序从小到大排列在一个容器中,那么数组的 下一个排列 就是在这个有序容器中排在它后面的那个排列。如果不存在下一个更大的排列,那么这个数组必须重排为字典序最小的排列(即,其元素按升序排列)。
- 例如,
arr = [1,2,3]的下一个排列是[1,3,2]。- 类似地,
arr = [2,3,1]的下一个排列是[3,1,2]。- 而
arr = [3,2,1]的下一个排列是[1,2,3],因为[3,2,1]不存在一个字典序更大的排列。给你一个整数数组
nums,找出nums的下一个排列。必须原地修改,只允许使用额外常数空间。
示例 1:
输入:nums = [1,2,3] 输出:[1,3,2]示例 2:
输入:nums = [3,2,1] 输出:[1,2,3]示例 3:
输入:nums = [1,1,5] 输出:[1,5,1]
很难受的一道题。算法只考了简单的排序,重点在思维与理解。首先你需要知道数组是如何按照字典序排序的。
什么是字典序?
字典序(Lexicographical Order)就是把序列(比如字符串、数组、单词序列等)当成“字典里的一行行词条”来排序,遵循人们查字典时的顺序习惯。具体来说:
逐位比较
给定两个序列 AA 和 BB,从第 0 位(或第 1 位)开始,往后依次比较它们的元素:
- 如果在第 k位上,A[k]<B[k],那么 A 在字典序中就排在 BB之前;
- 如果 A[k]>B[k,则 A排在 B之后;
- 如果 A[k]=B[k],继续比较下一位,直到遇到不相等的位置或其中一个序列结束。
前缀规则
如果一个序列是另一个序列的前缀,比如A=[1,2],B=[1,2,3]A = [1,2]\quad,\quad B = [1,2,3]
那么较短的那个 AA 会排在较长的那个 BB 之前(因为在“字典”里 shorter word 通常更靠前)。
形式化定义
我们设一下吧。设有两个整数序列。
A=(a0,a1,…,an−1),B=(b0,b1,…,bm−1)A = (a_0, a_1,…, a_{n-1}), B = (b_0, b_1,…, b_{m-1})
它们的字典序比较规则是:
找到最小的下标 k 使得 ak≠bk。
- 若存在这样的 kk,则
A<B ⟺ ak<bk如果所有对应位置都相等(即前 min(n,m)\min(n,m) 个元素都相同),则
A<B ⟺ n<m
EXAMPLE
字符串
"apple"与"apply":
比较到第四个字符然后
e < y,所以"apple" < "apply"。数组
- [1,2,4][1, 2, 4] 与 [1,2,3,9][1, 2, 3, 9]:
第 0、1 位都相同,比较第 2 位,4>34 > 3,所以 [1,2,4][1,2,4] 排在 [1,2,3,9][1,2,3,9] 之后。- [1,2][1,2] 与 [1,2,0][1,2,0]:
前两位相同,但第一个序列长度为 2,第二个长度为 3,所以 [1,2]<[1,2,0][1,2] < [1,2,0]。
在这个问题里,我们把所有排列看成有序列表,按照字典序从小到大排好,当前排列的“下一个”就是紧挨着它、在这套顺序里最小但又比它大的那个排列。正因为字典序天然对应“从小到大”的顺序,才能保证算法只需做一次局部修改(找到分界、交换、反转)就能得到下一个。
相信看到这里你依旧没看懂。不过没有关系,我们只需要凭感觉排列一下:
123
132
213
231
312
321
就是这样凭直觉来的排序。先升序排序,再交换后两位,再后三位,后四位…
那么我们再比如:
1 1 2 3 7 6 4
我们迅速找到最大数字7,往后看:是64。说明这是1123746的下一种排序。
那么这个下一个字典序一定要从当前数列后四位开始做文章。在3764中,3XXX的排序方法刚好排完,因为764是降序,一定是最后一种(有了这个发现,我们就知道可以直接找数列从后到前升序的数列,并从这个数列的再向前一位开始处理)。
所以我们把比3大的下一个数字4摘出来放到3的位置,数列变成4XXX。
而4XXX的第一个字典序排序方法,上面也讲过了,当然是升序排序:4376。那么,我们就得到了1123764的下一种按字典序排序的数列:
1 1 2 4 3 7 6
🔁二次遍历查找
通过上面的例子,我们可以总结出“寻找下一个排列的”大致方法:
步骤 1:从后往前找到第一个降序对
我们用i从后往前遍历,找到第一个满足 nums[i] < nums[i+1] 的索引 i,我们称之为分界点”。如果找不到这样的 i(整个数组是降序的),说明当前已经是最大的排列,我们将数组全部翻转成最小的排列(即升序)。否则,继续下一步。
步骤 2:从后往前找到第一个比 nums[i] 大的数字
我们继续从后往前查找,在数列的分界点右边找到第一个大于 nums[i] 的数字 nums[j]。这里因为分界点之后的数列已经是降序数列了,所以直接遍历查找即可。
步骤 3:交换 nums[i] 和 nums[j]
步骤 4:翻转分界点右边所有数字(即升序排列)
交换后,右边部分仍是降序的,我们为了找到最小的比当前排列大的数,就要把这部分变成升序。
举个例子:nums = [1, 2, 3]
- 找到 i = 1,因为
nums[1] = 2 < 3 - 找到 j = 2,因为
nums[2] = 3 > 2 - 交换:nums = [1, 3, 2]
- 反转
i+1之后的部分,不影响,因为2后面已经是升序
//交换量输的函数
void swap(int* a, int* b) {int temp = *a;*a = *b;*b = temp;
}// 翻转函数,用于把降序变为升序
void reverse(int* nums, int start, int end) {while (start < end) {swap(&nums[start], &nums[end]);start++;end--;}
}void nextPermutation(int* nums, int numsSize) {int i = numsSize - 2;//找到第一个下降的位置 iwhile (i >= 0 && nums[i] >= nums[i + 1]) {i--;}if (i >= 0) {//找到第一个比 nums[i] 大的数字 jint j = numsSize - 1;while (j >= 0 && nums[j] <= nums[i]) {j--;}//交换 nums[i] 和 nums[j]swap(&nums[i], &nums[j]);}//翻转 i+1 到 numsSize-1 的部分reverse(nums, i + 1, numsSize - 1);
}
82. 删除排序链表中的重复元素 II
给定一个已排序的链表的头
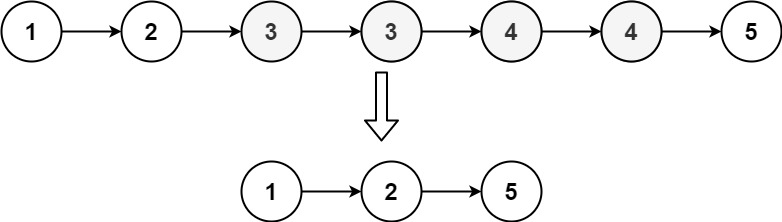
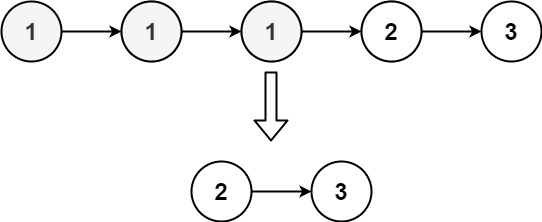
head, 删除原始链表中所有重复数字的节点,只留下不同的数字 。返回 已排序的链表 。示例 1:
输入:head = [1,2,3,3,4,4,5] 输出:[1,2,5]示例 2:
输入:head = [1,1,1,2,3] 输出:[2,3]
这道题原本可以有点难度,但是他给出的是已经排好序的链表,所以难度断崖式降低。会遍历、会删除,这道题就没什么大问题了。
🔁遍历 & 去重
依旧是设置虚拟头结点和指向它的结构体指针。
由于要为删除链表做准备,所以我们在遍历时需要比较当前节点的后两个节点的值(那第一个节点就有重复怎么办?这就是我们设置虚拟头结点的原因之一。第一次遍历时直接开始比较的当前节点的下一个节点正是给出链表的头结点)。
我们把当前结点的下一个结点的值设为val,并和下下一个比较。如果这两个节点的值相同,那说明后面可能会有更多相同值,也可能没有了,但是我们一视同仁,直接进入删除环节:
再次进入判断:如果val值等于当前结点的下一个节点的值,那么删除该节点,并让当前节点移动至下一个节点,直到下一个节点的值不等于val值。
出判断后,当前这一坨相同值已经被我们处理干净了。我们让指针移动,继续判断后面的情况,最后返回虚拟头结点的下一个节点,也就是去重后链表的头结点。
struct ListNode* deleteDuplicates(struct ListNode* head) {struct ListNode dummy = {0, head};struct ListNode* now = &dummy;while (now -> next && now -> next -> next ){//判断后两个值int val = now -> next -> val;if (val == now -> next -> next -> val){//如果相等就进入循环删除操作while (now -> next && now -> next -> val == val){now -> next = now -> next -> next;}} else {//未发现重复就继续遍历链表now = now -> next;}}return dummy.next;
}