算法学习(二)
回溯法
回溯法解决的问题
-
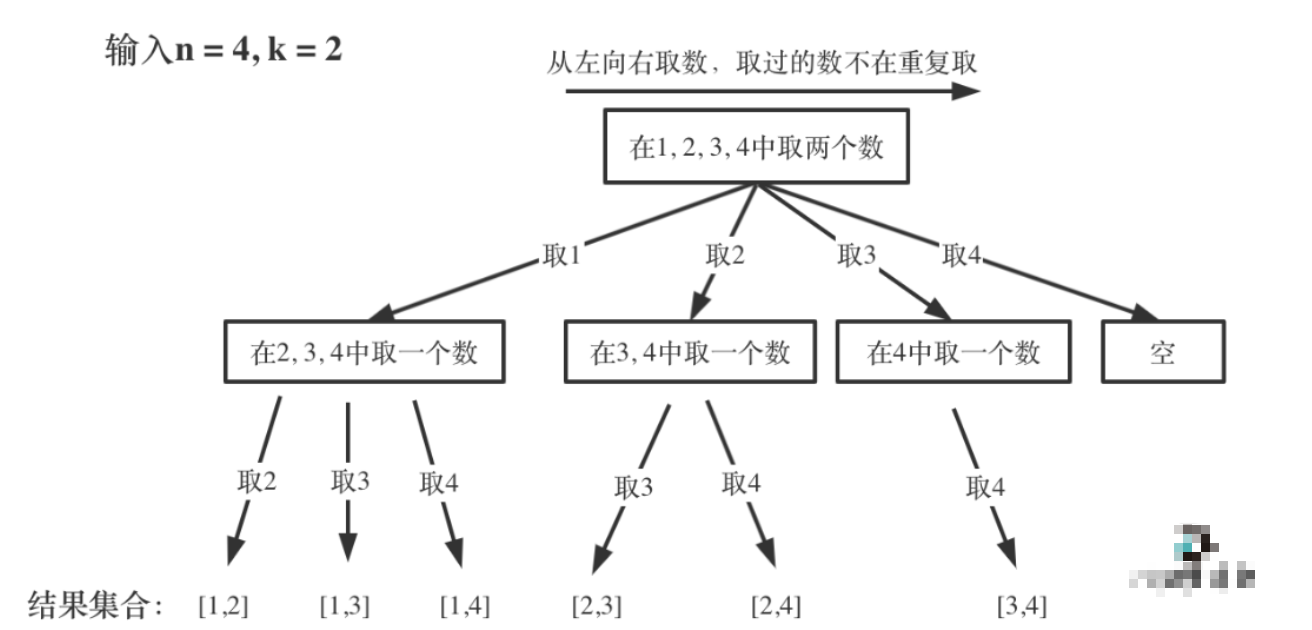
组合问题:N个数里面按一定规则找出k个数的集合
-
切割问题:一个字符串按一定规则有几种切割方式
-
子集问题:一个N个数的集合里有多少种符合条件的子集
-
排列问题:N个数按一定规则全排列,有几种排列方式
-
棋盘问题:N皇后,解数独等等
组合是不强调元素顺序的,排列是强调元素顺序的。
回溯法解决的问题都可以抽象为树形结构,回溯法解决的都是在结合中递归查找子集,集合的大小就构成了书的宽度,递归的深度就构成了树的深度。
回溯模板
void backtracking(参数){if(终止条件){存放结果;return;}for(选择:本层集合中元素(数中节点孩子的数量就是集合的大小)){处理节点;backtracking(路径,选择列表);//递归回溯,撤销处理结果 }
}backtracking这里自己调用自己,实现递归。
for循环可以理解是横向遍历,backtracking(递归)就是纵向遍历。

class Solution {public List<List<Integer>> combine(int n, int k) {List<List<Integer>> res = new ArrayList<>();List<Integer> list = new ArrayList<>();for (int i = 1; i <= n; i++) {list.add(i);backtrack(res, list, n, k, i + 1);list.remove(list.size() - 1);}return res;}public void backtrack(List<List<Integer>> res, List<Integer> list, int n, int k, int start) {if (list.size() == k) {res.add(new ArrayList<>(list));return;}for (int i = start; i <= n; i++) {list.add(i);backtrack(res, list, n, k, i + 1);list.remove(list.size() - 1);}}
} 

class Solution {public List<List<Integer>> combinationSum3(int k, int n) {List<List<Integer>> result = new ArrayList<>();List<Integer> list = new ArrayList<>();for (int i = 1; i <= 9; i++) {list.add(i);backtracking(n, k, i + 1, list, result);list.remove(list.size() - 1);}return result;}public void backtracking(int n, int k, int start, List<Integer> list, List<List<Integer>> result) {if (list.size() == k && sum(list) == n) {result.add(new ArrayList<>(list));}for (int i = start; i <= 9; i++) {list.add(i);backtracking(n, k, i + 1, list, result);list.remove(list.size() - 1);if (sum(list) > n) {break;}}}private int sum(List<Integer> list) {int sum = 0;for (int i = 0; i < list.size(); i++) {sum += list.get(i);}return sum;}
}
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;public class day457 {public List<List<Integer>> combinationSum(int[] candidates, int target) {List<List<Integer>> result = new ArrayList<>();Arrays.sort(candidates);backtracking(result, new ArrayList<>(), target, candidates, target, 0);return result;}public void backtracking(List<List<Integer>>result,List<Integer>list,int target,int []candidates,int remain,int start){for (int i = start; i <candidates.length ; i++) {int num = candidates[i];if (remain < num){break;}if (remain == num){result.add(new ArrayList<>(list));}else{backtracking(result,list,target,candidates,remain-num,i);}list.remove(list.size()-1);}}
}Java的格式化输出方法
double res = 3.14159;
System.out.printf("%.2f\n", res); // 输出:3.14(换行)对比 System.out.println:
-
println直接输出变量的原始值,无法控制格式
printf允许通过占位符控制输出格式。
"%.2f\n"
-
%.2f:-
%表示占位符的开始。 -
.2指定小数点后保留两位。 -
f表示浮点数类型(float或double)。 -
例如,若
res = 3.14159,输出会格式化为3.14(自动四舍五入)。
-
-
\n:-
换行符,使后续输出从下一行开始。
后缀数组
-
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;public class BaoLi {public static void main(String[] args) {String s = "banana";System.out.println("暴力排序结果:");System.out.println(bruteForceSort(s));System.out.println("二分+哈希结果:");System.out.println(binaryHashSort(s));}// 暴力排序public static List<String> bruteForceSort(String s) {List<String> suffixes = new ArrayList<>();int n = s.length();for (int i = 0; i < n; i++) {suffixes.add(s.substring(i));}Collections.sort(suffixes);return suffixes;}// 二分+哈希排序private static final int P = 31;private static final int MOD = (int) (1e9 + 9);private static long[] p_pow;private static long[] h;public static List<String> binaryHashSort(String s) {int n = s.length();preprocessHash(s, n);Integer[] suffixIndices = new Integer[n];for (int i = 0; i < n; i++) suffixIndices[i] = i;Arrays.sort(suffixIndices, (i, j) -> compareSuffixes(s, i, j));List<String> suffixes = new ArrayList<>();for (int idx : suffixIndices) suffixes.add(s.substring(idx));return suffixes;}private static void preprocessHash(String s, int n) {p_pow = new long[n + 1];p_pow[0] = 1;for (int i = 1; i <= n; i++) {p_pow[i] = (p_pow[i - 1] * P) % MOD;}h = new long[n + 1];for (int i = 0; i < n; i++) {h[i + 1] = (h[i] * P + (s.charAt(i) - 'a' + 1)) % MOD;}}private static int compareSuffixes(String s, int i, int j) {int n = s.length();int maxLen = Math.min(n - i, n - j);int left = 0, right = maxLen;while (left < right) {int mid = (left + right + 1) >>> 1;long hashI = getHash(i, i + mid - 1);long hashJ = getHash(j, j + mid - 1);if (hashI == hashJ) {left = mid;} else {right = mid - 1;}}// 处理其中一个后缀是另一个的前缀if (i + left == n) return -1;if (j + left == n) return 1;// 比较第一个不同字符return s.charAt(i + left) - s.charAt(j + left);}private static long getHash(int l, int r) {int len = r - l + 1;long hash = (h[r + 1] - h[l] * p_pow[len]) % MOD;return (hash + MOD) % MOD;}
}
String.substring(int beginIndex):
Java中的String.substring(int beginIndex)方法返回从beginIndex开始到字符串末尾的子字符串。例如,如果字符串是"hello",s.substring(1)会返回"ello"
前缀判定

// 对每个 list2 的元素判断是否是 list1 中任意字符串的前缀
// 这是一个增强 for 循环,用于遍历 list2 中的每个元素
// 变量 prefix 代表 list2 中的当前元素
for (String prefix : list2) {// 用于标记是否在 list1 中找到了以 prefix 为前缀的字符串// 初始值设为 false,表示还未找到boolean found = false;// 这是另一个增强 for 循环,用于遍历 list1 中的每个元素// 变量 s 代表 list1 中的当前元素for (String s : list1) {// 使用 startsWith 方法判断 s 是否以 prefix 开头// 如果是,则将 found 标记为 trueif (s.startsWith(prefix)) {found = true;// 一旦找到以 prefix 为前缀的字符串,就跳出当前循环// 因为已经满足条件,无需再继续检查 list1 中的其他元素break; }}// 根据 found 的值输出结果// 如果 found 为 true,输出 "Y",表示找到了以 prefix 为前缀的字符串// 如果 found 为 false,输出 "N",表示未找到System.out.println(found ? "Y" : "N");
}System.out.println(found ? "Y" : "N");//三元运算符字典树
import java.util.Scanner;// 定义主类
public class Main {// 定义字典树节点类static class TrieNode {// 每个节点有 26 个孩子节点,对应 26 个小写英文字母TrieNode[] children = new TrieNode[26];}public static void main(String[] args) {// 创建 Scanner 对象,用于从标准输入读取数据Scanner scan = new Scanner(System.in);// 读取第一个整数 N,表示要插入字典树的字符串数量int N = scan.nextInt();// 读取第二个整数 M,表示要查询的字符串数量int M = scan.nextInt();// 创建字典树的根节点TrieNode root = new TrieNode();// 插入所有字符串到 Trie 中for (int i = 0; i < N; i++) {// 读取一个字符串String s = scan.next();// 调用 insert 方法将字符串插入到字典树中insert(root, s);}// 处理每个查询for (int i = 0; i < M; i++) {// 读取一个查询字符串String t = scan.next();// 调用 query 方法检查该字符串是否是字典树中某个字符串的前缀// 根据查询结果输出 "Y" 或 "N"System.out.println(query(root, t) ? "Y" : "N");}// 关闭 Scanner 对象,释放资源scan.close();}// 插入字符串到字典树的方法private static void insert(TrieNode root, String s) {// 从根节点开始TrieNode current = root;// 遍历字符串的每个字符for (char c : s.toCharArray()) {// 计算字符在 children 数组中的索引,'a' 对应索引 0,'b' 对应索引 1,以此类推int idx = c - 'a';// 如果该索引对应的孩子节点为空if (current.children[idx] == null) {// 创建一个新的节点并赋值给该索引对应的孩子节点current.children[idx] = new TrieNode();}// 移动到该孩子节点current = current.children[idx];}}// 查询字符串是否是字典树中某个字符串的前缀的方法private static boolean query(TrieNode root, String t) {// 从根节点开始TrieNode current = root;// 遍历查询字符串的每个字符for (char c : t.toCharArray()) {// 计算字符在 children 数组中的索引int idx = c - 'a';// 如果该索引对应的孩子节点为空if (current.children[idx] == null) {// 说明该字符串不是字典树中任何字符串的前缀,返回 falsereturn false;}// 移动到该孩子节点current = current.children[idx];}// 如果能遍历完查询字符串的所有字符,说明该字符串是字典树中某个字符串的前缀,返回 truereturn true;}
}