纽约大学具身智能体在城市空间中的视觉导航之旅!CityWalker:从海量网络视频中学习城市导航

- 作者:Xinhao Liu, Jintong Li, Yicheng Jiang, Niranjan Sujay, Zhicheng Yang, Juexiao Zhang, John Abanes, Jing Zhang, Chen Feng
- 单位:纽约大学
- 论文标题:CityWalker: Learning Embodied Urban Navigation from Web-Scale Videos
- 论文链接:https://arxiv.org/abs/2411.17820
- 项目主页:https://ai4ce.github.io/CityWalker/
- 代码链接:https://github.com/ai4ce/CityWalker
主要贡献
- 提出了可扩展的数据驱动方法:通过利用网络规模的城市行走和驾驶视频来训练模型,解决了动态城市环境中导航这一具有挑战性的问题,为实现类人城市导航提供了一种高效且可行的解决方案。
- 设计了简单且可扩展的数据处理范式:无需大量手动标注,仅依靠现成的视觉里程计(VO)模型从视频中提取动作监督信号,即可实现大规模模仿学习,大大降低了数据准备的成本和难度,使模型能够从海量数据中学习到复杂的导航策略。
- 显著提升了导航性能:实验结果表明,在大规模多样化数据集上进行训练能够显著提高导航性能,使智能体能够有效应对城市中的复杂场景和动态变化,超越了现有的方法,为在真实世界中部署自主导航智能体奠定了坚实基础。
研究背景
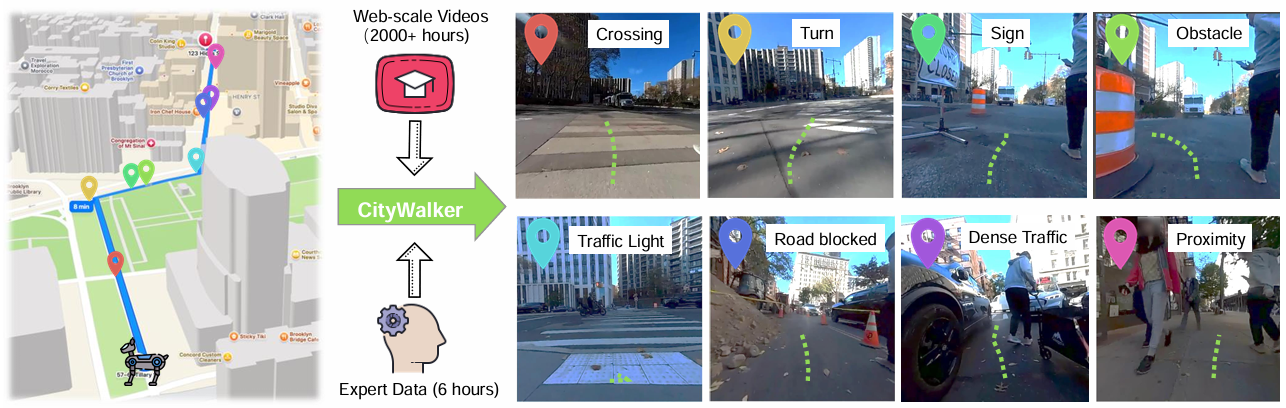
- 视觉导航的重要性:
- 视觉导航对于移动智能体来说是一项至关重要的能力。在城市环境中,人类通常依赖导航工具(如谷歌地图)来规划从当前位置到目标位置的路径,但实际在路径点之间的导航需要智能体具备复杂的空间意识和决策能力,以应对各种动态变化和障碍物。
- 现有方法的局限性:
- 尽管在模拟器或适度复杂环境中取得了一定的进展,但现有的视觉导航方法在没有地图或在街道外的设置中表现不佳,限制了自主智能体(如最后一公里配送机器人)的部署。
- 现实世界的城市环境是动态且不可预测的,充满了多样的地形、障碍物和密集的人群,需要智能体实时适应,并且遵守常识性的导航规则和社会规范,如使用人行道、遵守交通信号、保持适当的人际距离等。
- 这些复杂的行为和约束很难被纳入模拟环境中,导致现有的强化学习和模仿学习方法在真实世界的城市导航中难以取得理想效果。
- 数据驱动方法的潜力:
- 受到语言、视觉和机器人任务中扩展定律成功的启发,论文提出利用丰富的网络视频数据来开发鲁棒的导航策略,以克服现有方法的局限性,实现智能体在动态城市环境中的高效、安全导航。
具身城市导航
问题定义
CityWalker 的目标是让智能体在动态城市环境中从当前位置导航到指定的目标位置。这一任务被定义为一个 点目标导航问题(point-goal navigation problem),具体描述如下:
- 输入:
- 当前时间步 t t t 的 RGB 观测 o t o_t ot。
- 当前 GPS 位置 p t p_t pt。
- 当前子目标路径点 w t w_t wt(由导航工具如谷歌地图提供)。
- 输出:
- 智能体需要学习一个策略 π ( a t ∣ o t − k : t , p t − k : t , w t ) \pi(a_t | o_{t-k:t}, p_{t-k:t}, w_t) π(at∣ot−k:t,pt−k:t,wt),将过去的观测和位置信息映射到动作空间 A A A 中的一个动作 a t a_t at。
- 动作 a t a_t at 表示为欧几里得空间中的动作路径点。
- 模型通常预测未来 5 个时间步的动作,即 k = 5 k = 5 k=5。
目标:智能体需要在到达当前子目标 w t w_t wt 后,根据观测和位置数据判断是否已到达目标,并继续导航到下一个路径点。
评估指标
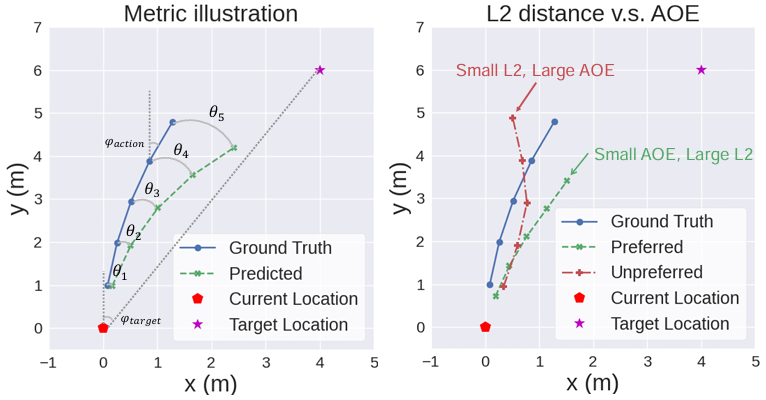
为了全面评估不同方法在城市导航任务中的性能,论文定义了以下评估指标:
-
平均方向误差:
- 用于衡量预测动作与真实动作之间的方向差异。
- 定义为预测动作与真实动作之间的夹角的平均值,公式如下:
AOE ( k ) = 1 n ∑ i = 1 n θ i k = 1 n ∑ i = 1 n arccos ( ⟨ a ^ i k , a i k ⟩ ∥ a ^ i k ∥ ∥ a i k ∥ ) \text{AOE}(k) = \frac{1}{n} \sum_{i=1}^{n} \theta_{ik} = \frac{1}{n} \sum_{i=1}^{n} \arccos \left( \frac{\langle \hat{a}_{ik}, a_{ik} \rangle}{\|\hat{a}_{ik}\| \|a_{ik}\|} \right) AOE(k)=n1i=1∑nθik=n1i=1∑narccos(∥a^ik∥∥aik∥⟨a^ik,aik⟩)
其中, k k k 表示预测动作的索引, n n n 是样本数量, a ^ i k \hat{a}_{ik} a^ik 是预测动作, a i k a_{ik} aik 是真实动作。
-
最大平均方向误差:
- 用于评估预测动作中最大方向误差的平均值,公式如下:
MAOE = 1 n ∑ i = 1 n max k θ i k \text{MAOE} = \frac{1}{n} \sum_{i=1}^{n} \max_{k} \theta_{ik} MAOE=n1i=1∑nkmaxθik - 这一指标可以更好地反映模型在关键时间步上的性能。
- 用于评估预测动作中最大方向误差的平均值,公式如下:
-
关键场景:
- 识别出在导航过程中最关键的几个场景,包括转弯(Turn)、过马路(Crossing)、绕行(Detour)、近距离接触(Proximity)和人群(Crowd)。
- 对每个场景分别计算 AOE 和 MAOE,以更全面地评估模型性能。
从网络视频中学习
为了实现大规模模仿学习,论文利用网络上的城市行走视频作为训练数据。以下是关键步骤:
数据来源
- 收集了超过 2000 小时的网络来源的城市行走视频,涵盖了不同的地理位置、天气条件和时间段。
- 这些视频自然地捕捉了城市环境中导航的复杂性,包括与行人的交互、遵守交通信号以及绕过各种障碍物。
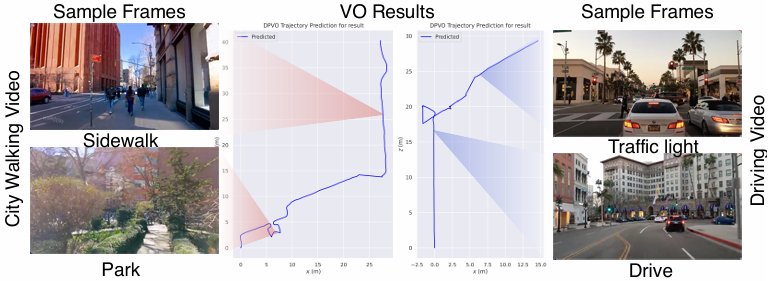
动作标签提取
- 使用视觉里程计(VO)工具(如 DPVO)从视频中提取轨迹姿态,作为动作监督信号。
- 由于 VO 方法存在全局轨迹精度问题和尺度模糊性,论文通过以下方法解决:
- 短时间窗口内的相对姿态:仅依赖于短时间窗口内的相对姿态,避免全局轨迹误差的影响。
- 动作归一化:将每个动作归一化为平均步长。这一步骤解决了不同视频之间的尺度不一致问题。
泛化性和可扩展性
- 该数据处理方法不仅适用于城市行走视频,还可以扩展到其他具有自我运动的视频,如驾驶视频。
- 通过结合城市行走和驾驶视频进行训练,模型能够学习到更通用的导航策略,适用于跨领域和跨体现的任务。
流程管道与训练
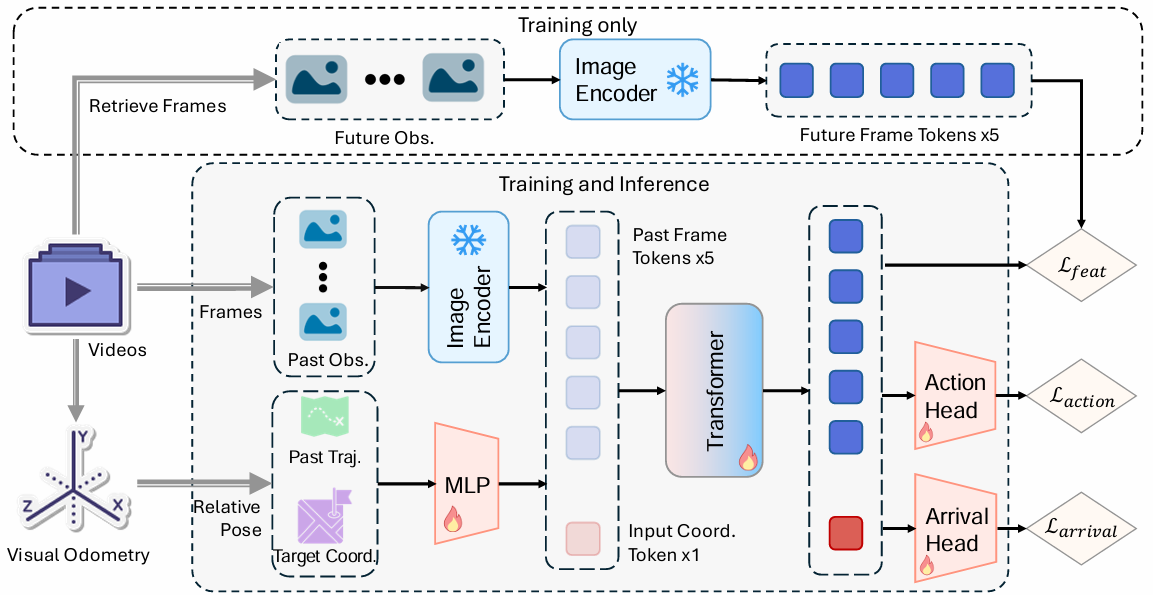
模型架构
- 核心是一个 Transformer,处理包含过去 k k k 帧图像特征和一个坐标嵌入的输入序列。
- 坐标嵌入由过去 k k k 个位置和一个目标位置堆叠而成。
- 输出序列与输入长度相同,通过动作头(Action Head)和到达预测头(Arrival Head)解码为动作和到达状态预测。
特征幻觉
- 作为辅助损失,引导 Transformer 预测更接近未来帧的图像特征。
- 计算输出图像标记与未来帧直接提取的图像标记之间的均方误差损失。
损失函数
- 结合了 L1 损失、方向损失、到达状态的二元交叉熵损失和特征幻觉损失:
L = ω l1 L l1 + ω ori L ori + ω arr L arr + ω feat L feat \mathcal{L} = \omega_{\text{l1}} \mathcal{L}_{\text{l1}} + \omega_{\text{ori}} \mathcal{L}_{\text{ori}} + \omega_{\text{arr}} \mathcal{L}_{\text{arr}} + \omega_{\text{feat}} \mathcal{L}_{\text{feat}} L=ωl1Ll1+ωoriLori+ωarrLarr+ωfeatLfeat
其中,方向损失定义为预测动作和真实动作之间的负余弦相似度:
L ori = − 1 k ∑ i = 1 k ⟨ a ^ i , a i ⟩ ∥ a ^ i ∥ ∥ a i ∥ \mathcal{L}_{\text{ori}} = -\frac{1}{k} \sum_{i=1}^{k} \frac{\langle \hat{a}_i, a_i \rangle}{\|\hat{a}_i\| \|a_i\|} Lori=−k1i=1∑k∥a^i∥∥ai∥⟨a^i,ai⟩
实验
实验设置
-
基线方法:
- GNM:一种通用导航模型,适用于多种机器人。
- ViNT:一种视觉导航基础模型,支持微调。
- NoMaD:一种基于扩散策略的导航模型。
-
数据收集:
- 使用 Unitree Go1 四足机器人进行数据收集,配备 Livox Mid-360 LiDAR 和 Webcam 用于 RGB 观测。
- 使用 LiDAR SLAM 方法获取机器人的姿态作为真实动作标签。
- 在纽约市不同区域收集了 15 小时 的遥操作数据,其中 6 小时 用于微调,9 小时 用于测试。
-
关键场景:
- 转弯(Turn):当真实动作方向变化显著时,定义为 ϕ action > 2 0 ∘ \phi_{\text{action}} > 20^\circ ϕaction>20∘。
- 过马路(Crossing):当检测到交通信号灯时,定义为分数 > 0.5 > 0.5 >0.5。
- 绕行(Detour):当动作方向与目标方向偏差较大时,定义为 ∣ ϕ action − ϕ target ∣ > 4 5 ∘ |\phi_{\text{action}} - \phi_{\text{target}}| > 45^\circ ∣ϕaction−ϕtarget∣>45∘。
- 近距离接触(Proximity):当检测到的行人占据图像面积超过 25% 时。
- 人群(Crowd):当检测到的行人数量 ≥ 5 \geq 5 ≥5 时。
性能基准测试
本小节旨在回答问题 Q1:CityWalker 模型是否能够在复杂的城市环境中成功导航?
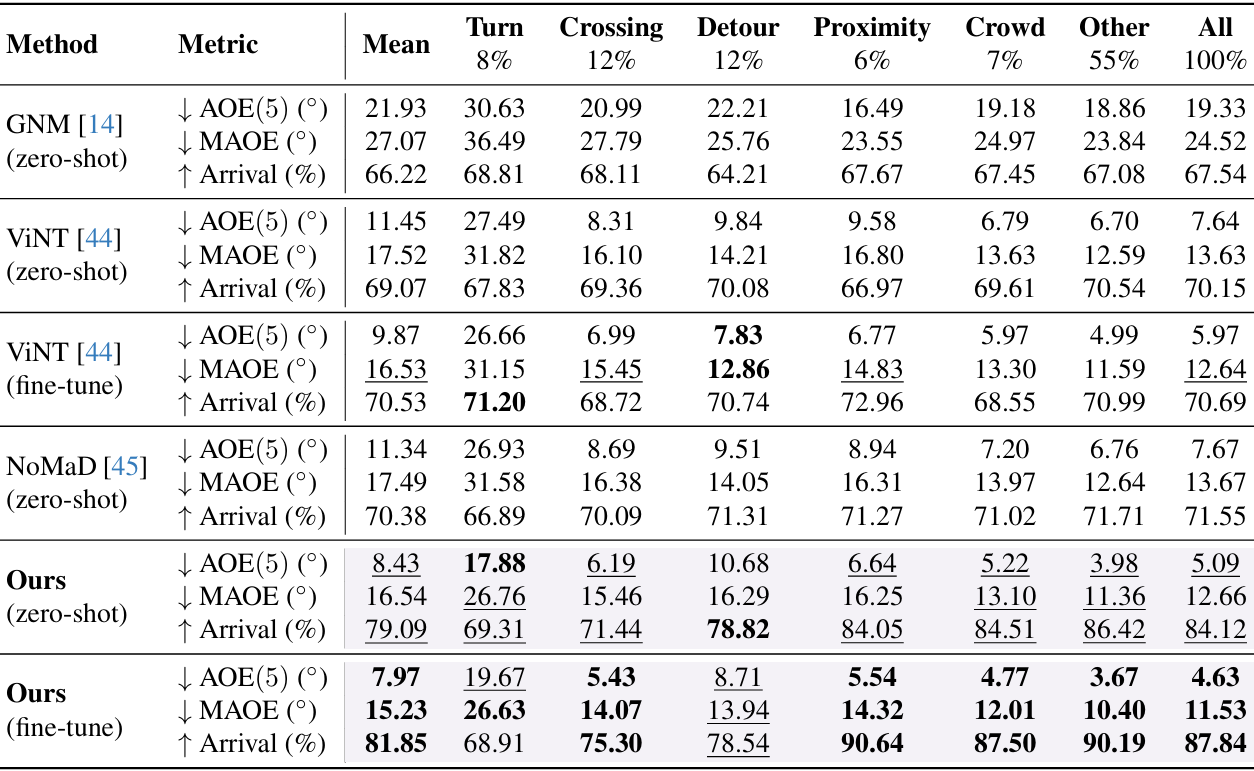
- 离线数据评估:
- 上表展示了不同方法在各种关键场景下的性能对比,主要评估指标为 AOE(5)、MAOE 和 到达率(Arrival Rate)。
- CityWalker 在所有关键场景中均表现出色,尤其是在微调后,其 MAOE 和 到达率 显著优于基线方法。
- 例如,在 转弯(Turn) 场景中,CityWalker 的 MAOE 为 14.07°,而 ViNT 的 MAOE 为 31.15°。
- 在 到达率 方面,CityWalker 在所有场景中的平均到达率为 87.84%,远高于 ViNT 的 70.69%。
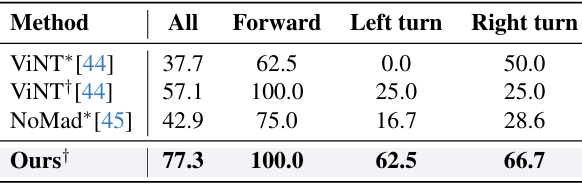
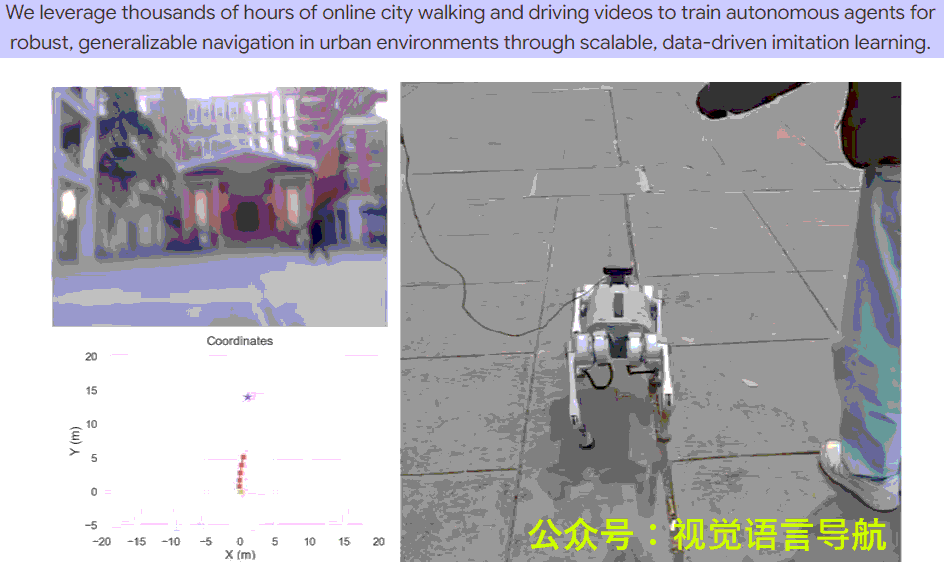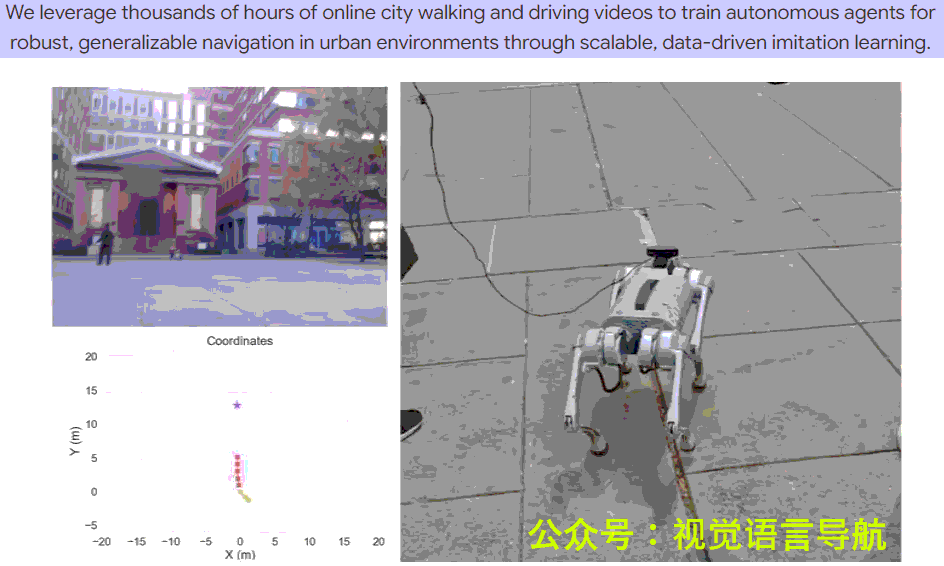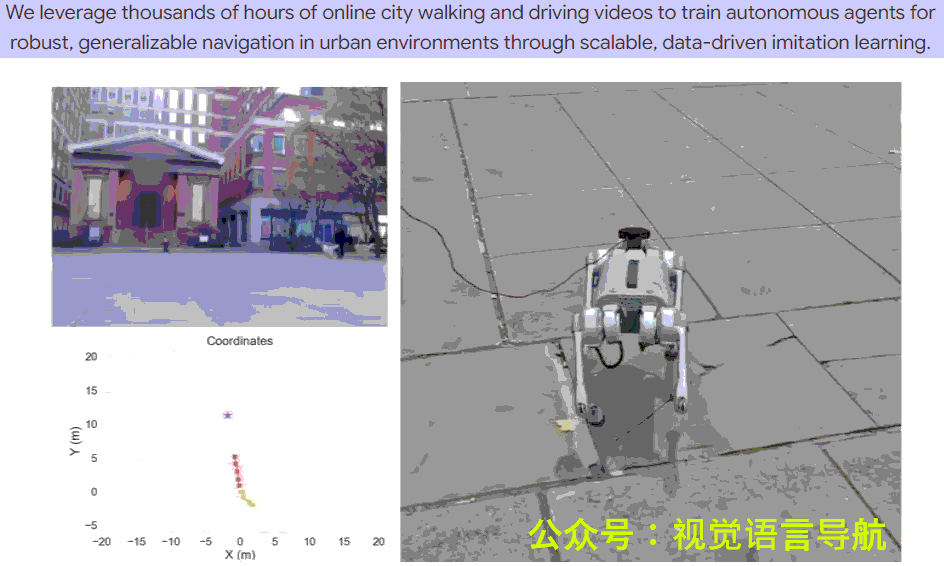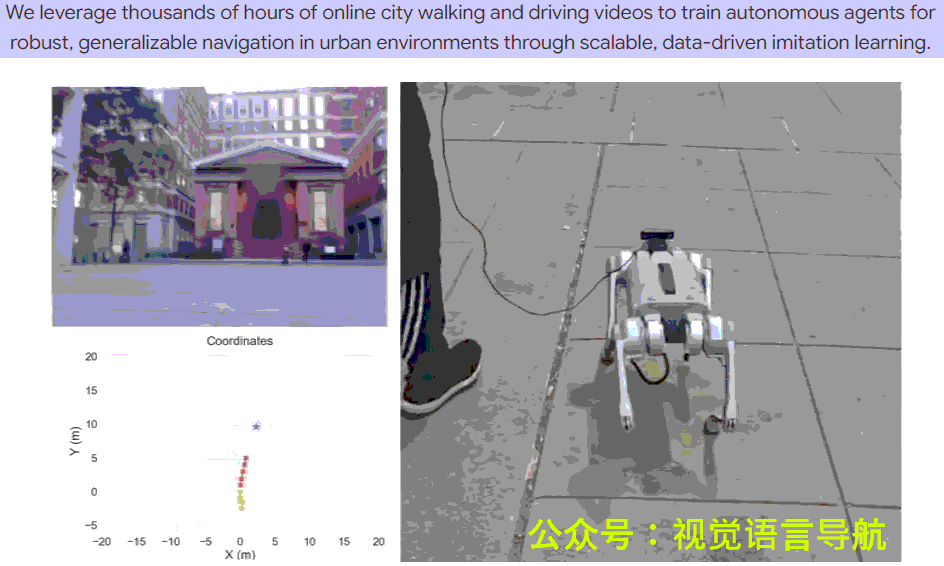
- 真实世界部署:
- 在 Unitree Go1 四足机器人上进行真实世界导航实验,目标位置距离起始位置约 50-100 米。
- 实验分为 前进(Forward)、左转(Left turn) 和 右转(Right turn) 三种情况,每种情况进行 8-14 次试验。
- 上表显示了不同方法的成功率,CityWalker 在所有情况下均表现出色,整体成功率达到 77.3%,显著高于 ViNT 的 57.1% 和 NoMaD 的 42.9%。
- 这表明 CityWalker 能够有效应对城市环境中的复杂动态变化,具有更强的适应性和可靠性。

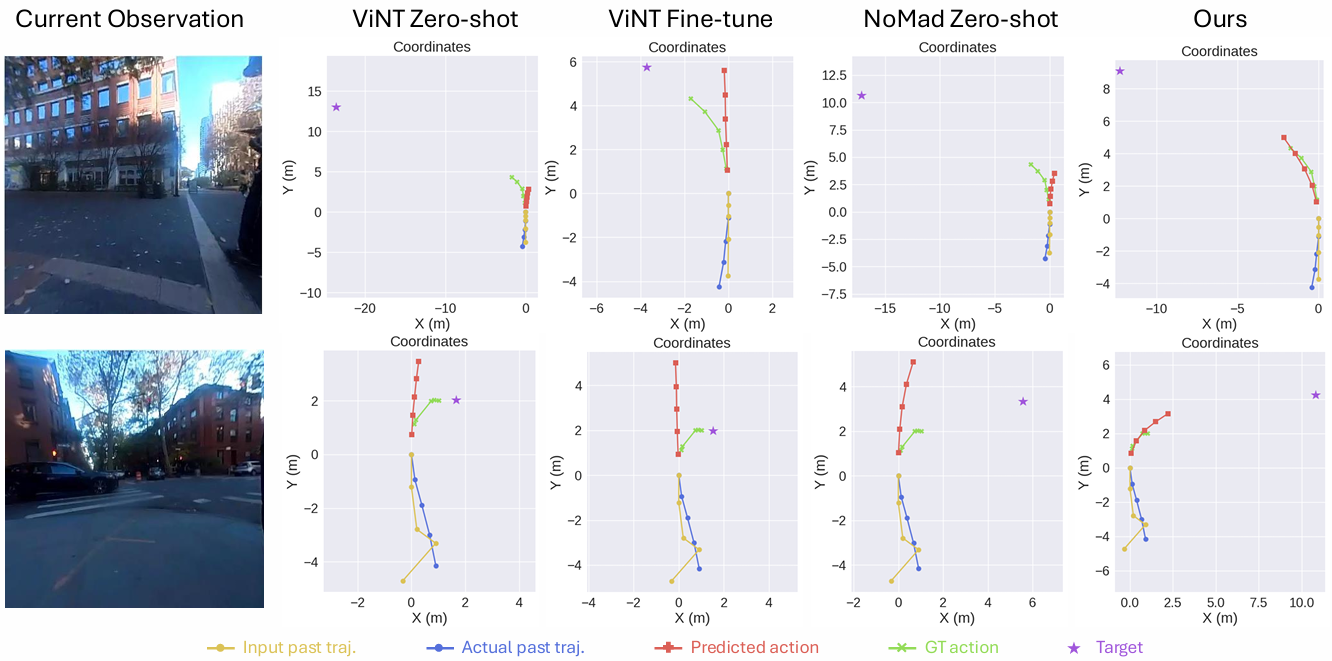
数据扩展优势
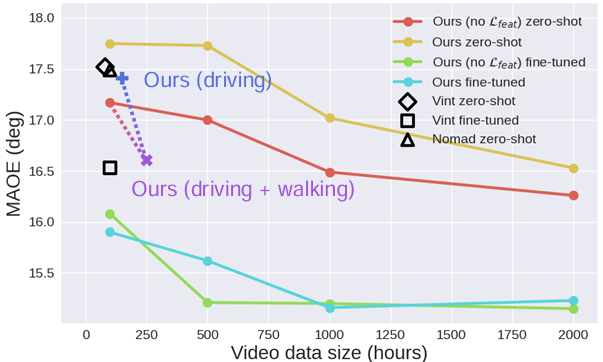
本小节旨在回答问题 Q2:增加训练数据量是否能够显著提升模型性能?
-
性能与数据量关系:
- 上图展示了模型在不同数据量下的性能变化,以 MAOE 为评估指标。
- 结果表明,随着训练数据量的增加,CityWalker 的零样本性能显著提升。
- 当训练数据量超过 1000 小时时,CityWalker 的零样本性能甚至超过了经过微调的 ViNT 模型。
- 这表明大规模训练数据能够显著提升模型的导航性能,即使在没有微调的情况下也能取得优异结果。
-
跨领域数据:
- 论文还评估了仅使用驾驶视频以及结合驾驶和行走视频训练的模型性能。
- 结果显示,仅使用驾驶视频训练的模型性能与基线方法相当,但结合两种视频训练的模型性能显著提升。
- 例如,使用 250 小时的混合数据训练的模型性能接近使用 1000 小时行走数据单独训练的模型,这表明跨领域数据能够显著提升模型的泛化能力。
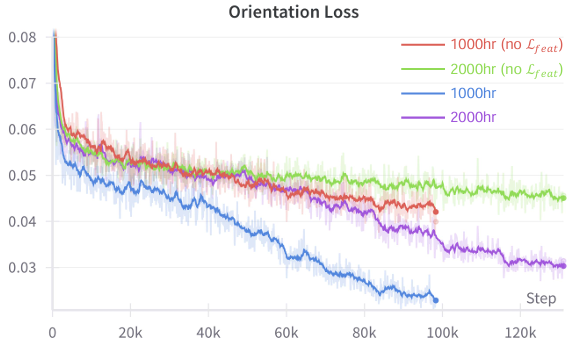
- 特征幻觉损失:
- 上图展示了不同训练设置下的损失曲线。
- 结果表明,使用特征幻觉损失的训练方法在大规模数据上能够更快收敛,并且在微调后能够进一步提升性能。
- 这表明特征幻觉损失在大规模训练中具有显著优势,能够提升模型的泛化能力。
模型组件分析
本小节旨在回答问题 Q3:模型的各个组件如何提升其性能和可靠性?
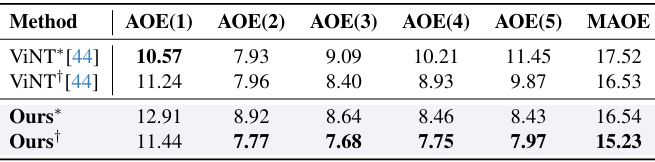
- 不同时间步的 AOE:
- 上表展示了不同方法在不同时间步的 AOE。
- CityWalker 在多个时间步上保持了较低且稳定的 AOE,而 ViNT 的 AOE 随着时间步的增加而显著上升。
- 这表明 CityWalker 在多步预测中具有更好的稳定性和准确性,适合真实世界中的复杂导航任务。
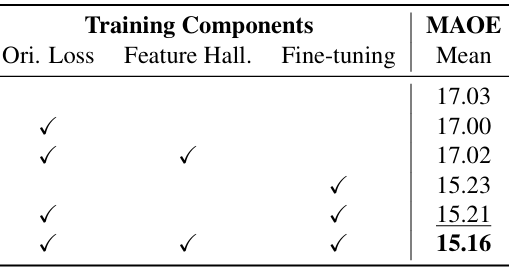
- 消融研究:
- 上表展示了不同训练组件对模型性能的影响。
- 结果表明,微调阶段使用专家数据能够显著提升模型性能,MAOE 从 17.03° 降低到 15.16°。
- 特征幻觉损失和方向损失对性能的提升作用较小,但在大规模数据训练中仍具有一定的改进效果。
结论与未来工作
- 总结:
- CityWalker通过利用大规模网络视频数据,显著提升了城市导航的性能,证明了数据扩展对于开发鲁棒导航策略的潜力。
- 该研究不仅提出了一种有效的数据驱动方法来解决动态城市环境中的导航问题,还通过实验验证了其在真实世界中的可行性和优越性,为未来智能体在复杂城市环境中的自主导航研究提供了新的思路和方向。
- 局限性:
- 在真实世界部署中,该方法对较大的GPS误差敏感,这是由于简单的位置数据处理方法无法有效处理显著的位置不准确,可能会导致导航决策出现偏差,从而影响导航的成功率和准确性。
- 未来工作:
- 将重点关注提高模型对位置噪声的鲁棒性,以增强模型在实际应用中的稳定性和可靠性。
- 此外,还可以进一步探索如何更好地利用多源数据(如不同类型的传感器数据、不同模态的数据等)来进一步提升模型的性能和泛化能力,以及如何将模型应用于更广泛的场景和任务中,推动智能体在复杂动态环境中的自主导航技术的发展。
