空间数据工程——如何使用 Python 和 ArcPy 对 Vision Zero 多边形的值进行地理处理
1.了解项目要求
ArcGIS Pro 中的 Python 脚本在简化跨图层字段计算方面发挥了关键作用Final_Output,并合并了以下多个字段:
该项目的核心是基于空间关系将值从一个空间图层赋值到另一个空间图层。设想这样一个场景:我们必须从一个图层提取邮政编码、工程区域或扇区等值,并在另一个图层中更新相交的多边形。然而,由于目标图层中存在条件选择和多个赋值,简单的空间连接并不可行。以下是任务的细分:
- 将邮政编码、APD 部门和信号工程区域图层的值分配给主要要素图层Final_Output中的多边形。
- 每个多边形可以与多个区域(邮政编码、部门等)相交,需要目标字段中唯一的、以逗号分隔的值。
- 使用 Python 脚本自动化工作流程以确保可重复性和效率。
我们将每个空间连接视为数据转换,从而使该项目与核心数据工程原则保持一致。
2. ArcGIS Pro 中 Vision Zero 多边形的高效现场制图和数据准备
对于像 Vision Zero 这样的复杂 GIS 项目来说,准确高效的数据准备至关重要。本文将引导您完成 ArcGIS Pro 中现场映射和数据重构的精简流程,以生成Final_Output符合 Vision Zero 项目特定数据结构要求的要素类。
步骤 1:定义字段映射过程
Final_Output_5基于要素类创建的第一个最终输出Final_Output_4需要符合 Vision Zero 标准和项目特定要求的一致方案。简而言之,分析中使用了特定字段。为了实现这一点,我:
Final_Output_4保留了先前 GIS 开发人员创建的现有数据集 () 中的关键字段。- 根据需要重命名或重新格式化字段以符合新规范。
- 引入了程序分析所需的几个新字段,例如交叉口、信号工程区域和时间戳元数据。
以下是 PostgreSQL 数据库中所需字段结构及其类型的概述:
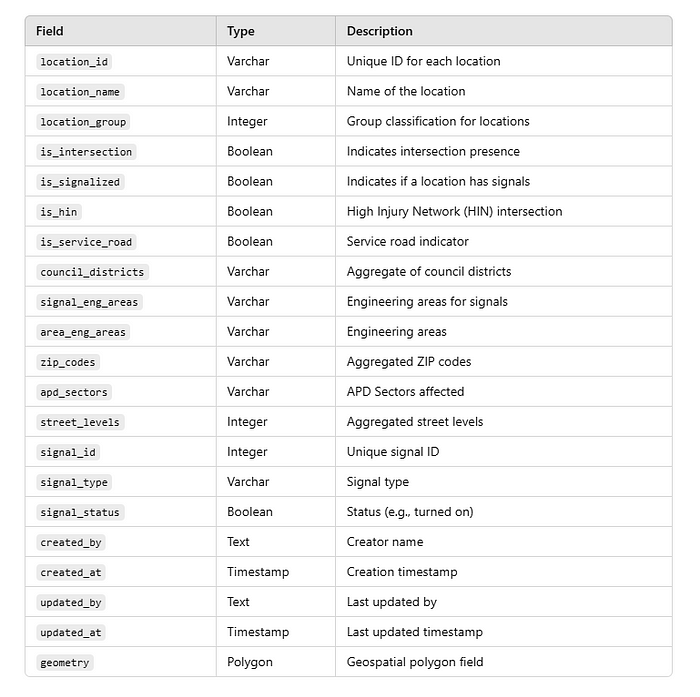
步骤 2:使用 Python 和 ArcPy 进行字段映射
下面的 Python 脚本可以自动执行字段映射,从而提高灵活性和效率。通过设置一个FieldMappings对象,我可以控制新要素类中的字段顺序和类型。编写此脚本后,我收到了一些添加更多字段的请求。新请求的字段(signal_type、signal_status 等)未出现在以下代码中。
import arcpy
# 定义旧要素图层和新输出图层的路径
old_feature_layer = r"...\Polygon Update\Default.gdb\Final_Output_4"output_path = r"...\Polygon Update\Polygon Update\Default.gdb"output_name = "Final_Output_5" # 新要素类的输出名称# 创建 FieldMappings 对象
field_mappings = arcpy.FieldMappings() # 步骤 1:根据需要保留和重命名字段 fields_to_keep= { 'Location_ID' : 'location_id' , 'description' : 'location_name' , 'STREET_LEVEL' : 'street_levels' , 'IS_INTERSECTION' : 'is_intersection' , 'IS_SVRD' : 'is_service_road' , 'counci_district' : 'council_districts'}
# 循环重命名字段并将其添加到 FieldMappings
for old_field_name, new_field_name in fields_to_keep.items(): try : field_map = arcpy.FieldMap() field_map.addInputField(old_feature_layer, old_field_name) # 重命名字段output_field = field_map.outputField output_field.name = new_field_name field_map.outputField = output_field field_mappings.addFieldMap(field_map) except Exception as e: print ( f"Error processing field {old_field_name} : {e} " ) # 步骤 2:根据指定将新字段添加到架构
new_fields = [ { 'name' : 'location_group' , 'type' : 'LONG' }, { 'name' : 'is_signalized' , 'type' : 'SHORT' }, { 'name':'is_hin','type':'SHORT' },{ 'name':'signal_eng_areas','type':'TEXT','length':50 },{ 'name':'area_eng_areas','类型':'TEXT','长度':50 },{ '名称':'zip_codes','类型':'TEXT','长度':10 },{ 'name':'apd_sectors','类型':'TEXT','长度':10 },{ 'name':'signal_id','类型':'LONG' },{ 'name':'created_by','类型':'TEXT','长度':50 },{ 'name':'created_at','类型':'DATE' },{ 'name':'updated_by','类型':'TEXT','长度':50 },{ 'name':'updated_at','类型':'DATE' }, { 'name' : 'geometry' , 'type' : 'POLYGON' }
]
# 循环添加新字段
for new_field in new_fields: field_map = arcpy.FieldMap() new_field_def = arcpy.Field() new_field_def.name = new_field[ 'name' ] new_field_def. type = new_field[ 'type' ] if 'length' in new_field: new_field_def.length = new_field[ 'length' ] field_map.outputField = new_field_def field_mappings.addFieldMap(field_map)
# 步骤 3:创建新的要素类
arcpy.FeatureClassToFeatureClass_conversion(old_feature_layer, output_path, output_name, field_mapping=field_mappings)
print ( f"Feature layer ' {output_name} ' created with specified fields." )步骤 3:完成并验证字段映射
- 组织字段:运行脚本后,按照字段要求的顺序排列字段。验证所有字段(保留的和新建的)是否符合项目需求。
- 检查和验证:确保所有字段的字段映射完整且正确,确认每个字段都按照指定方式映射并且具有一致的数据类型和约束。
3. 准备转换数据
验证和构建字段
现在,是时候为字段填充值了。GIS 数据工程的第一步是确保源图层和目标图层中的字段结构正确。我们检查了每个字段的数据类型、长度和约束。
示例:调整字段长度以适应多值存储。为了存储多个相交值(例如,邮政编码或部门名称),我调整了字段长度以适应更长的逗号分隔字符串。我使用 实现了此操作arcpy.management.AlterField。您可以在流程的不同阶段运行此操作,因此最终输出的名称中带有 X。
arcpy.management.AlterField( "Final_Output_X","邮政编码",字段长度= 255 )
这种调整确保我们在处理过程中不会遇到截断错误。
修复几何体
复杂数据集可能包含无效几何图形,这会导致空间分析出现问题。为了解决这个问题,我RepairGeometry在两个图层上都使用了该工具,以避免在交叉操作中出现无效拓扑问题。
arcpy.management.RepairGeometry( "Final_Output_X" )
arcpy.management.RepairGeometry( "ZIPCodes_CopyFeatures" )4. 构建数据转换管道
使用 Python 和 ArcPy,我创建了一个高效的工作流程来转换和更新我们的主要图层。Final_Output在整个项目过程中,我保存了一份最终输出的副本,并在末尾添加一个数字,以便识别我在哪个阶段做了什么。然而,为了避免让这篇文章变得枯燥乏味,我不会逐一介绍所有的字段计算,也没有在 GitHub 仓库中创建相应的文件,因为其中一些计算非常简单,或者可以通过多种方式完成,例如,is_intersection根据多边形是否在交叉点处创建,在字段下为其分配 0 和 1:
def is_intersection_location ( location_name ): # 检查 location_name 中是否有两条街道(用逗号表示)if ',' in location_name: return 1 # True return 0 # False # 为每个多边形应用函数
is_intersection_location(!location_name!)将多个邮政编码分配给单个多边形的示例脚本
处理一对多关系(单个多边形可能与多个邮政编码、APD 分区或议会选区相交)在整个项目中至关重要。我在 ArcPy 中构建了数据转换流程,以识别这些交集并将多个值合并到单个字段中,从而保持复杂空间数据的清晰度。对于每个转换(邮政编码、分区等),我都运行了空间连接并将相交值分配给Final_Output。每个脚本都会捕获交集并更新目标图层中的值。
导入arcpy # 设置图层
final_output_layer = "Final_Output_13"zip_layer = "ZIPCodes_CopyFeatures" # 创建用于空间选择的要素图层
arcpy.management.MakeFeatureLayer(final_output_layer, "final_layer" )
arcpy.management.MakeFeatureLayer(zip_layer, "zip_layer" ) # 创建更新游标以迭代 Final_Output_13 中的多边形
with arcpy.da.UpdateCursor( "final_layer" , [ "OID@" , "SHAPE@" , "zip_codes" ]) as final_cursor: for final_row in final_cursor: final_polygon = final_row[ 1 ] # 多边形的几何形状zip_codes = set () # 使用集合存储唯一的邮政编码# 选择与当前多边形相交的邮政编码区域arcpy.management.SelectLayerByLocation( "zip_layer" , "INTERSECT" , final_polygon) # 创建搜索游标以检查所选邮政编码with arcpy.da.SearchCursor( "zip_layer" , [ "ZIPCODE" ]) as zip_cursor: for zip_row in zip_cursor: zip_code = str (zip_row[ 0 ]) # 将邮政编码转换为字符串进行存储zip_codes.add(zip_code) # 如果找到任何邮政编码,则将连接的值分配给 zip_codes 字段final_row[ 2 ] = ", " .join( sorted (zip_codes)) if zip_codes else None # 更新行final_cursor.updateRow(final_row) # 清除选择
arcpy.management.SelectLayerByAttribute( "zip_layer" , "CLEAR_SELECTION" )
arcpy.management.SelectLayerByAttribute( “最终图层”,“清除选择”)守则解释
- SelectLayerByLocation:此命令从中选择
ZIPCodes_CopyFeatures与每个多边形相交的特征Final_Output_13。 - 基于集合的存储:通过将值存储在集合中,我们确保每个邮政编码在最终的逗号分隔列表中仅出现一次。
- 字段更新:我们使用更新游标来修改中的每一行
Final_Output_13,确保我们的数据转换过程直接而高效。
5.确保灵活性和自动化
数据工程的核心在于创建可重复的工作流程,我们的脚本确保每次转换(无论是针对邮政编码、扇区还是信号区域)都能保持一致性。每个脚本都可以轻松修改,只需更新图层名称和字段映射即可处理不同的字段或空间图层。
灵活性示例:APD 部门转型
经过微小调整,我们使用相同的代码结构来处理 APD 扇区:
导入arcpy # 设置图层
final_output_layer = "Final_Output_13"apd_layer = "APDSectors_CopyFeatures" # 创建用于空间选择的要素图层
arcpy.management.MakeFeatureLayer(final_output_layer, "final_layer" )
arcpy.management.MakeFeatureLayer(apd_layer, "apd_layer" ) # 创建更新游标以迭代 Final_Output_13 中的多边形
with arcpy.da.UpdateCursor( "final_layer" , [ "OID@" , "SHAPE@" , "apd_sectors" ]) as final_cursor: for final_row in final_cursor: final_polygon = final_row[ 1 ] # 多边形的几何形状apd_sectors = set () # 使用集合存储唯一的扇区名称# 选择与当前多边形相交的 APD 扇区arcpy.management.SelectLayerByLocation( "apd_layer" , "INTERSECT" , final_polygon) # 创建搜索游标以检查选定的 APD 扇区with arcpy.da.SearchCursor( "apd_layer" , [ "SECTOR_NAME" ]) as apd_cursor: for apd_row in apd_cursor: sector_name = apd_row[ 0 ] apd_sectors.add(sector_name) # 添加唯一的扇区名称# 如果找到任何扇区,则将连接的值分配给 apd_sectors 字段final_row[ 2 ] = ", " .join( sorted (apd_sectors)) if apd_sectors else None # 更新行final_cursor.updateRow(final_row) # 清除选择
arcpy.management.SelectLayerByAttribute( "apd_layer" , arcpy.management.SelectLayerByAttribute( "最终层" , "CLEAR_SELECTION " )这种模块化结构使我们能够创建适用于不同空间层和属性字段的灵活脚本。
灵活性示例:基于另一个分类进行分类
在这种情况下,我必须为 Final_Output_12 中另一个名为“area_eng_areas”的字段赋值。这些值来自另一个名为“Area_Engineering_CopyFeatures”的图层中的字段,其中一个名为 COUNCIL_DISTRICT 的字段记录了从 1 到 10 的数字。数字 1 和 9 代表中央,2、3、5 和 8 代表南部,4、6、7 和 10 代表北部。一个面要素可能与 Area_Engineering_CopyFeatures 图层中的两个或多个要素相交。在这种情况下,我需要用逗号分隔它们。例如,如果 Final_Output_12 中的一个面与 COUNCIL_DISTRICT 字段中的值 9 和 3 相交,那么 Final_Output_12 中 area_eng_areas 的赋值必须是“CENTRAL, SOUTH”。如果多边形与指向一个方向的相同数字相交,例如“NORTH, NORTH”,则无需重复“NORTH”。只需使用一个“NORTH”。
导入arcpy # 设置图层
final_output_layer = "Final_Output_12"engineering_layer = "Area_Engineering_CopyFeatures" # 定义议会区域到方向的映射
district_mapping = { 1 : "CENTRAL" , 9 : "CENTRAL" , 2 : "SOUTH" , 3 : "SOUTH" , 5 : "SOUTH" , 8 : "SOUTH" , 4 : "NORTH" , 6 : "NORTH" , 7 : "NORTH" , 10 : "NORTH"} # 如果字段不存在,则添加该字段
if "area_eng_areas" not in [f.name for f in arcpy.ListFields(final_output_layer)]: arcpy.AddField_management(final_output_layer, "area_eng_areas" , "TEXT" ) # 制作特征用于空间选择的图层
arcpy.management.MakeFeatureLayer(final_output_layer, "final_layer" )
arcpy.management.MakeFeatureLayer(engineering_layer, "engineering_layer" ) # 创建更新游标以迭代 Final_Output_12 中的多边形
with arcpy.da.UpdateCursor( "final_layer" , [ "OID@" , "SHAPE@" , "area_eng_areas" ]) as final_cursor: for final_row in final_cursor: final_oid = final_row[ 0 ] # 获取用于空间选择的 OIDfinal_polygon = final_row[ 1 ] # 多边形的几何形状direction = set () # 使用集合存储唯一方向# 选择与当前多边形相交的工程区域arcpy.management.SelectLayerByLocation( "engineering_layer" , "INTERSECT" , final_polygon) # 创建搜索使用arcpy.da.SearchCursor( "engineering_layer" , [ " SHAPE @" ,“COUNCIL_DISTRICT” ])作为eng_cursor:对于eng_cursor中的eng_row :council_district = int (eng_row[ 1 ]) # 确保议会区是一个整数if council_district in district_mapping: Directions.add(district_mapping[council_district]) # 如果找到任何区域,则将连接的值分配给 area_eng_areas 字段final_row[ 2 ] = ", " .join( sorted (directions)) if Directions else None # 更新行final_cursor.updateRow(final_row) # 清除选择
arcpy.management.SelectLayerByAttribute( "engineering_layer" , "CLEAR_SELECTION" )
arcpy.management.SelectLayerByAttribute( "final_layer" , "CLEAR_SELECTION" )关键步骤:
- 定义映射:
district_mapping将理事会区 ID(1-10)转换为方向类别。 - 如果缺失则添加字段:检查字段
area_eng_areas并Final_Output_12在需要时添加。 - 空间选择:对于每个多边形,选择相交的工程区域,检索理事会区域,并使用将它们映射到方向
district_mapping。 - 更新字段:将方向合并到逗号分隔的列表中,
area_eng_areas以捕获多个相交的值。 - 清除选择:删除残留选择以确保清洁的环境。
这种方法可以处理单个字段中的多个相交类别,确保每个多边形的方向数据唯一且准确。
6. 洞察与反思
该项目展示了地理空间数据工程的几个关键方面:
- 数据结构和字段管理:正确设置字段和处理文本限制对于避免错误至关重要。
- 几何验证:处理之前修复和验证几何有助于避免空间分析中常见的陷阱。
- 自动化脚本:Python 和 ArcPy 能够创建高效、可重复的流程,实现手动工作流程中繁琐的空间数据转换。
在 GIS 中,数据工程涉及空间连接、几何管理和数据转换,这些对于可靠且富有洞察力的分析至关重要。借助 Python 和 ArcPy,我们可以将强大的数据工程实践应用于空间数据,从而设置数据,以便在地理空间分析中准确有效地使用。