音视频学习 - MP3格式
环境
JDK 13
IDEA Build #IC-243.26053.27, built on March 16, 2025
Demo
MP3Parser
MP3
MP3全称为MPEG Audio Layer 3,它是一种高效的计算机音频编码方案,它以较大的压缩比将音频文件转换成较小的扩展名为.mp3的文件,基本保持源文件的音质,MP3是ISO/MPEG标准的一部分,
ISO/MPEG标准描述了使用高性能感知编码方案的音频压缩,此标准一直在不断更新以满足“质高量小”的追求,现已形成MPEG Layer1、Layer2、Layer3三种音频编解码方案,分别对应MP1、MP2、MP3 这三种声音文件
了解下MP3的编码方式
静态码率(CBR):Constants Bits Rate是一种固定采样率的压缩方式
这种编码方式不需要文件头,第一帧开始就是音频数据
(1)优点:压缩快,能被大多数软件和设备支持。
(2)缺点:占用空间大,效果不是十分理想。现已逐渐被VBR方式取代。
动态码率(VBR):Variable Bit Rate使用这个方式时,可以选择从最差音质/最大压缩比到最好音质/最低压缩比之间的种种过渡级数,在MP3文件编码之时,程序会尝试保持所选定的整个文件的品质,将选择适合音乐文件不同部分的不同比特率来编码。
需要文件头
(1)优点:可以让整首歌都能大致达到我们的音质要求。
(2)缺点:编码时无法估计压缩出来的文件体积大小
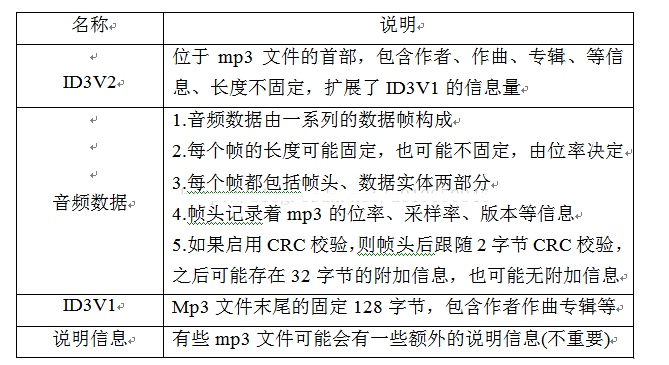
文件结构
一般可分为以下三部分
来自参考3
配合具体的解析的开源工程来理解
mp3agic-Java写的读写mp3的开源库
因为工程是以前的,遇到些问题,费了些时间,编译出mp3agic的jar包
查看该工具加载MP3文件代码,从中也可以看出,分成Id3v1,音频,Id3v2和自定义的部分
// Mp3File.java
private void init(int bufferLength, boolean scanFile) throws IOException, UnsupportedTagException, InvalidDataException {if (bufferLength < MINIMUM_BUFFER_LENGTH + 1) throw new IllegalArgumentException("Buffer too small");this.bufferLength = bufferLength;this.scanFile = scanFile;try (SeekableByteChannel seekableByteChannel = Files.newByteChannel(path, StandardOpenOption.READ)) {// 加载Id3v1initId3v1Tag(seekableByteChannel);// 加载音频帧部分scanFile(seekableByteChannel);if (startOffset < 0) {throw new InvalidDataException("No mpegs frames found");}// 加载Id3v2部分initId3v2Tag(seekableByteChannel);if (scanFile) {// 加载自定义部分initCustomTag(seekableByteChannel);}}}ID3V1
ID3 V1.0标准并不周全,存放的信息少,无法存放歌词,无法录入专辑封面、图片等。
此标准是将MP3文件尾的最后128个字节用来存放ID3信息
| 字节 | 长度(字节) | 说明 |
|---|---|---|
| 1-3 | 3 | 存放”TAG”字符,表示ID3V1.0标准,紧接其后的是歌曲信息 |
| 4-33 | 30 | 歌名 |
| 34-63 | 30 | 作者 |
| 64-93 | 30 | 专辑名 |
| 94-97 | 4 | 年份 |
| 98-127 | 30 | 附注 |
| 128 | 1 | MP3音乐类别,共147种 |
音乐类型具体可以看 ID3v1Geners.java中定义的枚举或者本文后的参考3
0="Blues";
1="ClassicRock";
2="Country";
3="Dance";
4="Disco";
5="Funk";
6="Grunge";
7="Hip-Hop";
8="Jazz";
9="Metal";
10="NewAge";
11="Oldies";
12="Other";
13="Pop";
14="R&B";
15="Rap";
16="Reggae";
17="Rock";
18="Techno";
...
143="Salsa";
144="Trashl";
145="Anime";
146="JPop";
147="Synthpop";
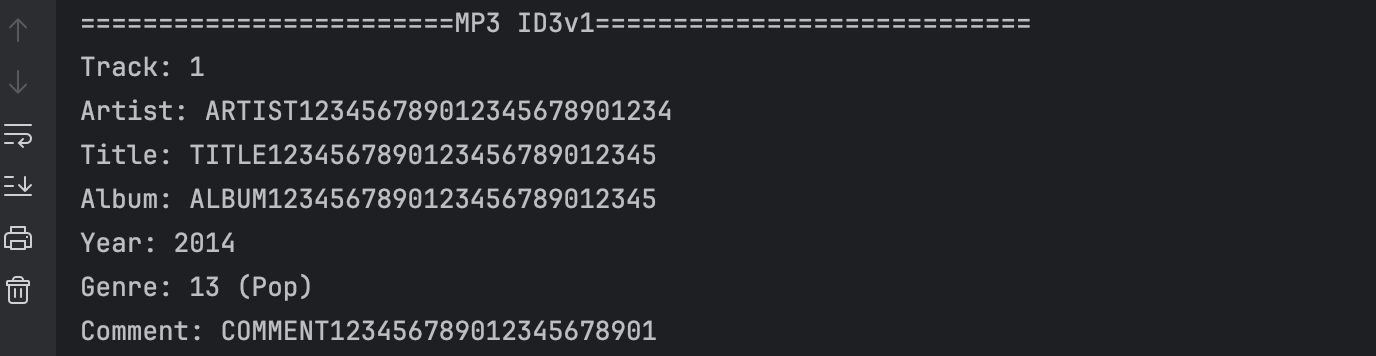
验证
// Main.java
public class Main {public static void main(String[] args) throws InvalidDataException, UnsupportedTagException, IOException {Main parse = new Main();String filename = "resource/v24tagswithalbumimage.mp3";...}
}
public void getID3v1Tag (String filename) throws InvalidDataException, UnsupportedTagException, IOException {System.out.println("\n========================MP3 ID3v1============================");Mp3File mp3file = new Mp3File(filename);if (mp3file.hasId3v1Tag()) {ID3v1 id3v1Tag = mp3file.getId3v1Tag();System.out.println("Track: " + id3v1Tag.getTrack());System.out.println("Artist: " + id3v1Tag.getArtist());System.out.println("Title: " + id3v1Tag.getTitle());System.out.println("Album: " + id3v1Tag.getAlbum());System.out.println("Year: " + id3v1Tag.getYear());System.out.println("Genre: " + id3v1Tag.getGenre() + " (" + id3v1Tag.getGenreDescription() + ")");System.out.println("Comment: " + id3v1Tag.getComment());}}
private void initId3v1Tag(SeekableByteChannel var1) throws IOException {// 创建128个字节的大小缓冲区ByteBuffer var2 = ByteBuffer.allocate(128);// 文件对象指向尾部 - 128的位置var1.position(this.getLength() - 128L);var2.clear();// 读取128个字节int var3 = var1.read(var2);if (var3 < 128) {throw new IOException("Not enough bytes read");} else {try {// 创建id3vTag对象。将128个字节传入this.id3v1Tag = new ID3v1Tag(var2.array());} catch (NoSuchTagException var5) {// 不是以TAG开头抛出异常在这里捕获,是否有Id3v1这个就是判断该属性// public boolean hasId3v1Tag() {// return this.id3v1Tag != null;// }this.id3v1Tag = null;}}}
private void unpackTag(byte[] var1) throws NoSuchTagException {// 是否以TAG开头this.sanityCheckTag(var1);// 这里就是根据协议读取指定区间,然后转成对应的内容this.title = BufferTools.trimStringRight(BufferTools.byteBufferToStringIgnoringEncodingIssues(var1, 3, 30));this.artist = BufferTools.trimStringRight(BufferTools.byteBufferToStringIgnoringEncodingIssues(var1, 33, 30));this.album = BufferTools.trimStringRight(BufferTools.byteBufferToStringIgnoringEncodingIssues(var1, 63, 30));this.year = BufferTools.trimStringRight(BufferTools.byteBufferToStringIgnoringEncodingIssues(var1, 93, 4));// 音乐类型this.genre = var1[127] & 255;if (this.genre == 255) {this.genre = -1;}// 读取附注if (var1[125] != 0) {this.comment = BufferTools.trimStringRight(BufferTools.byteBufferToStringIgnoringEncodingIssues(var1, 97, 30));this.track = null;} else {this.comment = BufferTools.trimStringRight(BufferTools.byteBufferToStringIgnoringEncodingIssues(var1, 97, 28));byte var2 = var1[126];if (var2 == 0) {this.track = "";} else {this.track = Integer.toString(var2);}}}
// 最后调用String,然后编码格式是ISO-8859-1,应该不支持中文
public static String byteBufferToStringIgnoringEncodingIssues(byte[] var0, int var1, int var2) {try {return byteBufferToString(var0, var1, var2, defaultCharsetName);} catch (UnsupportedEncodingException var4) {return null;}
}
音频帧
来自参考1
每个帧都有一个帧头,长度是四个字节,帧后面可能有2字节的CRC校验,取决于帧头的第16位,为0则无校验,为1则有校验,后面是可变长度的附加信息,对于标准的MP3文件来说,其长度是32字节,紧接其后的是压缩的声音数据,当解码器读到此处时就进行解码了。
| 名称 | 长度(字节) | 属性 |
|---|---|---|
| 帧头 | 4 | 必存在 |
| CRC | 2 | 可能存在 |
| Side Info | 32 | 必存在 |
| 声音数据 | N | 必存在 |
typedef FrameHeader {unsigned int sync:11; // 同步信息unsigned int version:2; // 版本unsigned int layer: 2; // 层unsigned int error protection:1; // 是否要CRC校验unsigned int bitrate_index:4; // 位率unsigned int sampling_frequency:2; // 采样频率unsigned int padding:1; // 帧长调节unsigned int private:1; // 保留字unsigned int mode:2; // 声道模式unsigned int mode extension:2; // 扩充模式unsigned int copyright:1; // 版权unsigned int original:1; // 原版标志unsigned int emphasis:2; // 强调模式
}HEADER, *LPHEADER;
| 名称 | 位长 | 第几字节 | 说明 |
|---|---|---|---|
| 同步信息 | 11 | 1~2 | 所有位均为1,第1字节恒为FF |
| 版本 | 2 | 2 | 00-MPEG 2.5 01-未定义 10-MPEG2 11-MPEG 1 |
| 层 | 2 | 2 | 00-未定义 01-Layer 3 10-Layer 2 11-Layer 1 |
| CRC校验 | 1 | 2 | 0-校验 1-不校验 |
| 位率 | 4 | 3 | 取样率,单位为kbs。详见下表 |
| 采样频率 | 2 | 3 | MPEG-1: 00:44.1kHz 01:48kHz 10:32kHz 11-未定义 |
| MPEG-2: 00:22.05kHz 01:24kHz 10:16kHz 11-未定义 | |||
| MPEG-2.5: 00:11.025kHz 01:12kHz 10:8kHz 11-未定义 | |||
| 帧长调节 | 1 | 3 | 用于调整文件头长度,0:无需调整 1:调整 |
| 保留字 | 1 | 3 | 没有使用 |
| 声道模式 | 2 | 4 | 00:立体声Stereo 01:Joint Stereo 10:双声道 11:单声道 |
| 扩充模式 | 2 | 4 | 当声道模式为01时才使用 |
| 版权 | 1 | 4 | 0:不合法 1:合法 |
| 原版标志 | 1 | 4 | 是否原版, 0: 非原版,1:原版 |
| 强调方式 | 2 | 4 | 用于声音降噪压缩后再补偿的分类,很少用到 |
位率
V1: MPEG 1
V2: MPEG 2 和 MPEG 2.5
L1: Layer 1
L2: Lyaer 2
L3: Layer 3
| bits | V1,L1 | V1,L2 | V1,L3 | V2,L1 | V2,L2 | V2,L3 |
|---|---|---|---|---|---|---|
| 0000 | free | free | free | free | free | free |
| 0001 | 32 | 32 | 32 | 32(32) | 32(8) | 8(8) |
| 0010 | 64 | 48 | 40 | 64(48) | 48(16) | 16(16) |
| 0011 | 96 | 56 | 48 | 96(56) | 56(24) | 24(24) |
| 0100 | 128 | 64 | 56 | 128(64) | 64(32) | 32(32) |
| 0101 | 160 | 80 | 64 | 160(80) | 80(40) | 64(40) |
| 0110 | 192 | 96 | 80 | 192(96) | 96(48) | 80(48) |
| 0111 | 224 | 112 | 96 | 224(112) | 112(56) | 56(56) |
| 1000 | 256 | 128 | 112 | 256(128) | 128(64) | 64(64) |
| 1001 | 288 | 160 | 128 | 288(144) | 160(80) | 128(80) |
| 1010 | 320 | 192 | 160 | 320(160) | 192(96) | 160(96) |
| 1011 | 352 | 224 | 192 | 356(176) | 224(112) | 112(112) |
| 1100 | 384 | 256 | 224 | 384(192) | 256(128) | 128(128) |
| 1101 | 416 | 320 | 256 | 416(224) | 320(144) | 256(144) |
| 1110 | 448 | 384 | 320 | 448(256) | 384(160) | 320(160) |
| 1111 | bad | bad | bad | bad | bad | bad |
帧大小即每帧的采样数,表示一帧数据中采样的个数,该值是恒定的
MP3的帧大小是1152
帧长度是压缩时每一帧的长度,包括帧头的4个字节。它将填充的空位也计算在内。Layer 2和Layer 3的空位是1字节。当读取MPEG文件时必须计算该值以便找到相邻的帧
计算公式:
Layer2/3:Len(字节) = ((每帧采样数/8*比特率)/采样频率)+填充
例:MPEG1 Layer3 比特率128000,采样率44100,填充0,帧长度为:((1152/8*128K)/44.1K+0=417字节
帧持续时间
计算公式:
每帧持续时间(毫秒) = 每帧采样数 / 采样频率 * 1000
例:1152/441000*1000=26ms
帧头后边是Side Info。对标准的立体声MP3文件来说其长度为32字节。当解码器在读到上述信息后,就可以进行解码了
验证
读取音频数据帧头
// Mp3File.java
// 初始化方法
...
// 传MP3文件
scanFile(seekableByteChannel);
...
// Mp3File.java
private void scanFile(SeekableByteChannel seekableByteChannel) throws IOException, InvalidDataException {// 读取MP3文件的缓冲区ByteBuffer byteBuffer = ByteBuffer.allocate(bufferLength);// <1>获取音频帧的起始位置int fileOffset = preScanFile(seekableByteChannel);seekableByteChannel.position(fileOffset);boolean lastBlock = false;int lastOffset = fileOffset;while (!lastBlock) {byteBuffer.clear();int bytesRead = seekableByteChannel.read(byteBuffer);byte[] bytes = byteBuffer.array();// 最后一帧字节长度小于缓冲区长度if (bytesRead < bufferLength) lastBlock = true;if (bytesRead >= MINIMUM_BUFFER_LENGTH) {while (true) {try {int offset = 0;// <2>音频首帧的处理if (startOffset < 0) {offset = scanBlockForStart(bytes, bytesRead, fileOffset, offset);if (startOffset >= 0 && !scanFile) {return;}lastOffset = startOffset;}// <3>读取音频帧offset = scanBlock(bytes, bytesRead, fileOffset, offset);// 文件偏移量fileOffset += offset;// 更新文件的偏移量seekableByteChannel.position(fileOffset);break;} catch (InvalidDataException e) {if (frameCount < 2) {startOffset = -1;xingOffset = -1;frameCount = 0;bitrates.clear();lastBlock = false;fileOffset = lastOffset + 1;if (fileOffset == 0)throw new InvalidDataException("Valid start of mpeg frames not found", e);seekableByteChannel.position(fileOffset);break;}return;}}}}}
<1> 获取文件偏移量
protected int preScanFile(SeekableByteChannel seekableByteChannel) {ByteBuffer byteBuffer = ByteBuffer.allocate(AbstractID3v2Tag.HEADER_LENGTH);try {seekableByteChannel.position(0);byteBuffer.clear();int bytesRead = seekableByteChannel.read(byteBuffer);// ID3v2的表头 10个字节if (bytesRead == AbstractID3v2Tag.HEADER_LENGTH) {try {byte[] bytes = byteBuffer.array();ID3v2TagFactory.sanityCheckTag(bytes);// 音频帧的起始位置是通过表头的10个字节 + f(表头最后的4个字节)计算出来,后面可知就是ID3v2的结构体的sizereturn AbstractID3v2Tag.HEADER_LENGTH + BufferTools.unpackSynchsafeInteger(bytes[AbstractID3v2Tag.DATA_LENGTH_OFFSET], bytes[AbstractID3v2Tag.DATA_LENGTH_OFFSET + 1], bytes[AbstractID3v2Tag.DATA_LENGTH_OFFSET + 2], bytes[AbstractID3v2Tag.DATA_LENGTH_OFFSET + 3]);} catch (NoSuchTagException | UnsupportedTagException e) {// do nothing}}} catch (IOException e) {// do nothing}return 0;}
规则代码如下
public static int shiftByte(byte c, int places) {// c 位与 0xff 那还是原来的字节,只保留低8位int i = c & 0xff;// < 0 ,i向左位移// > 0 , i向右位移,虽然这里传的都是<0,考虑大端的场景应该是兼容if (places < 0) {return i << -places;} else if (places > 0) {return i >> places;}return i;}public static int unpackSynchsafeInteger(byte b1, byte b2, byte b3, byte b4) {// b4是size的最低位 => size[3]// b3是size[2]// ...// & 0x7f就是只保留该位,然后通过位移得到该位的值,然后相加计算出ID3v2的总长度int value = ((byte) (b4 & 0x7f));value += shiftByte((byte) (b3 & 0x7f), -7);value += shiftByte((byte) (b2 & 0x7f), -14);value += shiftByte((byte) (b1 & 0x7f), -21);return value;}
<2>音频首帧的处理
private int scanBlockForStart(byte[] bytes, int bytesRead, int absoluteOffset, int offset) {while (offset < bytesRead - MINIMUM_BUFFER_LENGTH) {// 音频帧头同步: 11位都要是1 = 0b1111 1111 1110 000。低位与E0要等于E0if (bytes[offset] == (byte) 0xFF && (bytes[offset + 1] & (byte) 0xE0) == (byte) 0xE0) {try {// 初始化音频帧,帧头有4个字节MpegFrame frame = new MpegFrame(bytes[offset], bytes[offset + 1], bytes[offset + 2], bytes[offset + 3]);// 因为VBR是Xing公司发明的,所以音频首帧里会留"痕迹",位于MP3文件中第一个有效帧的数据区if (xingOffset < 0 && isXingFrame(bytes, offset)) {xingOffset = absoluteOffset + offset;xingBitrate = frame.getBitrate();offset += frame.getLengthInBytes();} else {// 非VBRstartOffset = absoluteOffset + offset;channelMode = frame.getChannelMode();emphasis = frame.getEmphasis();layer = frame.getLayer();modeExtension = frame.getModeExtension();sampleRate = frame.getSampleRate();version = frame.getVersion();copyright = frame.isCopyright();original = frame.isOriginal();// 帧数量加1frameCount++;// 帧率添加到集合中,如果有不同多个值说明是VBRaddBitrate(frame.getBitrate());offset += frame.getLengthInBytes();return offset;}} catch (InvalidDataException e) {offset++;}} else {offset++;}}return offset;}
这里按音频帧头的格式填充
public MpegFrame(byte frameData1, byte frameData2, byte frameData3, byte frameData4) throws InvalidDataException {long frameHeader = BufferTools.unpackInteger(frameData1, frameData2, frameData3, frameData4);setFields(frameHeader);}private void setFields(long frameHeader) throws InvalidDataException {long frameSync = extractField(frameHeader, BITMASK_FRAME_SYNC);if (frameSync != FRAME_SYNC) throw new InvalidDataException("Frame sync missing");setVersion(extractField(frameHeader, BITMASK_VERSION));setLayer(extractField(frameHeader, BITMASK_LAYER));setProtection(extractField(frameHeader, BITMASK_PROTECTION));setBitRate(extractField(frameHeader, BITMASK_BITRATE));setSampleRate(extractField(frameHeader, BITMASK_SAMPLE_RATE));setPadding(extractField(frameHeader, BITMASK_PADDING));setPrivate(extractField(frameHeader, BITMASK_PRIVATE));setChannelMode(extractField(frameHeader, BITMASK_CHANNEL_MODE));setModeExtension(extractField(frameHeader, BITMASK_MODE_EXTENSION));setCopyright(extractField(frameHeader, BITMASK_COPYRIGHT));setOriginal(extractField(frameHeader, BITMASK_ORIGINAL));setEmphasis(extractField(frameHeader, BITMASK_EMPHASIS));}判断是否是"Xing"帧
private boolean isXingFrame(byte[] bytes, int offset) {if (bytes.length >= offset + XING_MARKER_OFFSET_1 + 3) {if ("Xing".equals(BufferTools.byteBufferToStringIgnoringEncodingIssues(bytes, offset + XING_MARKER_OFFSET_1, 4)))return true;if ("Info".equals(BufferTools.byteBufferToStringIgnoringEncodingIssues(bytes, offset + XING_MARKER_OFFSET_1, 4)))return true;if (bytes.length >= offset + XING_MARKER_OFFSET_2 + 3) {if ("Xing".equals(BufferTools.byteBufferToStringIgnoringEncodingIssues(bytes, offset + XING_MARKER_OFFSET_2, 4)))return true;if ("Info".equals(BufferTools.byteBufferToStringIgnoringEncodingIssues(bytes, offset + XING_MARKER_OFFSET_2, 4)))return true;if (bytes.length >= offset + XING_MARKER_OFFSET_3 + 3) {if ("Xing".equals(BufferTools.byteBufferToStringIgnoringEncodingIssues(bytes, offset + XING_MARKER_OFFSET_3, 4)))return true;if ("Info".equals(BufferTools.byteBufferToStringIgnoringEncodingIssues(bytes, offset + XING_MARKER_OFFSET_3, 4)))return true;}}}return false;}
<3>读取音频帧
private int scanBlock(byte[] bytes, int bytesRead, int absoluteOffset, int offset) throws InvalidDataException {while (offset < bytesRead - MINIMUM_BUFFER_LENGTH) {// 同样传4字节的帧头初始化MpegFrameMpegFrame frame = new MpegFrame(bytes[offset], bytes[offset + 1], bytes[offset + 2], bytes[offset + 3]);// 帧信息不一致容错处理,会抛异常sanityCheckFrame(frame, absoluteOffset + offset);int newEndOffset = absoluteOffset + offset + frame.getLengthInBytes() - 1;// 要给ID3v1留128个字节位置if (newEndOffset < maxEndOffset()) {endOffset = absoluteOffset + offset + frame.getLengthInBytes() - 1;frameCount++;addBitrate(frame.getBitrate());offset += frame.getLengthInBytes();} else {break;}}return offset;}
ID3V2
ID3V2一共有四个版本,ID3V2.1/2.2/2.3/2.4
ID3V2.3由一个标签头和若干个标签帧或者一个扩展标签头组成,至少要有一个标签帧,每一个标签帧记录一种信息,例如作曲、标题等
标签头
位于文件开始处,长度为10字节
char Header[3]; /*必须为“ID3”否则认为标签不存在*/
char Ver; /*版本号ID3V2.3 就记录3*/
char Revision; /*副版本号此版本记录为0*/// 标志字节一般为0,定义如下(abc000000B)
// a:表示是否使用Unsynchronisation
// b:表示是否有扩展头部,一般没有,所以一般也不设置
// c:表示是否为测试标签,99.99%的标签都不是测试标签,不设置
char Flag; /*标志字节,只使用高三位,其它位为0 */// 标签大小共四个字节,每个字节只使用低7位,最高位不使用恒为0,计算公式如下:
// Size = (Size[0] & 0x7F) * 0x200000 + (Size[1] & 0x7F) * 0x400+(Size[2] & 0x7F) * 0x80 + (Size[3] & 0x7F)
char Size[4]; /*标签大小*/
标签帧
每个标签帧都有10个字节的帧头和至少一个字节的内容构成
// TIT2: 标题5449 5432
// TPE1: 作者
// TALB: 专集
// TRCK: 音轨格式 N/M 其中N为专集中的第N首,M为专集中共M首,N和M 为ASCII 码表示的数字
// TYPE: 年代
// COMM: 备注,格式: "eng\0备注内容",其中eng 表示备注所使用的自然语言
char ID[4]; /*标识帧,说明其内容,例如作者/标题等*/
// 帧内容大小,计算公式如下:
// Size = Size[0]*0x100000000 + Size[1]*0x10000+ Size[2]*0x100 +Size[3];
char Size[4]; /*帧内容的大小,不包括帧头,不得小于1*/
// 标志帧,使用每个字节的高三位,其他位均为0(abc00000B xyz00000B)
// a -- 标签保护标志,设置时认为此帧作废
// b -- 文件保护标志,设置时认为此帧作废
// c -- 只读标志,设置时认为此帧不能修改
// x -- 压缩标志,设置时一个字节存放两个BCD 码表示数字
// y -- 加密标志
// z -- 组标志,设置时说明此帧和其他的某帧是一组
char Flags[2]; /*标志帧,只定义了6 位*/
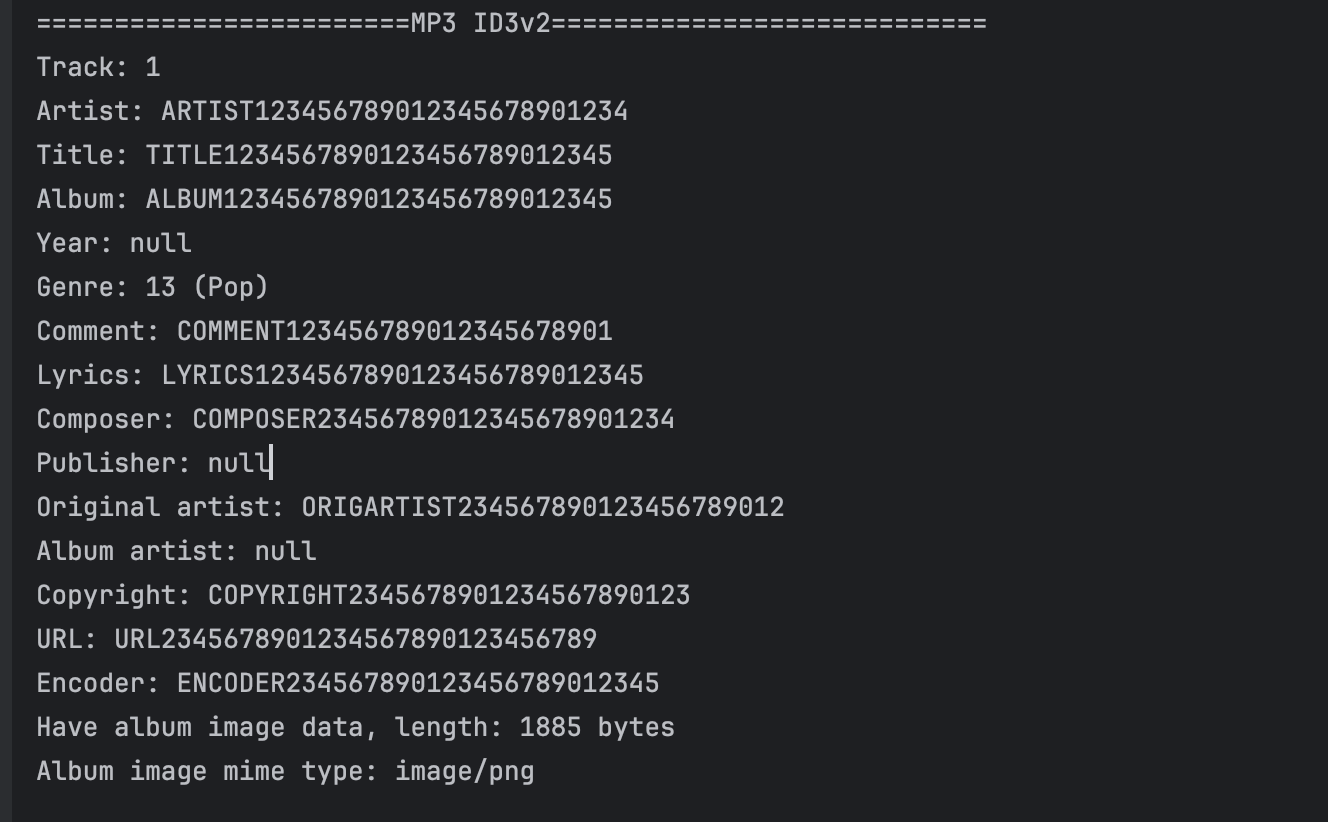
验证
打印MP3文件中的Id3v2
...
public void getID3v2Tag(String filename) throws InvalidDataException, UnsupportedTagException, IOException {System.out.println("\n========================MP3 ID3v2============================");Mp3File mp3file = new Mp3File(filename);if (mp3file.hasId3v2Tag()) {ID3v2 id3v2Tag = mp3file.getId3v2Tag();System.out.println("Track: " + id3v2Tag.getTrack());System.out.println("Artist: " + id3v2Tag.getArtist());System.out.println("Title: " + id3v2Tag.getTitle());System.out.println("Album: " + id3v2Tag.getAlbum());System.out.println("Year: " + id3v2Tag.getYear());System.out.println("Genre: " + id3v2Tag.getGenre() + " (" + id3v2Tag.getGenreDescription() + ")");System.out.println("Comment: " + id3v2Tag.getComment());System.out.println("Lyrics: " + id3v2Tag.getLyrics());System.out.println("Composer: " + id3v2Tag.getComposer());System.out.println("Publisher: " + id3v2Tag.getPublisher());System.out.println("Original artist: " + id3v2Tag.getOriginalArtist());System.out.println("Album artist: " + id3v2Tag.getAlbumArtist());System.out.println("Copyright: " + id3v2Tag.getCopyright());System.out.println("URL: " + id3v2Tag.getUrl());System.out.println("Encoder: " + id3v2Tag.getEncoder());byte[] albumImageData = id3v2Tag.getAlbumImage();if (albumImageData != null) {System.out.println("Have album image data, length: " + albumImageData.length + " bytes");System.out.println("Album image mime type: " + id3v2Tag.getAlbumImageMimeType());}}}
...
结果如下
从网上下载的一些mp3文件因为是静态码率,所以没有标签头,用Sublime Text打开后就是

用FFmpeg把pcm压缩编码为mp3会加上
$ ffmpeg -y -i v24tagswithalbumimage.mp3 -acodec pcm_s16le -f s16le -ac 2 -ar 44100 v24tagswithalbumimage.pcm
v24tagswithalbumimage.mp3文件的二进制
标签头
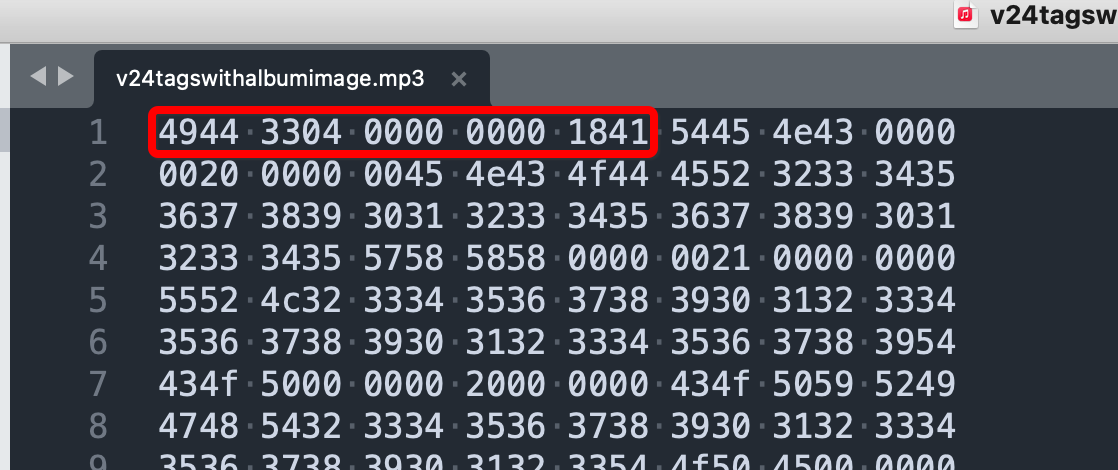
Header[3] + Version是4944 3304:就是 ID3v2和 第4版
Revision:0
Flag:0 不使用Unsynchronisation,没有扩展头,非测试标签
Size[4]是1841根据上面提到的公式
Size = (Size[0] & 0x7F) * 0x200000 + (Size[1] & 0x7F) * 0x400+(Size[2] & 0x7F) * 0x80 + (Size[3] & 0x7F)
计算: (0x18 & 0x7F) * 0x80 + (0x41 & 0x7F)
= 0x18 * 0x80 + 0x41
= 3137
加上头的10个字节,所以mp3文件的ID3v2部分是 3147
这个调试的时候也可以验证
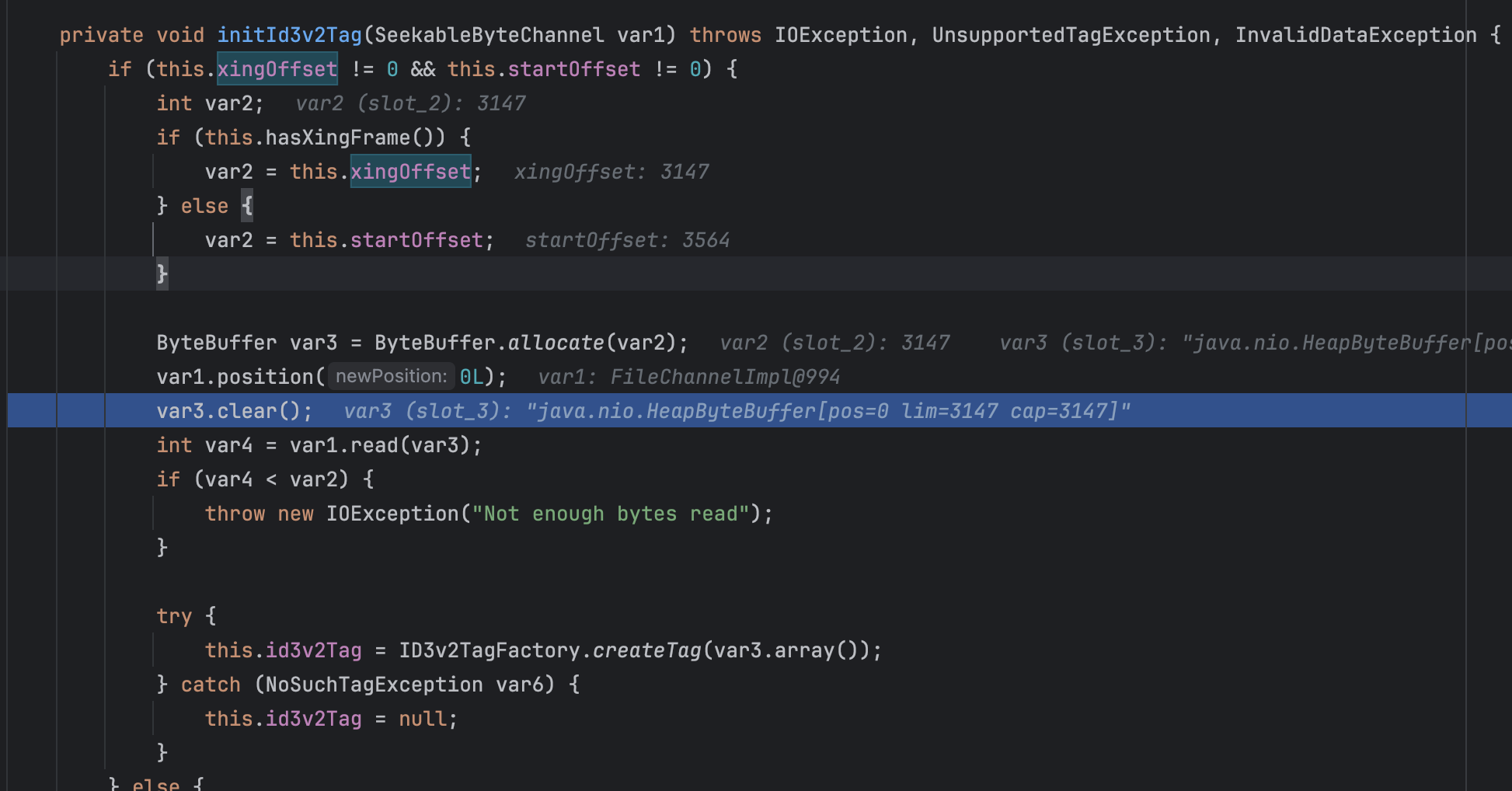
var1 是mp3文件, var3 是被认为ID3v2的内容。
寻找首个音频帧
// 根据ID3v2的size + 上面的公式 + ID3v2的文件头
0x1841 => 0x41 + 0x18 << 7 = 3137
3137 + 10 = 31473147 = 196 * 16 + 11

根据前4个字节 0xfffb9044
0b1111 1111 111/ 11 / 01 / 0 / 1001 / 00 / 0 / 0 / 01 / 00 0 / 1 / 00
同步信息: 0xfffb 前11个都是1
版本:11-说明是MPEG 1
层:01-说明是Layer 3 是MP3符合预期
CRC: 0 不校验
位率: 1001,因为是MPEG 1 + Layer 3,根据上面的码表 取样率:128kbps
采样率: 00,因为是MPEG 1说明是44.1kHz
帧长调节: 0,无需调整
保留字: 0
声道模式: 01 .Joint 关闭强度立体声 + MS立体声
扩充模式: 00
版权:0,不合法
原版:1,原版
强调方式: 00
参考
- 音频格式之MP3:(1)MP3封装格式简介
- 静态码率(CBR)和动态码率(VBR)
- MP3文件结构解析(超详细)