KAN 与 MLP 的深入比较
柯尔莫哥洛夫-阿诺德网络 (KAN) 和多层感知器 (MLP) 之间有什么区别,以及在深度学习中使用它们各自的优势是什么?
本文将探讨 KAN 背后的数学基础及其对深度神经网络的巧妙运用。KAN 从深度学习的可解释性和可解释性角度展现了许多新的可能性,但在实际应用中也存在一系列问题。请继续阅读,了解 KAN 与 MLP 之间的区别,并加深理解。
深度学习中的柯尔莫哥洛夫-阿诺德表示定理
柯尔莫哥洛夫-阿诺德表示定理确立了任何多元函数都可以分解为不同单变量函数的和,从而简化了复杂函数的计算。
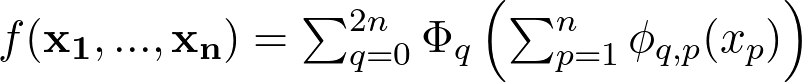
柯尔莫哥洛夫-阿诺德表示定理的一般方程。
内部函数 (𝟇) 是输入数据的初始变换,与多层感知器 (MLP) 不同,它可能是非线性变换,即使用单个变量的信息进行任意阶的变换。另一方面,外部函数 ( 𝚽 ) 决定了原始多变量函数中不同变量之间的复杂相互作用。
内部函数学习与每个变量相关的模式,因为正如我们在下面的等式中看到的,每个内部函数都与一个变量相关。另一方面,通过外部函数,我们捕捉不同变量之间的相互作用。这样,柯尔莫哥洛夫-阿诺德表示定理假设原始的多变量函数可以分解为复杂度较低的函数,这些函数既能捕捉变量之间的关系,又能捕捉每个变量的模式。
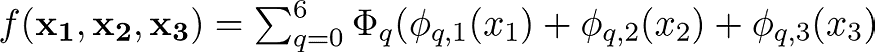
原始多元函数中每个变量的内部函数和外部函数。每个𝟇只与一个变量相互作用,而变量之间的任何相互作用都应该由𝚽考虑。
在 KAN 中,内部函数和外部函数的处理方式相同,在原始实现中使用 B 样条函数。当 KAN 的多层级联时,初始层始终表示柯尔莫哥洛夫-阿诺德表示定理中的内部函数,而第二层将作为前一层的外部函数,然后第二层将被视为第三层的内部函数。这样,第一层之上的每一层都将捕捉多元函数的组成模式。此过程如下图所示:
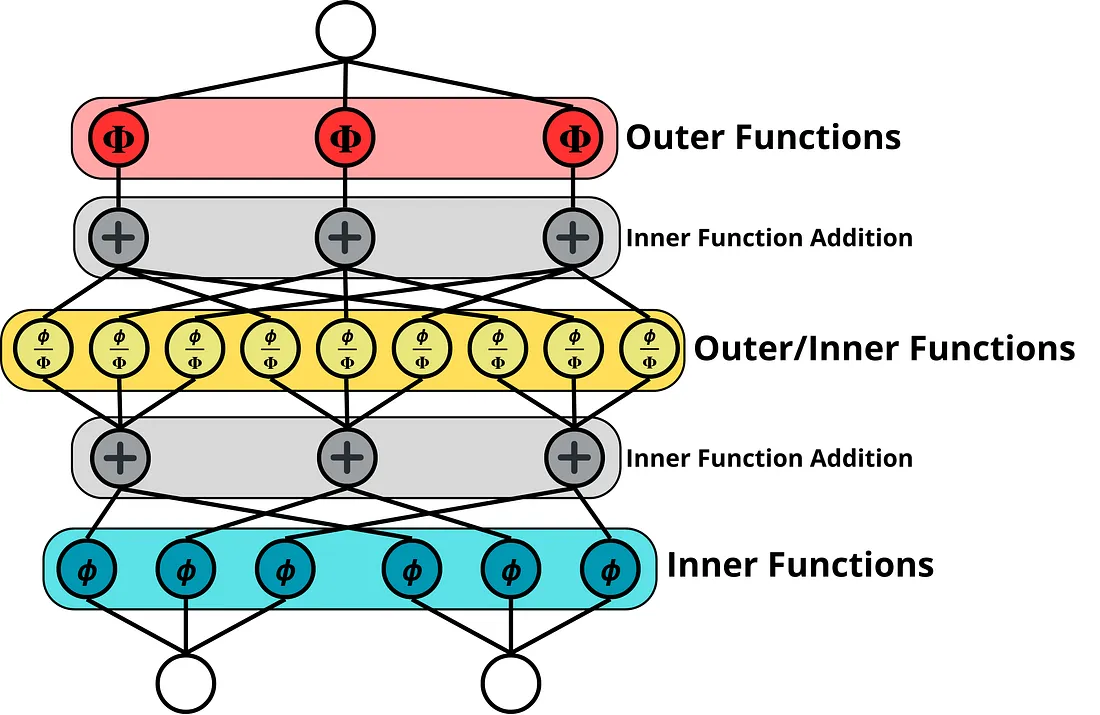 KAN 的表示具有三层,输入维度为 2,输出维度为 1。中间层充当第一层的外部函数,也充当第三层的内部函数。
KAN 的表示具有三层,输入维度为 2,输出维度为 1。中间层充当第一层的外部函数,也充当第三层的内部函数。
考虑上图,KAN 层的工作形状如下:
- 对于层中的每个输入元素,都会对输出层中的每个元素执行一次变换(𝟇 或𝚽 )。因此,如果我们有两个输入元素和三个输出元素,我们将并行执行六次变换。
- 加法运算将考虑输入维度。因此,如果输入是一个包含两个元素的向量,加法运算将根据它们在执行变换时的相应索引(图像的第一层)将元素两个两个地相加。如果有三个输入元素和三个输出元素,则将执行三种不同的加法运算,其中每次运算将添加三个元素(图像的第二层)。
一般来说,这意味着要设计一个 KAN 层,如果我们有一个输入大小d和一个输出大小m,那么我们总共有dxm个变换(线性或非线性),当它们在各自的维度上相加时,会在以下数学表达式中收敛:
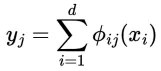
B 样条 KAN 与 MLP 的差异
柯尔莫哥洛夫-阿诺德表示定理本身并未确立内函数 (𝟇) 和外函数 ( 𝚽 ) 的具体使用方法,因此 KAN 的实现方式多种多样。本文将重点介绍最常用的 B 样条函数,因为它们在 KAN 实现中非常流行。然而,目前已有多种实现方式,它们各自侧重于 B 样条函数所具有的不同优势,同时也存在一些缺点。
每次变换的表现力
在 2024 年进行的原始实施中,单变量函数使用样条函数进行参数化,与 MLP 相比具有以下差异:
- KAN 将不同 B 样条的权重作为网络中的可学习参数。每条样条代表一个单变量函数(内函数或外函数),并在层末尾表示来自同一变量的不同样条函数的和。学习到的参数使用 B 样条函数基进行更新,需要初始化初始网格和控制点,并进一步更新以优化样条函数。然后,输入张量用于根据给定的控制点计算样条函数,并影响网格的动态调整。
- 另一方面,MLP 为每个神经元分配一个权重,以及一个可选的偏置参数,然后是预先设定的激活函数。在这种情况下,先使用线性变换,然后再使用非线性变换。这些变换的通用性要有限得多,至少在单个感知器的情况下是如此。
下图展示了单个感知器的行为。对于多层感知器 (MLP),具体来说,在隐藏层中,感知器的输入是前一层所有感知器输出的加权和。然而,为了简单起见,我们只表示一个具有输入的孤立神经元,而不是一个属于隐藏层的神经元。
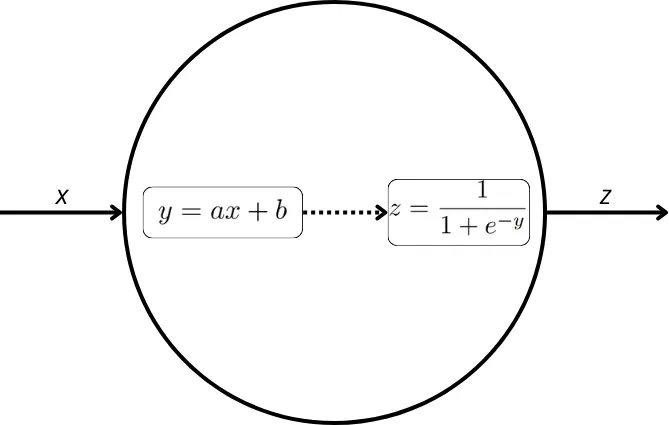
假设所选的激活函数是 Sigmoid,则接收输入“x”的单个感知器将执行这些转换。
从图形上看,我们可以看到感知器执行的线性和非线性变换;下图中,两种变换以及它们的组合都有表示:
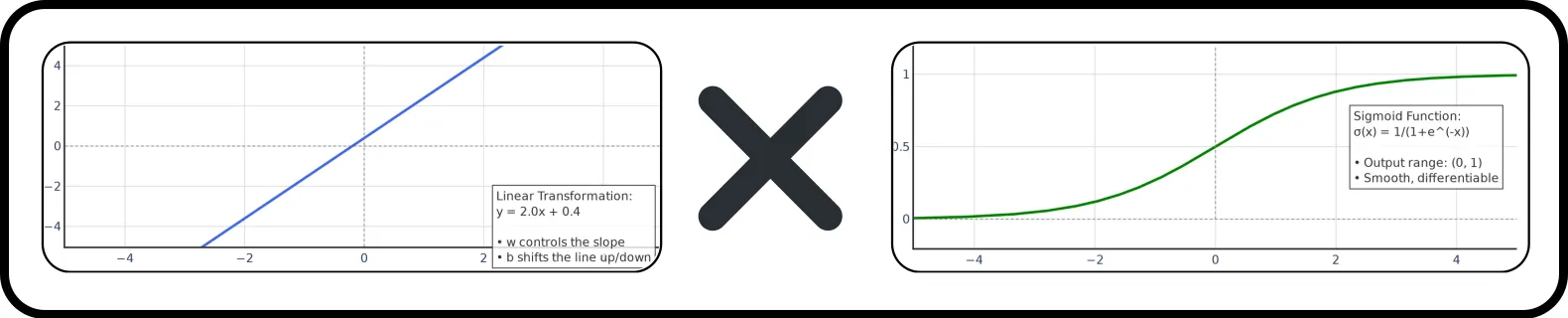
从图形上讲,我们可以用这些图来表示感知器执行的每一个转换。
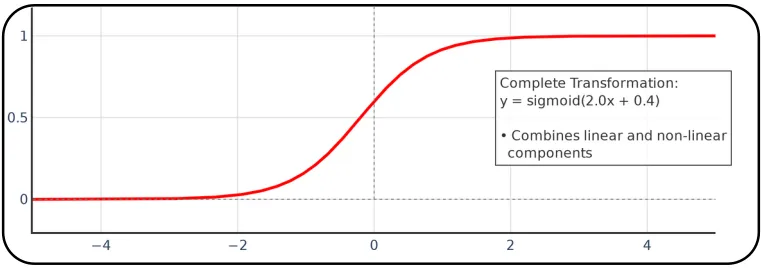 前两次转变可以概括为这次转变。
前两次转变可以概括为这次转变。
这样,对于多层感知器 (MLP) 来说,固定的激活函数极大地限制了不同神经元可能的输出值。在前面的图像中,我们可以看到,对于 S 型函数,神经元执行的总变换(同时考虑线性和非线性变换)与 S 型函数的原始形状非常相似,只是略微升高(由于线性变换的偏差)并且斜率更陡(由于线性变换的原始斜率)。如我们所见,这对变换为每个感知器增加了有限的表达能力。
虽然柯尔莫哥洛夫-阿诺德网络 (KAN) 通过其基于样条函数的架构增强了对复杂模式建模的表达能力,但多层感知器 (MLP) 却因通用近似定理 (UAT) 而成为深度学习的基础。该定理保证,即使是单隐藏层的 MLP,只要具有足够的宽度,也能以任意精度近似任何连续函数。因此,理论上,MLP 可以表示与 KAN 复杂度相当的函数,尽管这会以增加参数和计算资源为代价。
UAT 并非天生就偏向 MLP 而非 KAN;相反,它强调了这两种架构在理论上都是通用的近似器。正如以下章节所讨论的,KAN 相对于 MLP 和 KAN 都具有一些重要的优势。
可追溯性
对于KAN,初始变换应用于网络边缘的单个变量。节点中这些变换的求和确保了后续层能够捕获多变量相互作用,如图X所示。即使KAN堆叠了多层,这种方法也能确保可追溯性。通过追溯第一层的路径,我们可以清晰地观察到每个变量是如何单独变换的。后续层执行的变换可以在数学上分解为基于前几层的操作以及这些变换的求和。最终,这将导致只涉及单个变量的变换。
相比之下,对于多层感知器 (MLP),待学习的权重分布在许多连接上,这些连接在进入每个感知器之前都会被加权。这种分布使得确定单个输入变量的影响变得非常困难。
可解释性
从可解释性的角度看,由于KAN可以通过非线性变换(具有很强的通用性)以及随后的加法运算来表示,因此复杂的函数可以分解为人类可解释的简单函数。
对于多层感知器 (MLP) 而言,分配给每个感知器的加权权重会对网络的可解释性产生非常负面的影响,而固定的激活函数则几乎没有可解释性的空间。每当堆叠多层时,可解释性就会丧失或难以获得。
Kan 是 MLP 的泛化
我们可以将 KAN 视为 MLP 中执行的转换的概括,因为在最简单的情况下可以获得类似的结果:
- 如果我们使用只有两个控制点的样条曲线,那么在样条曲线生成的变换中我们将只有一个参数需要学习,这相当于表示来自神经元的线性变换的权重,而不考虑偏差,如下面解释所示。
- 样条函数可以收敛到类似于常用固定函数的函数。这不太可能自然发生,但样条函数能够适应更复杂的函数。然而,由于样条函数的平滑特性,KAN 在尝试收敛到像 ReLU 这样的突变激活函数时会遇到困难。
在最简单的情况下,KAN 如何收敛到感知器
计算 B 样条的公式取决于控制点和基函数:
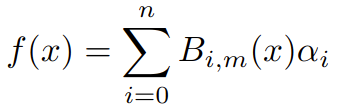
B样条函数的一般方程,B表示基函数,P表示控制点。该公式适用于n个不同的控制点和m阶基函数。
B ᵢ 表示基函数i,𝛂ᵢ 表示控制点i 。要生成i次函数,我们总共需要i+1 个基函数和控制点。
因此,对于线性 B 样条(1 次)而言,我们需要两个控制点(P₁,P₂)和两个基函数(B₁,B₂)。在这种情况下,我们可以将上述公式解释为:
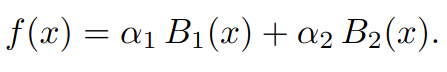
线性 B 样条的具体情况。
对于线性样条函数,我们有以下基函数:
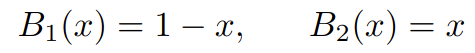
线性 B 样条中使用的基函数
如果我们代入上述公式,我们可以区分与线性变换相关的组件的偏差,正如我们所见,它表达了与 MLP 执行的线性变换相同的概念。
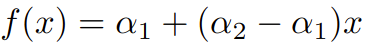
具有线性基函数的 B 样条方程。
KAN 优势
内部函数和外部函数的使用比 MLP 带来了一些关键优势:
- KAN 可解释性:尽管通过样条函数进行的变换更为复杂,但这些变换保留了单个变量的信息,与多层感知器相比,保持了可解释性。多层感知器的每个节点都连接到所有后续节点,因此追踪每个输入变量的影响极其困难。此外,单变量变换在边缘处理,这为给定网络带来了可追溯性。在任何 KAN 层中,每个变量的影响都可以被追踪和可视化,这在某些方面具有诸多优势,如下所述。
- KAN 在符号学习方面优于 MLP:KAN 中执行的运算可以表示为节点中的线性运算(如加法/减法)和边中的非线性运算(如乘法/除法、对数、平方根……)后续样条曲线将添加涉及多个变量的更复杂的非线性运算。
- 激活函数可以动态调整,使 KAN 更加通用:在 KAN 的情况下,激活函数具有在训练期间学习的参数,而在 MLP 中,始终选择预定的激活函数,与 KAN 执行的变换相比,这大大限制了感知器的表达能力。
- KAN 更具表现力:正如我们之前提到的,一条样条函数可以执行各种非线性运算,其中一些最简单的运算是乘法或除法,但由于它是一个非线性函数,它最终可以在单层中表示指数或对数函数,而对于 MLP 来说,这需要多层结构。一些实验表明,KAN 能够以比 MLP 少得多的参数来调整组合函数和平滑函数。
- 加速收敛:在分层分解与目标函数一致的情况下优化训练,例如符号回归或 PDE 求解的情况。
KAN 的缺点
然而,与 MLP 相比,KAN 也存在一些缺点:
- 训练不稳定性:在 KAN 中使用可学习的非线性变换会导致更大的训练不稳定性。这使得这些网络与更简单、更易于优化的 MLP 相比,收敛更具挑战性。基于样条函数的变换增加了复杂性,需要仔细初始化(比普通 MLP 需要初始化更多模块)并进行超参数调整(网格大小、样条函数阶数),以确保训练稳定。
- 架构调整:由于 KAN 执行的转换非常复杂,设计一个与 MLP 类似配置的网络(例如使用相同的层数和隐藏层大小)会导致计算成本显著增加。这是因为 KAN 中的每一层都涉及学习多个样条参数,而 MLP 依赖于更简单的线性转换,并遵循固定的激活函数。因此,用 KAN 替换 MLP 需要调整层数和隐藏层大小等参数,以平衡性能和效率。
- 可扩展性差:使用 Cox-De Boor 等递归方法计算样条曲线涉及许多操作,与 MLP 相比,KAN 的计算成本更高。网格的调整也会增加计算开销。单层中使用的系数数量众多,这些系数可能属于模型参数、样条曲线使用的基础或网格点,这使得这些网络的内存成本大幅增加。此外,并行计算变得更加复杂,这意味着这种新架构不像针对 GPU 的 MLP 那样进行优化。所有这些问题都对自然语言处理和计算机视觉提出了一系列挑战。对于 Transformer,使用 KAN 意味着更改与模型每一层相关的 MLP,这会增加模型的延迟并减慢其训练速度,由于模型过度拟合而获得相似或更差的结果。
结论
总而言之,虽然 MLP 在 UAT 的广泛保障下仍然不可或缺,但 KAN 为专门的应用提供了一个补充框架,其结构优势与特定问题的要求相一致,主要是在符号学习领域。
然而,我们必须谨慎对待 KAN 的说法,因为在许多情况下,这些所谓的优势是由 KAN 的实施方式决定的,而不是由 Kolmogorov-Arnold 定理本身决定的,我们将在以后的文章中讨论。
