金融数据分析(Python)个人学习笔记(11):回归分析
三、回归分析
(一)普通线性回归
导入模块和数据
import pandas as pd
import numpy as npdata = pd.read_csv('sh600000.csv') # 读取文件
print(data.corr())
'''
调用 DataFrame 对象的 corr 方法,计算 data 中各列之间的相关性,并返回一个相关性矩阵。
相关性矩阵展示了每两列之间的相关系数,相关系数的取值范围是 [-1, 1],
接近 1 表示正相关,接近 -1 表示负相关,接近 0 表示相关性较弱。
'''
结果:
open high low close preclose volume amount turn pctChg peTTM psTTM pcfNcfTTM pbMRQ logret2
open 1.000000 0.997689 0.996849 0.994293 0.998860 0.358026 0.534556 0.357970 -0.055159 0.861367 0.993735 0.104028 0.988012 -0.092460
high 0.997689 1.000000 0.996767 0.997247 0.996750 0.380920 0.555916 0.380859 -0.011431 0.863237 0.996631 0.103424 0.991196 -0.100280
low 0.996849 0.996767 1.000000 0.997702 0.995915 0.330306 0.510320 0.330247 -0.000485 0.872148 0.996820 0.108283 0.990846 -0.094570
close 0.994293 0.997247 0.997702 1.000000 0.993353 0.353046 0.530696 0.352983 0.042021 0.875099 0.999196 0.105381 0.992839 -0.105589
preclose 0.998860 0.996750 0.995915 0.993353 1.000000 0.359950 0.536150 0.359895 -0.072933 0.862545 0.992716 0.107547 0.987344 -0.099961
volume 0.358026 0.380920 0.330306 0.353046 0.359950 1.000000 0.978140 1.000000 -0.061049 0.282862 0.349292 0.104829 0.358645 -0.072425
amount 0.534556 0.555916 0.510320 0.530696 0.536150 0.978140 1.000000 0.978128 -0.051605 0.447040 0.527419 0.102406 0.532431 -0.083300
turn 0.357970 0.380859 0.330247 0.352983 0.359895 1.000000 0.978128 1.000000 -0.061107 0.282796 0.349228 0.104807 0.358582 -0.072467
pctChg -0.055159 -0.011431 -0.000485 0.042021 -0.072933 -0.061049 -0.051605 -0.061107 1.000000 0.096129 0.040657 -0.024130 0.031685 -0.054719
peTTM 0.861367 0.863237 0.872148 0.875099 0.862545 0.282862 0.447040 0.282796 0.096129 1.000000 0.882366 0.134941 0.846042 -0.117185
psTTM 0.993735 0.996631 0.996820 0.999196 0.992716 0.349292 0.527419 0.349228 0.040657 0.882366 1.000000 0.096442 0.990563 -0.106102
pcfNcfTTM 0.104028 0.103424 0.108283 0.105381 0.107547 0.104829 0.102406 0.104807 -0.024130 0.134941 0.096442 1.000000 0.203128 -0.019001
pbMRQ 0.988012 0.991196 0.990846 0.992839 0.987344 0.358645 0.532431 0.358582 0.031685 0.846042 0.990563 0.203128 1.000000 -0.100457
logret2 -0.092460 -0.100280 -0.094570 -0.105589 -0.099961 -0.072425 -0.083300 -0.072467 -0.054719 -0.117185 -0.106102 -0.019001 -0.100457 1.000000
1. 创建特征矩阵
X = data.iloc[:,:-1].copy()
y = data.iloc[:,-1].copy()
'''
iloc:索引
[:,:-1]:除最后一列外的所有数据
x和y是特征矩阵
copy():创建独立副本,防止原始数据被修改
'''
2. 拆分训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20,random_state=1000)
'''
sklearn:机器学习库
model_selection模块提供用于数据划分、模型选择和评估的工具
train_test_split:用于数据集划分的函数
test_size=0.20:测试集在整个数据集中占0.2
random_state=1000:设置随机种子,用于保证每次划分的结果一致
'''
3. 数据标准化
数据标准化是一种常见的预处理步骤。不同特征的取值范围可能差异很大,这可能会影响某些机器学习算法的性能,比如距离度量相关的算法(如K近邻算法)。标准化可以将不同特征的数据缩放到相同的尺度,通常是将数据转换为均值为0,标准差为1的标准正态分布,从而提高模型的稳定性和性能。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
'''
sklearn.preprocessing模块提供数据预处理工具
StandardScaler类用于实现数据的标准化
fit:获取X特征,使用训练集的特征矩阵X_train来计算标准化所需的均值和标准差只使用训练集来计算均值和标准差,目的是为了避免测试集信息泄露到训练过程中,保证模型评估的公平性
transform:使用之前fit方法计算得到的均值和标准差,将X_train中的每个特征转换为均值为0,标准差为1的标准正态分布。最后将标准化后的结果重新赋值给X_train
'''
4. 普通线性回归
线性回归是一种基本的机器学习算法,用于建立自变量(特征)和因变量(目标)之间的线性关系。这段代码的主要功能是创建一个线性回归模型,使用训练数据对其进行训练,然后输出模型的截距项和各个特征对应的系数。
from sklearn.linear_model import LinearRegression
LR = LinearRegression()
LR.fit(X_train,y_train)
print('截距项:',LR.intercept_)
pd.DataFrame(LR.coef_.T, index = X.columns, columns = ['coef_val'])
'''
机器学习更关注预测能力好坏,不在乎参数的显著性,对于回归结果不包括显著性分析
sklearn.linear_model模块提供了多种线性模型
LinearRegression类用于实现普通最小二乘法的线性回归
fit:训练回归模型,将训练集的特征矩阵X_train和目标向量y_train作为参数传入。作用是使用最小二乘法来估计线性回归模型的参数(即系数和截距),使得模型预测值与真实值之间的误差平方和最小。
LR.intercept_:模型的截距项
pd.DataFrame:将线性回归模型的系数转换为pandas的DataFrame对象
LR.coef_.T:系数的转置
index = X.columns:使用特征矩阵 X 的列名作为索引
columns = ['coef_val']:将系数列命名为 coef_val。
'''
结果:
coef_val
open 3.787160
high 1.659964
low 1.984311
close -5.023428
preclose -3.770039
volume 145.107178
amount 0.255046
turn -145.367121
pctChg 0.065354
peTTM 0.321539
psTTM -1.227559
pcfNcfTTM -0.226256
pbMRQ 2.172706
登录网站可查询各模块使用细节。
系数不稳定,线性回归中,系数绝对值大小代表属性重要性
5. 绘制系数柱状图
from matplotlib import pyplot
pyplot.bar([x for x in range(len(LR.coef_))], LR.coef_)
pyplot.xticks(range(13), X.columns,rotation=60)
pyplot.show()
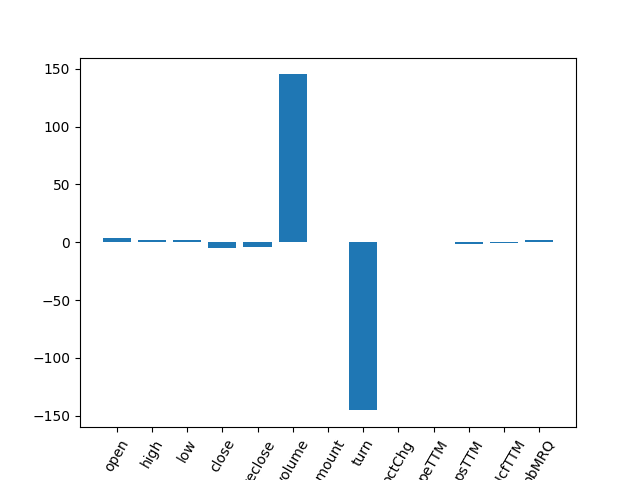
6. 预测与评价
y_pred = LR.predict(X_test)
LR.score(X_train,y_train),LR.score(X_test,y_test)
from sklearn.metrics import r2_score
LR_train_score = r2_score(y_train, LR.predict(X_train))
LR_test_score = r2_score(y_test,y_pred)
LR_train_score,LR_test_score
'''
predict:使用训练好的模型对新数据进行预测
score:计算模型在给定数据集上的决定系数R^2R^2越接近1,表示模型对数据的拟合效果越好;越接近0,表示模型的拟合效果越差;若为负数,则说明模型的表现比简单的均值预测还要差。
sklearn.metrics模块提供了多种用于评估模型性能的指标函数。
r2_score:计算决定系数R^2,第一个参数是真实的目标值,第二个参数是模型的预测值
'''
(二)岭回归ridge regression
岭回归分析是一种改良的最小二乘法,其通过放弃最小二乘法的无偏性,以损失部分信息为代价来寻找效果稍差但回归系数更符合实际情况的模型方程。主要用于解决多重共线性问题。
在存在多重共线性的情况下,岭回归能够通过收缩参数来稳定估计值。因为正则化项使得参数估计不再仅仅取决于最小化误差平方和,还受到参数大小的限制,所以可以减少由于多重共线性导致的参数估计的方差增大问题,使估计的参数更具有稳定性和可靠性。岭回归通过引入正则项,有效缓解了多重共线性问题,提高了模型的稳定性和泛化能力
1. 模型的设置与训练
from sklearn.linear_model import Ridge
ridge = Ridge(alpha=1.5)
ridge.fit(X_train, y_train)
print('截距项:',ridge.intercept_)
pd.DataFrame(ridge.coef_.T, index = X.columns, columns = ['coef_val'])
'''
Ridge类用于实现岭回归
alpha=1.5:设置正则化参数alpha是岭回归中的正则化系数,它控制了正则化项的强度。alpha 值越大,正则化作用越强,模型系数会被压缩得更小;alpha值越小,正则化作用越弱;当alpha 趋近于0时,岭回归就退化为普通线性回归。
'''
结果:
截距项: -0.09298468345821594coef_val
open 0.5702584526513296
high 0.33248832902141384
low 0.25383168437975745
close -0.3867401304117483
preclose -0.4143548152261121
volume -0.10316827824811864
amount 0.18695212994803445
turn -0.11206704409506837
pctChg 0.018191201219843075
peTTM -0.06902168835396578
psTTM -0.3193444941154428
pcfNcfTTM 0.023594665845129877
pbMRQ -0.1187925233940659
2. 最优alpha值的选择
y_pred = ridge.predict(X_test)
ridge.score(X_train,y_train),ridge.score(X_test,y_test)
结果:
(0.03590191238355622, 0.0027335294770192142)
R^2显示预测能力很差
调整正则化参数,观察不同alpha值下模型的偏回归系数变化情况,以此来寻找更合适的alpha值
首先,构造一系列不同的 alpha 值。
然后,针对每个 alpha 值训练一个岭回归模型,记录模型的偏回归系数、训练集得分和测试集得分。
最后,绘制 alpha 值与偏回归系数的关系图。
import matplotlib.pyplot as plt
# 构造不同的Alpha值
Alphas = np.logspace(-2, 2, 200)
# np.logspace(-2, 2, 200):生成一个对数等间距的数组,范围从10^-2到10^2,共 200 个值。
# alpha的取值范围可能非常大,使用对数尺度可以更均匀地覆盖不同的取值范围# 构造空列表,用于存储模型的偏回归系数、训练得分、测试得分
ridge_cofficients = []
train_scores = []
test_scores = []
# 循环迭代不同的Alpha值
for Alpha in Alphas:ridge = Ridge(alpha = Alpha)ridge.fit(X_train, y_train)ridge_cofficients.append(ridge.coef_)train_scores.append(ridge.score(X_train,y_train))test_scores.append(ridge.score(X_test,y_test))
绘制Alphas与回归系数的关系(岭迹图Ridge trace)
plt.rcParams['axes.unicode_minus'] = False
'''
plt.rcParams:全局设置图形参数的字典。
'axes.unicode_minus':坐标轴负号的显示方式设置为 False 是为了确保负号能正常显示
'''
# 设置绘图风格
plt.style.use('ggplot')# 绘制折线图
plt.plot(Alphas, ridge_cofficients)# 对x轴作对数变换
plt.xscale('log')
# plt.xscale:设置x轴的刻度类型# 设置折线图x轴和y轴标签
plt.xlabel('Alpha')
plt.ylabel('Cofficients')
plt.title('Ridge trace')
# 图形显示
plt.show()
结果:
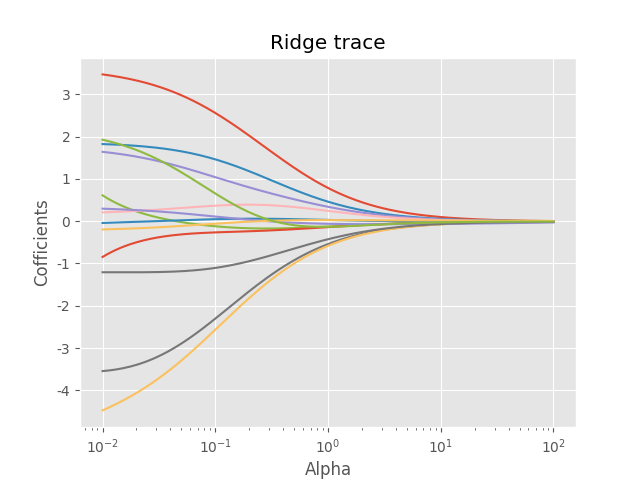
每条曲线代表每个系数的变化,变化较大的曲线表示该变量存在多重共线性
alpha逼近0时,相当于普通线性回归,随着alpha增大,系数趋近于0
可以看出,alpha在 1 附近时,各参数趋于稳定
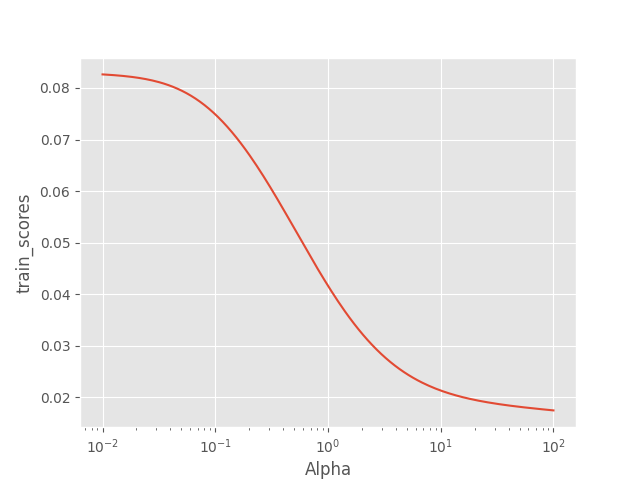
绘制alpha和训练得分曲线
plt.plot(Alphas, train_scores)
# 对x轴作对数变换
plt.xscale('log')
# 设置折线图x轴和y轴标签
plt.xlabel('Alpha')
plt.ylabel('train_scores')
plt.show()
结果:
绘制alpha和测试得分曲线
plt.plot(Alphas, test_scores)
# 对x轴作对数变换
plt.xscale('log')
# 设置折线图x轴和y轴标签
plt.xlabel('Alpha')
plt.ylabel('test_scores')
plt.show()
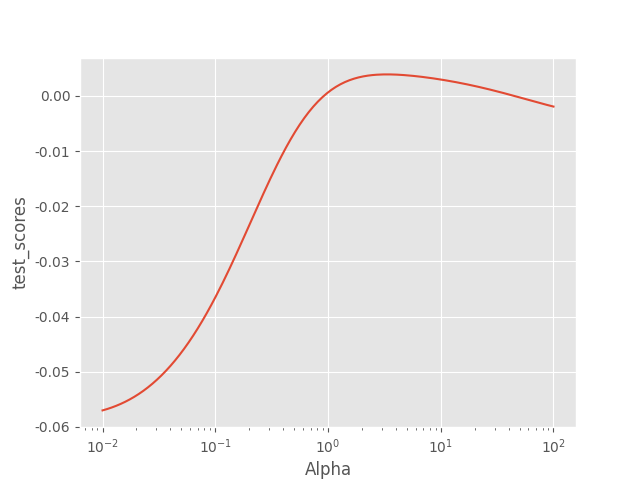
从训练集来看,alpha越大,拟合训练集拟合越差,因为较大的alpha使参数缩减为0
从测试得分情况来看,增大alpha的引入可以提高测试集预测能力,即泛化能力,但过大则会降低预测能力
alpha 在 1附近时,得分最高
正则项的引入降低了训练性能,提高了泛化性能
if test_scores:max_index = [i for i, score in enumerate(test_scores) if score == max(test_scores)]if max_index:best_alpha = Alphas[max_index[0]]print(best_alpha)else:print("没有找到合适的最大值")
else:print("test_scores 列表为空")
'''
enumerate:将一个可迭代对象组合为一个索引序列,同时列出数据和数据的索引。enumerate(test_scores):将test_scores列表中的每个元素与其对应的索引组成一个元组,返回一个迭代器。
从Alphas数组中筛选出对应最高测试集得分的alpha值
由于可能存在多个 alpha 对应相同的最高得分,这里假设取第一个,即 [0]
还可以把alpha的取值范围扩大,可能会稍微增加预测得分
但过大的alpha导致参数系数缩减至接近0,意义不大
'''
结果:
3.409285069746811
ridge = Ridge(alpha = 3.41) # 设置正则项系数
ridge.fit(X_train, y_train)
print('截距项:',ridge.intercept_)
pd.DataFrame(ridge.coef_.T, index = X.columns, columns = ['coef_val'])
结果:
截距项: -0.0929846834582158coef_val
open 0.2777057036252364
high 0.15994842411720023
low 0.12798324633064911
close -0.18746705997181487
preclose -0.19915677651101046
volume -0.06284150050714805
amount 0.09343847173496571
turn -0.06668238709432904
pctChg 0.001529848206729679
peTTM -0.07263530618660588
psTTM -0.1658438207790917
pcfNcfTTM 0.01791879189261865
pbMRQ -0.07121975938610597
训练和测试得分
ridge_train_score = ridge.score(X_train,y_train)
ridge_test_score = ridge.score(X_test,y_test)
ridge_train_score,ridge_test_score
结果:
(0.02724113523403071, 0.003901664250077874)
线性回归中,系数绝对值大小代表属性重要性
from matplotlib import pyplot
pyplot.bar([x for x in range(len(ridge.coef_))], ridge.coef_)
pyplot.xticks(range(13), X.columns,rotation=60)
pyplot.show()
结果:
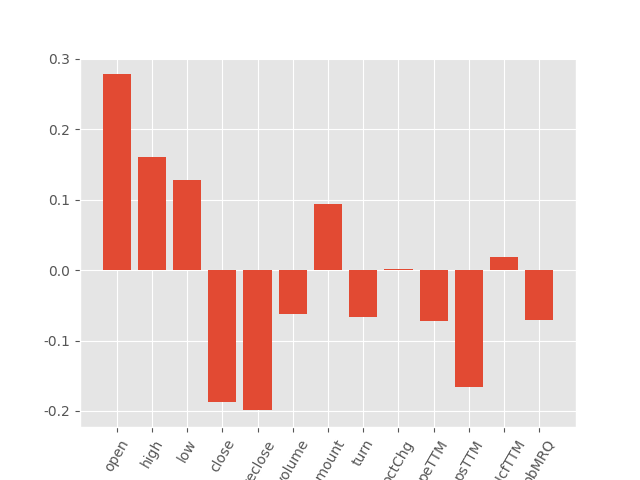
(三)LASSO回归 LASSO regression
Lasso回归在普通线性回归基础上,引入正则项,从而起到筛选对因变量有重要影响特征的功能,并且缓解了过拟合和多重共线性问题。
使用sklearn库中的Lasso回归模型,通过改变正则化参数alpha的值,观察模型的系数变化以及在训练集和测试集上的得分情况,最后绘制出alpha与回归系数的关系图。
1. 模型的设置与训练
from sklearn.linear_model import Lasso # 载入LASSO回归函数
# 针对Alpha的不同取值,观察得分情况# 对特征进行标准化处理
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)# 构造空列表,用于存储模型的偏回归系数
lasso_cofficients = []
train_scores = []
test_scores = []
Alphas = np.logspace(-4, 2, 200) # 10^-4 - 10^2
for Alpha in Alphas:lasso = Lasso(alpha = Alpha, normalize=False, max_iter=100000)# max_iter=100000:最大迭代次数为100000,以确保模型能够收敛。lasso.fit(X_train, y_train)lasso_cofficients.append(lasso.coef_)train_scores.append(lasso.score(X_train,y_train))test_scores.append(lasso.score(X_test,y_test))
绘制正则化参数Lambda与回归系数的关系
plt.plot(Alphas, lasso_cofficients)
# 对x轴作对数变换
plt.xscale('log')
# 设置折线图x轴和y轴标签
plt.xlabel('Alpha')
plt.ylabel('Cofficients')
# 显示图形
plt.show()
结果:
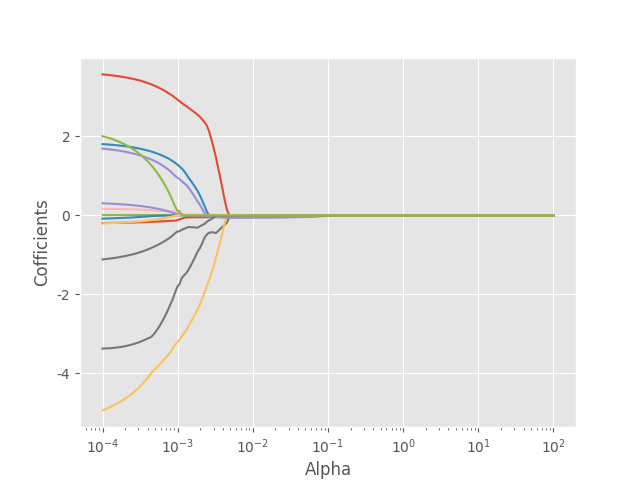
可以看出,随着正则系数alpha的增大,参数衰减的非常快,有些参数缩减至0
2. 最优alpha值的选择
绘制alpha和训练得分曲线
plt.plot(Alphas, train_scores)
# 对x轴作对数变换
plt.xscale('log')
# 设置折线图x轴和y轴标签
plt.xlabel('Alpha')
plt.ylabel('train_scores')
plt.show()
结果:
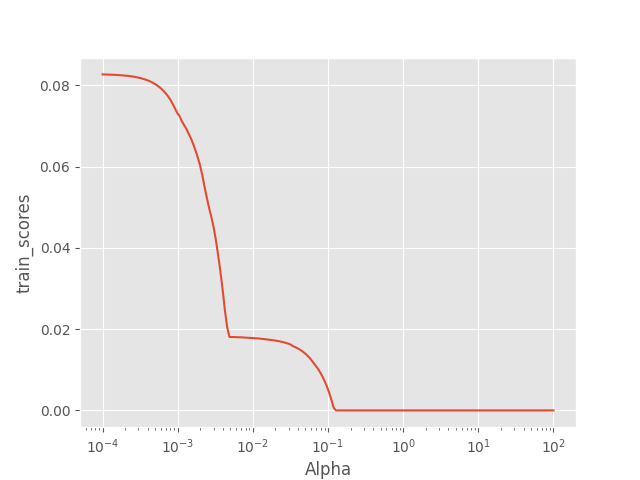
绘制alpha和测试得分曲线
plt.plot(Alphas, test_scores)
# 对x轴作对数变换
plt.xscale('log')
# 设置折线图x轴和y轴标签
plt.xlabel('Alpha')
plt.ylabel('test_scores')
plt.show()
结果:
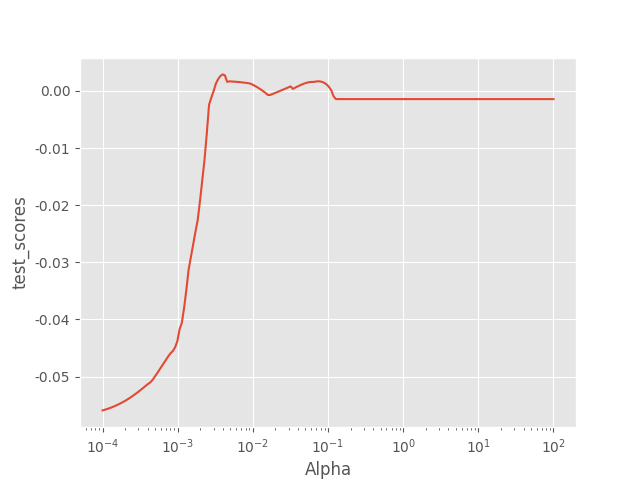
找出最优Alpha
if test_scores:max_index = [i for i, score in enumerate(test_scores) if score == max(test_scores)]if max_index:best_alpha = Alphas[max_index[0]]print(best_alpha)else:print("没有找到合适的最大值")
else:print("test_scores 列表为空")
结果:
0.003962688638701479
# 令 alpha = 0.004
lasso = Lasso(alpha=0.004, max_iter = 10000) # 设置正则项系数
lasso.fit(X_train, y_train)
print('截距项:',lasso.intercept_)
pd.DataFrame(lasso.coef_.T, index = X.columns, columns = ['coef_val'])
结果:
截距项: -0.09298468345821563coef_val
open 0.6149381560459118
high 0.0
low 0.0
close -0.2831269736338545
preclose -0.38378688882842266
volume -0.0
amount -0.0
turn -0.041202233514632355
pctChg -0.0
peTTM -0.05553595338739603
psTTM -0.0
pcfNcfTTM 0.0067293375771284815
pbMRQ -0.0
训练和测试得分
lasso_train_score = lasso.score(X_train,y_train)
lasso_test_score = lasso.score(X_test,y_test)
lasso_train_score,lasso_test_score
结果:
(0.029061156032246127, 0.0028906089799513035)
from matplotlib import pyplot
pyplot.bar([x for x in range(len(lasso.coef_))], lasso.coef_)
pyplot.xticks(range(13), X.columns,rotation=60)
pyplot.show()
结果:
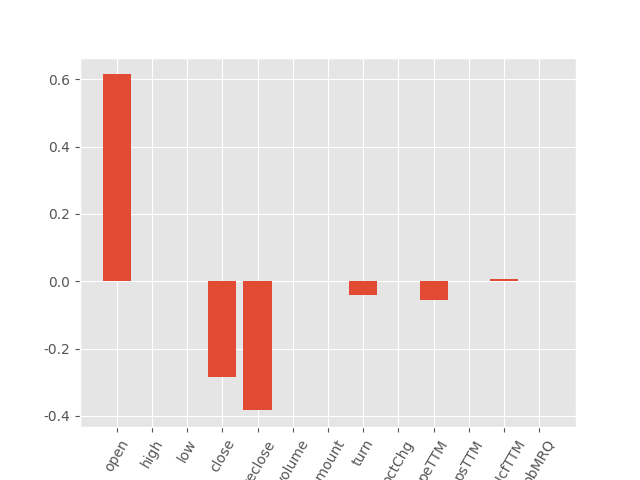
测试集上 R2 为 0 说明,拟合的回归模型相当于常数模型,各参数均为0。
lasso回归的特点:通过增大alpha提高泛化能力,会剔除一些变量。
(四)弹性网络回归 Elastic Net regression
结合了岭回归和 Lasso 回归的优点。在处理线性回归问题时,弹性网络回归在目标函数中同时引入了 两种回归的正则化项,在解决多重共线性、进行特征选择、处理高维数据等方面对普通线性回归进行了有效改良。
from sklearn.linear_model import ElasticNet # 载入弹性网络回归函数# 针对Alpha的不同取值,观察得分情况# 对特征进行标准化处理
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)# 构造空列表,用于存储模型的偏回归系数
EN_cofficients = []
train_scores = []
test_scores = []
Alphas = np.logspace(-4, 2, 200) # 10^-4 - 10^2
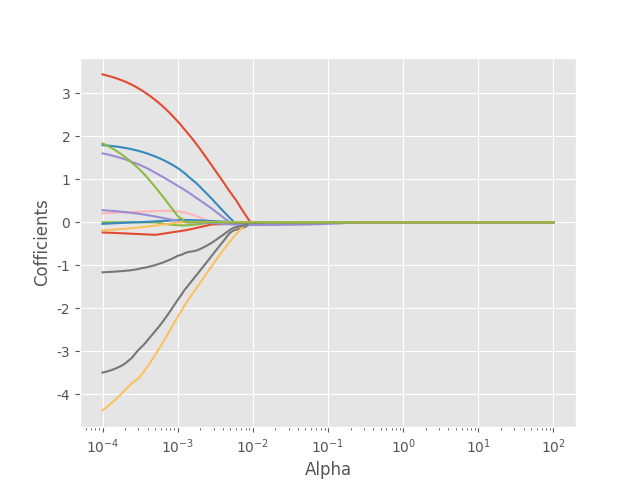
for Alpha in Alphas:EN =ElasticNet(alpha=Alpha, l1_ratio=0.5, max_iter=100000)# 弹性网络有两个参数,此处只改变了一个EN.fit(X_train, y_train)EN_cofficients.append(EN.coef_)train_scores.append(EN.score(X_train,y_train))test_scores.append(EN.score(X_test,y_test))# 绘制Lambda与回归系数的关系
plt.plot(Alphas, EN_cofficients)
# 对x轴作对数变换
plt.xscale('log')
# 设置折线图x轴和y轴标签
plt.xlabel('Alpha')
plt.ylabel('Cofficients')
# 显示图形
plt.show()
结果:
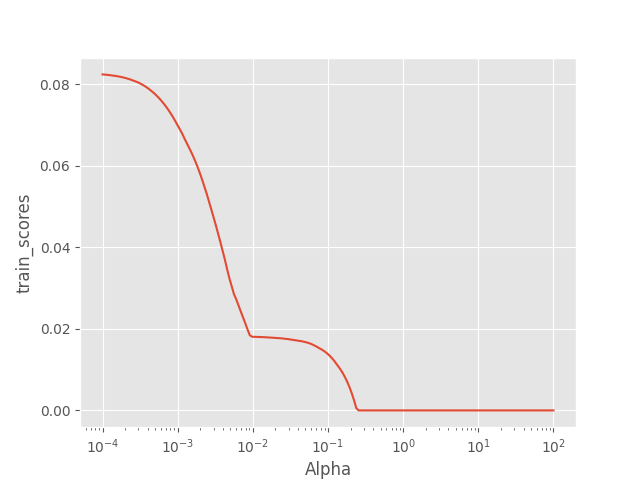
绘制alpha和训练得分曲线
plt.plot(Alphas, train_scores)
# 对x轴作对数变换
plt.xscale('log')
# 设置折线图x轴和y轴标签
plt.xlabel('Alpha')
plt.ylabel('train_scores')
plt.show()
结果:
绘制alpha和测试得分曲线
plt.plot(Alphas, test_scores)
# 对x轴作对数变换
plt.xscale('log')
# 设置折线图x轴和y轴标签
plt.xlabel('Alpha')
plt.ylabel('test_scores')plt.savefig("./Alpha_scoresTE2.png")
plt.show()
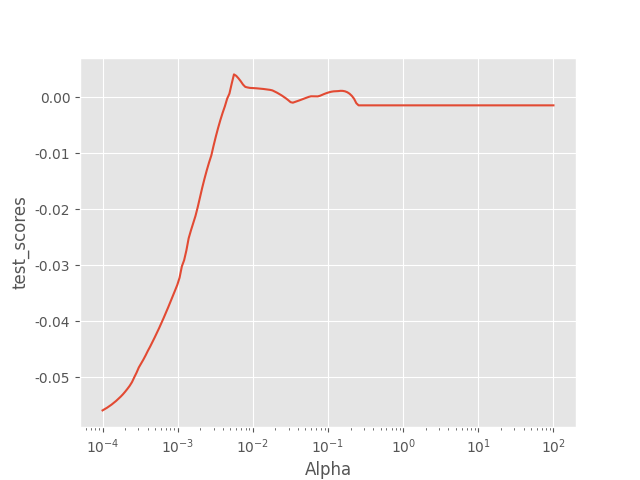
if test_scores:max_index = [i for i, score in enumerate(test_scores) if score == max(test_scores)]if max_index:best_alpha = Alphas[max_index[0]]print(best_alpha)else:print("没有找到合适的最大值")
else:print("test_scores 列表为空")
结果:
0.005607169938205458
# 令 alpha = 0.0056
EN = ElasticNet(alpha=0.0056,l1_ratio=0.5, normalize=False,max_iter=100000) # 设置正则项系数
EN.fit(X_train, y_train)
print('截距项:',EN.intercept_)
pd.DataFrame(EN.coef_.T, index = X.columns, columns = ['coef_val'])
结果:
截距项: -0.09298468345821569coef_val
open 0.5826190218113909
high 0.005159500794307866
low 0.0
close -0.18698213493219917
preclose -0.3286315136537636
volume -0.00924732095611357
amount 0.0
turn -0.03374430673119545
pctChg 0.0
peTTM -0.05346062990582323
psTTM -0.12579105433396318
pcfNcfTTM 0.006717132348324692
pbMRQ -0.0
from matplotlib import pyplot
pyplot.bar([x for x in range(len(EN.coef_))], EN.coef_)
pyplot.xticks(range(13), X.columns,rotation=60)
pyplot.show()
结果:
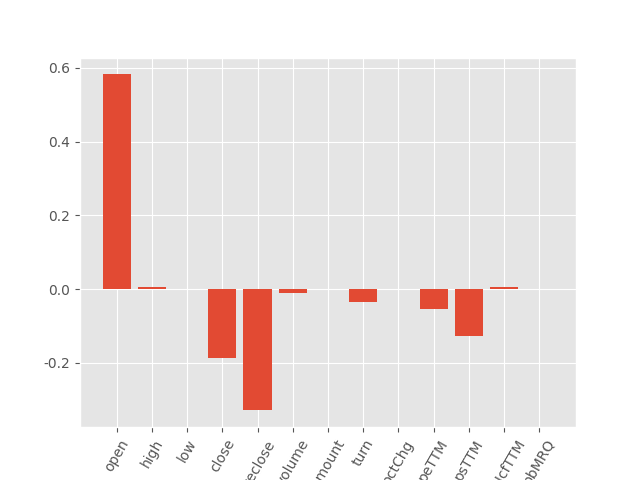
训练和测试得分
EN_train_score = EN.score(X_train,y_train)
EN_test_score = EN.score(X_test,y_test)
EN_train_score,EN_test_score
结果:
(0.02855025537702549, 0.0040615183023572365)
(五)比较 四种回归模型结果
score = np.array([[LR_train_score, LR_test_score],[ridge_train_score, ridge_test_score],[lasso_train_score, lasso_test_score],[EN_train_score, EN_test_score]])
pd.DataFrame(score, index=['普通回归','岭回归','LASSO','弹性网络'], columns = ['训练得分','测试得分'])
训练得分 测试得分
普通回归 0.09423672222206736 -0.09641097485641459
岭回归 0.02724113523403071 0.003901664250077874
LASSO 0.029061156032246127 0.0028906089799513035
弹性网络 0.02855025537702549 0.0040615183023572365
相对于普通回归,加入正则项后,对模型的泛化能力均有所提升,
岭回归、LASSO、弹性网络三种模型哪种好,看具体情况