前端路由 ( 1 ) | history 原理
当前主流前端路由的实现基于history库,今天就来简单说说其原理。
项目具体实现可以访问我的git仓库查看:my-sample-history![]() https://github.com/Gravity2333/my-sample-history
https://github.com/Gravity2333/my-sample-history
前端路由出现之前,多页面应用在切换页面时通常需要浏览器重新向服务器发送Get请求重新获取html文档。
单页面应用全局只有一个index.html 文档,我们需要在路由切换的时候,动态修改其内容,并且保证其不反复向服务器发送请求。
所以,前端路由需要解决以下两个问题:
1. 如何修改浏览器URL栏的内容并且不让浏览器重新请求页面
2. 如何监听到路径的变化以切换页面内容
首先我们先看第一个问题,通常修改URL栏的方法包含
(1) 用户自定义 用户自己输入修改url地址
(2)用户点击前进 后退 按钮
(3)调用 history.pushState方法
用户在地址栏修改url后回车,浏览器会发送请求重新获取页面html,即便当前url没有任何变化,这属于浏览器的默认行为,如果我们需要阻止浏览器默认发起请求,可以把真正的路径写在hash后面。
hash #
hash的原本作用,是用在页面中不同锚点之间的跳转,比如 /home#title 会跳转到页面id=title的位置, /home#footer 会跳转到 id = ‘footer'的位置。跳转的过程中,虽然地址栏改变,但是在点击回车之后,浏览器会默认当前跳转发生在页面内,不会重新发起请求!
利用这种方式,把我们的页面路径全部表示在 # 后面,就可以阻止浏览器默认发起请求的行为。
这也是Hash模式路由的实现原理!
那么当用户点击前进后退的时候,浏览器会不会重新请求呢? 这个需要了解一下浏览器原生的history对象,需要注意,这里的history和我们今天要说的前端路由底层的histroy库是两码事,history库是对浏览器原生history的更近一层封装。
浏览器原生histroy
history可以理解为一个历栈,这个栈会在页面创建时被创建,在页面关闭时被销毁。也就是说,history的生命周期是整个浏览器Tab页的生命周期,当在一个Tab页中切换不同的站点 页面的时候,histroy对象会一直存在!
history对象如下所示,其中包含了history栈的长度 length 以及当前历史所保存的State信息。

为了保证用户的隐私,history栈无法遍历,只能获取当前页面对应路径所对应的state状态!
用户点击浏览器前进后退时,其实本质上就是在history栈中移动,用户也可以通过 history.go()的方式切换页面。
切换页面时,如果新的页面和当前页面不同源的时候,浏览器会重新发送Get请求以请求新的html文档。 当同源的时候,浏览器会认为路径跳转时页面内部的,不会重新发送Get请求获取页面。
所以,当我们保证所跳转到的路径和当前路径同源,就可以保证浏览器不会重新发送请求。
比如,当我们从 http://127.0.0.1:8080/home 跳转到 http://127.0.0.1:8080/about时,浏览器会认为当前跳转为站内跳转,只会修改history对象但是不会发生跳转。
pushState & replaceState
有时候我们需要在代码中动态的跳转页面,比如点击了某个Menu后跳转路由,此时我们就需要浏览器提供一个可以修改history的接口, 这个接口就是 pushState 和 replaceState
pushState和replaceStated的函数定义为
pushState ( state , title , url)
其中,state也就对应history中保存的历史状态,如果有需求,可以在其中存储页面需要保存的上下文信息
title这个目前可以忽略,算是保留字段,所有的浏览器目前都忽略这个字段
url 也就是要跳转的目标 url ,在使用pushState / repalceState的时候,要求这个url必须和当前页面url 同源。

这个特性也就保证了,pushState / replaceState 跳转的目标,不会引起浏览器更新页面(因为同源的histroy切换不会导致浏览器重新请求文档)
利用这个特性,我们就能在不刷新页面的情况下,更新history对象!
history栈的逻辑
histroy栈和我们理解的栈不太一样,Stack本质上为FILO 先入后出,在没有弹出元素的情况下,我们是访问不到非栈顶元素的!但是histroy栈的区别就在于,其内部包含指针,可以在不弹出历史的情况下,访问任意历史。 如下:
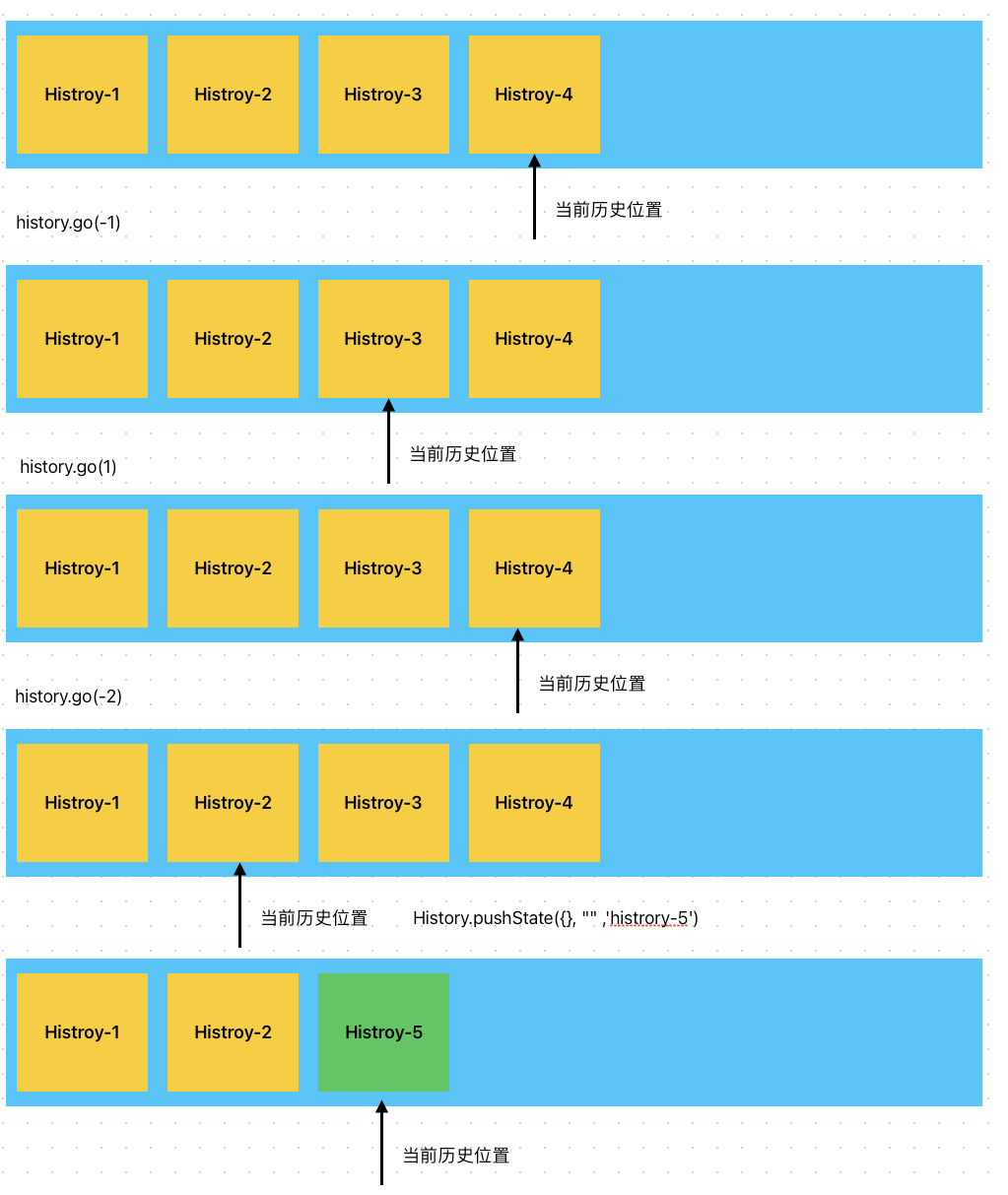
可以看到 指针可以前后移动,切换历史。
当我们使用pushState的时候,会把当前指针之后的历史都弹出,并且push新的历史入栈,并且修改指针的位置,如图
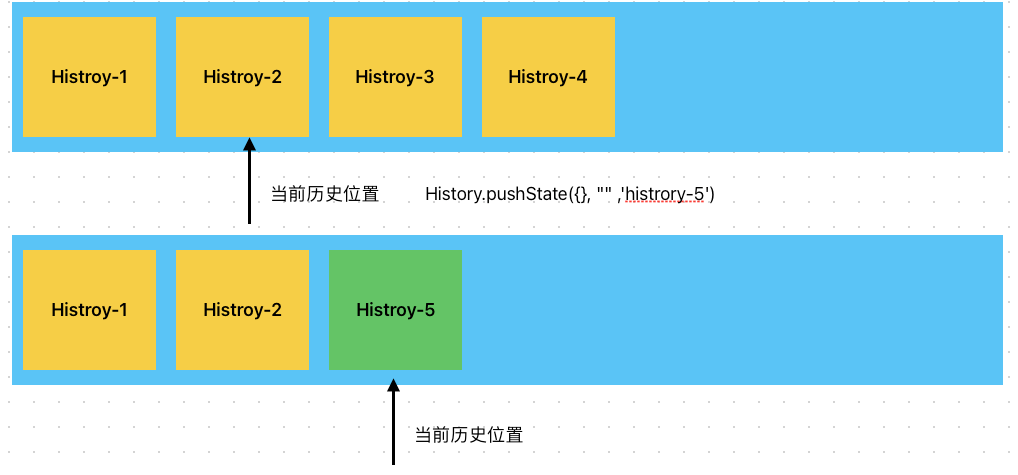
如果使用的是replaceState,则会替换掉当前指针指向的历史,不会影响前后的历史,如图:
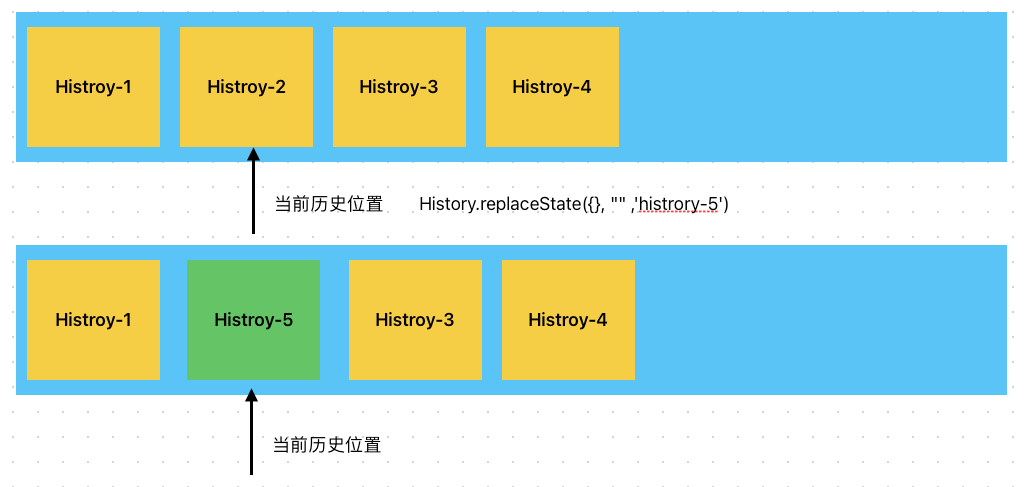
这点请注意区分!在我们自己实现memorizedHistory的时候,可能需要我们自己实现这个堆栈。
监听路径变化
说完了如何修改路径不引起浏览器刷新页面,我们再来看一下如何监听页面的变动。
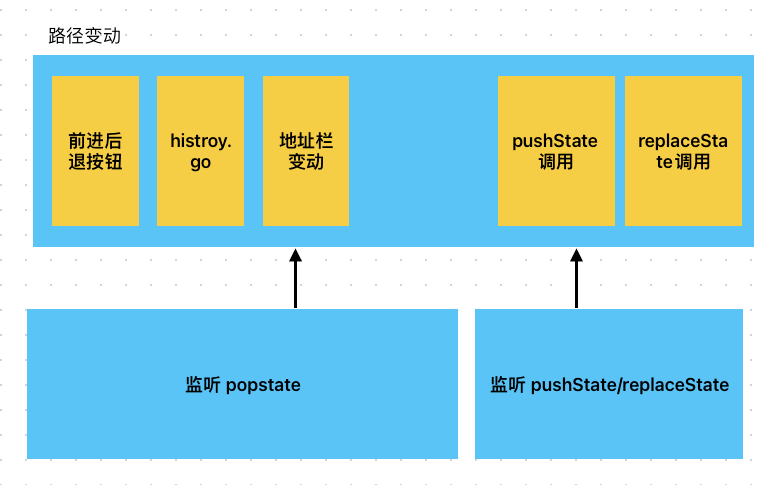
原生的history对象不提供可以直接注册监听回调的listen方法,我们通常是通过popstate事件实现的。
popstate事件会在history对象指针发生变动时触发,我们通常称history对象的指针变动为POP操作,也就是导航操作。
会触发的情况有
- 用户点击浏览器的前进,后退按钮
- 用户调用history.go history.back history.forward
- 用户修改页面hash时
需要注意,使用 pushState和replaceState函数修改history 不算是POP操作,不会触发popstate事件。
所以当我们监听路径时 需要从 popstate和pushState/replaceState两方面去监听!如图
history库的实现
history库做的事情,一个是封装了 push replace 函数,实现在不刷新页面的情况下,更新history,从而更新地址栏内容。 另外一个是实现了对popstate事件的触发以及push/replace函数调用的监听,从而通知外层系统 (如ReactRouter)修改展示内容。
Action类型
实现之前,我们先看Action类型,Action定义如下,包含 POP PUSH REPLACE 三种操作
enum Action {"POP" = "POP","PUSH" = "PUSH","REPLACE" = "REPLACE",
}其中,POP代表在history栈中导航(Navigate)当我们 history.go history.back history.forward或者点击前进后退时,此时对应的操作就是 POP
而PUSH REPLACE 对应的就是 pushState和replaceState操作。
Path对象
path对象包含了 pathname search hash 三个属性,如下:
type Pathname = string;
type Hash = string;
type Search = string;
type State = any;interface Path {pathname: Pathname;search: Search;hash: Hash;
}其中,pathname为路径名称,也就是url地址 origin之后,search之前的部分 如 https://www.baidu.com/page?search=params#title
其中 origin为源 也就是 协议 IP 端口的部分,在这里用DNS代替了 也就是 https://www.baidu.com
pathname为路径名称,为origin后,search问好之前的部分 也就是 /page
search为携带的搜索参数,为问号和问号后面的到#之前的部分 为 ?search=params
hash为锚点# 之后的部分
我们可以通过打印浏览器原生提供的location对象,来查看器内容:
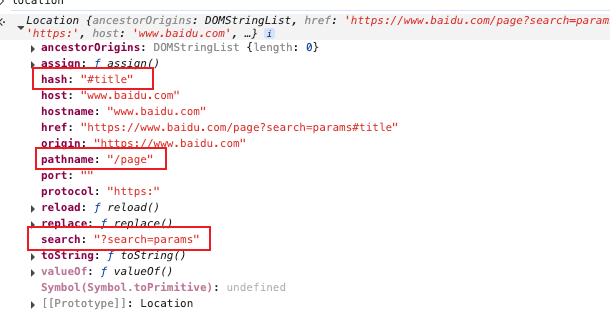
Location对象
location代表当前所在页面的历史信息,在逻辑上,你可以理解为 history栈中存储的一个个项目就是一个个Location,Location继承自path 除此以外还包含了 state和key的信息
/** Location 一个位置,继承Path 包含Path信息和携带的state 以及一个Key */
export interface Location extends Path {state: any;key: Key;
}HistoryState
history中可以通过state属性来保存当前路径的上下文信息,这个信息可以是任意类型,但是在history库中我们进行了约定,其类型如下:
/** HistoryState history的state在window.history中的存储格式 */
type HistoryState = {usr: any;key: Key;idx: number;
};
其中 usr代表当前用户的信息,用户可以存储任意值。
key为当前路径的唯一uuid,idx为当前路径在histroy栈中的序号,方便索引。
我们的Location会被拆分成 state以及href 存入histroy对象,在访问时又会被解析组合成Location对象返回,下面介绍。
事件中心 EventCenter
事件中心为一个构造方法,可以创建一个时间总线,可以通过listen注册监听回调,并且通过call方法广播调用所有组册的listener, 原理很简单 如下:
interface EventCenterType<F extends Function> {length: number,listen: (e: F) => (() => void)call: (arg: any) => void
}class EventCenter<F extends Function> implements EventCenterType<F> {events: F[] = []/** 获取事件数量 */get length() {return this.events.length}/** 监听函数 */listen(event: F) {this.events.push(event)return () => {this.events = this.events.filter(e => e !== event)}}/** call函数 触发事件 */call(arg: any) {this.events.forEach(fn => fn && fn(arg))}
}注意,listen函数回返回一个unlisten函数,方便取消监听!
两种实现模式
下面可以来介绍history的具体实现了,history包含两种路由模式,分别为browserHistory和hashHistory
一个显著的区别就是,hash会在浏览器的地址栏留下 # 锚点,因为其就是依靠hash变动不刷新页面的原理来实现路径的改变和监听的 这也是在pushState和replaceState这两个API出现之前普遍的前端路由实现模式。
pushState和replaceState出现之后,我们不需要通过hash的方式来保证操作history的情况下不刷新页面了,所以也就出现了更为美观的browser模式,这个模式没有 # 冒点,直接会把origin之后作为单页应用路径的开始,相比hash更简洁好看。
但是也有缺点,browser路由由于没有hash先天的浏览器不刷新优势,当用户手动回车时,需要服务器对任意路径的GET资源请求都返回index.html 操作,也就是devServer中histroyApiFallBack属性的作用。
createBrowserHistory
createBrowserHistory是工厂方法,调用会返回一个History对象。
初始状态,会创建listener和blocker两个事件中心,并且从当前的history上,获得当前默认的Location 及 index索引,如下: 注意action表示上一步的操作,默认为POP操作
/** 创建监听和block事件函数 */const listener = new EventCenter<Listener>();const blocker = new EventCenter<Blocker>();/** 获取当前的location和index 从当前window.location中取 */let [location, index] = getCurrentLocationAndIndex();/** 设置默认Action 初始为POP */let action = Action.POP;其中,getCurrentLocationAndIndex用来获取当前的Location对象和index
我们知道,Location是history库定义的对象,其真实的存储并不是以一个Location对象的方式存在histroy栈中,所以这个函数做的事其实是根据当前的histroy位置,组合出一个Location对象来
function getCurrentLocationAndIndex() {const { pathname, hash, search } = window.location;const { state } = globalHistory as { state: HistoryState };return [readOnly<Location>({pathname,hash,search,state: state?.usr || null,key: state?.key || "default",}),state?.idx,] as [Location, number];}在初始化的状态下,history栈.state 一定是为undefined的,此时的index = state?.idx 也为undefined, 所以这个时候就需要对index进行初始化,并且使用replaceState替换到当前的history栈元素中。
/** 如果index为undefined 说明当前页面还没有初始化过history对象* 如果是页面刷新,当前的state里一定有idx*/if (index === void 0) {/** 初始化 idx赋 0 */index = 0;/** 使用replaceState在当前state里加入idx */globalHistory.replaceState({...globalHistory.state,idx: index,},"");}接下来我们看push / replace函数 这两个函数用于向history中推入一个location状态,并且通知事件中心执行listener
push/replace的参数为: push(to: To,state: State)
其中,state为跳转携带的payload 会作为location.state存入
to可以是字符串 也可以是部分的 Path对象 即 Partial<Path> 定义如下
/** 部分的path */
export type PartialPath = Partial<Path>;
/** to 目的路径 */
export type To = string | PartialPath;对应的 你可以用以下的方式 调用 push/replace方法
history.push("/test?a=100&b=200#title",state)
// 等价于
history.push({pathname: '/test',search: "?a=100&b=200",hash: "#title",
},state)// 或者 写部分属性
history.push({pathname: '/test',hash: "#title",
},state)
// 等价于
history.push("/test#title",state)
实现可能会有点复杂 我们慢慢看
/*** push方法* @param to To* @param state any*/function push(to: To, state: State) {/** 生成新的location */const nextLocation = getNextLocation(to, state);const retry = () => {push(to, state);};/** 判断transiton是否允许 */if (allowTx({ location: nextLocation, action: Action.PUSH, retry })) {/** 把location转成存入globalHistory的state 以及URL */const [historyState, url] = getHistoryStateAndUrl(nextLocation,index + 1);/** 保存到GlobalHistory */globalHistory.pushState(historyState, "", url);/**更新状态 调用listener */applyTx(Action.PUSH);}}第一步,我们需要对传入的to参数进行解析,也就是归一化的过程
getNextLocation函数是根据传入的 to解析出来Parial<Path>, state, 结合当前的Location,覆盖生成新的Locaion对象
/*** 生成下一个(新的 带插入的)Location对象* @param to* @param state* @returns Location*/function getNextLocation(to: To, state: State): Location {/** 获得新的path */const nextPath = typeof to === "string" ? parsePath(to) : to;/** 以当前的pathname为base,生成location */return readOnly<Location>({pathname: location.pathname,search: "",hash: "",...nextPath,state,key: generateUniqueKey(),});}其中,parsePath会把一个路径,解析成Path对象, 如下
/*** parsePath: 根据path路径 创建path对象* @param pathStr string* @returns Path*/
function parsePath(pathStr: string): Path {const pathObj: Path = { pathname: "/", hash: "", search: "" };/** 从后向前解析 */const hashIndex = pathStr.indexOf("#");if (hashIndex >= 0) {pathObj.hash = pathStr.slice(hashIndex);pathStr = pathStr.slice(0, hashIndex);}const searchIndex = pathStr.indexOf("?");if (searchIndex >= 0) {pathObj.search = pathStr.slice(searchIndex);pathStr = pathStr.slice(0, searchIndex);}/** 赋值patiname */pathObj.pathname = pathStr;return pathObj;
}可以看到,如果你想在当前的Location下,仅仅修改部分属性,比如search hash 等 请使用 Partial<Path>的方式传递,不要用字符串的形式,否则其会用空值覆盖你没设置的属性,无法达到合并的效果。
拿到了待入栈的Location对象,我们需要将其转换成我们约定好的 history.state的结构,这一步由
getHistoryStateAndUrl 完成,这个函数会将Location对象,拆解成一个HistoryState类型的state 以及一个href路径。
href是什么? 你可以理解为完整的路径,在原生的location对象中,可以看到href 为包含了 origin pathname search hash 的完整路径字符串
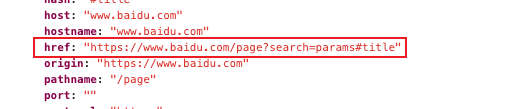
在history中,我们不设计origin的部分,所有的路径跳转都是在当前的orgin范围内的,所以href也就是 pathname+search+hash
/*** createHref方法 支持传入* href 是一个完整的 URL 字符串,用于 <a href> 或 history.pushState/replaceState 等操作。它的具体格式取决于使用的是 browser history 还是 hash history* 在这个代码中,createHref 生成的 URL 不包含协议(http:// 或 https://)、主机(host)和端口(port),它只生成 路径部分(pathname + search + hash)。* @param {to} To* @returns href string*/function createHref(to: To): string {return typeof to === "string" ? to : createPath(to);}其中,如果to不是个字符串,而是Partial<Path> 则需要createPath生成一个完整的href
/*** createPath 解析Path对象 => path字符串* @param param0 Partial<Path>* @returns string*/
function createPath({/** 需要给参数设置初始值,以保证获得一个完整的Path对象 */pathname = "/",search = "",hash = "",
}: PartialPath): string {let pathStr = pathname;if (search) {if (search?.startsWith("?")) {pathStr += search;} else {pathStr += `?${search}`;}}if (hash) {if (hash?.startsWith("#")) {pathStr += hash;} else {pathStr += `#${hash}`;}}return pathStr;
}
getHistoryStateAndUrl这个函数的作用,就是简单的拆解和封装,把state作为histroyState.usr 把location.key 以及当前维护的index + 1 封装成 historyState对象。 并且调用createHref传入Location生成href路径 一起返回
function getHistoryStateAndUrl(nextLocation: Location,nextIndex: number): [HistoryState, string] {return [readOnly<HistoryState>({usr: nextLocation.state,key: nextLocation.key,idx: nextIndex,}),/** nextLocation即成自Path 可以直接传 */createHref(nextLocation),];} 接下来需要做的就是 pushState入栈,并且调用事件中心.call 触发监听回调
/** 把location转成存入globalHistory的state 以及URL */const [historyState, url] = getHistoryStateAndUrl(nextLocation,index + 1);/** 保存到GlobalHistory */globalHistory.pushState(historyState, "", url);/**更新状态 调用listener */listeners.call({action: Action.POP,location: nextLocation})主要逻辑如此,但是真实的history.push方法会更复杂一些, 我们需要了解一下history的阻塞逻辑。
阻塞 block
在看阻塞之前,我们需要先看一下Update对象,其本质就是对action和location的简单封装
/** 更新,包含动作action和新的Location */
export type Update = {action: Action;location: Location;
};在我们调用 listeners.call() 传入的参数,正式这个Update对象,我们可以看到 Listener的定义如下:
/** 监听事件函数 */
export type Listener = (updates: Update) => void;而blocker函数,本质也是listener,其由history.block方法注册,如下:
const unblock = history.block(function handleBlock(tx: Transition){if(confirm("当前跳转不会保存任何信息,是否继续?")){unblock() // 取消阻塞tx.retry() // 重试}
})其应用场景在于,当我们需要拦截用户的跳转操作时,可以通过注册blocker函数来完成,比如当用户在编写表单的时候,如果在表单没有提交或者保存时离开,就可以通过blocke拦截并且对用户做出提示
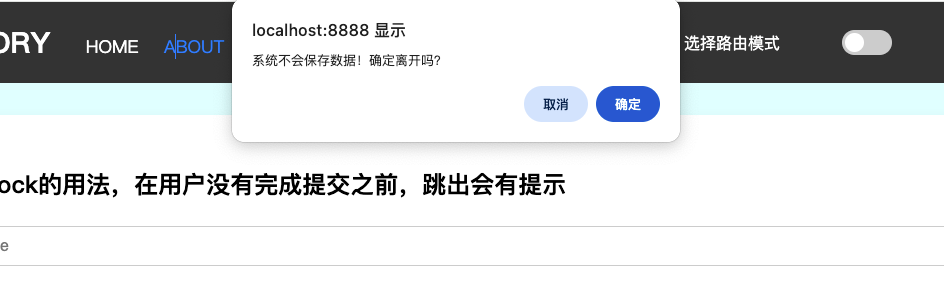
实现方法是通过 allowTx和applyTx完成。 Tx即Transition的意思 即 “过渡” 如果你熟悉React,你可能会对新增的useTranstion hooks 比较熟悉。
过渡即中间状态的意思,其ts定义如下,本质就是继承自Update并且增加了retry方法
/** 表示一个事务 block时用 */
export interface Transition extends Update {retry: () => void;
}/** 阻塞事件函数 */
export type Blocker = (transition: Transition) => void;
其工作原理也就是,在跳转之前,检查blocker对象,如果存在blocker函数,那么就把当前要跳转的任务 作为retry函数封装到Transtion内,交给blocker函数去执行,决定是否需要继续执行当前的跳转。
push函数中,我们可以看到
const retry = () => {push(to, state);};/** 判断transiton是否允许 */if (allowTx({ location: nextLocation, action: Action.PUSH, retry })) {/** 把location转成存入globalHistory的state 以及URL */const [historyState, url] = getHistoryStateAndUrl(nextLocation,index + 1);/** 保存到GlobalHistory */globalHistory.pushState(historyState, "", url);/**更新状态 调用listener */applyTx(Action.PUSH);}先通过allowTx 判断当前push任务是否能执行,如果能再调用下面的代码生成nextLocation
allowTx的实现很简单,就是判断当前的blocker的长度是不是为0 如果为0 就允许运行,表示当前无blocker阻塞,如果不是,就不允许运行,同时调用blocker.call(tx)
/** 判断transition是否能执行 */function allowTx(transition: Transition) {return !blocker.length || blocker.call(transition) || false;}
这里需要注意的一点是,如果blocker.length !== 0 那么 !blocker.length 为 false 此时 表达式的结果需要通过|| 后面的部分决定。 如果blocker.length === 0 那么表达式可以直接结束,不需要执行后面的代码了
(blocker.call(tx) || false) 永远返回false,表示当前allowTx不允许,并且同时调用了 blocker.call函数 设计的很巧妙!
如果allowTx不允许,那么push函数结束,跳转会先被拦截。
在blocker函数内,如果允许跳转继续,则会由内部调用 retry函数,重新允许push方法。
这也就是 tx成为 过渡的意思,先暂停跳转 再根据条件重试跳转 正是过渡的思想!
applyTx 即应用过渡,传入action,其内部会调用 getCurrentLocationAndIndex 更新全局的location和key 以及action。并且调用listener.call方法触发监听事件。 此时 外部系统才能接收到路径变动的通知 并且修改内容UI
/** 应用 事务 变更内部状态 调用listener */function applyTx(nextAction: Action) {action = nextAction;/** 此时新的location已经被设置,需要调用listener 更新location和index状态 */[location, index] = getCurrentLocationAndIndex();listener.call({ location, action } as Update);}
replace函数本质和push一样,只不过调用的replaceState方法
/*** replace* @param to To* @param state any*/function replace(to: To, state: State) {/** 生成新的location */const nextLocation = getNextLocation(to, state);const retry = () => {push(to, state);};/** 判断transiton是否允许 */if (allowTx({ location: nextLocation, action: Action.REPLACE, retry })) {/** 把location转成存入globalHistory的state 以及URL */const [historyState, url] = getHistoryStateAndUrl(nextLocation,index + 1);/** 保存到GlobalHistory */globalHistory.replaceState(historyState, "", url);/**更新状态 调用listener */applyTx(Action.REPLACE);}}监听popstate
我们刚才总结了,history的变动有两条路,我们现在已经对 pushState 和 replaceState这条路进行了监听,接下来就是对popstate事件的监听,即 用户手动修改url 点击浏览器前进后退按钮 以及history.go() 等操作的监听
这部分会相对复杂一点 但是本质上和push监听阻塞没什么区别
/** 监听popstate函数 监听go 浏览器前进后退按钮事件 */let blockTx: Transition | null = null;window.addEventListener(POP_STATE, () => {if (blockTx) {/** 如果存在blockTx 直接调用blocker处理tx */blocker.call(blockTx);blockTx = null;} else {/** 不存在blockTx */if (blocker.length) {/** 有阻塞 会退 设置blockTx *//** 由于此时location已经修改完成 直接获取当前location和index即可 */const [nextLocation, nextIndex] = getCurrentLocationAndIndex();if (nextIndex !== void 0) {/** 计算会退step */const steps = index - nextIndex;/** 封装retry */function retry() {go(-steps);}/** 封装blockTx */blockTx = {location: nextLocation,action: Action.POP,retry,};/** 回退 */go(steps);} else {warning("请不要绕过history调用 pushState/replaceState");}} else {/** 没有阻塞 应用tx */applyTx(Action.POP);}}});当用户点击浏览器前进后退按钮时,浏览器会先操作history完成跳转,然后再通过宏任务的方式触发popstate事件,也就是说,我们监听到popstate时间时,跳转已经发生了!
此时我们需要做的就是,回退,比如当前用户使用history.go(-2)向前跳转了两个历史,但是当前还存在一些blocker 此时我们需要计算 当前index和全局维护的index的距离,并且反向先跳转回到当前的历史。同时创建一个transtion过渡对象,保存在一个全局的blockTx变量下。
回退之后,回退事件调用的go(step) 会再次触发popstate,此时由于blockTx有值,所以去执行blocker.call(tx) blocker内部调用retry函数,重新go(step) 恢复跳转
跳转之后 继续触发popstate,此时blcoker为空,调用applyTx 更新状态,调用listener
如下图所示:
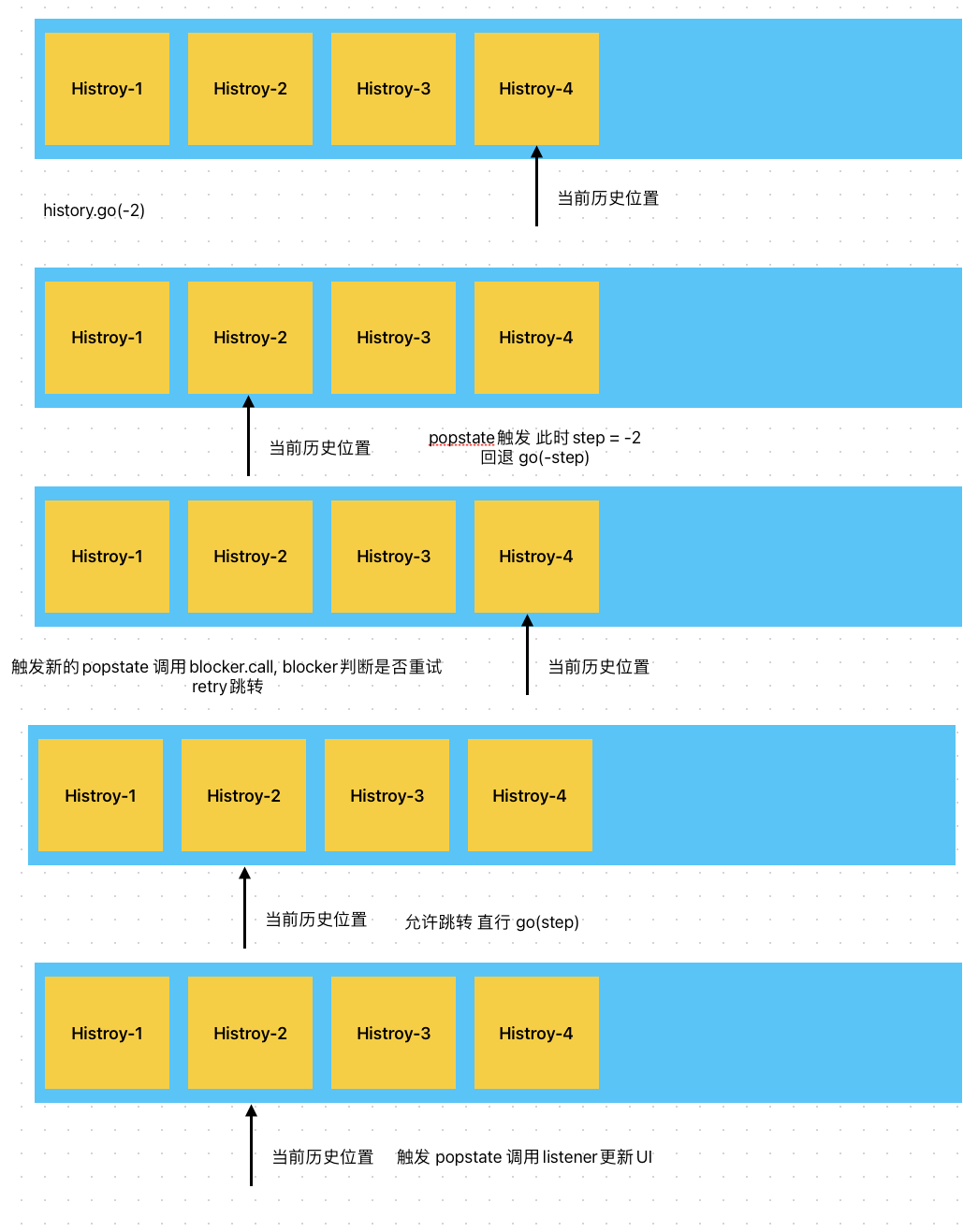
最后,导出上述实现的方法:
return {action,location,push,replace,createHref,go,back: () => {go(-1);},forward: () => {go(1);},listen: (fn: Listener) => {return listener.listen(fn);},block: (fn: Blocker) => {const unblock = blocker.listen(fn);if (blocker.length > 0) {window.addEventListener(BEFORE_UNLOAD, handleBeforeUnload);}return () => {unblock();if (blocker.length === 0) {window.removeEventListener(BEFORE_UNLOAD, handleBeforeUnload);}};},};这里需要注意,还需要考虑用户直接切到战外的情况,比如我在当前的表单页面直接通过url栏跳转到百度,那么此时也需要对用户进行提示

这个弹窗由浏览器提供,需要在 beforeUnLoad事件中设置监听!
阻止事件默认事件 并且设置returnValue ="" 即可!
/*** 处理浏览器url回撤跳转的情况,让浏览器弹出弹框提示用户* @param e*/
function handleBeforeUnload(e: any) {e.preventDefault();e.returnValue = "";
}createHashHistory
createHashHistory和createBrowserHistory基本一致 其主要区别在于,getCurrentLocationAndIndex 不能直接从window.location中 获取 pathname search hash 等
因为hash模式下,真正的href是从#后面开始的,所以需要截取#后面的部分 自己解析即可!
/** 获得当前的Location和index 注意 这里需要从location.hash 获取 并且使用parsePath解析* hash模式下,由于真正的路由信息在# 后 所以浏览器不会自动解析好Path: {pathname,search,hash}*/function getCurrentLocationAndIndex() {/** 注意区别 这里是从location.hash取hash信息 并且自己Parse */const hashStr = window.location.hash;const state = globalHistory.state as HistoryState;/** 这里注意 hashStr为 #/aaa 的形式 需要从第一个开始截取 */const { pathname, search, hash } = parsePath(hashStr.slice(1));return [readOnly<Location>({pathname,search,hash,state: state?.usr,key: state?.key,}),state?.idx,] as const;}其余内容和browser类似!
browser路由刷新问题
对于hash路由,由于改变的是#后的路径,用户回车后不会重新发起请求。
对于brwoser路由,用户回车之后,浏览器会重新发起请求,因为其路径和普通url别无二致。
这个时候,如果当前所在的页面为 http://127.0.0.1:8080/home 用户回车后,浏览器会向服务器请求 /home.html的资源,但是由于页面的路由是虚拟的,没有与其对应的html文档 就会报错404

解决办法
1. 前端开发解决, 设置devSever的historyApiFallback
2. 后段部署解决,修改nginx策略,当资源未找到时,直接返回index.html 即可!