网络原理 - 4(TCP - 1)
目录
TCP 协议
TCP 协议段格式
可靠传输
几个 TCP 协议中的机制
1. 确认应答
2. 超时重传
完!
TCP 协议
TCP 全称为 “传输控制协议”(Transmission Control Protocol),要对数据的传输进行一个详细的控制。
TCP 协议段格式
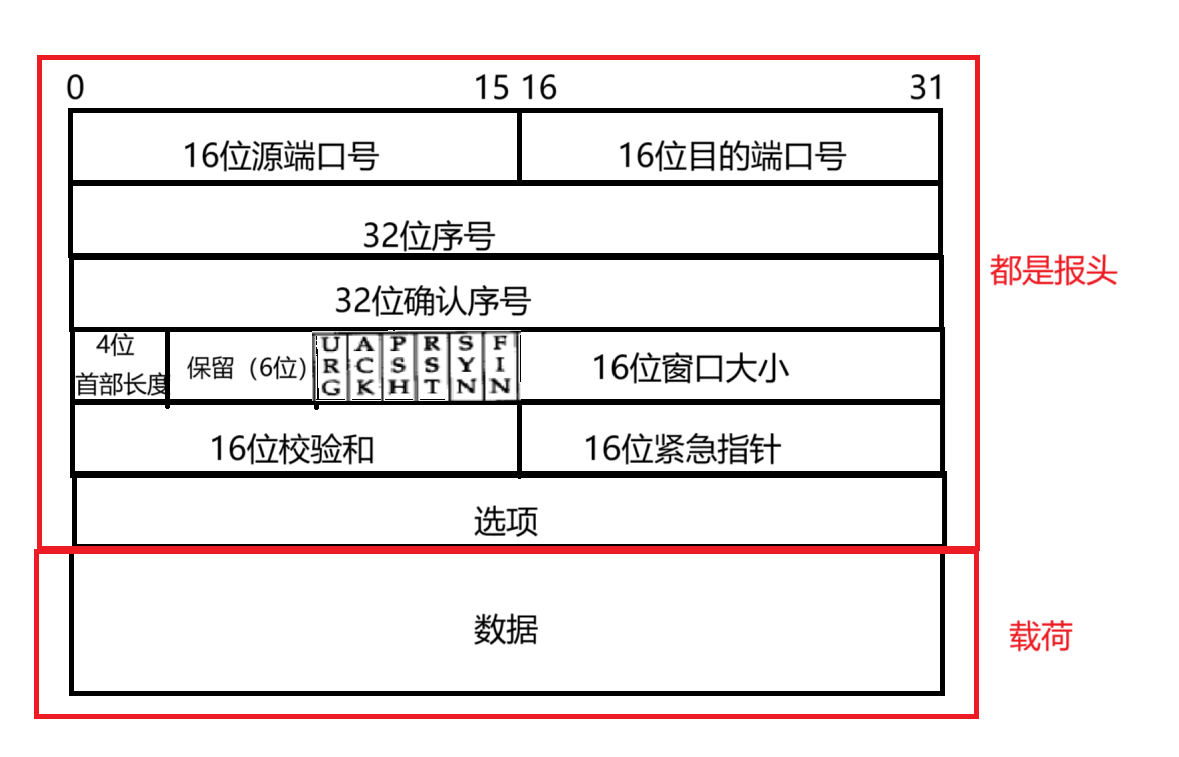
TCP 的报头对比于 UDP 的报头,就复杂很多了~~~
源端口号,目的端口号:和 UDP 还是一样的,表示数据是从那个进程来,到那个进程去。
32 位序号和 32 位确认序号,后面再详谈
4 位首部长度:首部长度也就是报头长度(header),不像 UDP 协议(报头固定是 8 个字节),TCP 报头中的前 20 个字节是固定长度的。后面这里包含了“选项(optional)”部分,选项部分可以有,也可以没有,可以有一个,也可以有多个。总的来说,表示了该 TCP 头部有多少个 32 位 bit(有多少个 4 字节),4 位首部长度,则说明 TCP 头部最大长度是 15(1111) * 4 = 60
保留位(reserved):在 UDP 协议中,长度受到 2 个字节的限制,想要进行扩展,发现无法扩展,一旦改变了报头长度,就会使得发送的 UDP 数据报和其他机器不兼容,无法通信。TCP 就提前做好了防备,设定报头的时候,提前准备了几个保留位(虽然不用,但先占个位置),后面一旦需要了,就把这些保留位给使用起来。
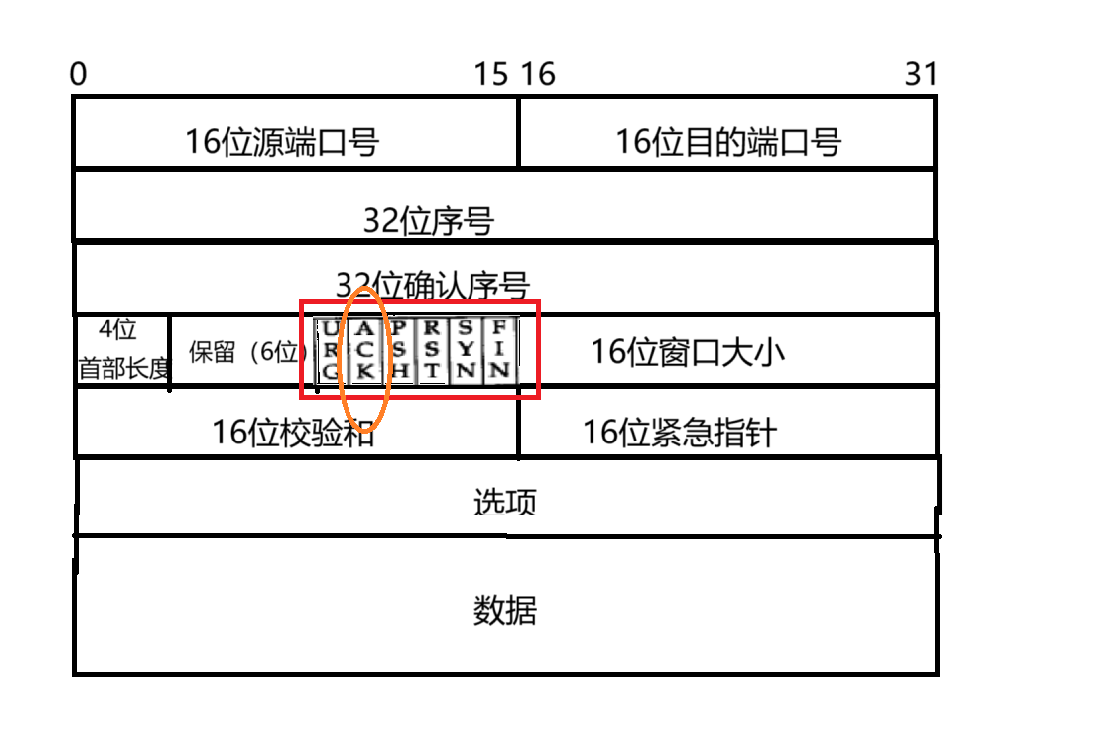
URG,ACK,PSH,PST,SYN,FIN:6 位标志位,是 TCP 协议中非常核心的部分,后面会详细展开
16 位窗口大小:后面再详谈
16 位校验和:类似于 UDP 的校验和一样。会把报头和数据载荷放在一起进行校验和。
16 位紧急指针:可以表示那部分数据是紧急数据。
TCP 内部的机制有非常多,上述报头的字段都是针对 TCP 中的各个机制的属性支撑,我们要详细了解 TCP 中的其他机制,才能更加深刻的认识到报头的含义。
可靠传输
前面我们提到 TCP 的特点:有连接,可靠传输,面向字节流,全双工。其中,TCP 中最核心,最重要的就是解决“可靠传输”的问题。
网络通信的过程是及其复杂的,无法确保发送方发出去的数据,100% 能够到达接收方。此处所提到的可靠性,只能“退而求其次”,只要尽可能的去进行发送,发送方能够知道对方是否收到,就认为是“可靠传输”了。
几个 TCP 协议中的机制
1. 确认应答
用来确保可靠性最核心的机制,称为“确认应答”。
举个栗子:A 和 B 进行交互~
A 向 B 发出消息说:“兄弟,晚上有事情吗,一起吃个饭”,B 回复:“好呀好呀”
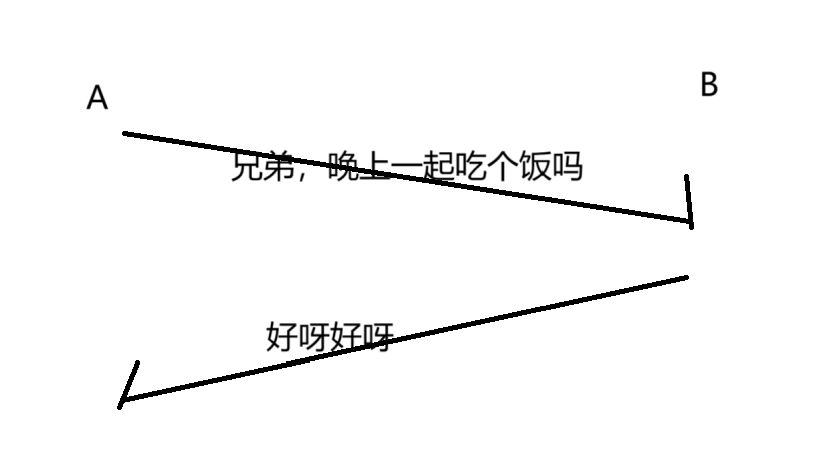
但是当 A 再说出下面这句“借我5000块”,B 看到之后,心想,果然没按好心,会回复”滚呀滚呀“。
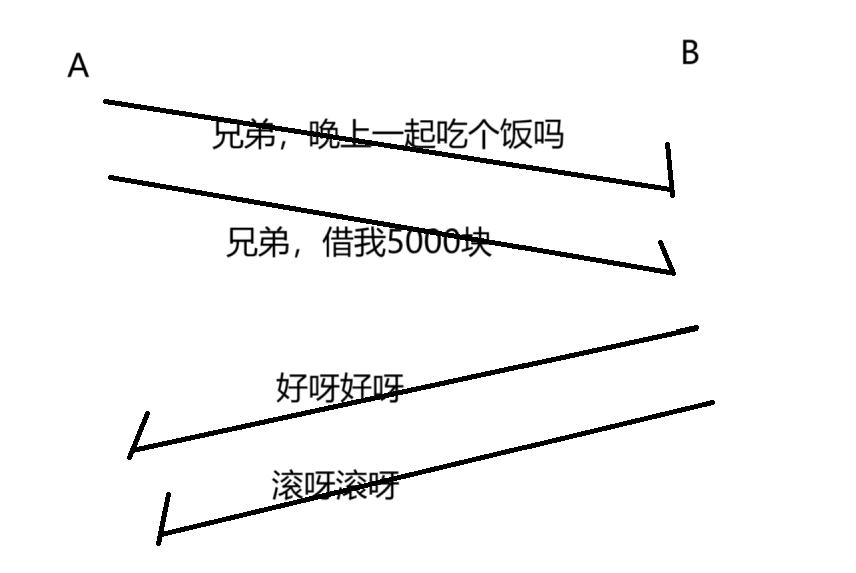
但是上面情况的时序,有些过于理想化了,实际上,网络传输过程中,经常会出现”后发先至”的情况。
网络通信中,为什么会出现“后发先至”的情况呢???
当一个数据报从发送方到接收方,其数据报会经历许多交换机 / 路由器,其传输过程中走的路径可能不一样,第一个数据包,可能走路线一,第二个数据包,走路线二...
有可能路线二畅通,路线一发生阻塞了,这就会导致,数据包二虽然后发,但是会先到达接收方。
我们上述的对话就可能变成这样:
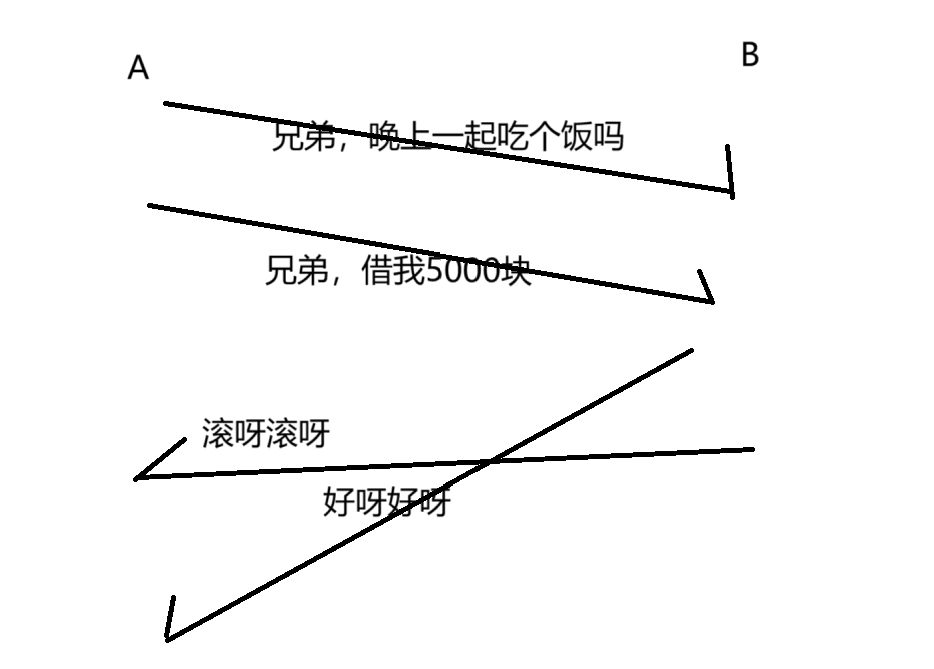
如果出现后发先至的情况,再去理解这里的含义,就会出现问题了!!!
为了解决上述的问题,就引入了序号和确认序号,对数据进行编号,应答报文里面,就告诉发送发,我这次应答的是那个数据!
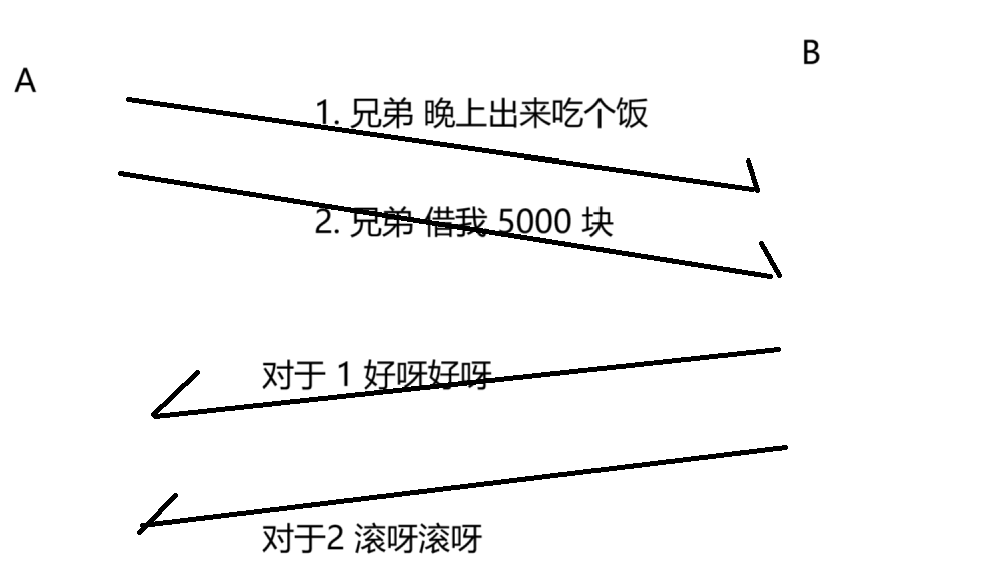
当然,我们上述的情况是一个简化版本的模型,真实的 TCP 协议的情况是更加复杂的。
TCP 是面向字节流的,以字节为单位进行传输的,没有“一条 两条”的概念。
实际上,TCP 的序号和确认序号都是以字节来进行编号的。
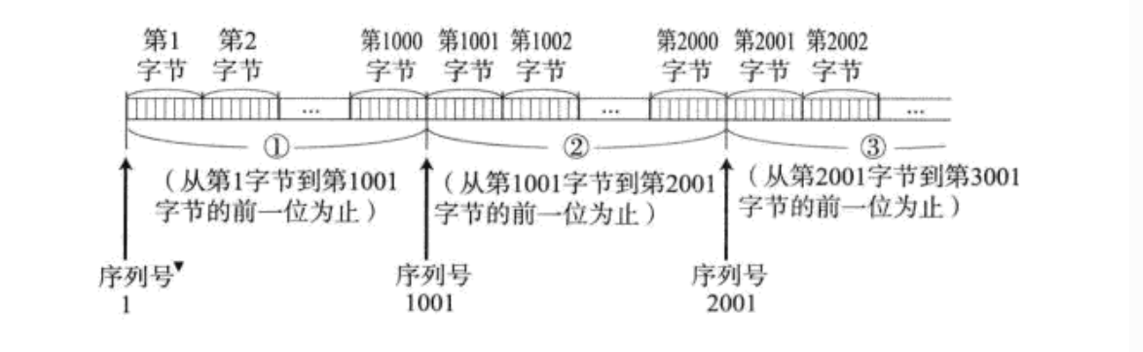 这就呼应到我们前面 TCP 协议中报头的 32 位序号了,在 TCP 的报头中的序号,只能存一个。
这就呼应到我们前面 TCP 协议中报头的 32 位序号了,在 TCP 的报头中的序号,只能存一个。
比如说有如下数据报:
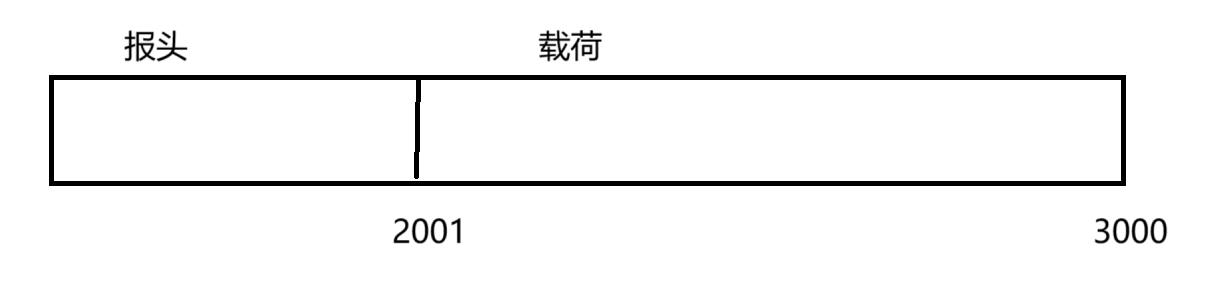
即假设载荷有 1000 个字节,1000 个序号,由于序号是连续的,只需要在报头中保存第一个字节的序号 - 2001 即可,后续字节的序号都是很容易计算得到的~
而应答报文中的确认序号,是按照发送过去的最后一个字节的序号再加 1 来进行设定的~
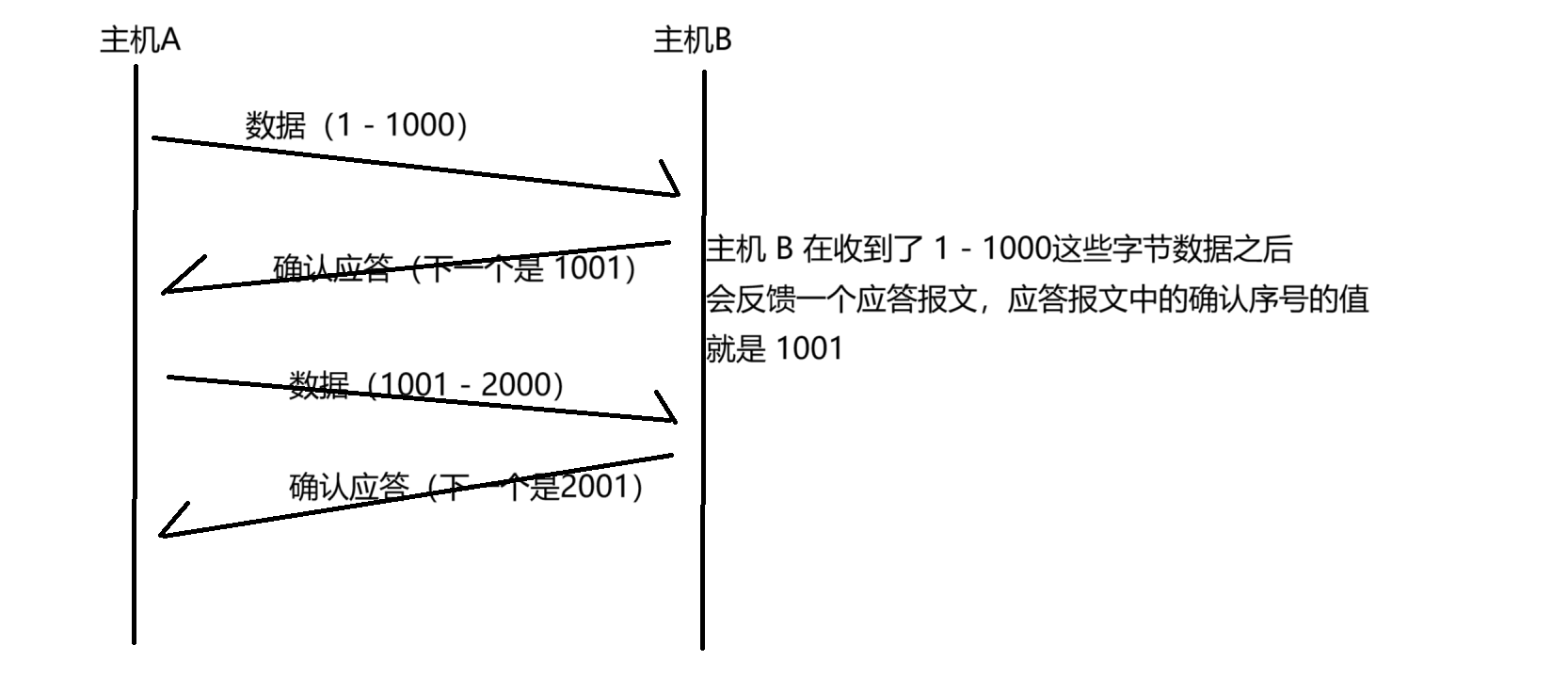
确认应答 1001 的含义,有两种或理解方式:
1. 数据小于 1001 的数据,都已经收到了
2. 发送方接下来要给我(接收方)发 1001 开始的数据了
TCP 的确认应答是确保 TCP可靠性的最核心的机制!!!
(错误的说法:TCP 之所以能够保证可靠性,是因为“进行了“三次握手”)
在确认应答中,通过应答报文来反馈给发送方,表示当前的数据正确收到了。应答报文,也叫做 ACK(acknowledge) 报文。这个 ACK 是不是有些熟悉呢???就是我们刚刚在报头结构中的 6 位标记位中的一位~~~平时的普通报文,ACK 这位是 0,如果当前报文是应答报文,则此时这个报文的 ACK 位置就是 1。
2. 超时重传
超时重传这个机制,是对确认应答的补充。
如果一切顺利,通过应答报文,接收方就可以告诉发送方,当前数据是不是成功收到了,但是,网络上可能存在“丢包”的情况。如果数据包丢了,没有到达对端,对方自然也就没有 ACK 报文了。
这个情况下,就需要超时重传了!
TCP 可靠性就是在对抗丢包,期望做到,在丢包情况客观存在的时候,也能够尽可能的把包传过去!
大概流程如下:
发送方发了个数据过去之后,要等一段时间。在等待的这段时间中,收到了接收方发来的 ACK(数据报在网络上传输也是需要时间的)如果等了好久,ACK 还没有等到,此时发送方就会人数数据的传输出现丢包情况了,当认为丢包之后,就会把刚才的数据包再传一次(重传),等待的过程有一个时间上的阈值(上限),就是超时。
上面的流程中,是认为没收到 ACK 就是丢包,其实这样说是有些问题的。
丢包,不一定就是发的数据丢了,还有可能是,ACK 丢了。数据丢了,还是 ACK 丢了,在发送方的角度来看,咦,都是一样的呀,就是收不到接收方的 ACK
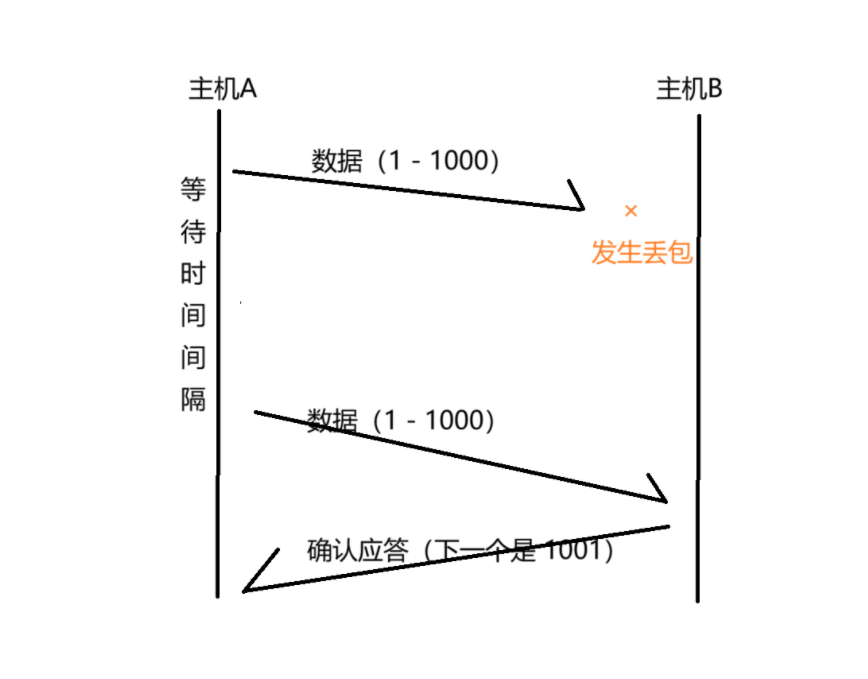
当我们是上面这种情况下,接收方本身就没收到数据,此时进行重传是理所应当的,没有任何问题~~~
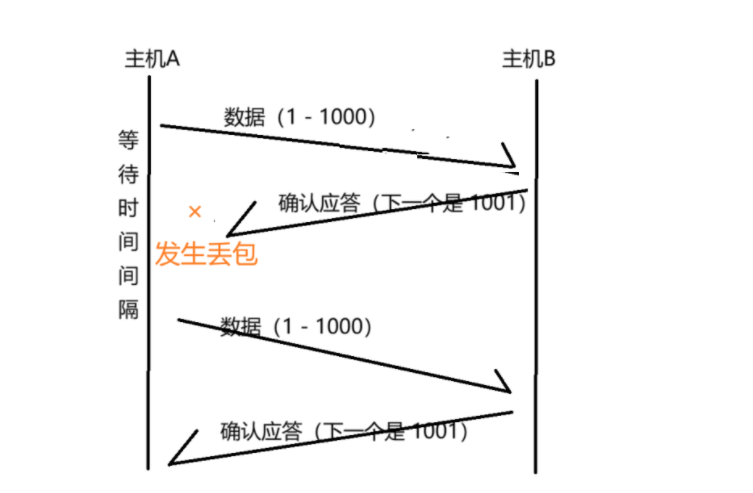
但如果是上图这种情况呢???数据已经被 B 收到了,再传输一次,同一份数据,B 就会收到两次,试想一下,如果发送的请求是扣款请求呢???(扣两次款???用户一定会猛喷!!!)
其实不然~~~
TCP socket 在内核中,存在一个接收缓冲区(一块内存空间),发送方发来的数据,是要先放到接收缓冲区中的,然后应用程序调用 read / scanner.next 才能读取到数据,这里的读操作,其实是读取接收缓冲区中的数据。

当数据到达接收缓冲区的时候,接收方首先会判定一下,看当前缓冲区中,是否已经有这个数据了(也会判定,这个数据曾经是否在缓冲区中存在过),如果已经存在或者存在过,就直接把重发发来的数据就丢弃了~~就能确保应用程序,在调用 read / scanner.next 的时候,不会出现重复数据~~~
那接收方是如何判定这个数据是否是“重复数据”呢???
核心的判定依据,还是我们刚刚提到过的 -- 数据的序号!!!
1. 数据还在缓冲区里面,还没有被 read 走,此时,我们就要拿着新收到的数据的序号,和缓冲区中的数据的序号对一下,看看有没有一样的,有一样的,就是重复了,就可以把新收到的数据丢弃了。
2. 数据已经被应用程序给 read 走了,此时新来的数据的序号就无法直接在接收缓冲区中查到了。
但是!!!应用程序在读取数据的时候,是会按照序号的先后顺序,连续进行读取的!!!
先读 1 - 1000, 1001 - 2000, 2001 - 3000。
一定是先读序号小的数据,然后再读序号大的数据(可以把接收缓冲区理解为带有优先级的阻塞队列)。此时 socket API 中就可以记录上次读的最后一个字节的序号是多少。
比如上次读的最后一个字节的序号是 3000,新收到一个数据包的序号是 1001,则这个 1001 一定是之前已经读过的了~这个时候,同样可以把这个新的数据包判定为“重复的包”直接丢弃掉~~~
上面谈到的 ACK,重传,保证顺序,自动取宠,其实都是 TCP 已经内置好了的,我们使用 TCP 的 API 的时候,outputStream.write() 只需要简单的调用这一行代码,上述功能都自动生效了~~~
(UDP 的不可靠,我们就需要好好考虑一下上面的问题了~~~)
补充:
超时是会重传,但是重传过程中,也是有一定策略的。
1. 重传次数是有上限的,重传到一定的程序,还没有收到 ACK,就会尝试重置连接,如果充值也失败,发送方就会直接放弃连接。
2. 重传的超时时间阈值也不是固定不变的,会随着重传次数的增加而增大。(换句话讲,就是重传的频率会越来越低)(因为:如果经历过了重传之后,还出现了丢包情况,那大概率是网络出现了比较严重的问题了,再怎么重传,也是白费劲,不如省点力气~~~)
举个栗子:
假设:一次网络通信过程中,丢包的概率是 10%(这已经是一个非常夸张的数字了!!!)
包能顺利到达的概率是 90%,那我们重传了一次,却又发生丢包,即两次传输数据都丢包的概率是 10% * 10% = 1% ==》换个角度看,两次传输包至少有一次能到达的概率是 99%,随着重传的次数增加,包到达接收方的概率也会大大增加,如果我们连续重传了三四次仍然还是发生丢包,只能说明,此时的丢包率是非常非常非常大了,意味着此时的网络已经出现了非常非常严重的故障了!!!再重传也意义不大了~~~