MAGI-1自回归式大规模视频生成
1. 关于 MAGI-1
提出 MAGI-1——一种世界模型(world model),通过自回归方式预测一系列视频块(chunk,固定长度的连续帧片段)来生成视频。
模型被训练为在时间维度上单调递增噪声的条件下对每个块进行去噪,从而实现 因果时序建模,并天然支持流式生成。
在 图像到视频 (I2V) 任务中,MAGI-1 结合多项算法创新与专用基础设施,兼具高时间一致性与可扩展性。模型还支持块级提示(chunk-wise prompting),实现平滑场景衔接、长时段合成以及细粒度文本控制。
MAGI-1 为统一高保真视频生成、灵活指令控制和实时部署提供了有前景的方向。
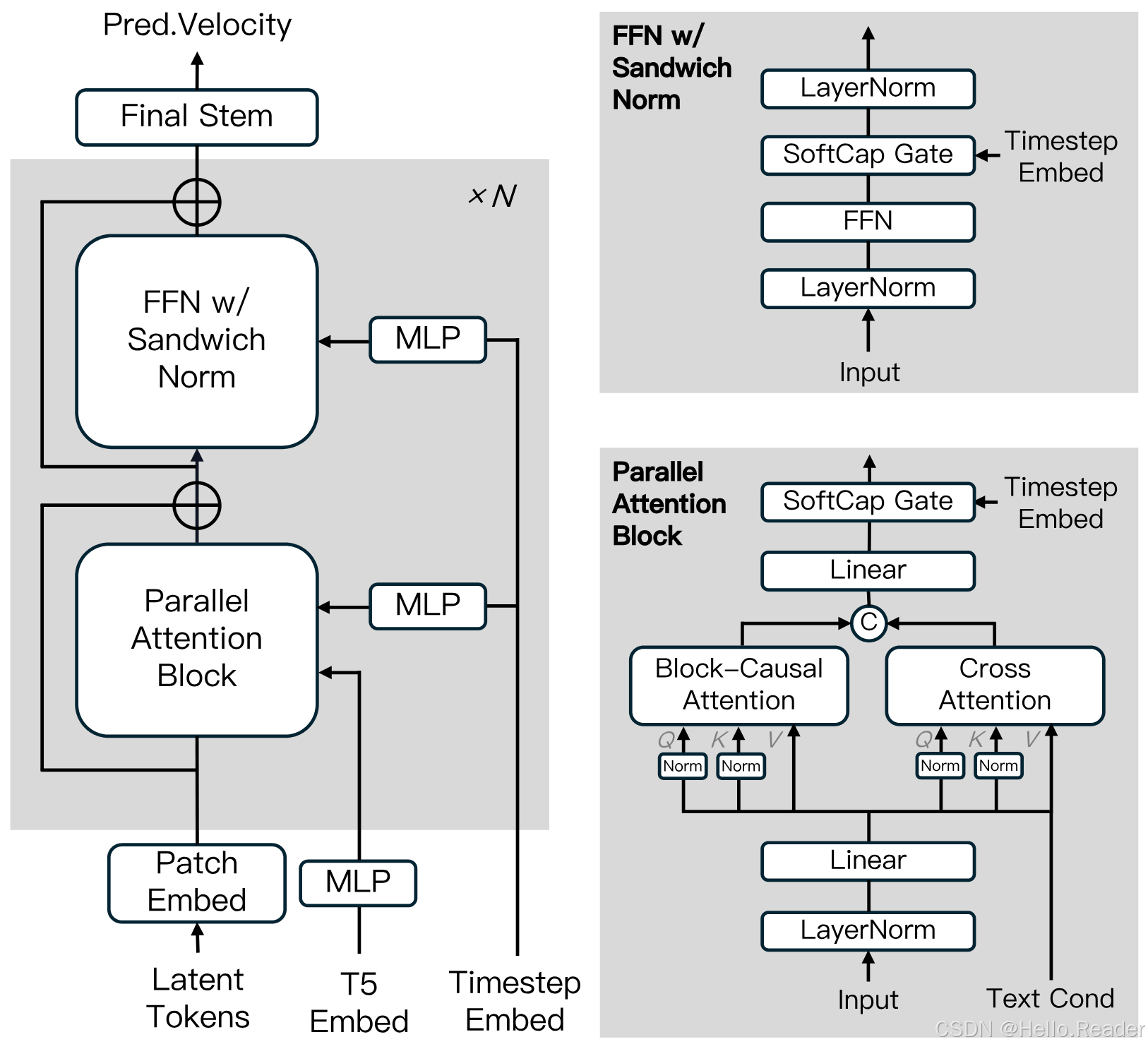
2. 模型概览
Transformer-based VAE
- Transformer 架构的变分自编码器,空间 8× + 时间 4× 压缩
- 解码速度快、重建质量高度竞争
自回归去噪算法
MAGI-1 按 块(每块 24 帧)而非整体进行自回归去噪。当当前块达到设定清晰度阈值,即可并行启动下一块生成,最多同时处理 4 块,显著提升效率。

扩散模型架构
基于 Diffusion Transformer,并引入多项关键创新以提升大规模训练效率与稳定性:
- Block-Causal Attention
- Parallel Attention Block
- QK-Norm 与 GQA
- Sandwich Norm、SwiGLU
- Softcap Modulation
详见技术报告。
蒸馏算法
采用 Shortcut Distillation:同一速度场(velocity-based)模型兼容多种推理预算。
- 训练中在步长 {64, 32, 16, 8} 间循环采样,并强制“大步 = 两个小步”自洽。
- 融合 Classifier-Free Guidance 蒸馏,在效率与保真度之间取得平衡。
3. 模型家族
| 模型 | 下载链接 | 推荐硬件 |
|---|---|---|
| T5 | ↗ | — |
| MAGI-1-VAE | ↗ | — |
| MAGI-1-24B | ↗ | H100 / H800 × 8 |
| MAGI-1-24B-distill | ↗ | H100 / H800 × 8 |
| MAGI-1-24B-distill + fp8_quant | ↗ | H100 / H800 × 4 或 RTX 4090 × 8 |
| MAGI-1-4.5B | ↗ | RTX 4090 × 1 |
4. 评测结果
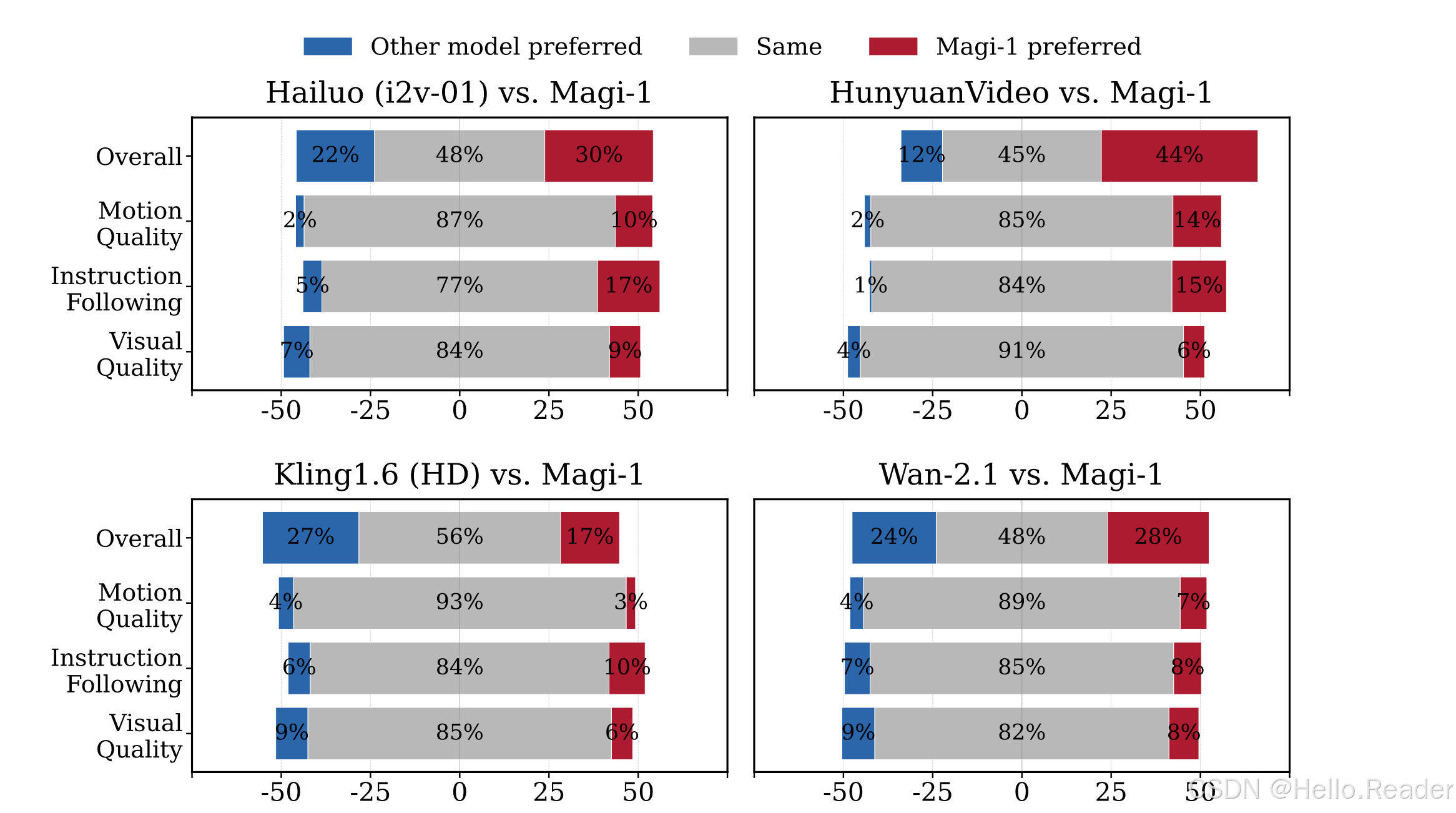
内部人类评测
MAGI-1 在开源模型中取得 SOTA(超越 Wan-2.1,显著领先 Hailuo、HunyuanVideo),在指令遵循和运动质量方面尤为突出,可与闭源商业模型 Kling 竞争。
物理评测(视频续帧)
| 模式 | 物理 IQ ↑ | 空间 IoU ↑ | 时空一致 ↑ | 加权 IoU ↑ | MSE ↓ |
|---|---|---|---|---|---|
| Magi (V2V) | 56.02 | 0.367 | 0.270 | 0.304 | 0.005 |
| VideoPoet (V2V) | 29.50 | 0.204 | 0.164 | 0.137 | 0.010 |
| Magi (I2V) | 30.23 | 0.203 | 0.151 | 0.154 | 0.012 |
| Kling 1.6 (I2V) | 23.64 | 0.197 | 0.086 | 0.144 | 0.025 |
| VideoPoet (I2V) | 20.30 | 0.141 | 0.126 | 0.087 | 0.012 |
| Gen 3 (I2V) | 22.80 | 0.201 | 0.115 | 0.116 | 0.015 |
| Wan 2.1 (I2V) | 20.89 | 0.153 | 0.100 | 0.112 | 0.023 |
| Sora (I2V) | 10.00 | 0.138 | 0.047 | 0.063 | 0.030 |
| GroundTruth | 100.0 | 0.678 | 0.535 | 0.577 | 0.002 |
5. 运行指南
5.1 环境准备(推荐 Docker)
# 拉取镜像
docker pull sandai/magi:latest# 启动容器
docker run -it --gpus all --privileged \--shm-size=32g --name magi --net=host --ipc=host \--ulimit memlock=-1 --ulimit stack=6710886 \sandai/magi:latest /bin/bash
源码方式
# 创建环境
conda create -n magi python==3.10.12
conda activate magi# 安装 PyTorch
conda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 \pytorch-cuda=12.4 -c pytorch -c nvidia# 安装依赖
pip install -r requirements.txt# 安装 ffmpeg
conda install -c conda-forge ffmpeg=4.4# 安装 MagiAttention
git clone git@github.com:SandAI-org/MagiAttention.git
cd MagiAttention
git submodule update --init --recursive
pip install --no-build-isolation .
5.2 推理命令
修改 example/24B/run.sh 或 example/4.5B/run.sh 控制输入输出。
关键参数说明
--config_file:模型配置文件路径,如example/24B/24B_config.json--mode:t2v(文本→视频) /i2v(图像→视频) /v2v(视频→视频)--prompt:文本提示(仅t2v模式)--image_path:输入图像路径(仅i2v模式)--prefix_video_path:前缀视频路径(仅v2v模式)--output_path:生成视频保存路径
Bash 示例
# 运行 24B
bash example/24B/run.sh# 运行 4.5B
bash example/4.5B/run.sh
自定义示例
# 图像转视频
--mode i2v \
--image_path example/assets/image.jpeg \# 视频续帧
--mode v2v \
--prefix_video_path example/assets/prefix_video.mp4 \
5.3 config.json 常用字段
| 字段 | 含义 |
|---|---|
| seed | 随机种子 |
| video_size_h / w | 输出分辨率 |
| num_frames | 视频时长 |
| fps | 帧率(4 帧 = 1 latent_frame) |
| cfg_number | 原始模型 2;distill/quant 模型 1 |
| load | 模型权重目录 |
| t5_pretrained / vae_pretrained | 预训练权重路径 |