Kubelet 可观测性最佳实践
Kubelet 介绍
Kubelet 是 Kubernetes 集群中的一个核心组件,它在每个节点上运行并负责维护容器的生命周期。这包括创建和删除容器、监控容器的健康状况以及向 Kubernetes 控制平面报告容器的状态。此外,Kubelet 还负责将容器日志上传到配置的日志服务器,并提供容器运行时的度量信息。对 Kubelet 的性能进行深入了解和监控是确保 Kubernetes 集群稳定性和效率的关键。
Kubelet 监控主要有以下几个方面的维度:
| 监控维度 | 描述 | 重要性 |
|---|---|---|
| 节点状态监控 | 监控节点的健康状况,包括 Ready、NotReady 状态 | 高 |
| 容器状态监控 | 监控容器的运行状态,如 Running、Paused、Terminated 等 | 高 |
| 系统资源监控 | 监控 CPU、内存、磁盘等资源的使用情况 | 高 |
| 网络监控 | 监控 Pod 和节点的网络性能和连接状态 | 中 |
| 事件和日志监控 | 监控 Kubernetes 集群中的事件和日志,帮助理解应用程序和资源的状态 | 高 |
| 追踪监控 | 跟踪请求在系统各服务和组件中的流程 | 中 |
| Pod 调度和运行 | 监控 Pod 的调度效率和运行时性能 | 高 |
| Kubelet API 性能 | 监控 Kubelet API 的响应时间和错误率 | 中 |
| 镜像拉取和存储 | 监控容器镜像的拉取效率和存储使用情况 | 中 |
Kubelet 组件的核心指标接口,除了本身的 /metrics 以外,还包括 cAdvisor 相关的指标接口 /metrics/cadvisor。以下为接口的简要说明。
/metrics
/metrics 接口提供了 kubelet 自身以及节点级别的监控指标。这些指标可以帮助管理员监控节点资源使用情况,优化资源分配,并快速定位性能瓶颈。以下是一些关键的指标类型:
- CPU 指标:包括 cpu_usage_total(总 CPU 使用量)和 cpu_usage_percent(CPU 使用率)等。
- 内存指标:包括 memory_usage_total(总内存使用量)和 memory_usage_percent(内存使用率)等。
- 存储指标:包括 disk_io_total(总磁盘 I/O)和 disk_io_rate(磁盘 I/O 速率)等。
- 网络指标:包括网络流量和带宽使用情况等。
这些指标对于监控节点资源使用和性能分析至关重要。
/metrics/cadvisor
/metrics/cadvisor 接口是由集成在 kubelet 中的 cAdvisor 提供的,用于监控容器资源使用情况。cAdvisor(Container Advisor)是 Google 开源的一个工具,它可以在各种容器环境中运行,包括 Docker、rkt 等。以下是 cAdvisor 的一些关键特性和指标:
- 容器级别的监控:cAdvisor 提供了容器级别的资源使用数据,包括 CPU、内存、磁盘 I/O 等。
- 实时数据:cAdvisor 定期从容器中收集信息,并暴露在 HTTP 接口上供用户查询。
观测云
观测云是一款专为 IT 工程师打造的全链路可观测产品,它集成了基础设施监控、应用程序性能监控和日志管理,为整个技术栈提供实时可观察性。这款产品能够帮助工程师全面了解端到端的用户体验追踪,了解应用内函数的每一次调用,以及全面监控云时代的基础设施。此外,观测云还具备快速发现系统安全风险的能力,为数字化时代提供安全保障。
部署 DataKit
DataKit 是一个开源的、跨平台的数据收集和监控工具,由观测云开发并维护。它旨在帮助用户收集、处理和分析各种数据源,如日志、指标和事件,以便进行有效的监控和故障排查。DataKit 支持多种数据输入和输出格式,可以轻松集成到现有的监控系统中。
登录观测云控制台,在「集成」 - 「DataKit」选择对应安装方式,当前采用 Linux 主机部署 DataKit。
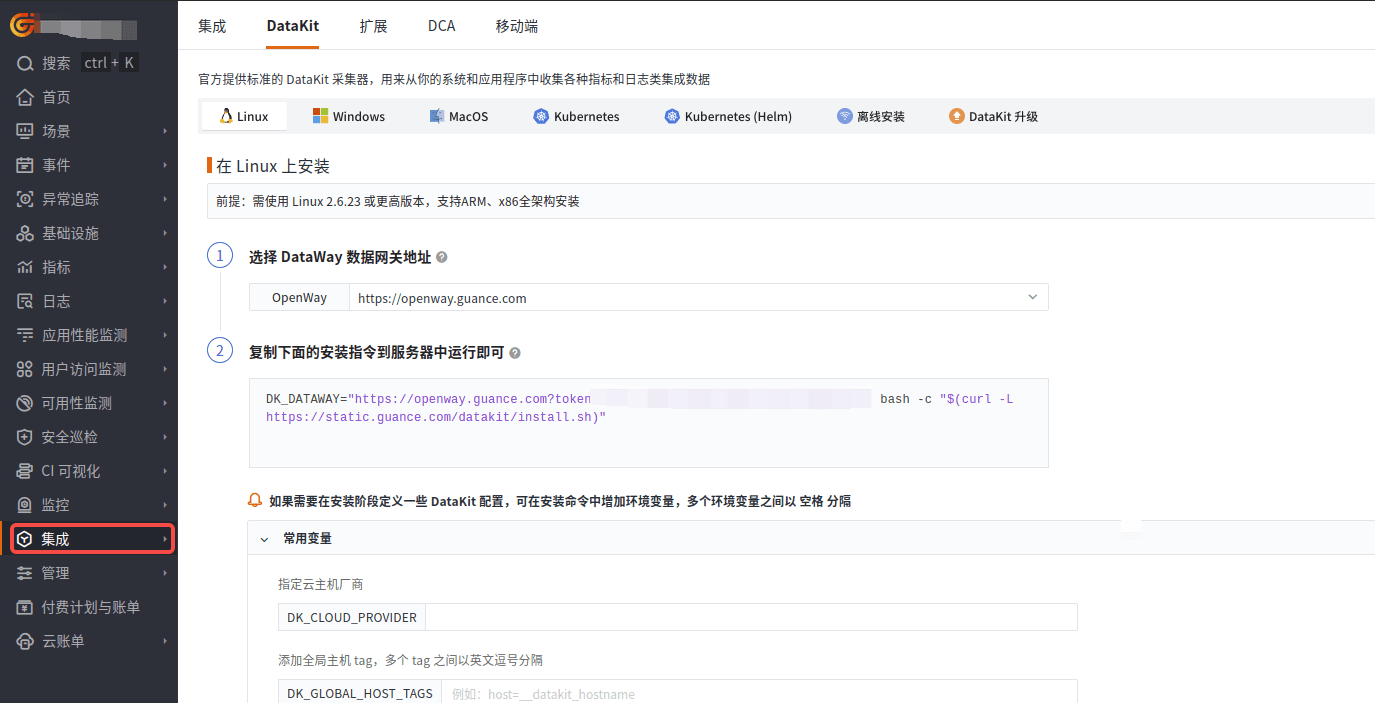
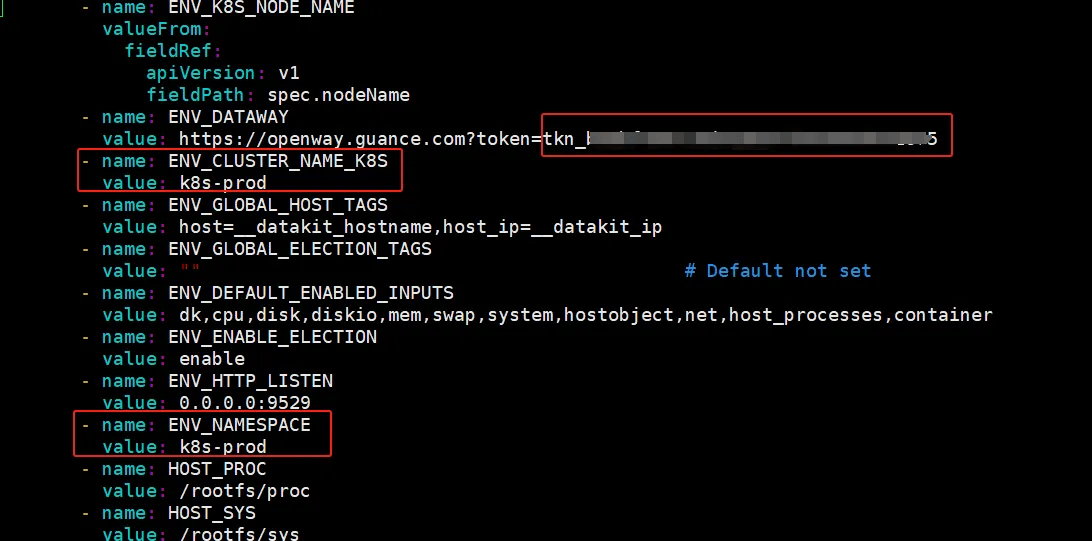
编辑 datakit.yaml ,把 token 粘贴到 ENV_DATAWAY 环境变量值中“token=”后面,设置环境变量 ENV_CLUSTER_NAME_K8S 的值并增加环境变量 ENV_NAMESPACE,这两个环境变量的值一般和集群名称对应,一个工作空间集群名称要唯一。
- name: ENV_NAMESPACEvalue: xxxx
把 datakit.yaml 上传到可以连接到 Kubernetes 集群的主机上,执行如下命令。
kubectl apply -f datakit.yaml
kubectl get pod -n datakit
采集器配置
KubernetesPrometheus 是 DataKit 的一个采集器,它根据自定义配置实现自动发现 Prometheus 服务并进行采集,极大简化了采集 Kubernetes 集群中 Kubelet 指标的复杂度。
通过在 DataKit 的 Comfigmap 中添加 kubernetesprometheus.conf 采集器,对 Kubelet 中 /metrics 以及 /metrics/cadvisor 指标接口进行采集。
apiVersion: v1
kind: ConfigMap
metadata:name: datakit-confnamespace: datakit
data:kubelet.conf: |-[inputs.kubernetesprometheus][[inputs.kubernetesprometheus.instances]]role = "node"selector = "kubernetes.io/os=linux"scrape = "true"scheme = "https"port = "__kubernetes_node_kubelet_endpoint_port"path = "/metrics"params = ""interval = "15s"[inputs.kubernetesprometheus.instances.custom]measurement = "kubelet"job_as_measurement = true[inputs.kubernetesprometheus.instances.custom.tags]instance = "__kubernetes_mate_instance"cluster_name_k8s = "default"job = "kubelet"[inputs.kubernetesprometheus.instances.auth]bearer_token_file = "/var/run/secrets/kubernetes.io/serviceaccount/token"[inputs.kubernetesprometheus.instances.auth.tls_config]insecure_skip_verify = truecert = "/var/run/secrets/kubernetes.io/serviceaccount/ca.crt"[[inputs.kubernetesprometheus.instances]]role = "node"selector = "kubernetes.io/os=linux"scrape = "true"scheme = "https"port = "__kubernetes_node_kubelet_endpoint_port"path = "/metrics/cadvisor"params = ""interval = "15s"[inputs.kubernetesprometheus.instances.custom]measurement = "cadvisor"job_as_measurement = true[inputs.kubernetesprometheus.instances.custom.tags]instance = "__kubernetes_mate_instance"cluster_name_k8s = "default"job = "kubelet"node = "__kubernetes_node_name"label_alpha_eksctl_io_nodegroup_name = "__kubernetes_node_label_alpha.eksctl.io/nodegroup-name"[inputs.kubernetesprometheus.instances.auth]bearer_token_file = "/var/run/secrets/kubernetes.io/serviceaccount/token"[inputs.kubernetesprometheus.instances.auth.tls_config]insecure_skip_verify = truecert = "/var/run/secrets/kubernetes.io/serviceaccount/ca.crt"
再把 kubelet.conf 挂载到 DataKit 的 /usr/local/datakit/conf.d/kubernetesprometheus/kubelet.conf 下面,最后重新部署 DataKit。
- mountPath: /usr/local/datakit/conf.d/kubernetesprometheus/kubelet.confname: datakit-confsubPath: kubelet.conf
关键指标
| Metrics | 描述 | 单位 |
|---|---|---|
kubelet_node_name | Kubelet 所在的节点 | count |
kubelet_running_pods | 当前节点正在运行的 Pod 数量 | count |
kubelet_running_containers | 当前节点上正在运行的容器数量 | count |
volume_manager_total_volumes | 当前节点上管理的卷总数 | count |
volume_manager_total_volumes | Kubelet 执行的容器运行时操作总数 | count |
kubelet_runtime_operations_total | Kubelet 执行的容器运行时操作失败的次数 | count |
kubelet_runtime_operations_errors_total | Kubelet 执行的容器运行时操作的持续时间分布 | s |
kubelet_runtime_operations_duration_seconds_bucket | Kubelet 启动 Pod 的总次数 | count |
kubelet_pod_start_duration_seconds_count | Kubelet 启动 Pod 的持续时间分布 | s |
kubelet_pod_start_duration_seconds_bucket | 存储操作的总次数 | count |
storage_operation_duration_seconds_count | 存储操作失败的总次数 | count |
storage_operation_errors_total | Kubelet 管理 cgroup 的操作总次数 | count |
kubelet_cgroup_manager_duration_seconds_count | Kubelet 管理 cgroup 的操作持续时间分布 | s |
kubelet_cgroup_manager_duration_seconds_bucket | Kubelet 的 Pod 生命周期事件生成器(PLEG)重新列出操作的总次数 | count |
kubelet_pleg_relist_duration_seconds_count | Kubelet 向 Kubernetes API Server 发送的 REST 请求总数 | count |
rest_client_requests_total | Kubelet 向 Kubernetes API Server 发送的 REST 请求的持续时间分布 | count |
rest_client_request_duration_seconds_bucket | Kubelet 进程占用的物理内存大小 | byte |
process_resident_memory_bytes | Kubelet 进程占用的 CPU 时间总和 | s |
process_cpu_seconds_total | Kubelet 进程占用的 CPU 时间总和 | s |
go_goroutines | Kubelet 进程中活跃的 Go 协程数量 | count |
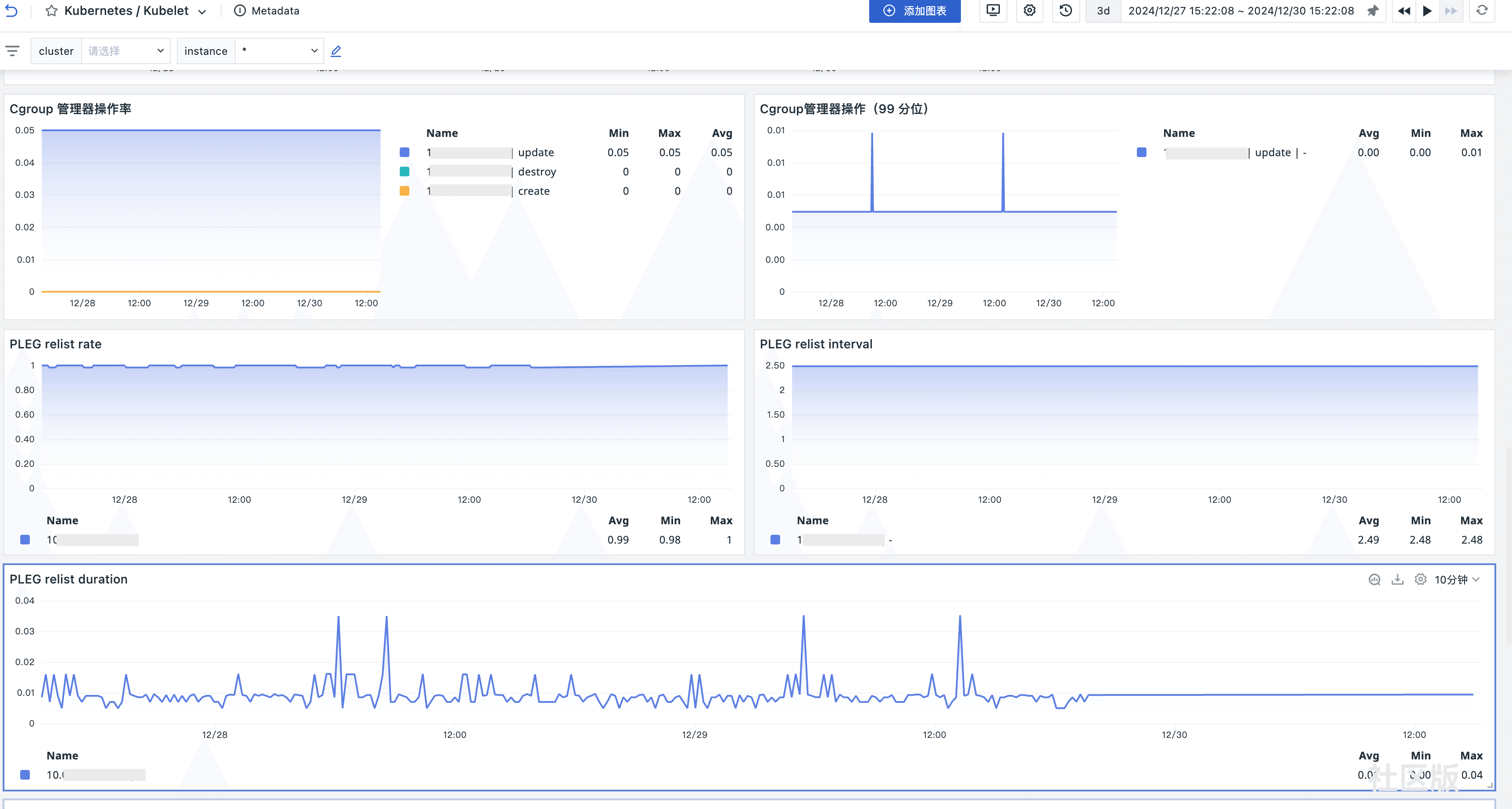
场景视图
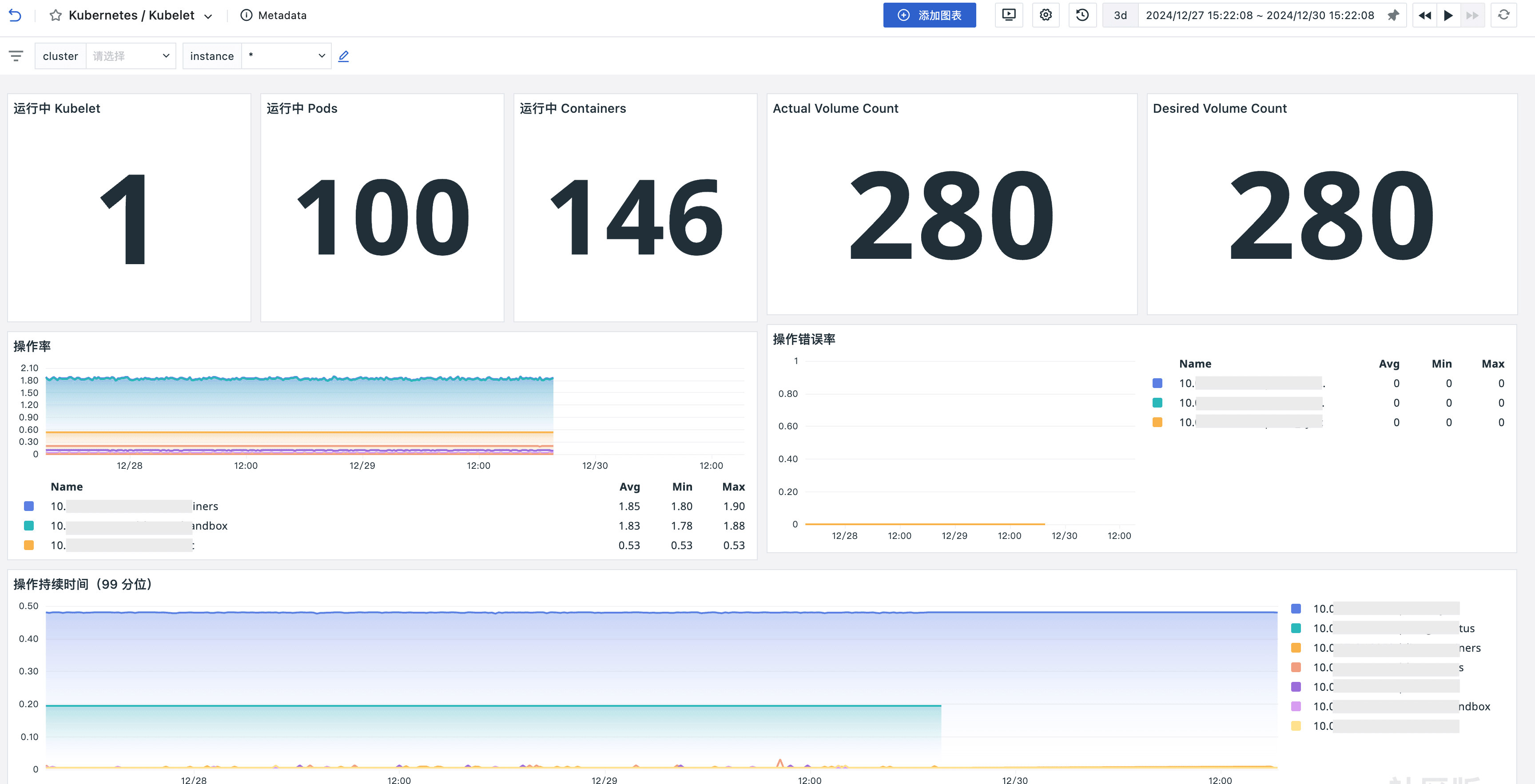
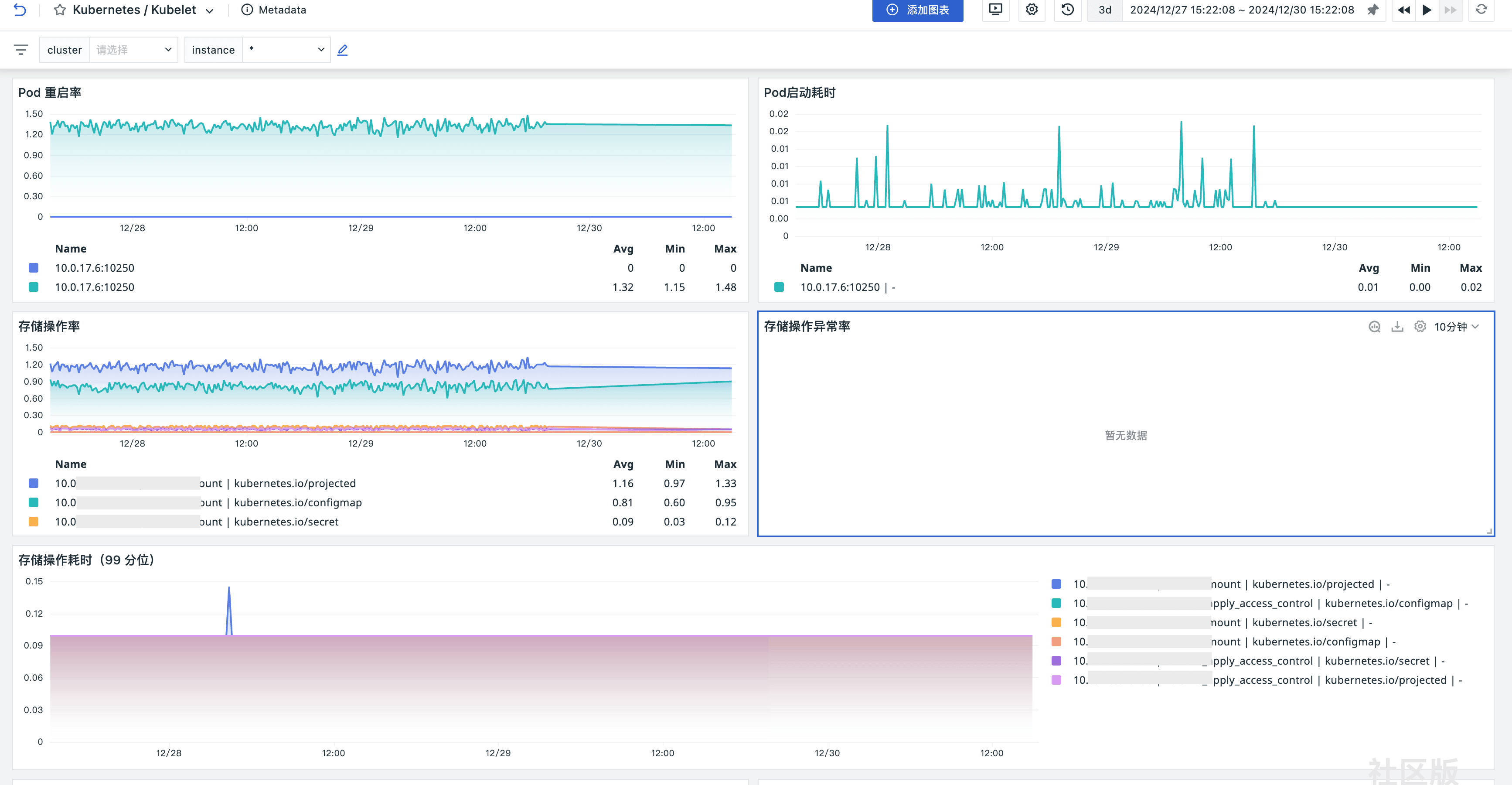
监控器(告警)
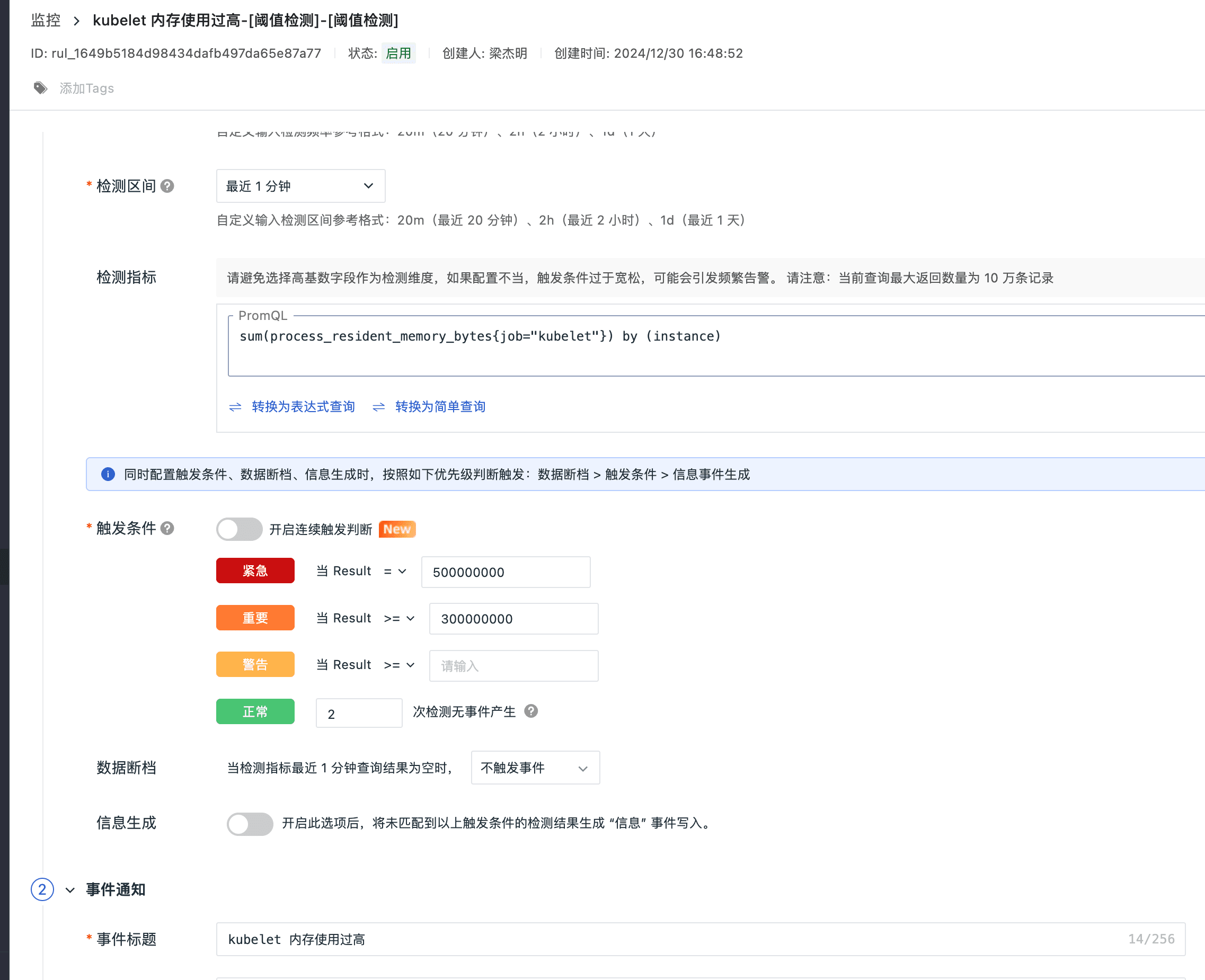
Kubelet 内存告警
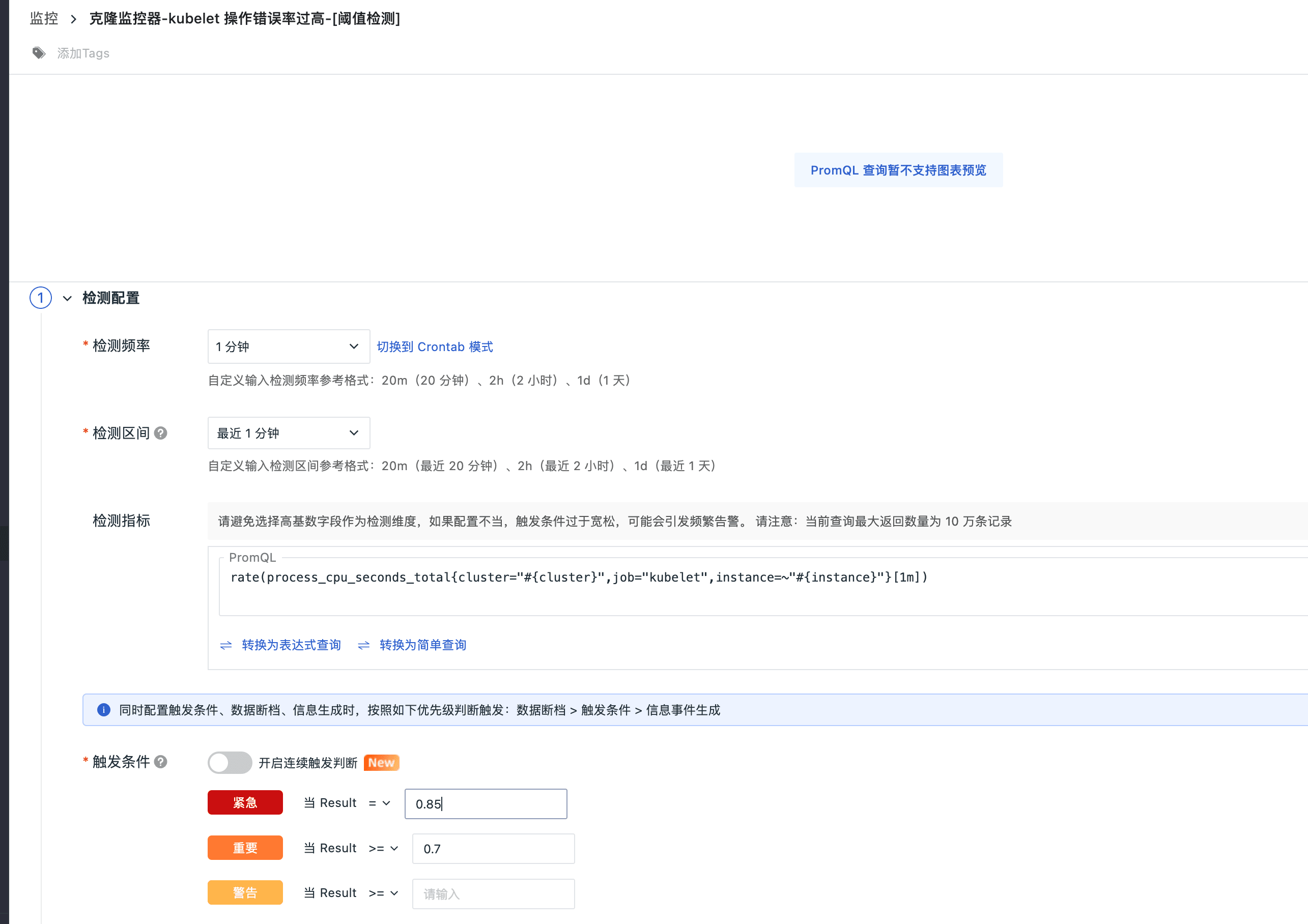
Kubelet CPU告警
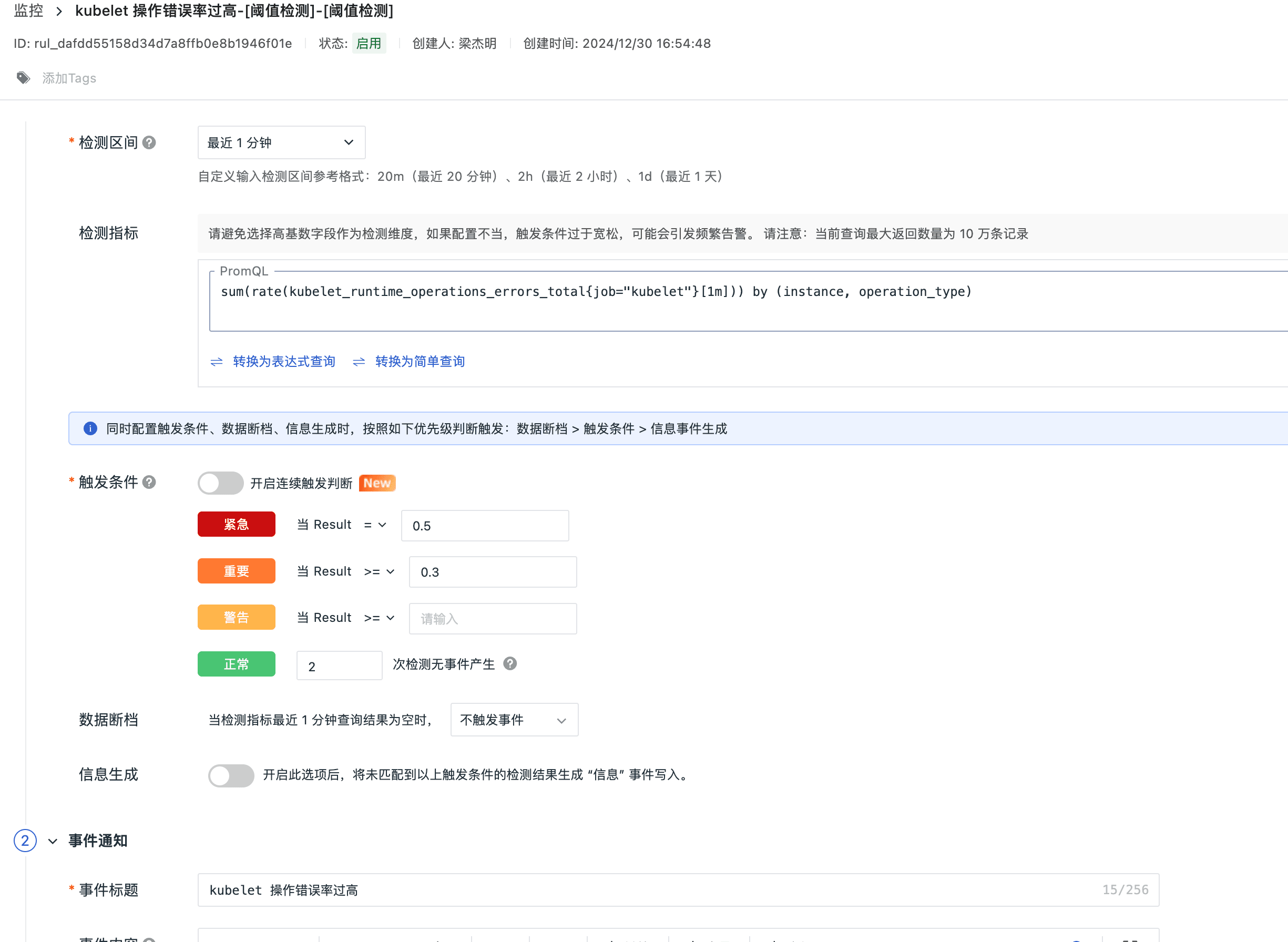
Kubelet 操作错误率过高告警
总结
Kubelet 是 Kubernetes 集群中负责维护容器生命周期的核心组件,其性能监控对于保障集群稳定性和效率至关重要。借助观测云,用户不仅能实时掌握 Kubelet 的运行状态,还能通过场景视图直观呈现监控数据,并设置监控器实现告警功能,从而有效管理 Kubelet 性能,提升 Kubernetes 集群的整体可靠性与性能。