rust编程学习(三):8大容器类型
1简介
rust标准库std::collections也提供了像C++ STL库中的容器,分为4种通用的容器,8种类型,如下表所示。
线性容器类型:
| 名称 | 简介 |
|---|---|
| Vec<T> | 内存空间连续,可变长度的数组,类似于C++中Vector<T>容器 |
| VecDeque<T> | 内存空间连续,可变长度的双端队列,类似于C++中Deque<T>容器 |
| LinkedList<T> | 内存空间不连续,双向链表,类似于C++中的list<T> |
key-value 键-值对存储
| 名称 | 简介 |
|---|---|
| HashMap<K,V> | 基于哈希表的无序键-值对,类似于C++ STL中unordered_map<K,V> |
| BTreeMap<K,V> | 基于B树的有序键-值对,类似于C++ STL中map<K,V>,不过map是基于红黑色的实现的 |
集合
| 名称 | 简介 |
|---|---|
| HashSet<T> | 基于哈希表实现的无序集合,类似于C++ STL中的set<T> |
| BTreeMap<T> | 基于B数的有序集合,类似于C++ STL中的unordered_set<T> |
优先队列
| 名称 | 简介 |
|---|---|
| BinaryHeap<T> | 基于二叉堆的优先队列,类似于C++ STL中的priority_queue<T> |
2. Vec使用方式
Vec是一种动态可变长数组(简称动态数组),即在运行时可增长或者缩短数组的长度。动态数组在内存中开辟了一段连续内存块用于存储元素,且只能存储相同类型的元素。新加入的元素每次都会被添加到动态数组的尾部。动态数组根据添加顺序将数据存储为元素序列。序列中每个元素都分配有唯一的索引,元素的索引从0开始计数。
下面例子给出常用的10种使用vec的方式,使用示例如下:
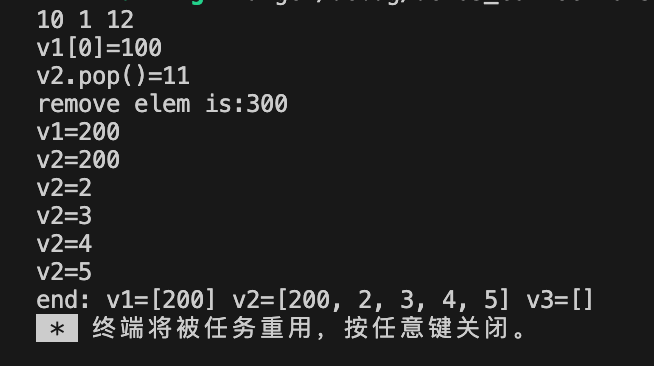
fn main() {//1.使用Vec::new()方式创建let mut v1:Vec<i32> = Vec::new(); // 2.使用vec!宏创建,创建动态数组的同时进行初始化let mut v2:Vec<i32> = vec![1,2,3,4,5];// 3.使用Vec::with_capacity函数创建指定容量的动态数组let mut v3:Vec<i32> = Vec::with_capacity(1024);//4.使用push方法向动态数组中添加元素v1.push(10);v2.push(11);v3.push(12);//5. 使用[]访问动态数组中的元素println!("{} {} {}", v1[0], v2[0], v3[0]);//5.1修改动态数组中的元素v1[0] = 100;v2[0] = 200;v3[0] = 300;//6.使用get方法访问动态数组中的元素//这种方式可以避免下标索引越界,get()返回的是Option枚举,所以使用match进行匹配解构match v1.get(0) {Some(v) => println!("v1[0]={}", v),None => println!("v1[0] is None"),};//7.使用pop()删除最后一个元素,并返回最后一个元素match v2.pop() {Some(val)=>println!("v2.pop()={}", val),None=>println!("v2 is empty"),} //8.使用remove()删除指定索引的元素,并返回被删除的元素let ret = v3.remove(0);println!("remove elem is:{}", ret);//9.使用iter_mut() 迭代器方法遍历并修改动态数组中的元素for i in v1.iter_mut() {*i += 100;println!("v1={}", i);}//10.使用iter() 迭代器方法遍历动态数组中的元素for i in v2.iter() { //这个方法是不能修改元素的println!("v2={}", i);}println!("end: v1={:?} v2={:?} v3={:?}", v1, v2, v3);
}输出内容:
3.VecDeque使用方式
双端队列是一种同时具有栈(先进后出)和队列(先进先出)特征的数据结构,适用于只能在队列两端进行添加或删除元素操作的应用场景。使用VecDeque结构体之前需要显式导入std::collections::VecDeque。
在步骤7中使用remove删除元素,我们这里使用了一种新的语法,if let进行匹配函数返回的枚举类型,它的作用和match类似,但是它只匹配其中某个枚举类型,在某些我们只关注某个枚举类型时候简化语法。使用示例如下:
use std::collections::VecDeque;
fn main() {//1. 使用VecDeque::new创建方式let mut vd1:VecDeque<u32> = VecDeque::new();//2.使用数组进行创建并初始化,10个元素,值为0let mut vd2:VecDeque<u32> = VecDeque::from([0;10]);//3.使用vec!进行初始化let mut vd3:VecDeque<u32> = VecDeque::from(vec![1,2,3,4,5]); //4.使用VecDeque::with_capacity创建指定容量的VecDequelet mut vd4:VecDeque<u32> = VecDeque::with_capacity(1024);//5.添加元素vd1.push_back(101); //从尾部添加元素vd1.push_front(102); //从头部添加元素//6.索引 修改元素vd2[0] = 100;match vd2.get(0){ //get(index)返回Option枚举,需要match解构Some(val) => println!("vd2[0]={}", val),None => println!("vd2[0] is None"),}//7.删除元素match vd3.pop_back(){ //从尾部删除元素 返回Option需要match解构Some(val) => println!("pop_back() elem={}", val),None => println!("vd3 is empty!!!"),}match vd3.pop_front() { //从头部删除元素 返回Option需要match解构Some(val) => println!("pop_front() elem={}", val),None => println!("vd3 is empty!!!"),}if let Some(val) = vd3.remove(2){ //remove(index)删除指定索引的元素println!("remove index 2 elem={}", val);//这里使用的if let语法,remove结果返回Option枚举,//如果枚举是Some(val),就进入if let块,如果枚举是None,就进入else块或不处理//if let语法和match语法的区别,match语法是匹配所有枚举类型,if let语法是匹配某一种枚举类型//if let语法可以用在返回值是枚举的函数中,简化代码编写}println!("vd1={:?} vd2={:?} vd3={:?} vd4={:?}", vd1, vd2, vd3, vd4);}输出内容:

4. LinkedList使用方式
链表(LinkedList) 是一种动态数据结构,由一系列节点组成,每个节点包含数据和指向下一个节点的指针(单链表)或指向前一个和下一个节点的指针(双链表)。
使用示例:
use std::collections::LinkedList;
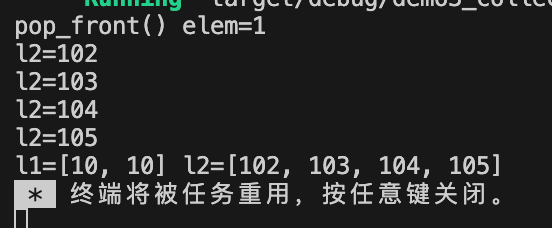
fn main() {//1.使用LinkedList::new创建方式let mut l1:LinkedList<u32> = LinkedList::new();//2.使用数组进行初始化let mut l2:LinkedList<u32> = LinkedList::from([1,2,3,4,5]);//3. 添加元素l1.push_front(10); //从头部添加元素l1.push_back(10); //从尾部添加元素//4.删除元素match l2.pop_front(){ //从头部删除元素Some(val) => println!("pop_front() elem={}", val),None => println!("l2 is empty!!!"),}//5.遍历 修改元素for i in l2.iter_mut() {*i += 100;println!("l2={}", i);}println!("l1={:?} l2={:?}", l1, l2);
}
输出信息:
5.HashMap使用方式
哈希表(HashMap)是基于哈希算法来存储键-值对的集合,其中所有的键必须是同一类型,所有的值也必须是同一类型,不允许有重复的键,但允许不同的键有相同的值。使用HashMap结构体之前需要显式导入std::collections::HashMap。
使用示例:
fn main() {//1.使用HashMap::new函数创建空的HashMaplet mut hm1:HashMap<&str, i32> = HashMap::new();//2.使用HashMap::from函数创建HashMap 使用数组进行初始化let mut hm2:HashMap<&str, i32> = HashMap::from([("a", 1), ("b", 2), ("c", 3)]);//3.使用HashMap::with_capacity函数创建指定容量的HashMaplet mut hm3:HashMap<&str, i32> = HashMap::with_capacity(1024);//4.添加元素、修改元素//使用insert方法在HashMap中插入或更新键-值对。//如果键不存在,执行插入操作并返回None。//如果键已存在,执行更新操作,将对应键的值更新并返回旧值。if let None = hm1.insert("h1", 1){ //如果返回None,说明插入成功println!("new insert val 1");}if let Some(old) = hm1.insert("h1", 11){ //如果返回旧值,说明更新成功println!("insert old val:{}", old);}//5.使用entry和or_insert方法检查键是否有对应值,//没有对应值就插入键-值对,已有对应值则不执行任何操作。hm3.entry("zhangsan").or_insert(32);hm3.entry("lisi").or_insert(42);hm3.entry("wangwu").or_insert(42);//6.使用iter()方法遍历HashMapfor (key, value) in hm2.iter_mut() {println!("key={}, value={}", key, value);*value += 100;}//7.使用remove方法删除并返回指定的键-值对,如果不存在就返回Noneif let Some(v) = hm3.remove("wangwu"){println!("remove key=wangwu, value={}", v);}//8.使用get方法获取指定键对应的值,如果不存在就返回Noneif let Some(v) = hm3.get("lisi"){println!("get key=lisi, value={}", v);}//9.使用contains_key方法检查HashMap中是否存在指定的键,返回布尔值println!("hm3 contains key=lisi:{}", hm3.contains_key("lisi"));//10.使用【】进行索引xuanprintln!("hm3={}", hm3["zhangsan"]);println!("hm1:{:?} hm2:{:?} hm3:{:?}", hm1, hm2, hm3);}输出结果:
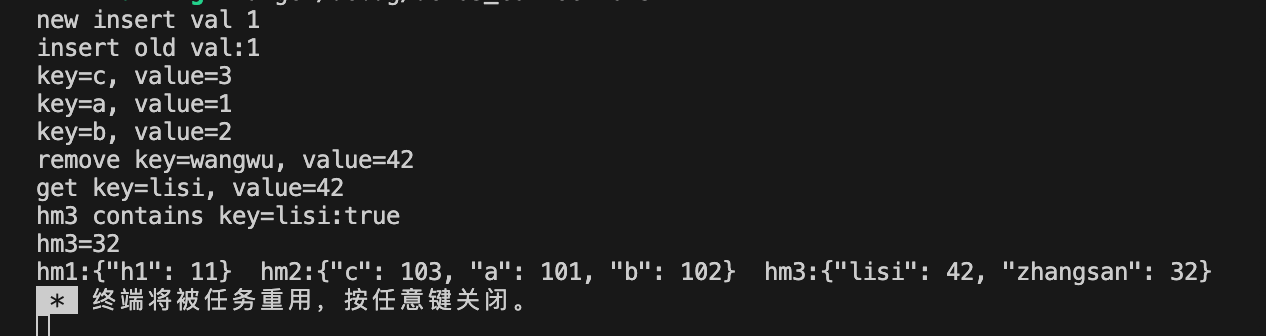
6.BTreeMap使用方法
-
使用BTreeMap存储的KV键值对,Key存储是有序的,除了像HashMap一样插入、删除、修改外,还支持range遍历,即范围遍历查找。
-
这是因为BTreeMap基于B树实现的,底层数据结构是一个自平衡的b树,确保有效的插入、删除和查找,键按排序顺序存储和访问,支持高效的范围查询和有序迭代。
-
使用示例:
use std::collections::BTreeMap;
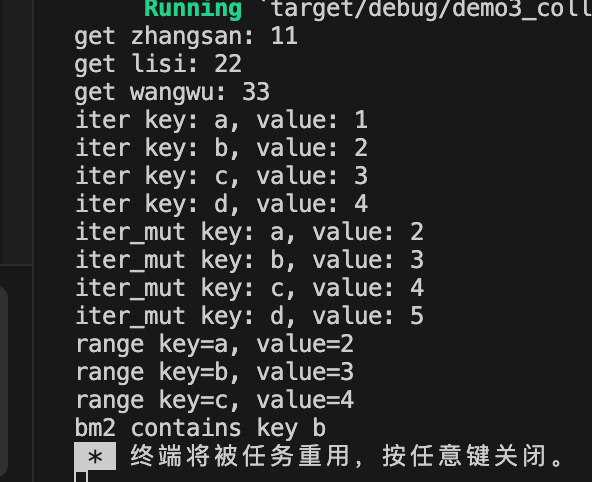
fn main() {//1.使用BTreeMap::new函数创建空的BTreeMaplet mut bm1:BTreeMap<&str, i32> = BTreeMap::new();//2.使用BTreeMap::from函数创建BTreeMap 使用数组进行初始化let mut bm2:BTreeMap<&str, i32> = BTreeMap::from([("a", 1), ("d", 4),("b", 2), ("c", 3)]);//3.插入元素bm1.insert("zhangsan", 11);bm1.insert("lisi", 22);bm1.insert("wangwu", 33);//4.获取元素println!("get zhangsan: {}", bm1.get("zhangsan").unwrap());println!("get lisi: {}", bm1.get("lisi").unwrap());println!("get wangwu: {}", bm1["wangwu"]);//5.遍历元素//5.1 迭代器遍历for (key, value) in bm2.iter() {println!("iter key: {}, value: {}", key, value);}//5.2 迭代器可变引用遍历for (key, val) in bm2.iter_mut() {*val += 1;println!("iter_mut key: {}, value: {}", key, val);}//5.3 迭代器范围遍历 遍历key的范围["a" 到 “c”]for (key, value) in bm2.range("a"..="c") {println!("range key={}, value={}", key, value);}//6.删除元素bm2.remove("a");//7.检查键是否存在if bm2.contains_key("b") {println!("bm2 contains key b");}else{println!("bm2 not contains key b");}
}
输出信息:
7.HashSet使用方法
HashSet是基于HashMap实现的,即Key和Value的值都是一样的(实际上在Rust实现没有为Value分配空间),HashSet是一个集合,存放一组同一类型的数据,可以实现并集、交集、差集操作。
使用例子:
use std::collections::HashSet;
fn main() {//1.使用HashSet::new()创建一个空的HashSetlet mut s1:HashSet<i32> = HashSet::new();//2.使用HashSet::from()创建一个HashSet,使用数组进行初始化let mut s2:HashSet<i32> = HashSet::from([1,2,3,4,5]);//3.使用 vec! 宏和 into_iter 创建集合let mut s3:HashSet<i32> = vec![2,3,4,9,8,7,6,5].into_iter().collect();//4.使用HashSet::insert()插入数据s1.insert(4);s1.insert(6);s1.insert(7);//5.使用HashSet::remove()删除数据s2.remove(&5);//&代表 引用//6.使用take()方法获取并删除集合中的第一个元素if let Some(v) = s3.take(&9){println!("take 9:{}", v);}//7.使用HashSet::contains()检查集合中是否包含某个元素if s3.contains(&6) {println!("s3 contains 6");}//8.遍历元素for val in s1.iter() {println!("s1:{}", val);}// let v:Vec<i32> = s1.into_iter().collect();//9.集合操作//9.1 并集let ss1: HashSet<i32> = s1.union(&s2).cloned().collect();println!("s1={:?} s2={:?} s1与s2并集={:?}", s1, s2, ss1);//9.2 交集let ss2:HashSet<i32> = s2.intersection(&s3).cloned().collect();println!("s2={:?} s3={:?} s1与s2交集={:?}", s2, s3, ss2);//9.3 差集let ss3:HashSet<i32> = s3.difference(&s1).cloned().collect();println!("s3={:?} s1={:?} s3与s1差集={:?}", s3, s1, ss3);}输出信息:
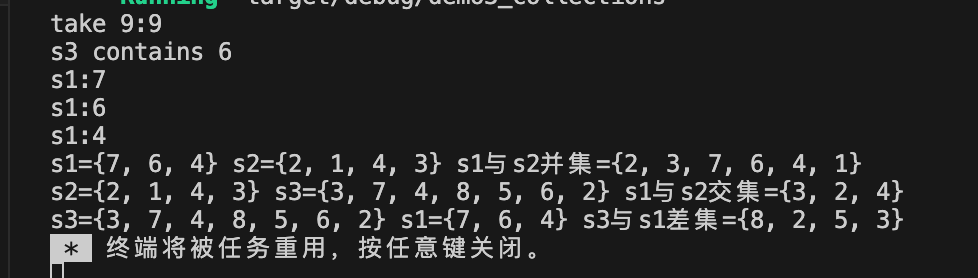
8.BTreeSet使用方法
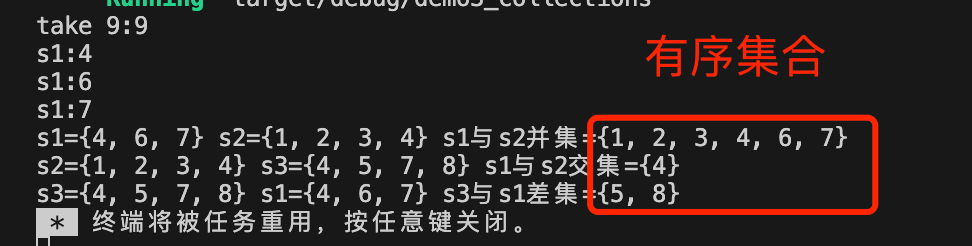
BTreeSet是基于BTreeMap实现的,即Key和Value的值都是一样的(实际上在Rust实现没有为Value分配空间),BTreeSet是一个集合,存放一组同一类型的数据,可以实现并集、交集、差集操作。与HashSet不同的是BTreeSet是有序集合,大家可以观察示例输出的信息验证。
使用示例:
use std::collections::BTreeSet;
fn main() {//1.使用BTreeSet::new()创建一个空的BTreeSetlet mut s1:BTreeSet<i32> = BTreeSet::new();//2.使用BTreeSet::from()创建一个BTreeSet,使用数组进行初始化let mut s2:BTreeSet<i32> = BTreeSet::from([1,2,3,4,5]);//3.使用 vec! 宏和 into_iter 创建集合let mut s3:BTreeSet<i32> = vec![8,5,4,9,8,7].into_iter().collect();//4.使用BTreeSet::insert()插入数据s1.insert(4);s1.insert(6);s1.insert(7);//5.使用BTreeSet::remove()删除数据s2.remove(&5);//&代表 引用//6.使用take()方法获取并删除集合中的第一个元素if let Some(v) = s3.take(&9){println!("take 9:{}", v);}//7.使用HashSet::contains()检查集合中是否包含某个元素if s3.contains(&6) {println!("s3 contains 6");}//8.遍历元素for val in s1.iter() {println!("s1:{}", val);}// let v:Vec<i32> = s1.into_iter().collect();//9.集合操作//9.1 并集let ss1: BTreeSet<i32> = s1.union(&s2).cloned().collect();println!("s1={:?} s2={:?} s1与s2并集={:?}", s1, s2, ss1);//9.2 交集let ss2:BTreeSet<i32> = s2.intersection(&s3).cloned().collect();println!("s2={:?} s3={:?} s1与s2交集={:?}", s2, s3, ss2);//9.3 差集let ss3:BTreeSet<i32> = s3.difference(&s1).cloned().collect();println!("s3={:?} s1={:?} s3与s1差集={:?}", s3, s1, ss3);}输出信息:
9.BinaryHeap使用方法
BinaryHeap 是 Rust 标准库中的一个数据结构,它实现了二叉堆(Binary Heap),默认是一个最大堆(Max-Heap)。二叉堆是一种特殊的完全二叉树,其中每个父节点的值都大于或等于其子节点的值(最大堆),或者每个父节点的值都小于或等于其子节点的值(最小堆)。
使用示例:
use std::collections::BinaryHeap;
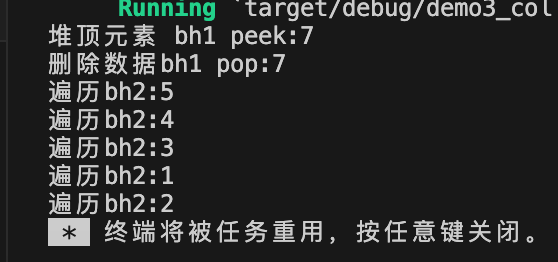
fn main() {//1.使用BinaryHeap::new()创建一个空的BinaryHeaplet mut bh1:BinaryHeap<i32, > = BinaryHeap::new();//2.使用BinaryHeap::from()创建,使用数组进行初始化let mut bh2:BinaryHeap<i32> = BinaryHeap::from([1,2,3,4,5]);//3.使用BinaryHeap::push()插入数据bh1.push(4);bh1.push(7);bh1.push(6);bh1.push(3);//4.使用BinaryHeap::peek()获取堆顶元素,但不删除if let Some(v) = bh1.peek() {println!("堆顶元素 bh1 peek:{}", v);}//5.使用BinaryHeap::pop()删除数据if let Some(v) = bh1.pop() {println!("删除数据bh1 pop:{}", v);}//6.遍历元素for val in bh2.iter() {println!("遍历bh2:{}", val);}
}
输出信息:
10.小结
本篇以示例的方式展示Rust中容器数据结构的使用方式,便于快速的了解基本容器的使用方式。
我是小C,欢迎大家一起学习交流~~~