图聚类中的亲和力传播
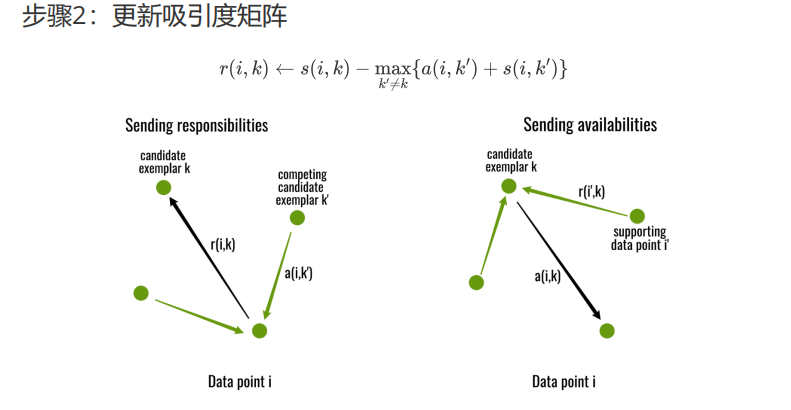
图中展示的是Affinity Propagation(亲和力传播)算法中的一个关键步骤——更新吸引度矩阵。Affinity Propagation是一种聚类算法,它通过消息传递的方式找到数据集中的代表性样本(称为exemplar或原型),并将其他数据点分配给这些原型,从而实现聚类。
### 1. **吸引度矩阵(Responsibility Matrix)与可用性矩阵(Availability Matrix)**
在Affinity Propagation算法中,有两个重要的矩阵:
- **吸引度矩阵 \( r(i, k) \)**:表示数据点 \( i \) 选择数据点 \( k \) 作为其原型的合适程度。
- **可用性矩阵 \( a(i, k) \)**:表示数据点 \( k \) 作为数据点 \( i \) 的原型的合适程度。
### 2. **更新吸引度矩阵的公式**
\[ r(i, k) \leftarrow s(i, k) - \max_{k' \neq k} \{a(i, k') + s(i, k')\} \]
其中:
- \( s(i, k) \) 是相似度矩阵中的元素,表示数据点 \( i \) 和数据点 \( k \) 之间的相似度。
- \( a(i, k') \) 和 \( s(i, k') \) 分别是数据点 \( i \) 对于其他候选原型 \( k' \) 的可用性和相似度。
这个公式的目的是计算数据点 \( i \) 选择数据点 \( k \) 作为其原型的“净吸引力”。具体来说,它考虑了数据点 \( i \) 与数据点 \( k \) 的直接相似度 \( s(i, k) \),并减去数据点 \( i \) 对于其他候选原型的最大吸引力。
### 3. **图示解释**
#### 左图:发送责任(Sending responsibilities)
- **Data point i**:当前考虑的数据点。
- **Candidate exemplar k**:候选原型 \( k \)。
- **Competing candidate exemplar k'**:与其他候选原型 \( k' \) 竞争成为数据点 \( i \) 的原型。
- **r(i, k)**:数据点 \( i \) 选择候选原型 \( k \) 的责任(净吸引力)。
- **a(i, k)**:数据点 \( k \) 作为数据点 \( i \) 原型的可用性。
左图展示了数据点 \( i \) 在选择候选原型 \( k \) 时,需要考虑 \( k \) 与其他候选原型 \( k' \) 的竞争关系。\( r(i, k) \) 表示在排除其他候选原型的影响后,数据点 \( i \) 选择 \( k \) 的净吸引力。
#### 右图:发送可用性(Sending availabilities)
- **Candidate exemplar k**:候选原型 \( k \)。
- **Supporting data point i'**:支持数据点 \( i' \),即认为 \( k \) 是一个好原型的数据点。
- **r(i', k)**:支持数据点 \( i' \) 选择候选原型 \( k \) 的责任。
- **a(i, k)**:数据点 \( k \) 作为数据点 \( i \) 原型的可用性。
右图展示了候选原型 \( k \) 在被数据点 \( i \) 考虑为原型时,需要考虑其他支持数据点 \( i' \) 的意见。\( a(i, k) \) 表示在综合其他支持数据点的意见后,数据点 \( k \) 作为数据点 \( i \) 原型的合适程度。
### 4. **总结**
Affinity Propagation算法通过迭代更新吸引度矩阵和可用性矩阵,逐步确定每个数据点的最佳原型,从而实现聚类。图中展示的步骤是算法的核心部分,通过计算和传递责任与可用性信息,使得算法能够自动发现数据集中的代表性样本,并将其他数据点合理地分配到不同的簇中。