【复盘】cpu飙升引发的连锁反应
背景分析
负责主要就是后端实例,以及通过负载均衡调用后续的python实例。
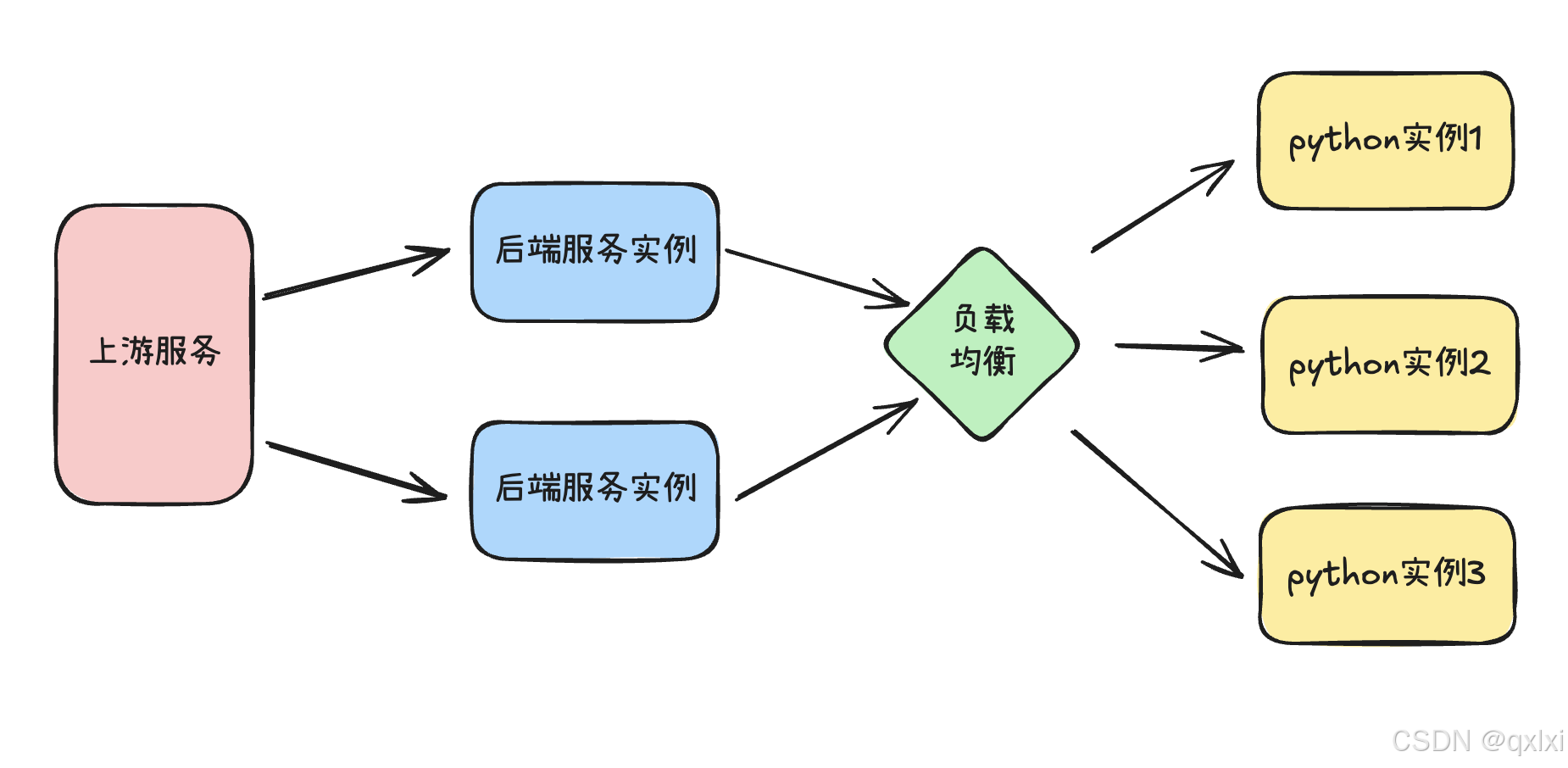
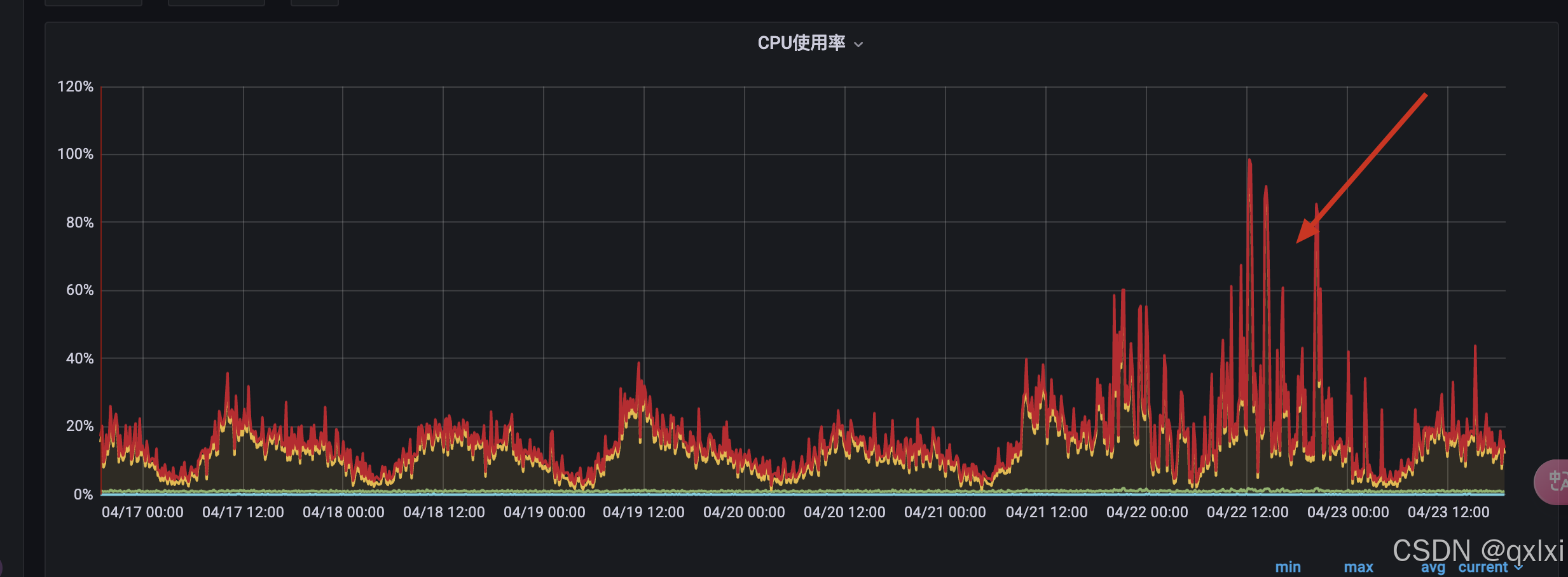
在21日下午5点左右 发现其中一台机器报警出现CPU过高,于是立马进行针对不用的服务进行暂停。
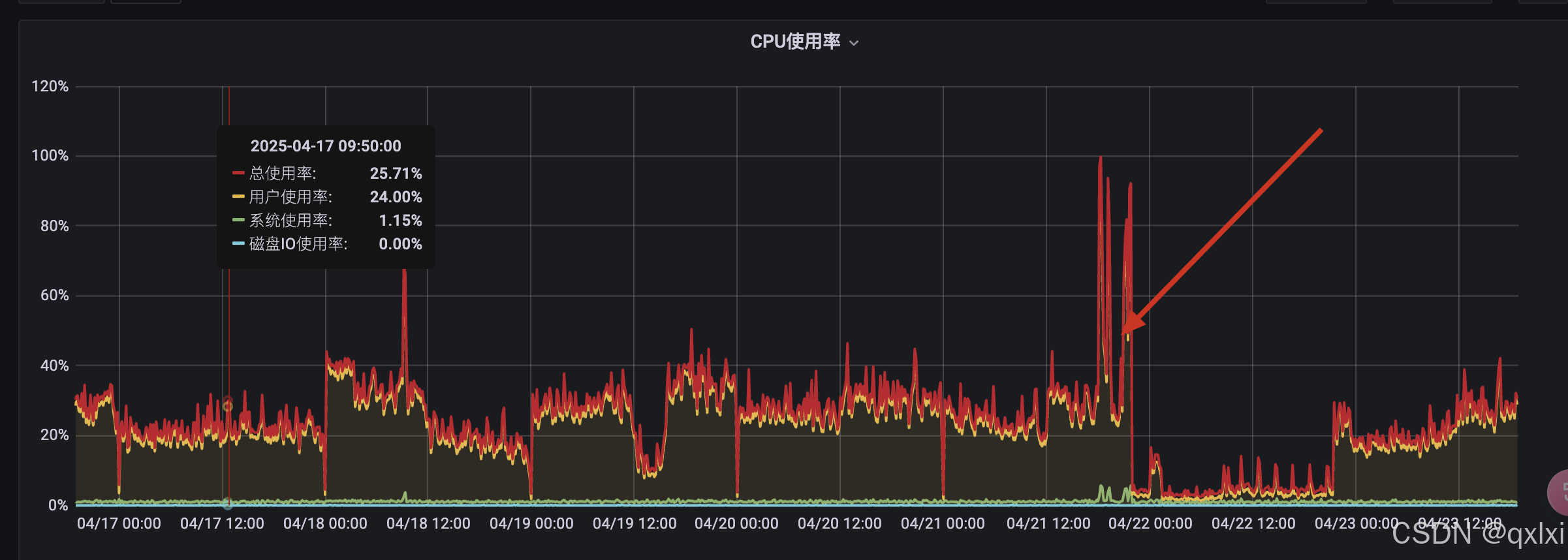
但是仅接着就出现大量的python服务实例请求超时 504 gateWayTimeOut
原因分析
于是分析 python服务的请求总数,发现并没有增加。于是就分析可能传递给python的参数过大导致的,都是一些请求三方的报文数据。
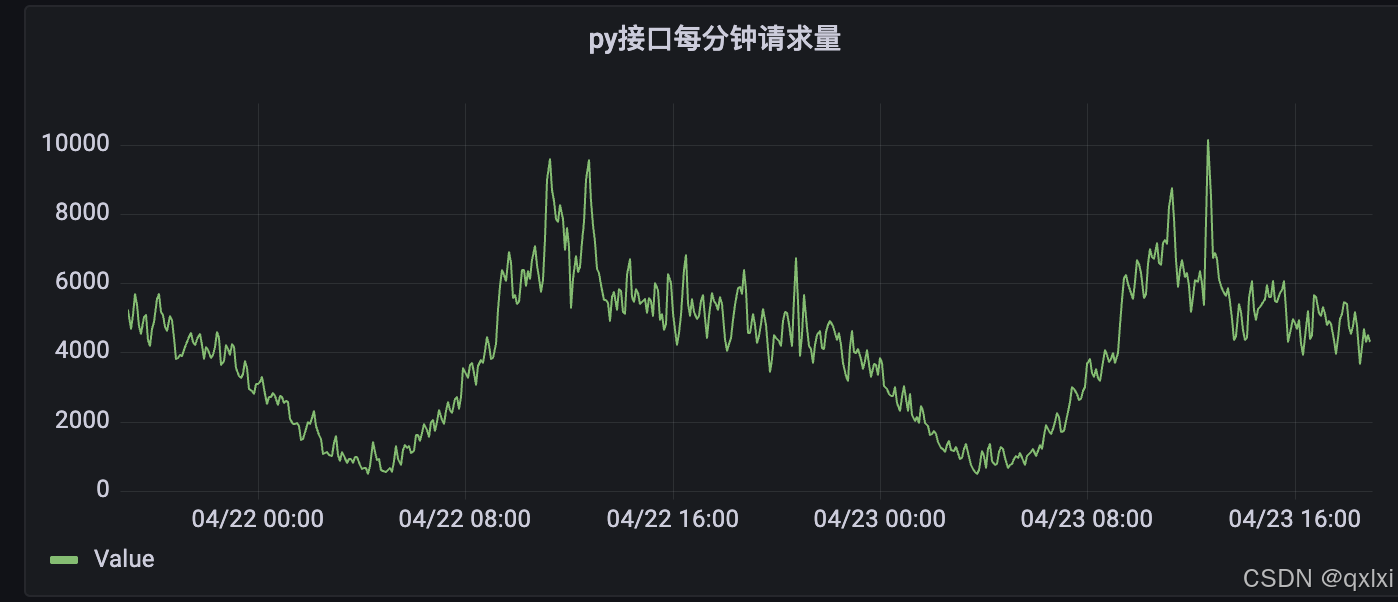
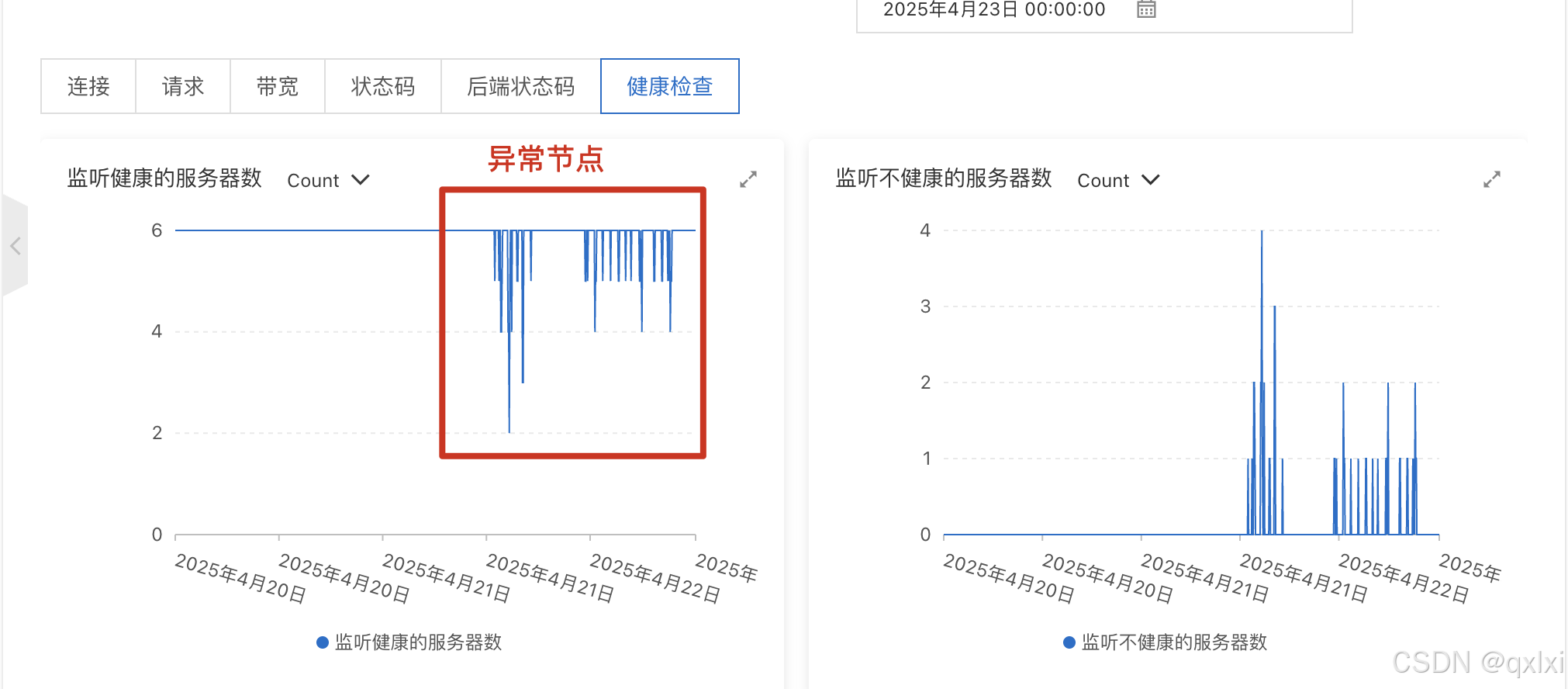
紧接着有高峰的都是不断的有报警的时间段,发现分析基本都是每个2个小时就有高峰期,于是分析可能是定时重试机制大批量失败的用户进而重试引发的 python服务实例cpu飙升,导致新建检测失败。
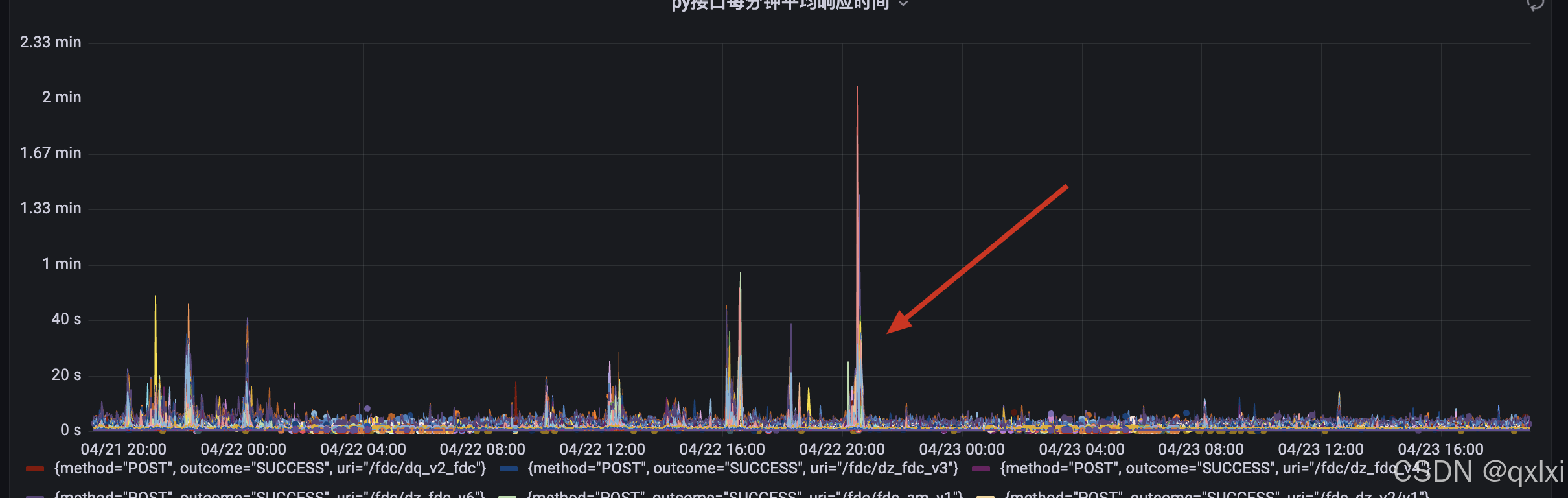
从图中可以看到一个简单的健康检查接口 耗时了6S左右。(其他业务接口基本都是100多秒) 导致整体服务处于僵死状态。 等服务恢复后 就正常处理健康检查。

对应就是服务cpu飙升。
解决方案
1.重启相关服务 发现还是没有解决
2.调整python服务进程数,发现由于cpu飙升至100% 由于按照几核的CPU 部署%70的进程数。才比较合理
3.针对大报文进行不处理
后续就是针对python服务进行新增实例数。提升整体的处理能力,以及相关团队优化python代码。
复盘
本次属于连锁反应,a服务实例cpu飙升 影响 整体python服务,进而影响整体上游服务。
所以当出现问题需要冷静分析具体原因
1.监控对应的cpu 磁盘 内存 网络是否异常
2.请求数据是否增加 外部原因等