ElasticSearch深入解析(二):核心概念
文章目录
- 一、倒排索引和全文检索
- 1. 倒排索引
- 2. 全文检索
- 二、ElasticSearch的核心概念
- 1. 集群
- 2. 节点
- 3. 索引
- 4. 分片
- 5. 副本
- 6. 文档
- 7. 字段
- 8. 映射
- 9. 分词
一、倒排索引和全文检索
1. 倒排索引
倒排索引是ElasticSearch核心的数据结构,为高效的全文搜索提供了强大支持。
- 主要由两部分组成:
- 单词词典,即每个文档进行分词后的词项在去重后组成的集合;
- 排列表记录了词项所在文档的文档列表、单词频率等信息。
倒排文件是倒排列表持久化存储的结果,通常保存在磁盘等存储设备上。
以下是倒排索引结构的说明:

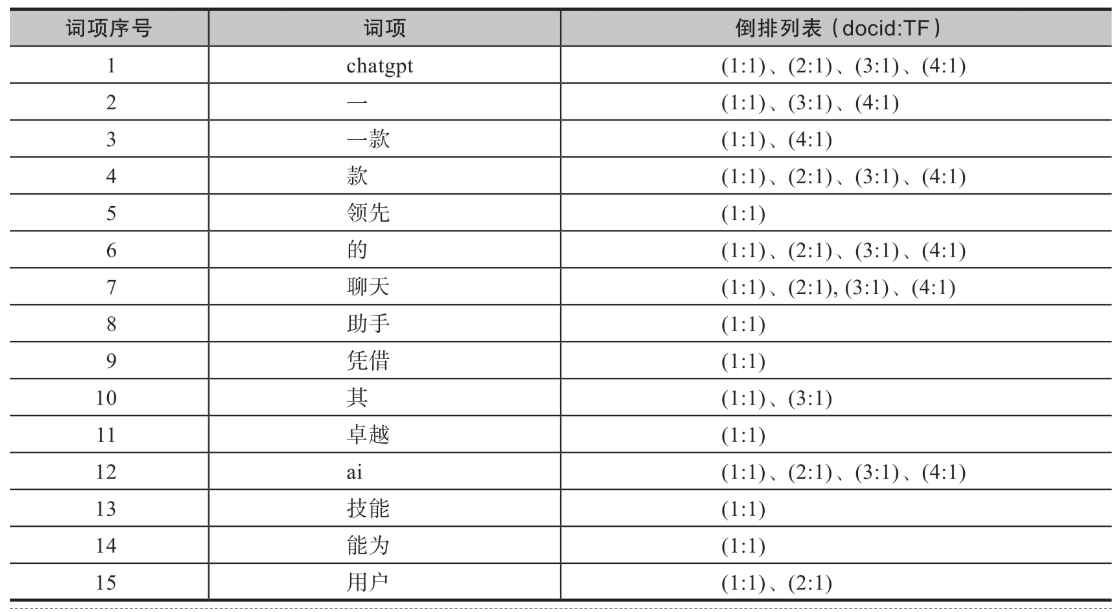
docid代表文档ID,TF代表词频。以词项“chatgpt”为例,其对应的倒排索引(1:1)中前面的1代表文档ID,说明文档1中包含“chatgpt”词项;后面的1代表词频,说明“chatgpt”词项在文档1里出现了1次。实际的倒排列表存储的信息要比表2-2复杂,还会包括词项在文档中出现的位置等信息,以方便实现复杂检索。
有了倒排列表,当检索“chatgpt”时,就无须对逐个文档进行扫描,而可以借助倒排索引锁定ID为1、2、3、4的文档,实现以O(1)的时间复杂度快速召回数据,达到快速响应的目的。
2. 全文检索
全文检索的前提是待检索的数据已经索引化,当用户查询时能根据建立的倒排索引进行查找。衡量全文检索系统的关键指标是全面、准确和快速。
ElasticSearch的全文检索的特点如下:
- 只处理文本,不处理语义;
- 结果列表有相关度排序;
- 支持高亮显示结果数据;
- 原始的文本被切分为单个单词、短语或特殊标记后进行存储;
- 给定词与它的变体(如近义词)会被折叠为一个词,如electrification和ectric、mice和mouse、“土豆”和“马铃薯”、“西红柿”和“番茄”等,每组词均被视为同一个词。(需要提前配置)
二、ElasticSearch的核心概念
1. 集群
集群是一组Elasticsearch节点的集合。节点根据用途不同会划分出不同的角色,且节点之间相互通信。Elasticsearch集群常用于处理大规模数据集,目的是实现容错和高可用。Elasticsearch集群需要一个唯一标识的集群名称来防止不必要的节点加入。
集群大小从单个节点到数千个节点不等,具体大小取决于实际业务场景。
2. 节点
节点是指一个Elasticsearch实例,更确切地说,它是一个Elasticsearch进程。节点可以部署到物理机或者虚拟机上。每当Elasticsearch启动时,节点就会开始运行。每个节点都有唯一标识的名称,在部署多节点集群环境的时候我们要注意不要写错节点名称。
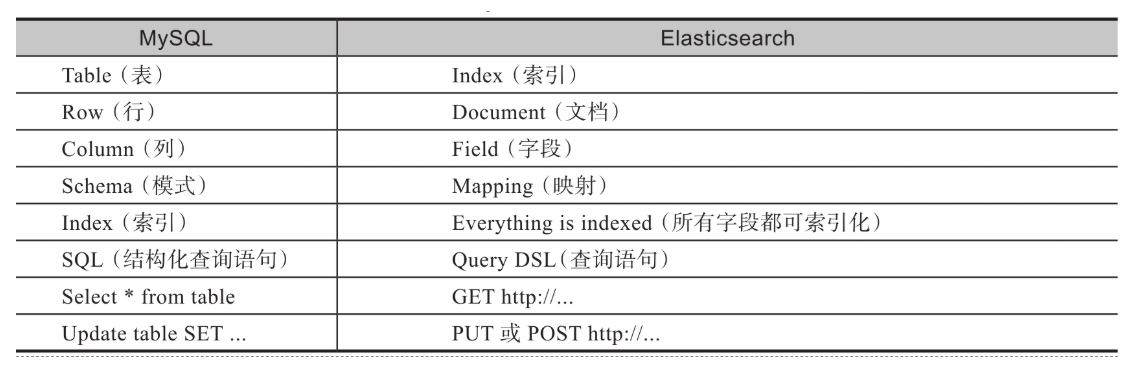
3. 索引
索引是Elasticsearch中用于存储和管理相关数据的逻辑容器。索引可以看作数据库中的一个表,它包含了一组具有相似结构的文档。在Elasticsearch中,数据以JSON格式的文档存储在索引内。每个索引具有唯一的名称,以便在执行搜索、更新和删除操作时进行引用。索引的名称可以由用户自定义,但必须全部小写。
总之,索引是Elasticsearch中用于组织、存储和检索数据的一个核心概念。通过将数据划分为不同的索引,用户可以更有效地管理和查询相关数据。
4. 分片
在理解分片的概念之前,我们需要先明确引入分片的核心原因。假设存在一个包含海量文档的索引,其数据总量达到1TB,而当前集群仅有两个节点,每个节点的可用数据存储空间为512GB。显然,单个节点的硬件存储上限无法容纳整个索引,此时必须通过某种机制对索引数据进行拆分,否则将导致数据无法完整存储。分片机制正是为解决这类问题而设计——它通过将原始索引拆解为多个更小的子集,使每个子集能够适配单节点的存储限制。
-
分片的本质与特性:
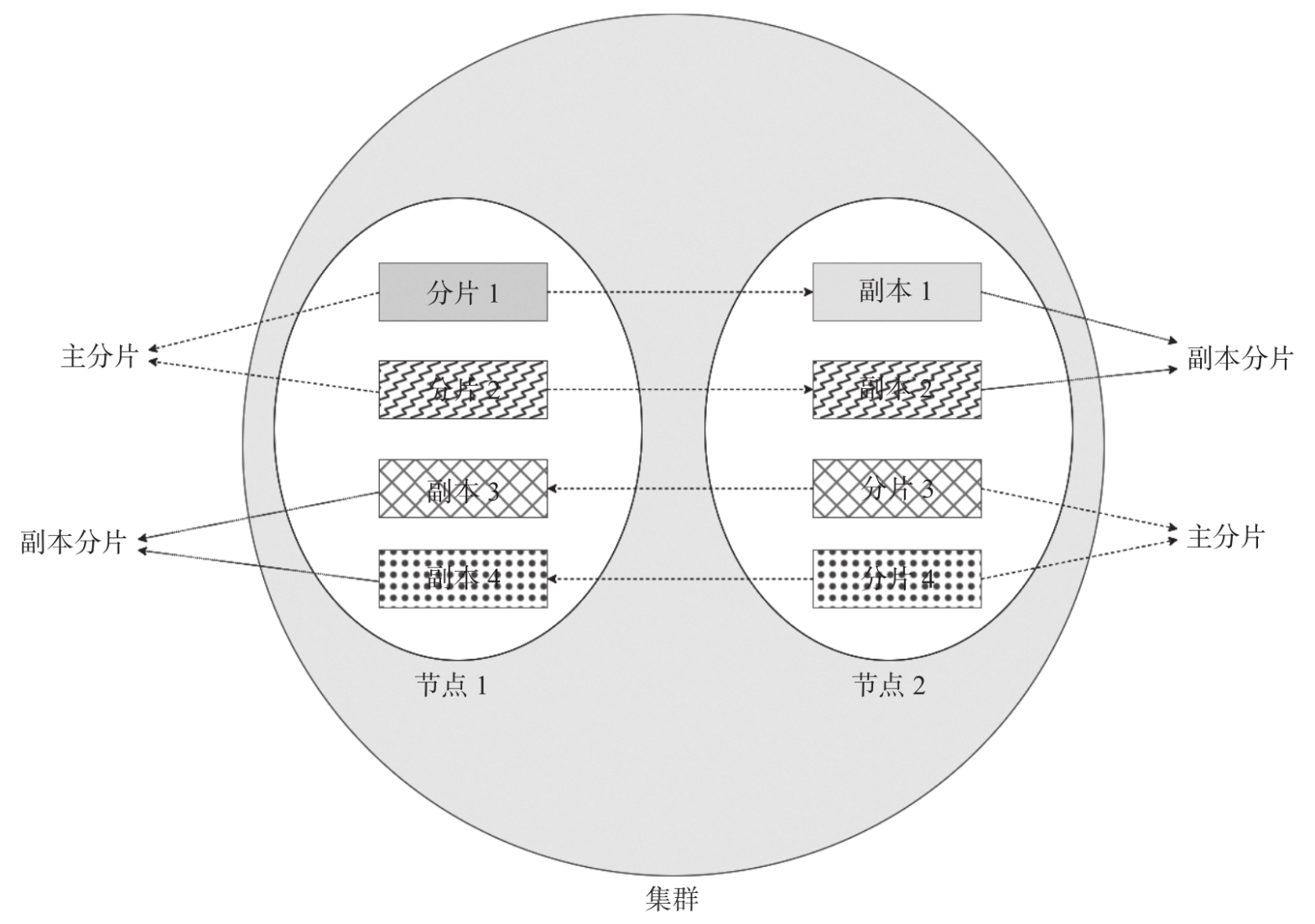
- 逻辑独立的子索引:每个分片本质上是一个完整且独立的Lucene索引,包含原始索引数据的一个子集。即使在单节点集群中,被分片的索引内任意文档也仅存储于某一个分片中(例如上图中的分片1~4、副本1~4)。
- 功能完整性:每个分片可独立执行数据存储、检索等操作,如同一个“微型索引”。
-
分片的工作机制:
当处理涉及多个分片的查询时,Elasticsearch会自动完成以下流程:- 请求分发:将查询请求并行路由至所有相关分片;
- 结果聚合:收集各分片的查询结果,合并后返回给用户。
对于应用程序而言,这一过程完全透明——开发者无需感知底层分片的分布逻辑或处理复杂度,只需关注业务层面的数据处理与用户交互。这种设计极大降低了使用门槛,使Elasticsearch既能支撑海量数据存储,又保持了接口的简洁性。
5. 副本
生产环境下,硬件随时可能发生故障。为了保证集群的容错性和高可用性、提高查询的吞吐率,Elasticsearch提供了复制数据的特性。分片可以被复制,被复制的分片称为“主分片”,如上图中的主分片1~4;主分片的复制版本称为“副本分片”或简称为“副本”,如上图中的副本1~4。创建索引时需要指定主分片,且主分片数一经指定就不支持动态更新了。而副本同样需要在创建索引时指定,每个分片可以有0或多个副本,副本数支持动态更新。当某主分片所在的数据节点不可用时,会导致主分片丢失现象,若短时间内不对此采取补救措施,集群会将该分片对应的副本提升为新的主分片。
注意:Elasticsearch 7.X版本之后,默认主分片数为1,副本分片数为1。
6. 文档
关系型数据库将数据以行或元组为单位存储在数据库表中,而Elasticsearch将数据以文档为单位存储在索引中。作为Elasticsearch的基本存储单元,文档是指存储在Elasticsearch索引中的JSON对象。文档中的数据由键值对构成。键是字段的名称,值是不同数据类型的字段。不同的数据类型包含但不限于字符串类型、数字类型、布尔类型、对象类型等。
7. 字段
字段是Elasticsearch中最小的单个数据单元,类似于关系型数据库表中的字段。一般实战项目前期的设计环节都是根据业务需求拆分、定义字段,并且敲定字段类型。与关系型数据库不同的是,Elasticsearch的一个字段可以设定两种或两种以上的数据类型,通过定义multi-field来灵活地满足复杂的业务需求。
8. 映射
映射类似于关系型数据库中的Schema,可以近似地理解为“表结构”。
9. 分词
倒排索引的本质是使用户以O(1)的时间复杂度快速召回结果数据。而分词则是构建倒排索引的重要一环。在英文文本中,空格就是切分语句或短语的“屏障”。但中文文本中则没有了这道“屏障”,于是分词就变得就不那么简单,需要由专门的分词算法构建的分词器来实现。