Chronos - 时间序列预测语言模型
 本文翻译整理自:https://github.com/amazon-science/chronos-forecasting
本文翻译整理自:https://github.com/amazon-science/chronos-forecasting
文章目录
- 一、关于 Chronos
- 相关链接资源
- 关键功能特性
- 二、安装
- 1、基础安装
- 2、开发模式安装
- 三、基本使用
- 1、时间序列预测
- 2、提取编码器嵌入
- 四、模型架构
- 五、零样本性能
- 六、最佳实践
- 七、数据集
一、关于 Chronos
Chronos 是基于语言模型架构的预训练时间序列预测模型家族。
通过量化和缩放将时间序列转换为token序列,使用交叉熵损失训练语言模型。
训练完成后,通过给定历史上下文采样多个未来轨迹来获得概率预测。
Chronos 模型已在大量公开时间序列数据以及高斯过程生成的合成数据上进行训练。
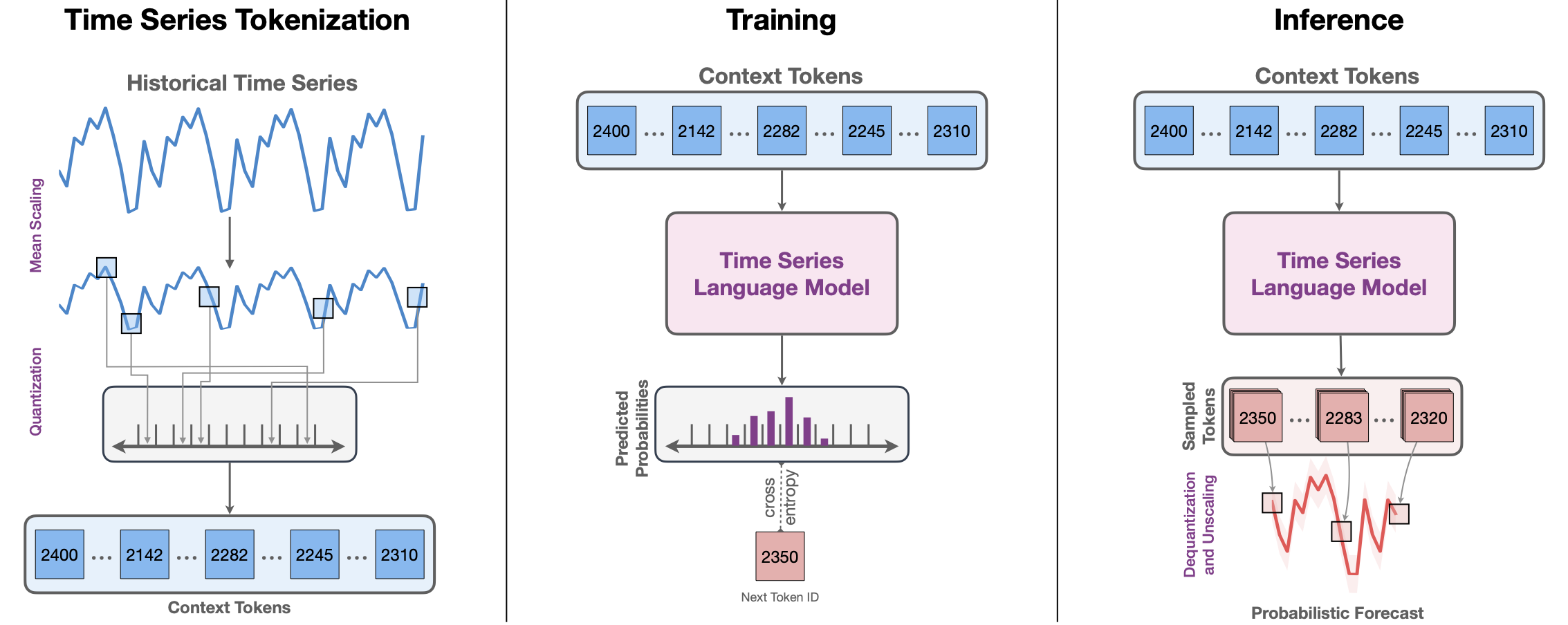
相关链接资源
- github : https://github.com/amazon-science/chronos-forecasting
- 官网:https://www.amazon.science/blog/adapting-language-model-architectures-for-time-series-forecasting
- 官方文档:https://auto.gluon.ai/stable/tutorials/timeseries/forecasting-chronos.html
- Paper : https://arxiv.org/abs/2403.07815
- Demo/在线试用:https://huggingface.co/collections/amazon/chronos-models-65f1791d630a8d57cb718444
- Hugging Face : https://huggingface.co/datasets/autogluon/chronos_datasets
- Community : https://github.com/amazon-science/chronos-forecasting/issues
- Blog : https://towardsdatascience.com/chronos-the-rise-of-foundation-models-for-time-series-forecasting-aaeba62d9da3
- FAQ : https://github.com/amazon-science/chronos-forecasting/issues?q=is%3Aissue+label%3AFAQ
- License : https://opensource.org/licenses/Apache-2.0
关键功能特性
- 基于T5架构的预训练时间序列模型
- 支持零样本(zero-shot)预测
- 提供多种模型尺寸选择(8M~710M参数)
- 支持概率预测和分位数输出
- 可提取编码器嵌入特征
- 支持SageMaker生产部署
二、安装
1、基础安装
pip install chronos-forecasting
2、开发模式安装
git clone https://github.com/amazon-science/chronos-forecasting.git
cd chronos-forecasting && pip install --editable ".[training]"
三、基本使用
1、时间序列预测
import pandas as pd
import torch
from chronos import BaseChronosPipelinepipeline = BaseChronosPipeline.from_pretrained("amazon/chronos-t5-small",device_map="cuda",torch_dtype=torch.bfloat16,
)df = pd.read_csv("https://raw.githubusercontent.com/AileenNielsen/TimeSeriesAnalysisWithPython/master/data/AirPassengers.csv")quantiles, mean = pipeline.predict_quantiles(context=torch.tensor(df["#Passengers"]),prediction_length=12,quantile_levels=[0.1, 0.5, 0.9],
)
对于原始的Chronos模型,可以使用 pipeline.reduce 来绘制预测样本。在 pipeline.product_quantiles中,可以找到更多关于 predict_wargs的选项:
from chronos import ChronosPipeline, ChronosBoltPipelineprint(ChronosPipeline.predict.__doc__) # for Chronos models
print(ChronosBoltPipeline.predict.__doc__) # for Chronos-Bolt models
我们现在可以将预测可视化:
import matplotlib.pyplot as plt # requires: pip install matplotlibforecast_index = range(len(df), len(df) + 12)
low, median, high = quantiles[0, :, 0], quantiles[0, :, 1], quantiles[0, :, 2]plt.figure(figsize=(8, 4))
plt.plot(df["#Passengers"], color="royalblue", label="historical data")
plt.plot(forecast_index, median, color="tomato", label="median forecast")
plt.fill_between(forecast_index, low, high, color="tomato", alpha=0.3, label="80% prediction interval")
plt.legend()
plt.grid()
plt.show()
2、提取编码器嵌入
import pandas as pd
import torch
from chronos import ChronosPipelinepipeline = ChronosPipeline.from_pretrained("amazon/chronos-t5-small",device_map="cuda",torch_dtype=torch.bfloat16,
)df = pd.read_csv("https://raw.githubusercontent.com/AileenNielsen/TimeSeriesAnalysisWithPython/master/data/AirPassengers.csv")# context must be either a 1D tensor, a list of 1D tensors,
# or a left-padded 2D tensor with batch as the first dimension
context = torch.tensor(df["#Passengers"])
embeddings, tokenizer_state = pipeline.embed(context)
四、模型架构
Chronos基于T5架构,主要差异在于词汇表大小(4096 vs 原版32128),减少了参数量。
| 模型 | 参数量 | 基础架构 |
|---|---|---|
| chronos-t5-tiny | 8M | t5-efficient-tiny |
| chronos-t5-mini | 20M | t5-efficient-mini |
| chronos-t5-small | 46M | t5-efficient-small |
| chronos-t5-base | 200M | t5-efficient-base |
| chronos-t5-large | 710M | t5-efficient-large |
| chronos-bolt-tiny | 9M | t5-efficient-tiny |
| chronos-bolt-mini | 21M | t5-efficient-mini |
| chronos-bolt-small | 48M | t5-efficient-small |
| chronos-bolt-base | 205M | t5-efficient-base |
五、零样本性能
Chronos在27个未见数据集上展现出卓越的零样本预测能力,优于本地统计模型和任务特定模型。
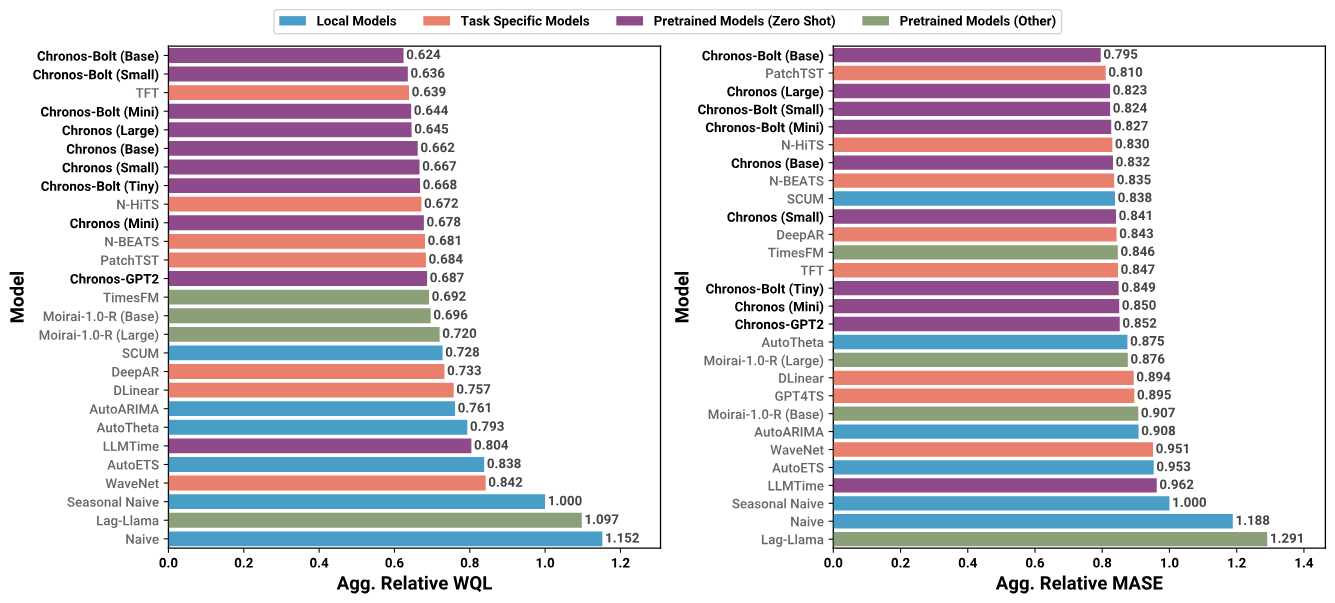
六、最佳实践
1、生产部署推荐:
- 使用AutoGluon进行微调和集成
- 通过SageMaker JumpStart部署推理端点
2、性能优化:
- Apple Silicon设备可使用MLX加速
- Chronos-Bolt模型比原版快250倍
七、数据集
训练和评估数据集可通过HuggingFace获取:
- https://huggingface.co/datasets/autogluon/chronos_datasets
- https://huggingface.co/datasets/autogluon/chronos_datasets_extra
伊织 xAI 2025-04-17(四)