【AI News | 20250423】每日AI进展
AI Repos
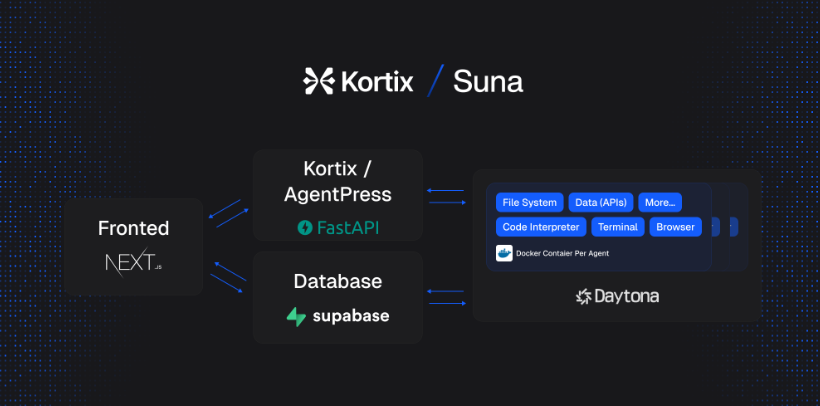
1、suna
Suna是一款完全开源的AI助手,旨在通过自然对话帮助用户轻松完成现实世界的任务。它作为您的数字伙伴,提供研究、数据分析和日常问题解决等功能,并结合强大的能力与直观的界面,理解您的需求并交付成果。Suna的工具箱包括无缝浏览器自动化、文件管理、网络爬虫和扩展搜索、命令行执行、网站部署以及与各种API和服务集成,使其能够通过简单的对话解决复杂问题并自动化工作流程。
2、short-video-maker
Shorts Video Maker是一款开源工具,旨在通过简单的文本输入自动创建引人入胜的短视频内容。它结合了文本转语音、自动字幕、背景视频和音乐等功能,可用于生成TikTok、Instagram Reels和YouTube Shorts等平台的短视频。该工具推荐至少双核CPU,可选GPU以加速字幕生成和视频渲染,并利用模型上下文协议(MCP)和REST API实现自动化视频创作。该项目由AI Agents A-Z YouTube频道开源。
3、dia
一款超逼真的文本转语音生成模型,号称超越 ElevenLabs 和 Sesame。仅仅只有 1.6B 参数,能直接从文本生成高度逼真的对话,还支持控制情感和语调,甚至可以生成笑声、咳嗽等非语言声音。
通过 [S1] 和 [S2] 标签控制生成多角色对话;支持生成笑声、清嗓子、叹息等非语言表达;提供声音克隆功能,可复制特定声音风格;实时生成,A4000 GPU 上约 40 tokens/s。提供 Gradio UI 界面,操作简单易上手,同时还可以在 Hugging Face 上在线体验。
AI News
1、字节跳动发布Vidi多模态模型:引领超长视频精准理解与编辑
字节跳动推出全新多模态模型Vidi,专注于视频理解与编辑,核心能力为精准时间检索,支持长达一小时的超长视频分析。Vidi整合视觉、音频和文本输入,在时间检索任务上性能超越GPT-4o与Gemini等主流模型,准确率提升约10%。其技术架构包括时间增强变换器和多模态编码器,并采用高效推理优化。Vidi在内容创作、智能视频分析、教育培训和娱乐推荐等领域展现出广泛应用前景,代码与模型将在GitHub开源。
2、xAI发布Grok Vision:视觉与多语言智能交互新纪元
xAI为Grok AI助手推出全新Grok Vision功能,实现通过智能手机摄像头实时分析物体、文本和环境,并结合多语言语音支持与实时搜索的无缝智能交互体验。用户可通过视觉输入和多语言语音进行提问,Grok能实时识别、解析并提供答案,其视觉处理能力在RealWorldQA基准测试中超越GPT-4V和Claude3。Grok Vision已在iOS版Grok应用上线,Android版部分功能需订阅,其开源API为开发者提供了二次开发潜力,预示着多模态AI交互的新篇章。
3、百度发布“心响”App:全托管多智能体协作超级AI
百度正式推出移动端应用“心响”,定位为通用超级智能体,旨在通过智能化手段解决用户复杂需求。该App深度整合地图类MCP功能,提供行程自动标注和出行推荐等服务。更创新地在健康、法律等专业领域实现多智能体协作,例如调度多个“医生AI分身”进行联合会诊,或由“律师智囊团”提供法律咨询。目前已覆盖200个任务类型,未来计划扩展至10万种以上,全面满足用户多样化需求。安卓版本已上线,iOS版本即将推出。
4、腾讯发布“企鹅读伴”AI阅读助手,混元大模型赋能中小学趣味阅读
腾讯在世界读书日推出“企鹅读伴”App,由混元大模型和元器平台驱动,专为中小学生设计。该AI助手能根据学生情况精准推荐书目,通过数字人、语音朗读、听书等多元模式,将传统阅读转化为互动体验。它还提供AI引导的阅读练习和启发式提问,培养学生的思辨能力。结合角色扮演和游戏化设计,激发阅读兴趣。系统自动生成阅读报告,助力学生和教育者追踪阅读情况,旨在重构阅读教育生态,实现阅读过程可追踪、成果可量化、兴趣可持续。
5、腾讯混元3D生成模型发布2.5版本:建模精度大幅提升至超高清
腾讯正式发布混元3D生成模型2.5版本,实现了建模精细度的飞跃,有效几何分辨率达到1024,总参数量提升至10B。新版本支持4K高清纹理和细粒度bump贴图,并率先实现多视图输入生成PBR模型,显著增强了模型真实感。混元3D AI创作引擎同步更新,免费生成额度翻倍,API已上线腾讯云。此外,v2.5优化了骨骼蒙皮系统和3D生成工作流,提供专业管线模板,旨在降低3D内容创作门槛,提升效率,并推动其在游戏、动画等领域的应用。腾讯混元持续拥抱开源,助力3D AIGC生态发展。
6、Otto推出业界首个PIMS集成AI医疗记录自动写回功能
Otto公司发布了其AI驱动的Recap功能的自动写回功能,成为首个在兽医技术领域实现AI生成SOAP笔记与实践信息管理系统(PIMS)无缝集成的公司。该功能支持与Avimark、Cornerstone等主流PIMS系统自动同步AI生成的医疗记录,消除了手动复制粘贴的繁琐流程,显著减少了兽医的文书工作负担,使其能够更专注于动物护理和与宠物主人的互动。AI Recap通过转录咨询内容智能提取关键信息,并以SOAP笔记或要点形式呈现,夜间自动同步至PIMS系统。
7、OpenBMB开源“卷姬”:革新长文本生成,挑战传统综述模式
OpenBMB开源了名为“卷姬”(SurveyGO)的AI模型,专注于长文本生成。该模型利用信息熵和卷积算法高效梳理海量文献,生成高质量综述报告。用户只需提供关键词,即可快速获取结构清晰、分析深入、观点有理有据且引用精准的综述。“卷姬”的强大能力源于LLMxMapReduce-V2长文本整合生成技术,该技术在参考文献利用等方面表现卓越。通过SurveyEval基准测试,“卷姬”展现出在处理大规模信息整合任务上的强大实力,预示着其在长文本生成领域广阔的应用前景。
8、阿里巴巴推出VACE模型:统一处理文本、图像和视频输入,革新视频创作
阿里巴巴发布通用人工智能模型VACE,旨在统一处理多种视频生成和编辑任务。VACE采用增强的扩散Transformer架构,通过“视频条件单元”(VCU)整合文本、图像、视频和空间蒙版等多种模态输入。其“概念解耦”技术实现对视频内容编辑的精细控制。VACE支持文本到视频、基于参考的视频合成、视频到视频编辑和基于遮罩的目标编辑等任务,并在自建基准测试中优于开源模型。阿里巴巴视VACE为通往通用多模态视频模型的重要一步,未来将扩大数据和算力进行扩展,部分代码将在GitHub开源。
9、Character.AI发布AvatarFX模型:静态图片人物开口说话
Character.AI推出创新视频生成模型AvatarFX,能将静态图片转化为具有真实感的可说话视频角色,赋予其动态表情、唇部同步和自然肢体动作。该模型基于先进的扩散模型,通过音频条件化等技术实现高速、高保真和时间一致性的视频生成,支持长序列叙事和多角色对话。AvatarFX提供多样化的音频选择,并内置安全控制措施。用户只需上传角色图片并配上音频,即可轻松生成生动视频,为个人项目、社交媒体和教学演示等提供便利。