Transformer起源-Attention Is All You Need
这篇笔记主要讲解Attention Is All You Need论文。《Attention Is All You Need》由 Ashish Vaswani 等人撰写,于 2017 年发表在 NIPS(Neural Information Processing Systems)会议上。它提出了一种全新的神经网络架构——Transformer,该架构完全基于注意力机制(Attention Mechanism),摒弃了传统的循环(Recurrent)和卷积(Convolutional)网络结构。Transformer 在机器翻译任务上取得了显著的性能提升,并且训练速度更快,成为自然语言处理(NLP)领域的一个重要里程碑。
Abstract
主流的序列转导模型基于复杂的包括编码器和解码器的递归或卷积神经网络。表现最佳的模型还通过注意力机制连接编码器和解码器。我们提出了一种新的简单网络架构——Transformer,完全基于注意力机制,摒弃了递归和卷积。在两个机器翻译任务上的实验表明,这些模型不仅质量更优,而且更加并行化,训练时间显著减少。我们的模型在WMT 2014英德翻译任务中达到了28.4的BLEU值,比现有的最佳结果,包括集成方法,提高了超过2个BLEU值。在WMT 2014英法翻译任务中,我们的模型经过3.5天的八块GPU训练后,建立了单模型最先进的BLEU分数41.0,这仅占文献中最佳模型训练成本的一小部分。
1&2. Introduction & Background
传统的序列转换模型(如机器翻译、语言建模等)大多基于复杂的循环神经网络(RNN)或卷积神经网络(CNN),这些模型通常包含编码器(Encoder)和解码器(Decoder)。尽管这些模型在性能上取得了很好的结果,但它们存在一些局限性:
-
训练速度慢:RNN 的逐时间步处理方式限制了并行化计算,导致训练时间长。
-
难以捕捉长距离依赖:CNN 虽然可以并行计算,但其感受野有限,难以捕捉长距离依赖关系。
注意力机制(Attention Mechanism)已经被证明可以有效地捕捉序列中任意位置之间的依赖关系,但以往的模型通常将注意力机制与 RNN 或 CNN 结合使用。Transformer 架构则完全基于注意力机制,摒弃了 RNN 和 CNN,从而实现了更高的并行化程度和更快的训练速度。
3. Model Architecture
在这里,编码器将输入的符号表示序列(x1,...,xn)映射到连续表示序列z =(z1,...,zn)。给定z,解码器随后生成一个输出符号序列(y1,...,ym),每次生成一个元素。在每一步中,模型采用自回归[自回归模型 -CSDN博客],利用之前生成的符号作为额外输入来生成下一个符号。Transformer模型遵循这一总体架构,使用堆叠的自注意力层和逐点全连接层,分别用于编码器和解码器,如图1的左半部分和右半部分所示。
Transformer 架构由编码器(Encoder)和解码器(Decoder)组成,两者均基于堆叠的自注意力(Self-Attention)层和前馈神经网络(Feed-Forward Network)。
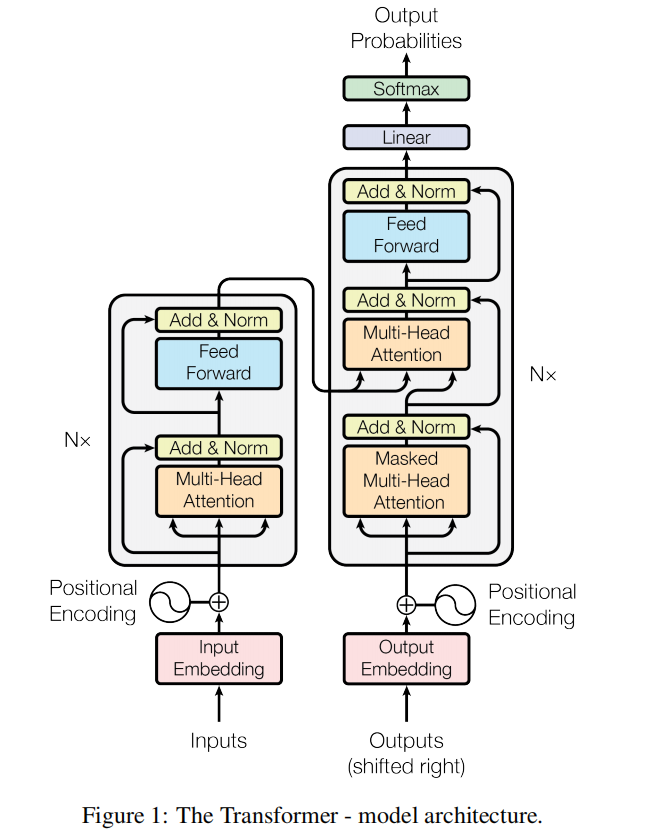
3.1.Encoder and Decoder Stacks
3.1.1.Encoder
编码器由多个相同的层(论文中使用了6层)堆叠而成,每层包含两个子层:
-
多头自注意力机制(Multi-Head Self-Attention):允许模型在不同子空间中并行地学习信息。
-
前馈神经网络(Feed-Forward Network):对每个位置的表示进行非线性变换。
我们在每个子层周围使用残差连接,随后进行层归一化。也就是说,每个子层的输出是LayerNorm(x +Sublayer(x)),其中Sublayer(x)是由该子层本身实现的功能。为了便于这些残差连接,模型中的所有子层以及嵌入层都生成维度为dmodel = 512的输出。
扩展介绍-Residual Connection(残差连接) 和 Layer Normalization(层归一化)
1. Residual Connection(残差连接)
残差连接是一种网络结构设计,它允许输入直接传递到网络的更深层次,而不仅仅是通过逐层的非线性变换。这种设计的核心思想是引入一个残差学习的概念,即网络学习输入与输出之间的残差(差异)而不是直接学习输出。
在训练非常深的神经网络时,随着网络层数的增加,梯度消失或梯度爆炸的问题会变得更加严重。这导致网络难以训练,性能下降。残差连接通过允许梯度直接传播,缓解了这一问题。
数学表示。假设 x 是输入,F(x) 是网络层的输出,残差连接可以表示为: y=F(x)+x 其中 y 是残差连接的输出。这种结构允许网络学习输入 x 和输出 y 之间的残差 F(x)=y−x。
2. Layer Normalization(层归一化)
层归一化是一种归一化技术,它对每个样本的特征进行归一化处理,使得每个特征的均值为 0,标准差为 1。与批量归一化(Batch Normalization)不同,层归一化在每个样本上独立进行,而不是在批次上进行。在训练深度神经网络时,内部协变量偏移(Internal Covariate Shift)是一个常见的问题,即每一层的输入分布会随着训练过程而变化。这种变化会影响网络的训练速度和稳定性。层归一化通过归一化输入,使得每一层的输入分布保持一致,从而缓解了这一问题。
数学表示。假设 x 是输入,层归一化的输出 y 可以表示为: y=γ((x−μ)/σ)+β 其中:
-
μ 是输入 x 的均值。
-
σ 是输入 x 的标准差。
-
γ 和 β 是可学习的参数,用于调整归一化后的数据。
3.1.2.Decoder
编码器由多个相同的层(论文中使用了6层)堆叠而成,解码器的结构与编码器类似,但额外包含一个子层:
-
编码器-解码器注意力机制(Encoder-Decoder Attention):允许解码器的每个位置关注编码器的输出。
解码器中的自注意力层需要进行掩码(Masking),以防止当前位置关注到未来的位置,从而保持自回归(Auto-Regressive)特性。
3.2.Attention
注意力函数可以描述为将查询和一组键-值对映射到输出的过程,其中查询、键、值和输出都是向量。输出是值的加权和,每个值的权重由查询与相应键的兼容性函数计算得出。
3.2.1.Scaled Dot-Product Attention
我们称这种特殊的注意力机制为“Scaled Dot-Product Attention”(图2)。输入由查询和维度为dk的键以及维度为dv的值组成。
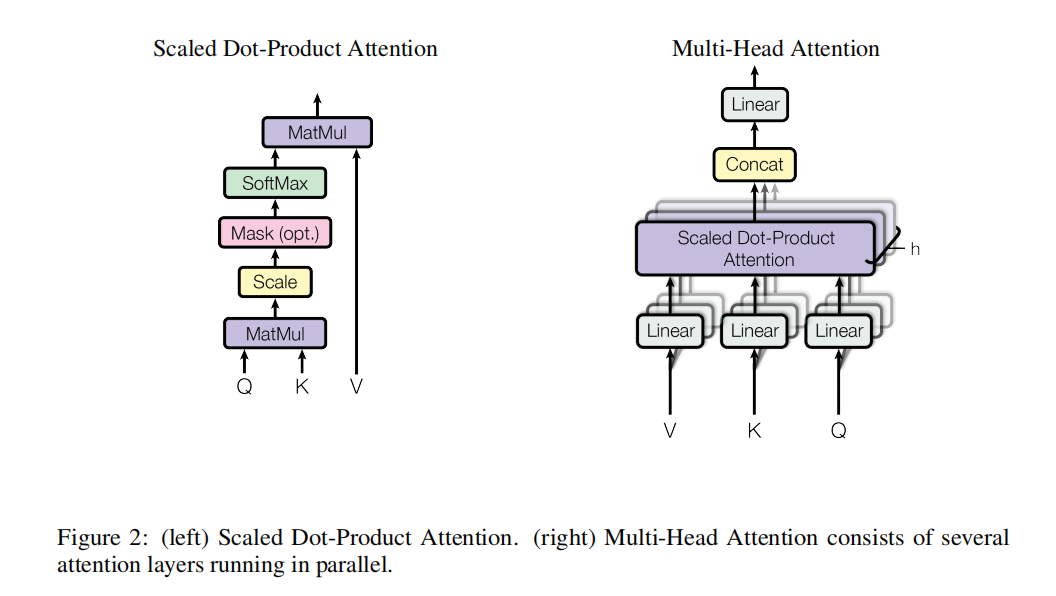
我们计算查询向量与所有键向量的点积,将每个点积结果除以√dk,并应用一个softmax函数来获得值的权重。在实践中,我们同时计算一组查询的注意力函数,将其打包成一个矩阵Q。键和值也打包成矩阵K和V。我们计算输出矩阵如下:
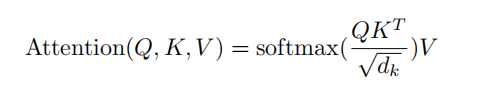
-
Q 是查询(Query)矩阵。
-
K 是键(Key)矩阵。
-
V 是值(Value)矩阵。
-
dk 是键向量的维度,用于缩放点积以避免数值不稳定。
3.2.2. Multi-Head Attention
我们没有采用单一的注意力函数来处理dmodel-dimensional的键、值和查询,而是发现将查询、键和值分别通过不同的学习线性投影线性地投影h次到dk、dk和dv维度是有益的。在这些投影后的查询、键和值上,我们并行执行注意力函数,得到dv维的输出值。这些输出值被连接起来,再次进行投影,最终得到如图2所示的结果。
多头注意力使得模型能够联合关注不同位置的不同表示子空间的信息,而单个注意力头的平均抑制了这一点。为了进一步增强模型的表示能力,Transformer 引入了多头注意力(Multi-Head Attention):

WO 其中每个“头”(Head)计算一个独立的注意力函数,然后将结果拼接起来。在这项工作中,我们使用了h = 8个并行注意力层,或称为头。对于每个头,我们使用dk = dv = dmodel/h = 64。由于每个头的维度降低,总计算成本与全维单头注意力相似。
--->不太理解,再说一遍。
多头注意力(Multi-Head Attention) 通过将输入数据分成多个不同的“头”(heads),分别计算自注意力,然后将结果拼接起来,从而能够捕捉不同子空间中的信息。在传统的单头注意力机制中,模型通过计算查询(Query)、键(Key)和值(Value)之间的关系来捕捉输入序列中的依赖关系。然而,单头注意力机制存在以下局限性:
-
表示能力有限:单头注意力只能在一个固定的子空间中捕捉信息,难以同时捕捉多种不同类型的依赖关系。
-
难以并行化:单头注意力机制在处理长序列时效率较低,因为每个位置的计算依赖于其他所有位置。
为了解决这些问题,Transformer 引入了多头注意力机制。通过将输入数据分成多个不同的“头”,每个头可以独立地学习输入序列中的不同特征和依赖关系,从而显著增强了模型的表示能力和并行化效率。
多头注意力机制的核心思想是将输入数据分成多个不同的子空间(heads),在每个子空间中独立地计算自注意力,然后将所有子空间的结果拼接起来,最后通过一个线性变换进行整合。
假设输入数据为:

在多头注意力中,输入数据 Q,K,V 首先通过线性变换被映射到多个不同的子空间中。具体来说,对于每个头 i:
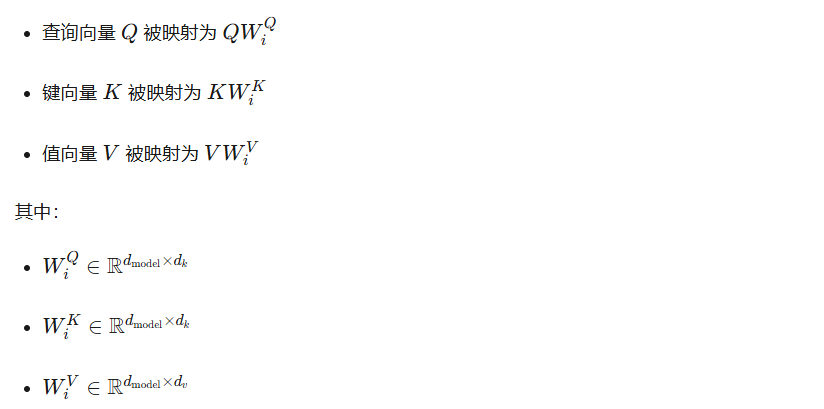
这些权重矩阵是可学习的参数,用于将输入数据映射到不同的子空间中。

将所有头的输出拼接起来,然后通过一个线性变换进行整合:

3.3. Position-wise Feed-Forward Networks(逐位置前馈神经网络)
除了注意力子层之外,我们的编码器和解码器中的每一层都包含一个全连接前馈网络,该网络分别且相同地应用于每个位置。它由两个线性变换组成,中间有一个ReLU激活函数。
![]()
虽然线性变换在不同位置上是相同的,但它们在每一层使用不同的参数。另一种描述方式是两个卷积核大小为1的卷积。输入和输出的维度为dmodel = 512,内层的维度为df=2048。
--->不太理解,看下面。
Position-wise Feed-Forward Networks(逐位置前馈神经网络)在编码器(Encoder)和解码器(Decoder)的每个层中都存在。其主要作用是对每个位置的表示进行非线性变换,从而增强模型的表达能力。
在 Transformer 架构中,自注意力机制(Self-Attention)负责捕捉序列中不同位置之间的依赖关系,但它本身是一个线性变换。为了引入非线性,逐位置前馈神经网络被设计为对每个位置的表示进行进一步的处理。这种非线性变换有助于模型捕捉更复杂的特征和模式。
逐位置前馈神经网络由两个线性变换组成,中间夹着一个非线性激活函数(通常使用 ReLU)。具体来说,对于每个位置 i 的输入 xi,前馈神经网络的输出 yi 可以表示为:
![]()

在 Transformer 架构中,逐位置前馈神经网络的参数(即 W1,W2,b1,b2)在所有位置上是共享的。这意味着每个位置的输入 xi 都通过相同的网络结构进行变换。这种参数共享机制减少了模型的参数数量,同时使得模型能够更高效地处理不同位置的输入。
逐位置前馈神经网络的内部结构可以分为两部分:
1.第一层线性变换:
![]()
这一层将输入 X 映射到一个隐藏层,通常隐藏层的维度 dff 比模型维度 dmodel 更大(例如,dff=2048)。
2.非线性激活函数:
![]()
ReLU 激活函数引入了非线性,使得模型能够捕捉更复杂的特征。
3.第二层线性变换:
![]()
这一层将隐藏层的输出映射回模型维度 dmodel。
3.4. Embeddings and Softmax
类似于其他序列转导模型,我们使用学习到的嵌入将输入标记和输出标记转换为维度为dmodel的向量。我们还使用常规的学习线性变换和softmax函数将解码器输出转换为预测的下一个标记概率。在我们的模型中,两个嵌入层和预softmax线性变换之间共享相同的权重矩阵,类似于[24]。在嵌入层中,我们将这些权重乘以√dmodel。
3.5. Positional Encoding
由于我们的模型不包含循环和卷积,为了使模型能够利用序列的顺序,我们必须注入一些关于标记在序列中相对或绝对位置的信息。为此,我们添加了“位置编码”在输入嵌入中编码器和解码器堆栈的底部。位置编码与嵌入具有相同的维度dmodel,因此两者可以相加。有许多位置编码的选择,包括学习的和固定的[8]。
在本工作中,我们使用不同频率的正弦和余弦函数:
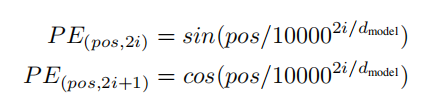
其中pos是位置,i是维度。也就是说,每个位置编码的维度对应一个正弦波。波长从2π到10000·2π形成几何级数。我们选择这个函数是因为假设它能让模型轻松学习通过相对位置进行关注,因为对于任何固定的偏移k,P Epos+k可以表示为P Epos的线性函数。
下面的部分并没有看的很仔细,有些只有翻译。
4. Why Self-Attention
在本节中,我们将自注意力层与常用的循环和卷积层进行比较,这些层通常用于将一个可变长度的符号表示序列(x1,...,xn)映射到另一个等长的序列(z1,...,zn),其中xi,zi∈R d,例如典型序列转导编码器或解码器中的隐藏层。为了说明我们使用自注意力的原因,我们考虑了三个理想特性。
一是每层的总计算复杂度。二是可以并行化的计算量,以所需最少顺序操作的数量来衡量。三是网络中长程依赖之间的路径长度。学习长程依赖是许多序列转换任务中的关键挑战。影响学习此类依赖能力的一个重要因素是信号在网络中前后传播所需路径的长度。输入和输出序列中任意位置组合之间的这些路径越短,学习长程依赖就越容易[11]。因此,我们还比较了由不同层类型组成的网络中任意两个输入和输出位置之间的最大路径长度。
1.总计算复杂度(Total Computational Complexity)
-
自注意力层:自注意力层的计算复杂度为 O(n2⋅d),其中 n 是序列长度,d 是表示的维度。这是因为自注意力机制需要计算每个位置与其他所有位置之间的关系。
-
循环层:循环层(如 RNN、LSTM、GRU)的计算复杂度为 O(n⋅d2),因为每个时间步的计算依赖于前一个时间步的状态。
-
卷积层:卷积层的计算复杂度为 O(k⋅n⋅d2),其中 k 是卷积核的大小。即使使用高效的分离卷积(Separable Convolutions),复杂度仍然较高。
在大多数自然语言处理任务中,序列长度 n 通常小于表示维度 d,因此自注意力层在计算复杂度上具有优势。
2.并行化能力(Parallelization)
-
自注意力层:自注意力层可以并行计算所有位置之间的关系,因为每个位置的计算不依赖于其他位置的计算结果。这使得自注意力层在训练时能够充分利用现代硬件(如 GPU)的并行计算能力。
-
循环层:循环层的计算是逐时间步进行的,每个时间步的计算依赖于前一个时间步的结果,因此无法并行化。这在处理长序列时会导致训练速度显著下降。
-
卷积层:卷积层虽然可以并行计算,但其感受野有限,需要多层卷积才能捕捉长距离依赖关系,这增加了计算复杂度。
3.长距离依赖关系(Long-Range Dependencies)
-
自注意力层:自注意力层通过计算每个位置与其他所有位置之间的关系,能够直接捕捉长距离依赖关系。这种机制使得模型能够更有效地学习输入序列中任意两个位置之间的依赖关系。
-
循环层:循环层在处理长序列时,由于梯度消失或梯度爆炸的问题,难以捕捉长距离依赖关系。虽然有一些技巧(如残差连接、门控机制)可以缓解这一问题,但仍然存在限制。
-
卷积层:卷积层的感受野有限,需要多层卷积才能捕捉长距离依赖关系。这不仅增加了计算复杂度,还可能导致信息丢失。
5. Training
5.1. Training Data and Batching
我们在标准的WMT 2014英德语数据集上进行了训练,该数据集包含约450万句对。句子使用字节对编码[3]进行编码,该编码共享约37000个源目标词汇。对于英法语,我们使用了显著更大的WMT 2014英法语数据集,包含3600万句,并将词元拆分为32000个词块词汇[31]。句子对根据近似序列长度批量处理。每个训练批次包含一组句子对,其中大约有25000个源词元和25000个目标词元。
5.2. Hardware and Schedule
我们在一台配备8个NVIDIA P100 GPU的机器上训练了模型。对于使用本文所述超参数的基本模型,每个训练步骤大约需要0.4秒。我们总共训练了100,000个步骤或12小时。对于我们的大型模型(见表3底部),每步时间是1.0秒。大型模型训练了300,000个步骤(3.5天)。
5.3. Optimizer
我们使用了Adam优化器[17],β1 = 0.9、β2 = 0.98和![]() 。我们在训练过程中根据公式调整学习率:
。我们在训练过程中根据公式调整学习率:
![]()
这相当于在前warmup_steps个训练步骤中线性增加学习率,之后按步数的平方根倒数比例降低学习率。我们使用了warmup_steps = 4000。
5.4. Regularization
我们在训练过程中使用了三种类型的正则化
残差丢弃。我们在每个子层的输出上应用丢弃,然后再将其加入到子层输入并进行归一化。此外,我们还对编码器和解码器堆栈中的嵌入和位置编码的总和应用丢弃。对于基础模型,我们使用Pdrop = 0.1的丢弃率。
标签平滑。训练过程中,我们采用了![]() 的标签平滑。这会损害困惑度,因为模型学会了更加不确定,但提高了准确率和BLEU分数
的标签平滑。这会损害困惑度,因为模型学会了更加不确定,但提高了准确率和BLEU分数
6. result
7.conclusion
在这项工作中,我们介绍了Transformer,这是首个完全基于注意力机制的序列转换模型,用多头自注意力取代了编码器-解码器架构中最常用的循环层。
对于翻译任务,Transformer的训练速度显著快于基于循环或卷积层的架构。在WMT 2014英德和WMT 2014英法翻译任务中,我们取得了新的突破。在前者任务中,我们的最佳模型甚至超越了所有先前报道的集成方法。
我们对基于注意力机制的模型未来充满期待,并计划将其应用于其他任务。我们打算将Transformer扩展到涉及文本以外的输入和输出模态的问题,并研究局部、受限注意力机制,以高效处理图像、音频和视频等大型输入和输出。
减少生成过程的顺序性也是我们的另一个研究目标。用于训练和评估模型的代码可在https://github.com/ tensorflow/tensor2tensor获取。