MySQL数据库基本操作-DQL-基本查询
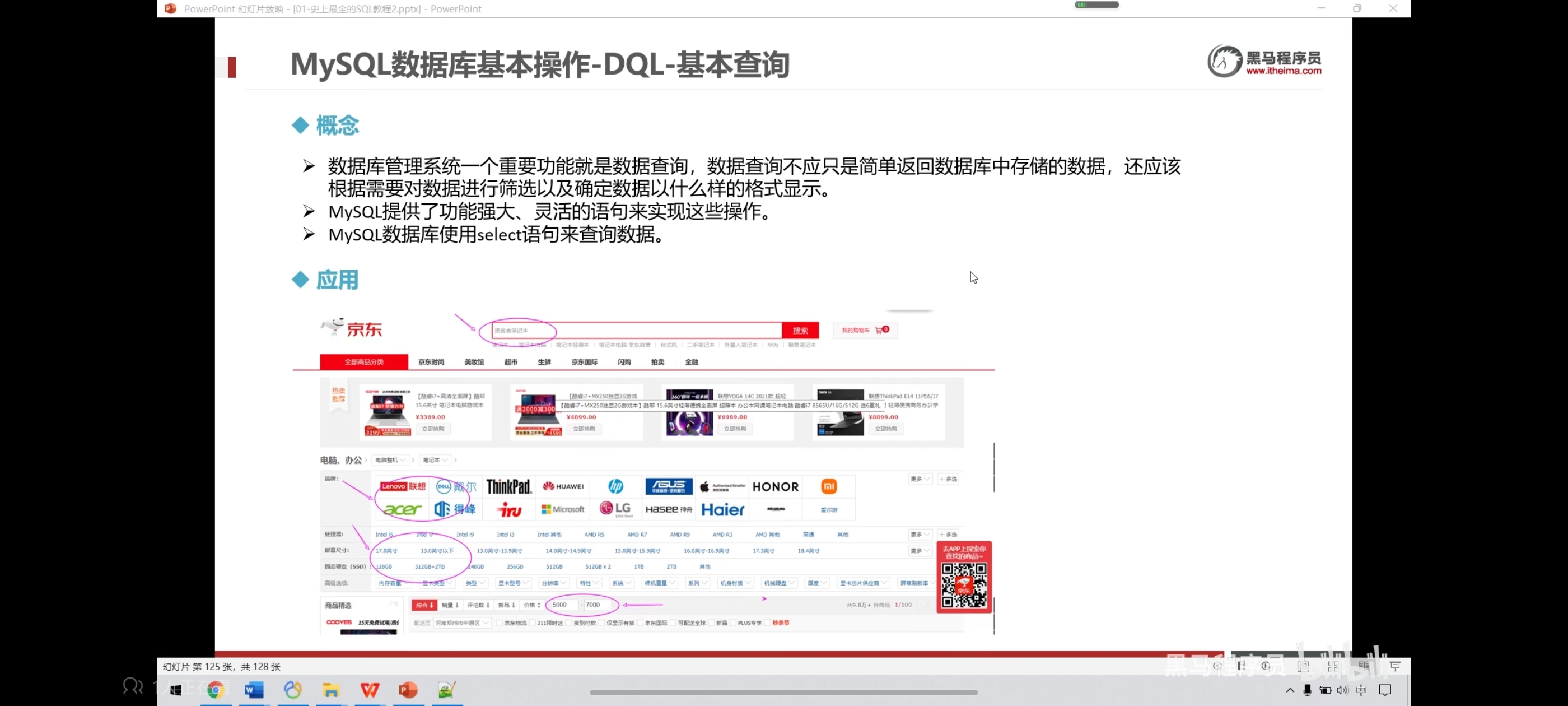
数据库的操作中,查询是最重要的
一、基本查询-数据准备
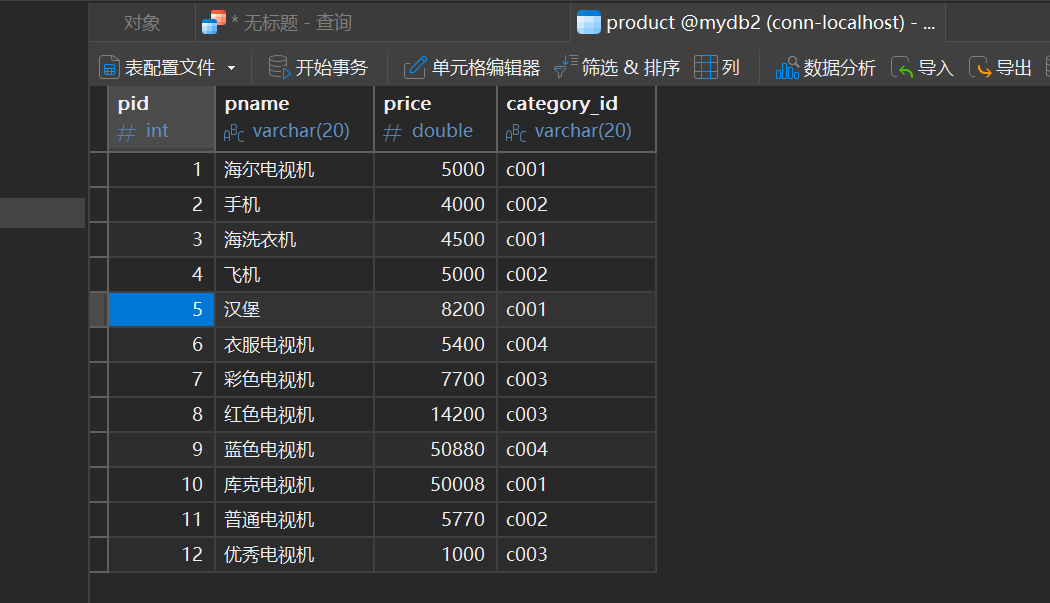
-- 数据准备
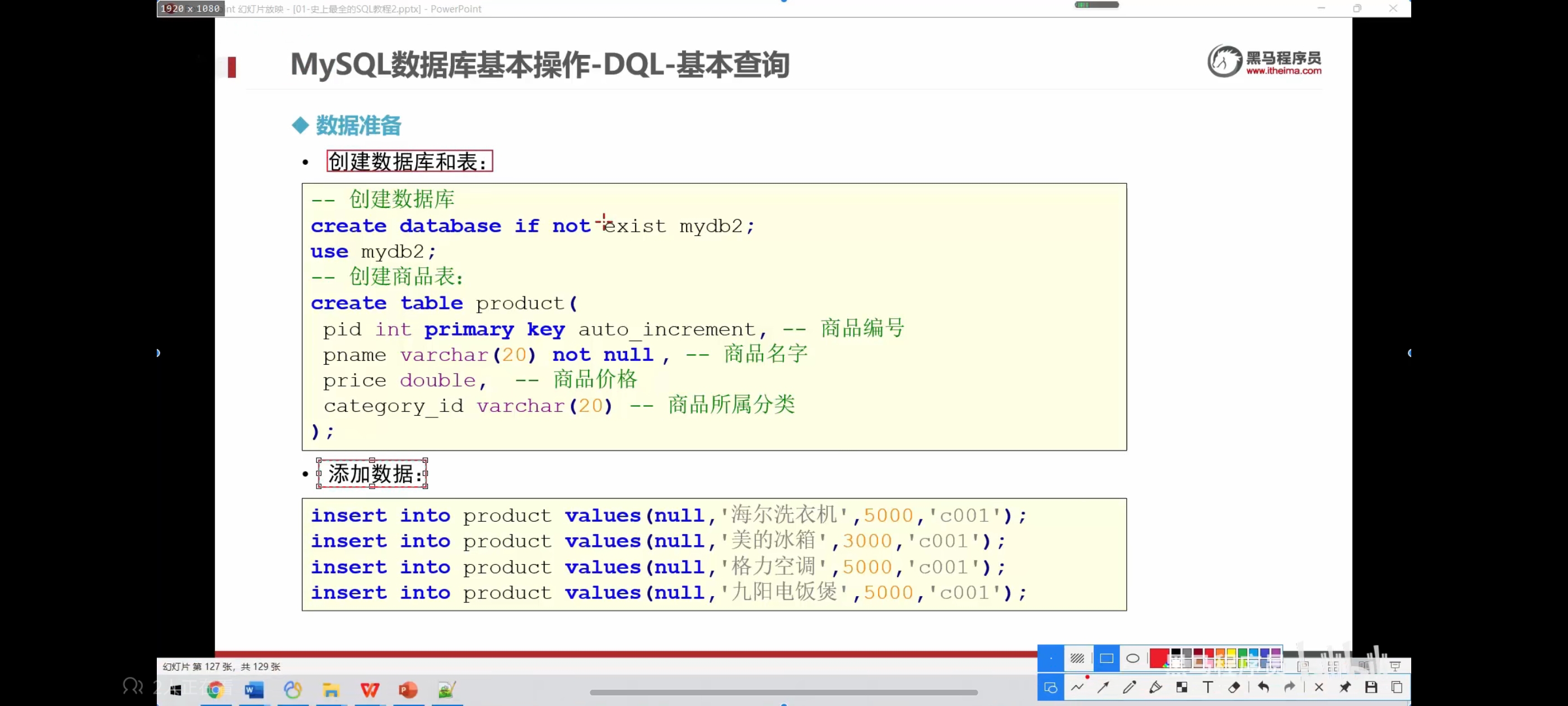
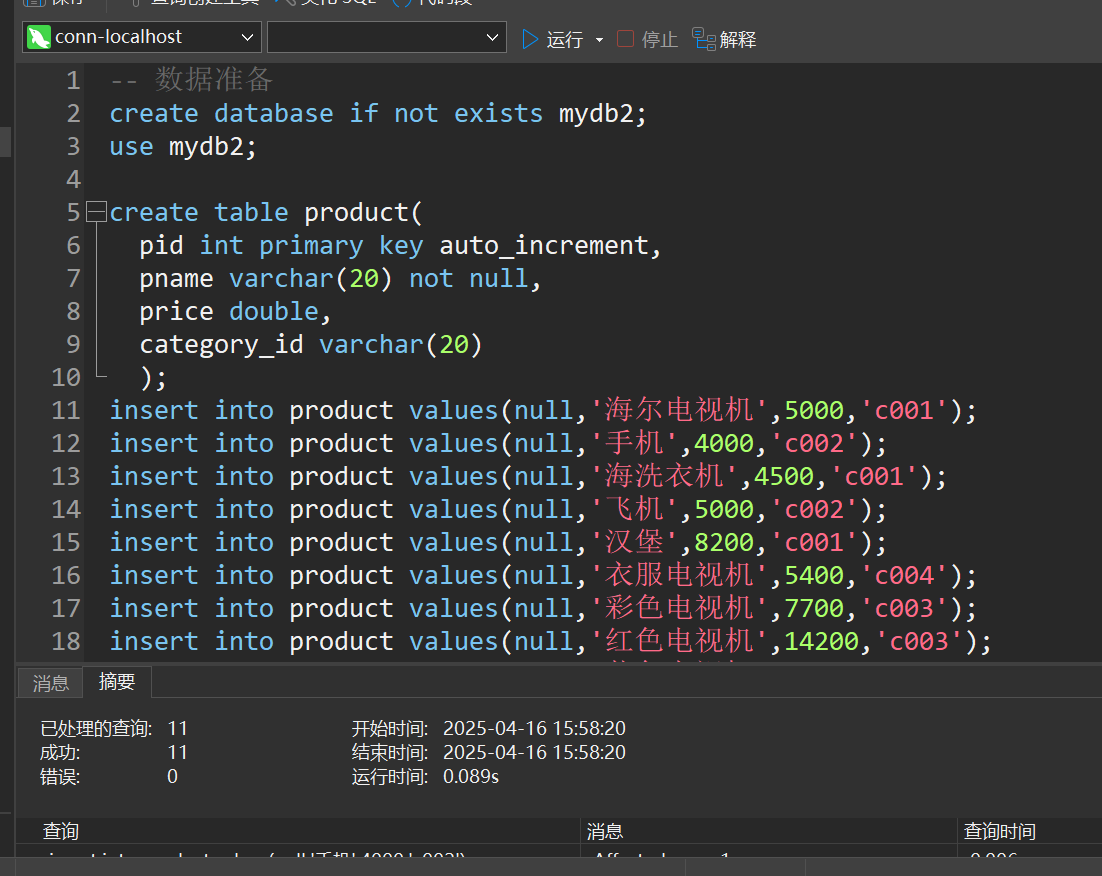
create database if not exists mydb2;
use mydb2;
create table product(
pid int primary key auto_increment,
pname varchar(20) not null,
price double,
category_id varchar(20)
);
insert into product values(null,'海尔电视机',5000,'c001');
insert into product values(null,'手机',4000,'c002');
insert into product values(null,'海洗衣机',4500,'c001');
insert into product values(null,'飞机',5000,'c002');
insert into product values(null,'汉堡',8200,'c001');
insert into product values(null,'衣服电视机',5400,'c004');
insert into product values(null,'彩色电视机',7700,'c003');
insert into product values(null,'红色电视机',14200,'c003');
insert into product values(null,'蓝色电视机',50880,'c004');
insert into product values(null,'库克电视机',50008,'c001');
insert into product values(null,'普通电视机',5770,'c002');
insert into product values(null,'优秀电视机',1000,'c003');
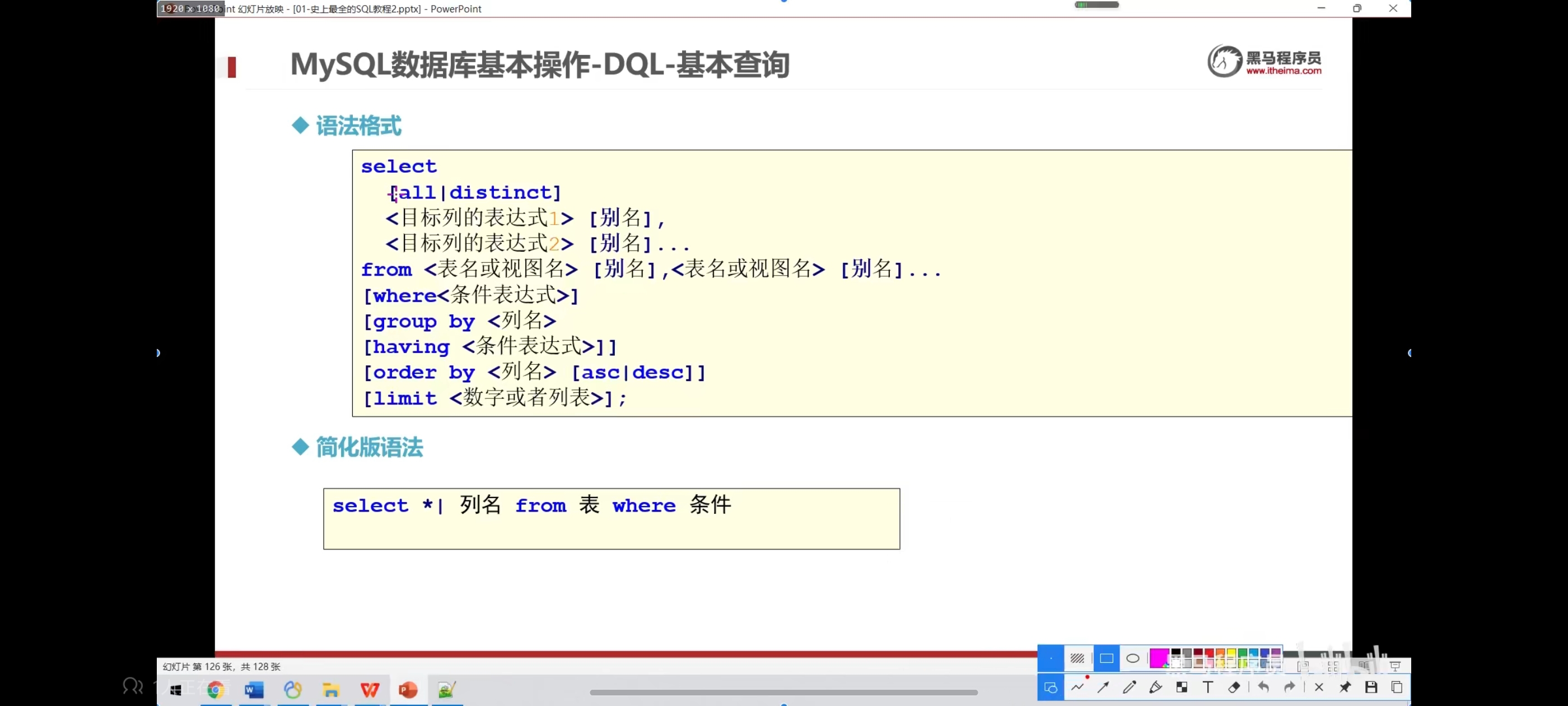
二、简单查询
别名查询给表或者列起一个别名
-- 查询所有的商品
select pid,pname,price,category_id from product;
select * from product;
-- 查询商品名和商品价格
select pname,price from product;
-- 别名查询,使用关键字是as(as可以省略的)
-- 表别名,就是给表起一个别名
select * from product as p;
select * from product p;
-- 多表查询会用
select p.id,u.id from product p,user u;
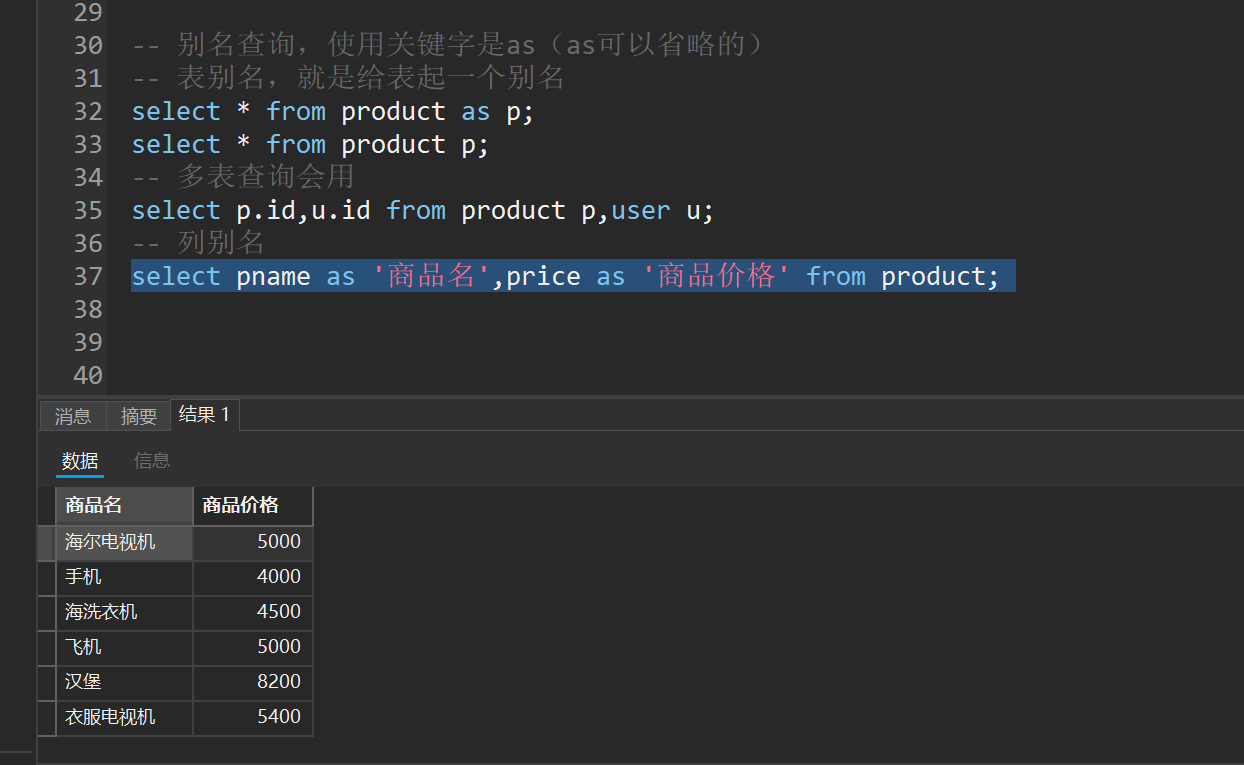
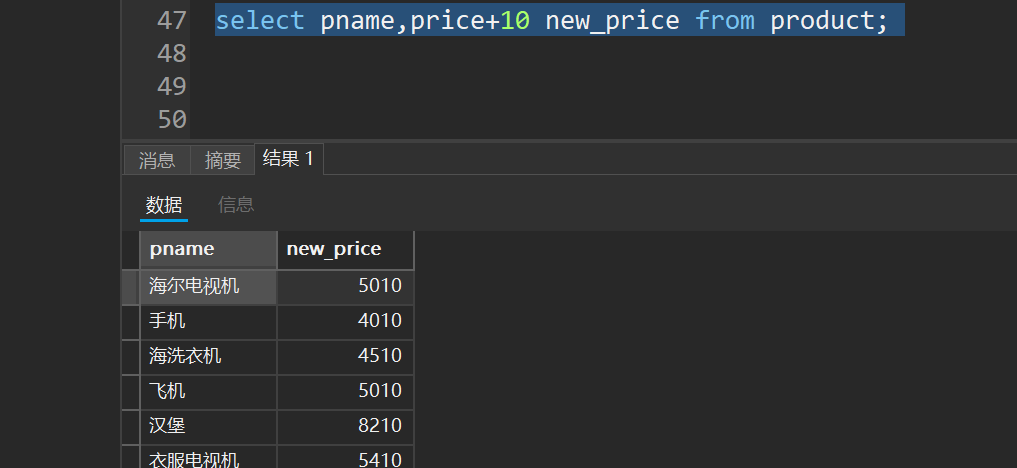
-- 列别名
select pname as '商品名',price as '商品价格' from product;
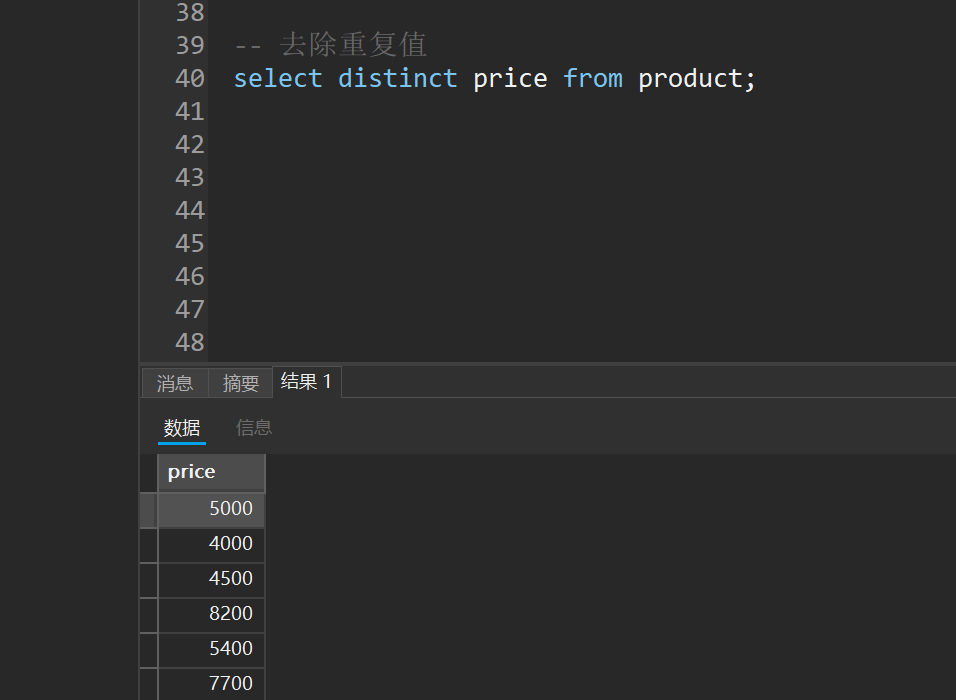
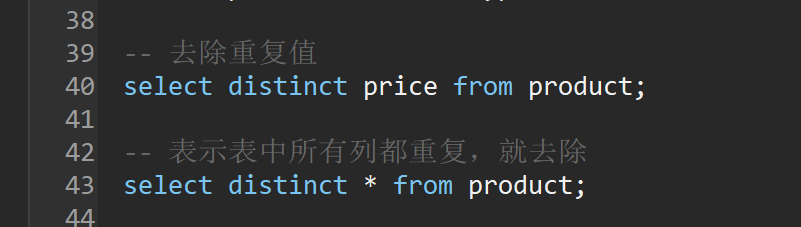
-- 去除重复值
select distinct price from product;
-- 表示表中所有列都重复,就去除
select distinct * from product;
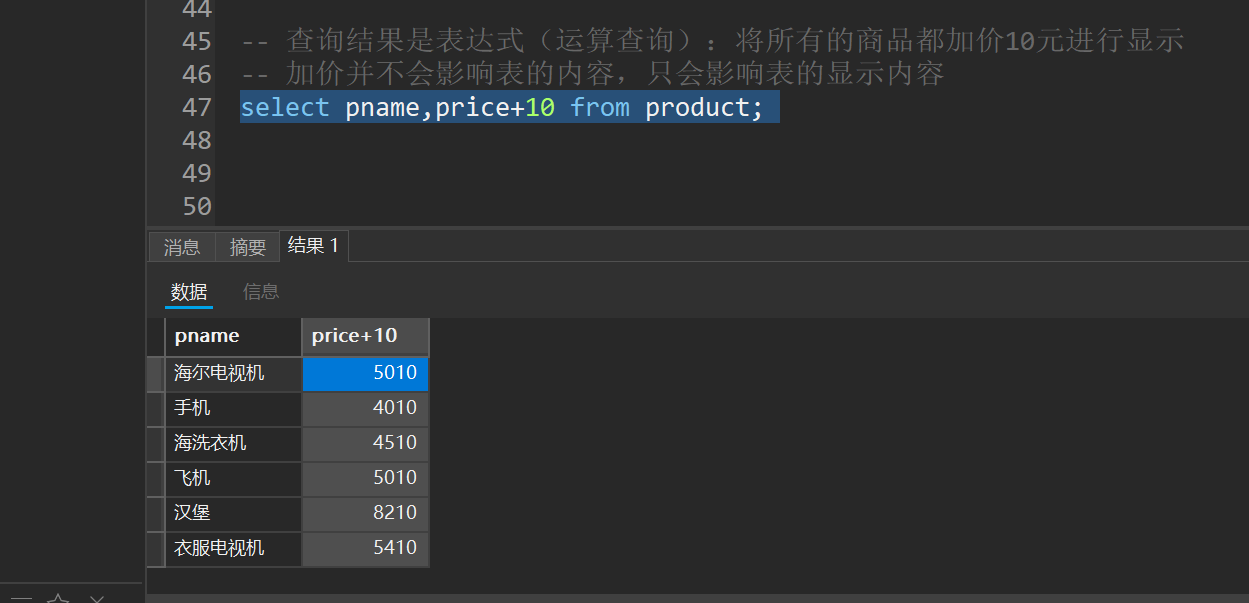
-- 查询结果是表达式(运算查询):将所有的商品都加价10元进行显示
-- 加价并不会影响表的内容,只会影响表的显示内容
select pname,price+10 new_price from product;
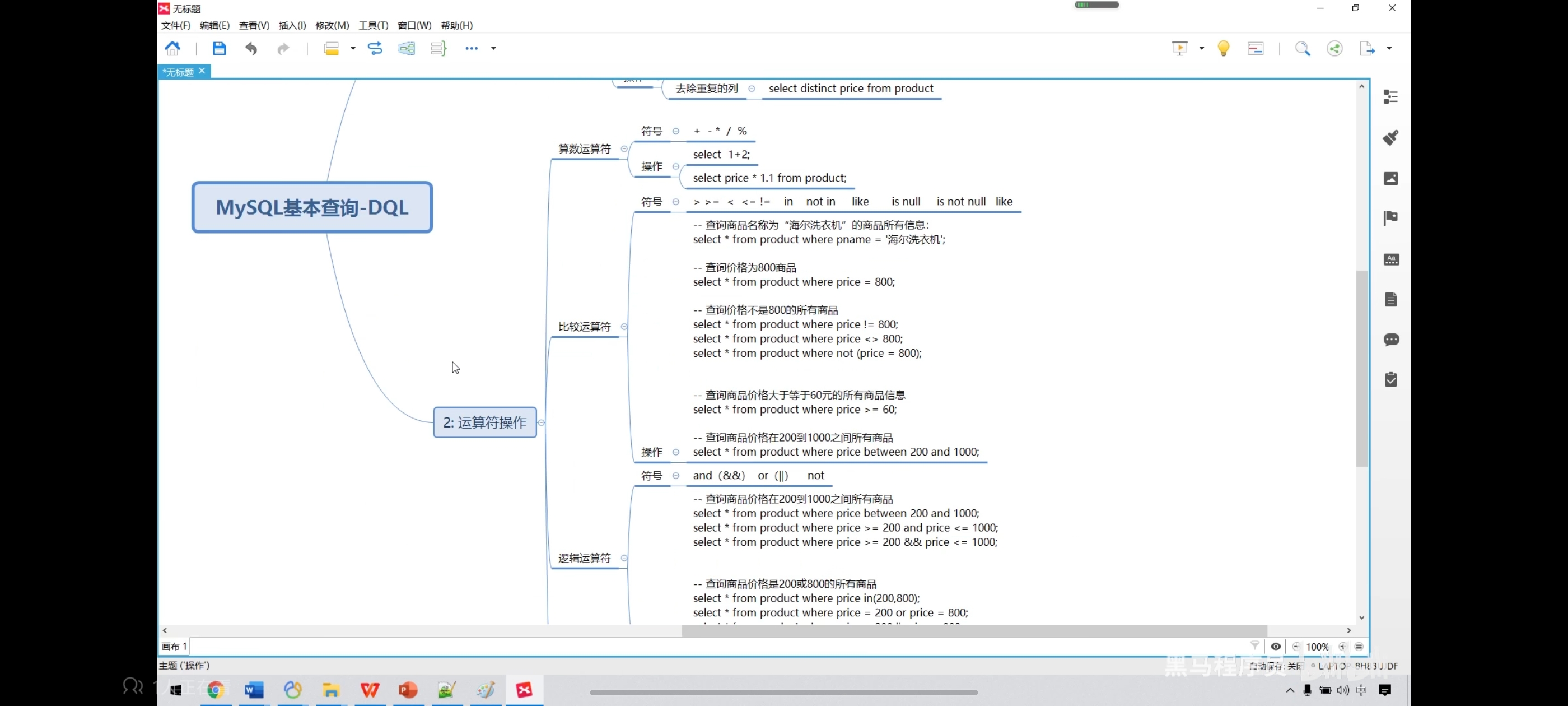
三、运算符
异或:不同为真,相同为假


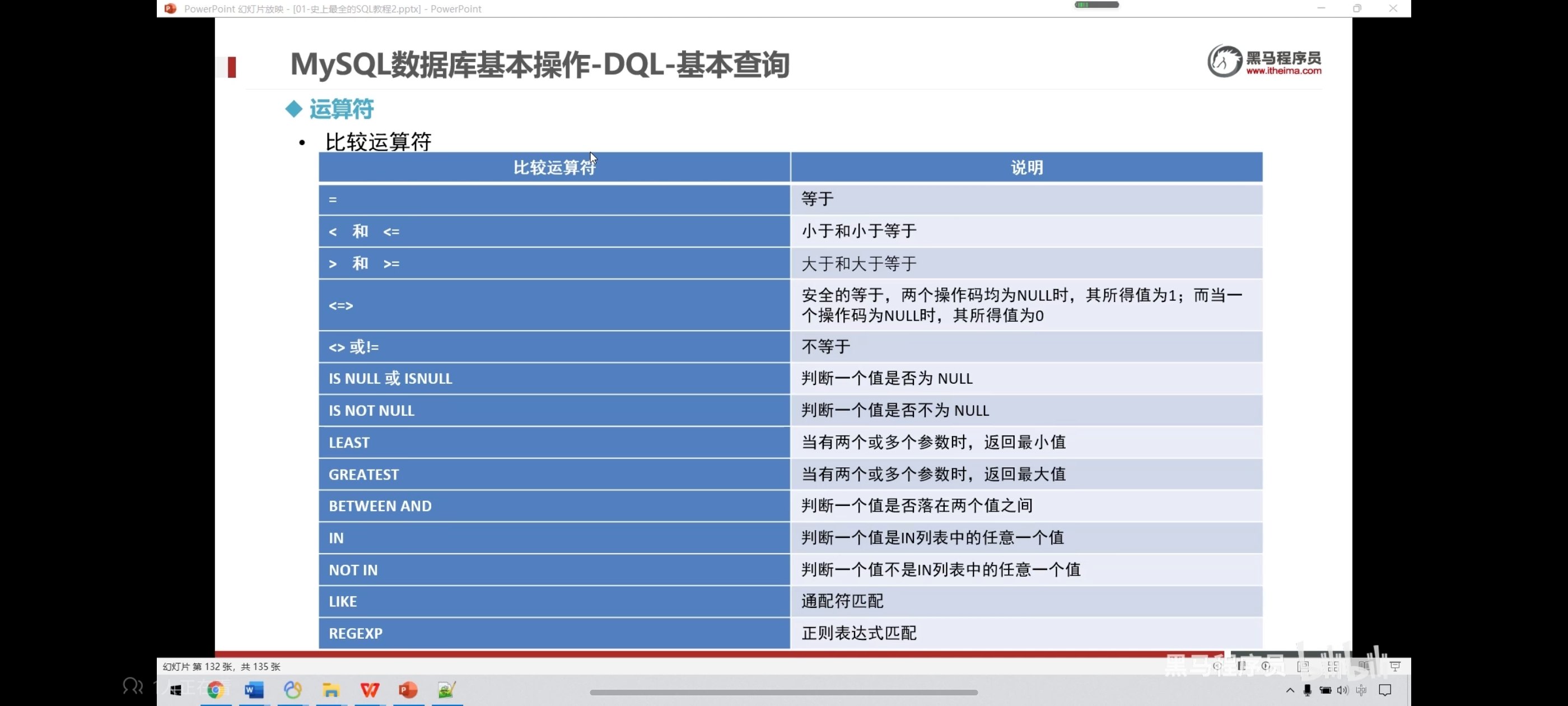


四、运算符操作-算数运算符查询
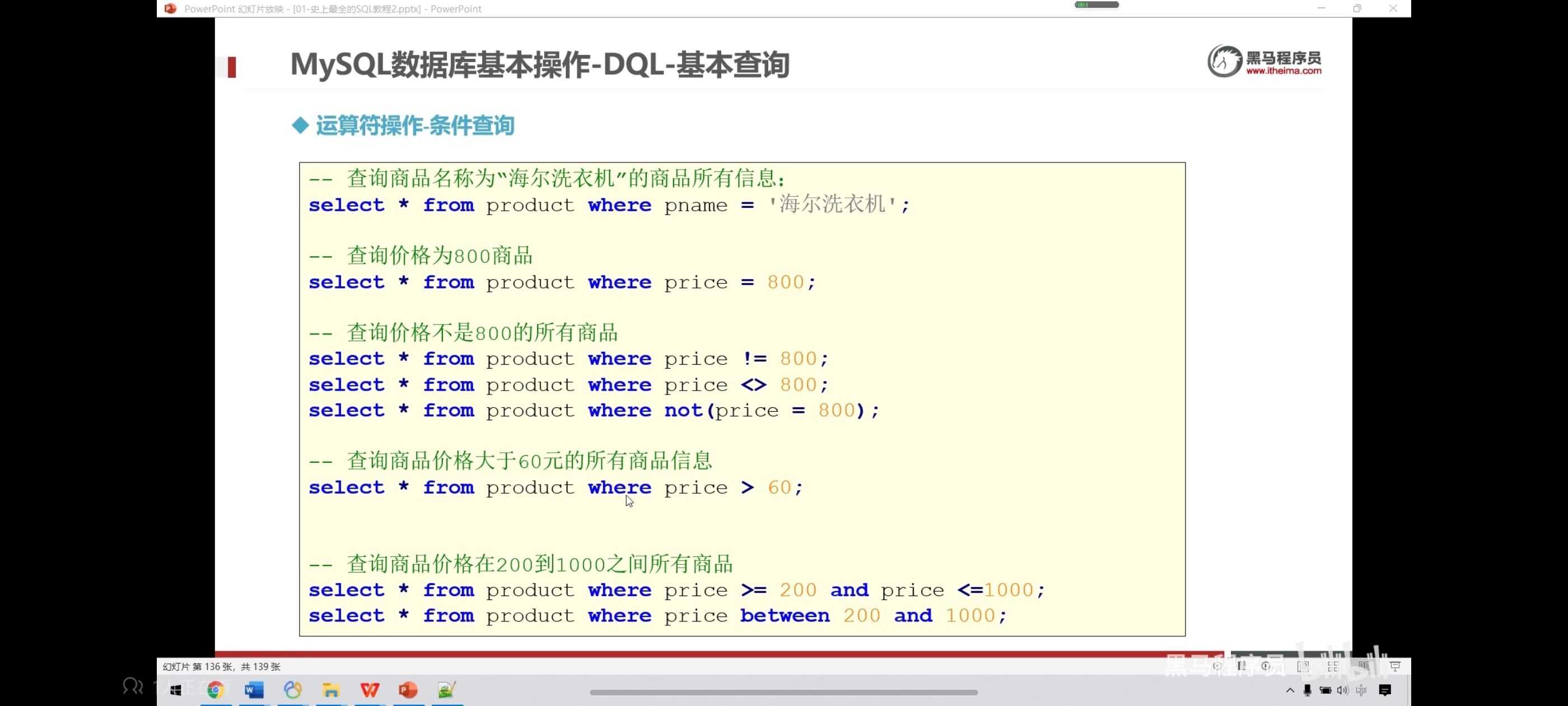
五、运算符操作-条件查询
<>表示的也是不等于,和!=一样
use mydb1;
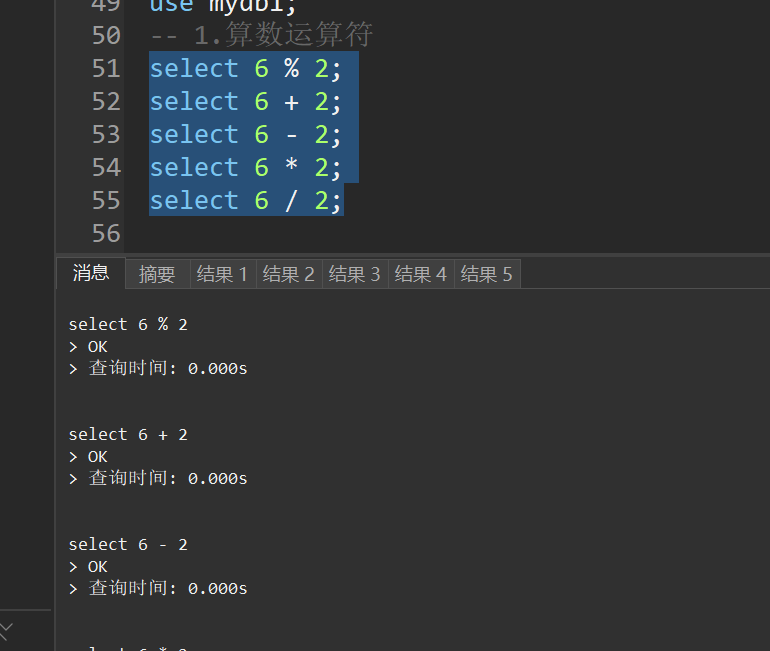
-- 1.算数运算符查询
select 6 % 2;
select 6 + 2;
select 6 - 2;
select 6 * 2;
select 6 / 2;
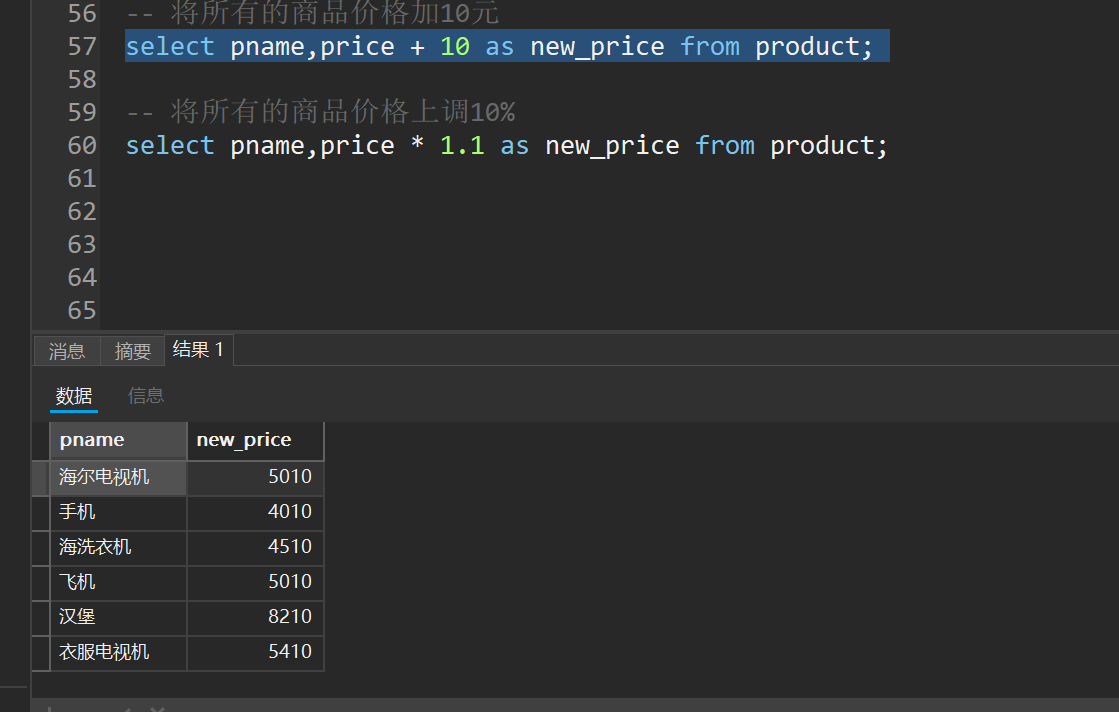
-- 将所有的商品价格加10元
select pname,price + 10 as new_price from product;
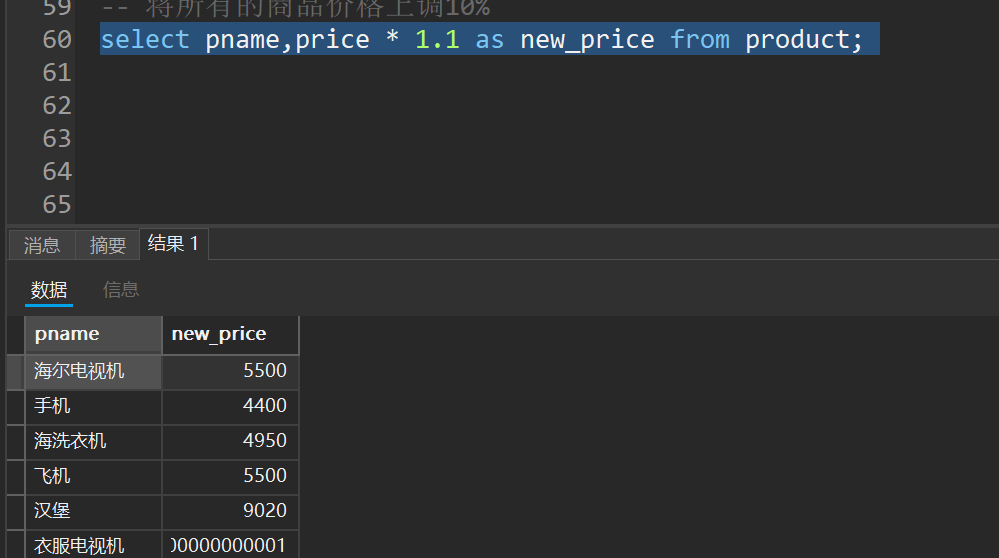
-- 将所有的商品价格上调10%
select pname,price * 1.1 as new_price from product;
-- 查询商品名称为海尔电视机的商品所有信息;
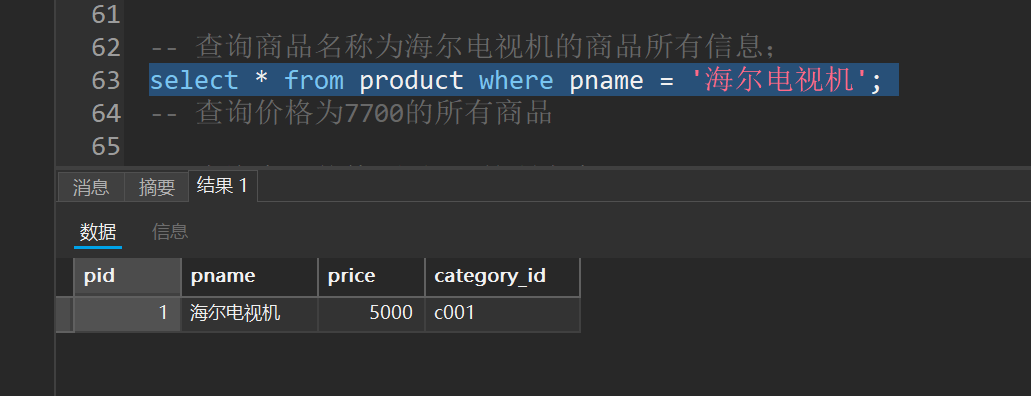
select * from product where pname = '海尔电视机';
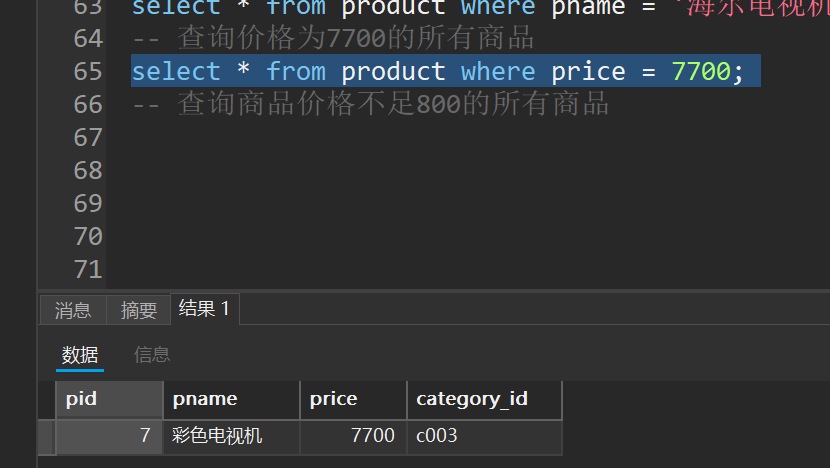
-- 查询价格为7700的所有商品
select * from product where price = 7700;
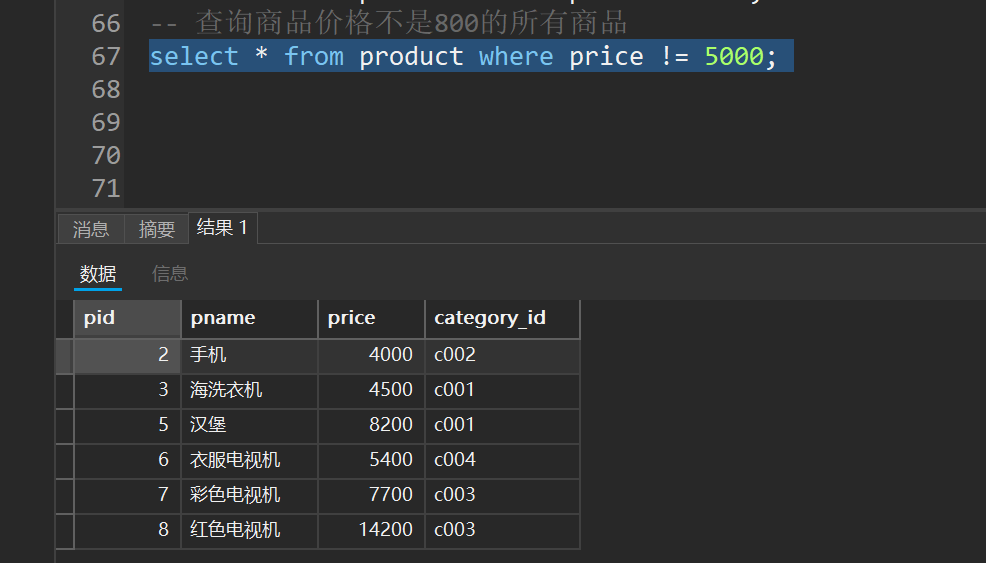
-- 查询商品价格不是800的所有商品
select * from product where price != 5000;
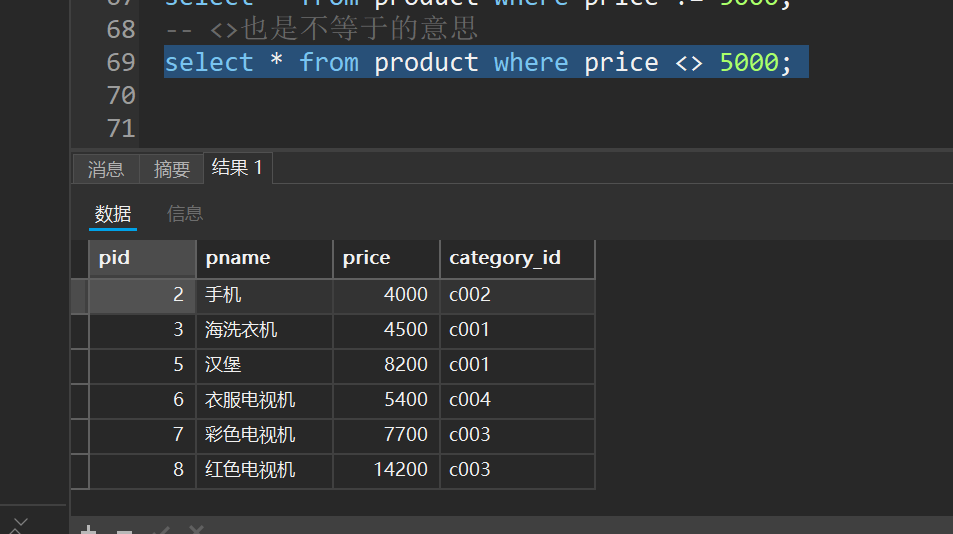
-- <>也是不等于的意思
select * from product where price <> 5000;
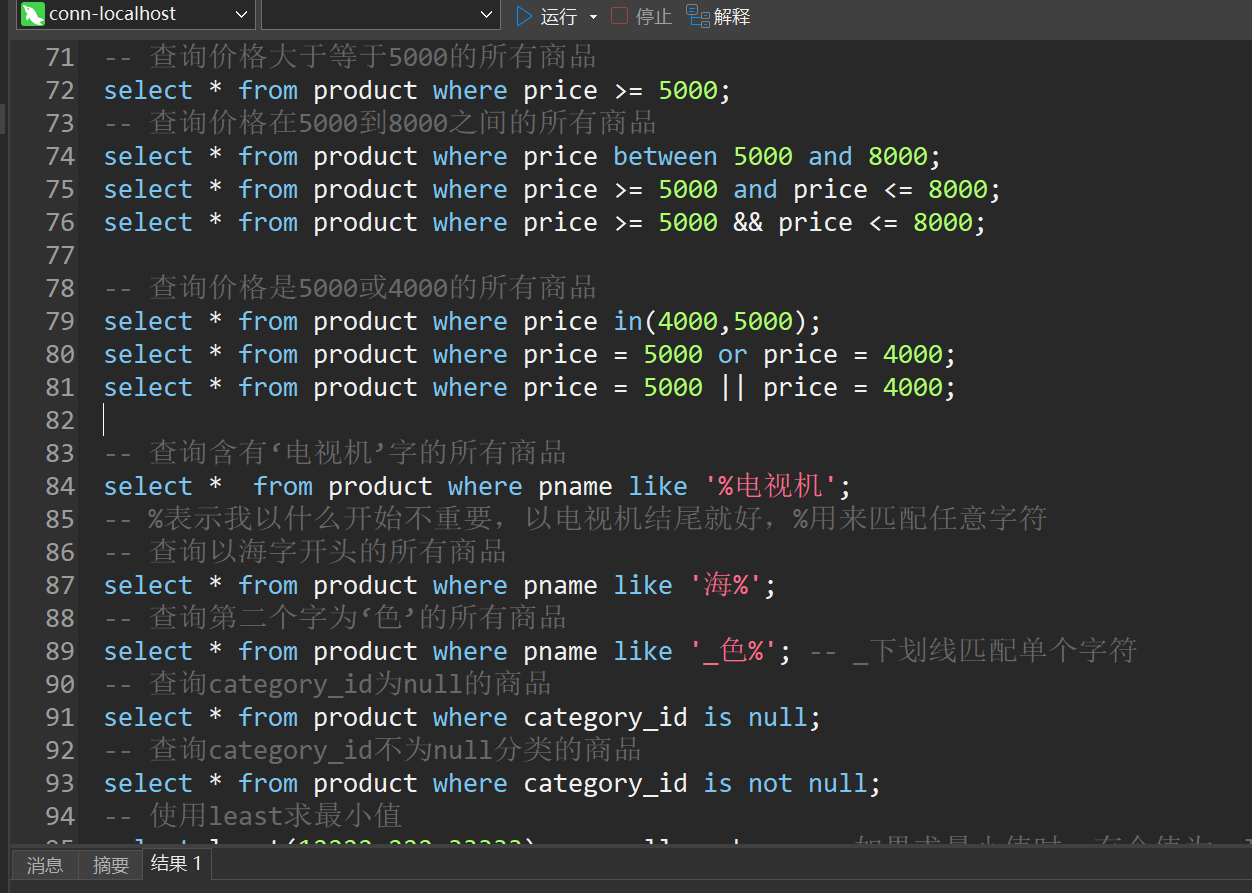
-- 查询价格大于等于5000的所有商品
select * from product where price >= 5000;
-- 查询价格在5000到8000之间的所有商品
select * from product where price between 5000 and 8000;
select * from product where price >= 5000 and price <= 8000;
select * from product where price >= 5000 && price <= 8000;
-- 查询价格是5000或4000的所有商品
select * from product where price in(4000,5000);
select * from product where price = 5000 or price = 4000;
select * from product where price = 5000 || price = 4000;
-- 查询含有‘电视机’字的所有商品
select * from product where pname like '%电视机';
-- %表示我以什么开始不重要,以电视机结尾就好,%用来匹配任意字符
-- 查询以海字开头的所有商品
select * from product where pname like '海%';
-- 查询第二个字为‘色’的所有商品
select * from product where pname like '_色%'; -- _下划线匹配单个字符
-- 查询category_id为null的商品
select * from product where category_id is null;
-- 查询category_id不为null分类的商品
select * from product where category_id is not null;
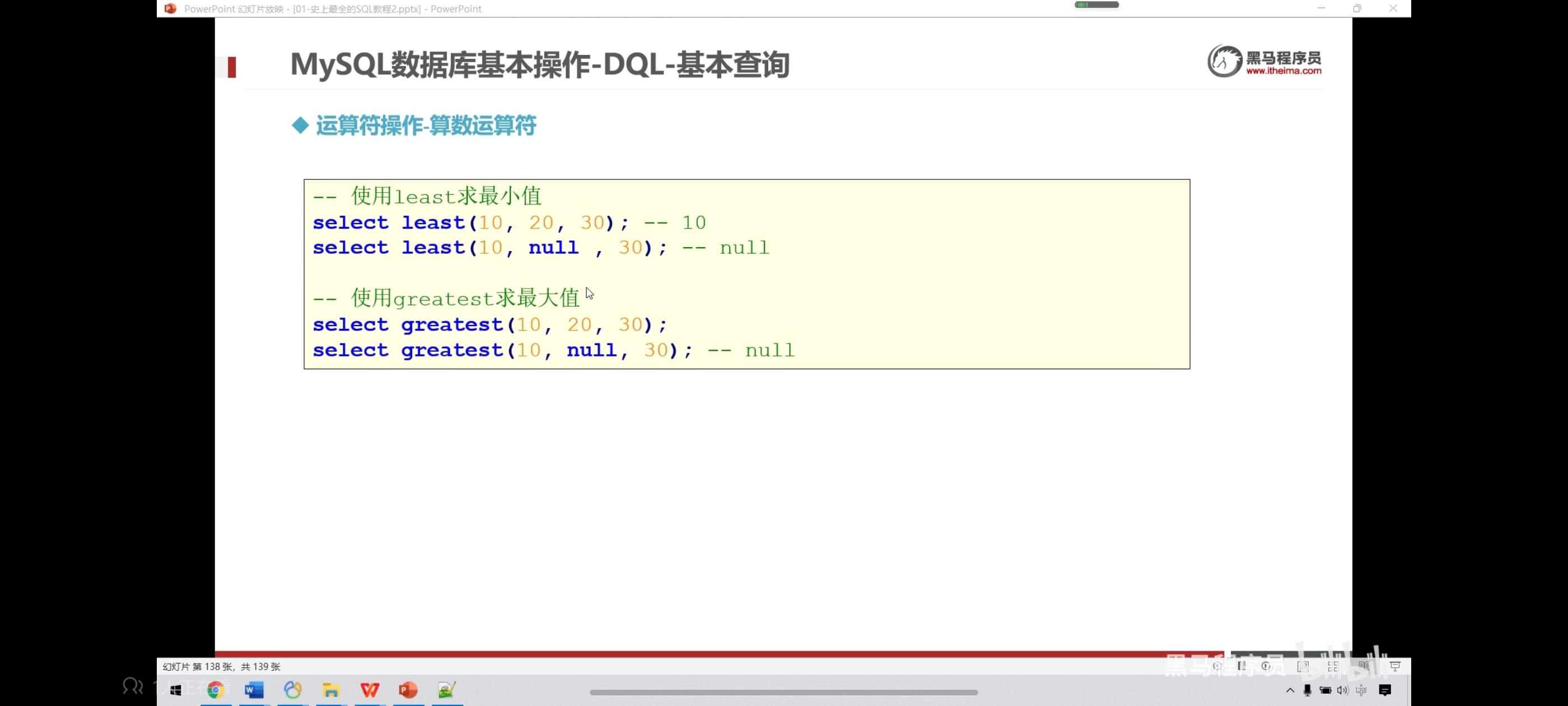
-- 使用least求最小值
select least(12222,222,33333) as small_number; -- 如果求最小值时,有个值为null,则不会进行比较,直接为null
-- 使用greatest求最大值
select greatest(121,232,23232) as big_number; -- 如果求最大值时,有个值为null,则不会进行比较,直接为null
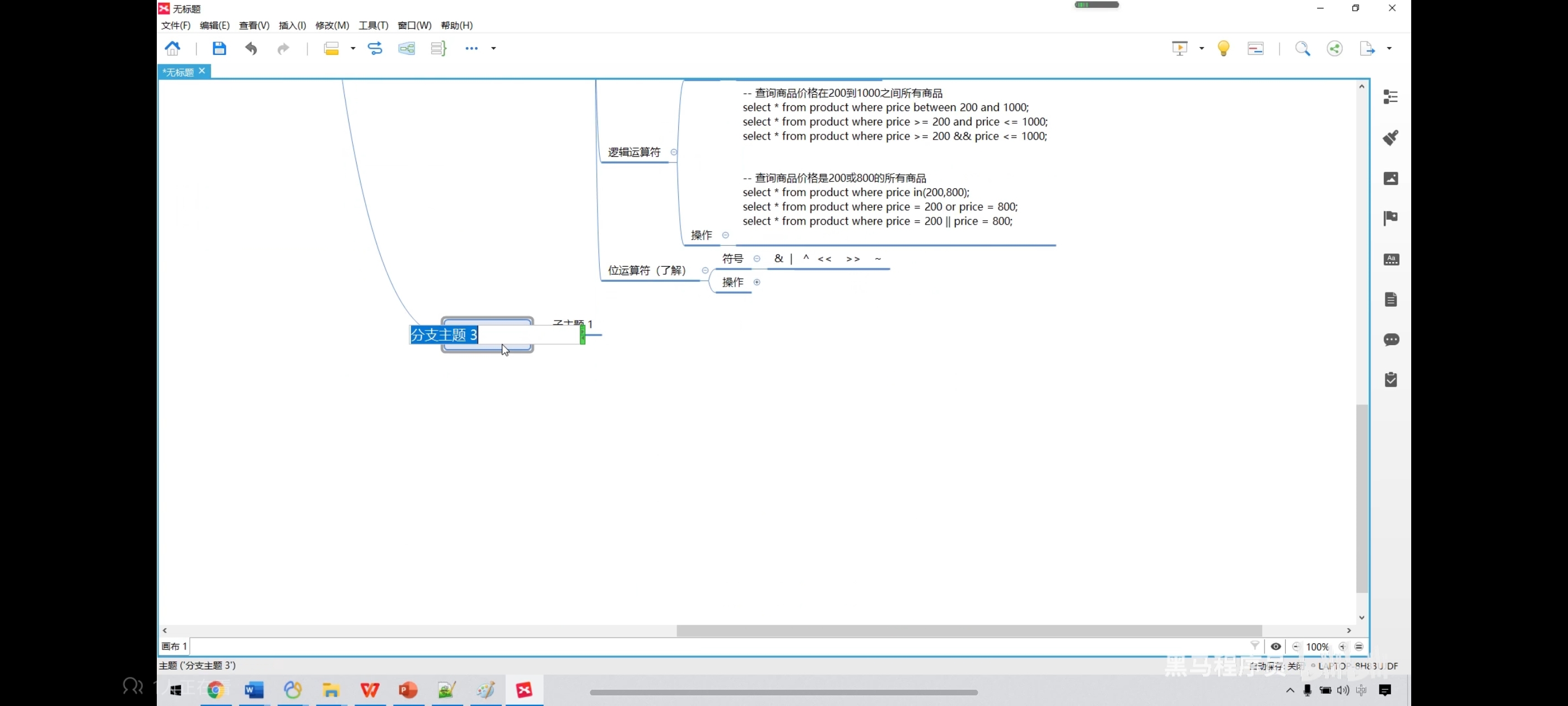
六、运算符操作-位运算操作
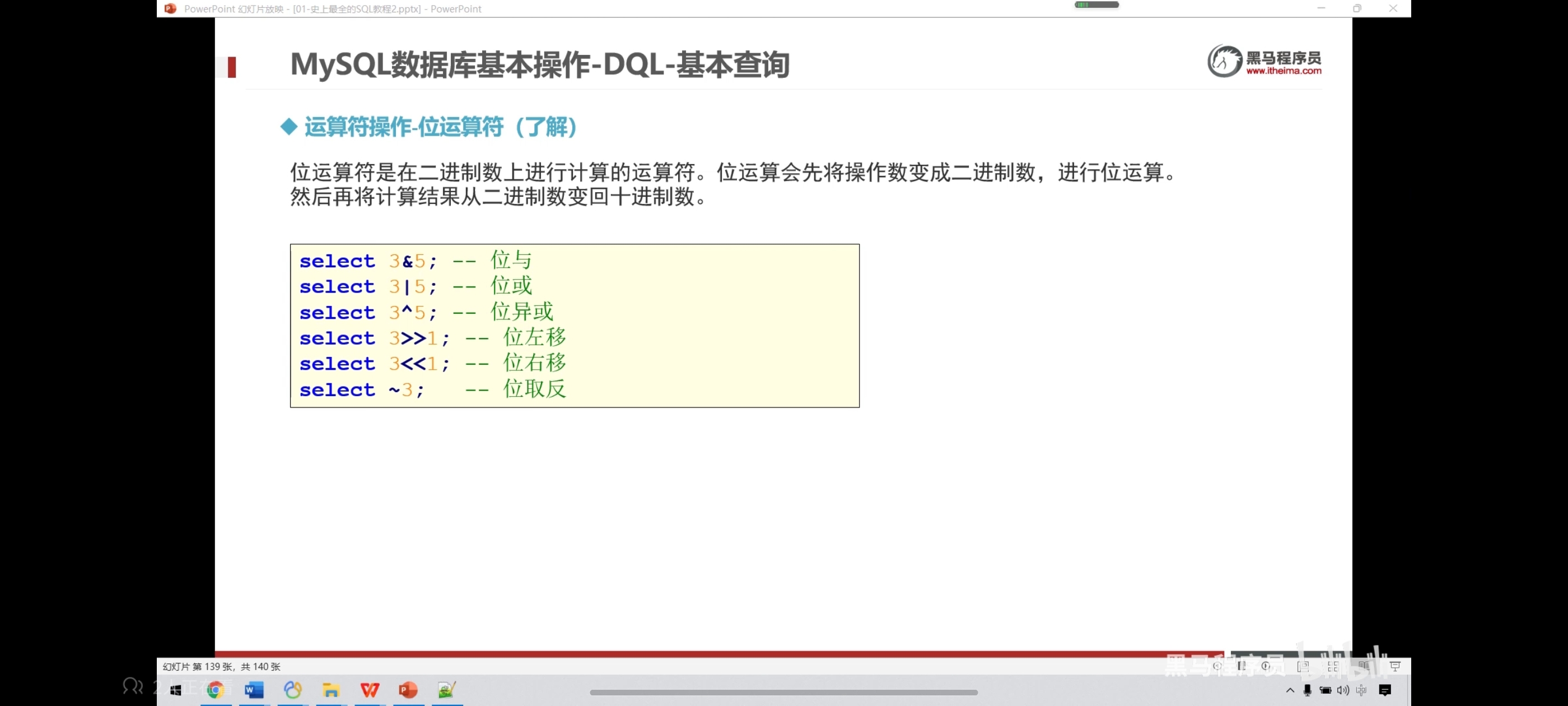
select 3 & 5; -- 位与,两个都为1就为1
select 3|5; -- 位或,有一个有一个为1就为1
select 3^5; -- 相同为0不同为1
select 3>>1; -- 位右移
select 3<<1; -- 位左移
select ~3; -- 位取反,取反就是把0变1,1变0
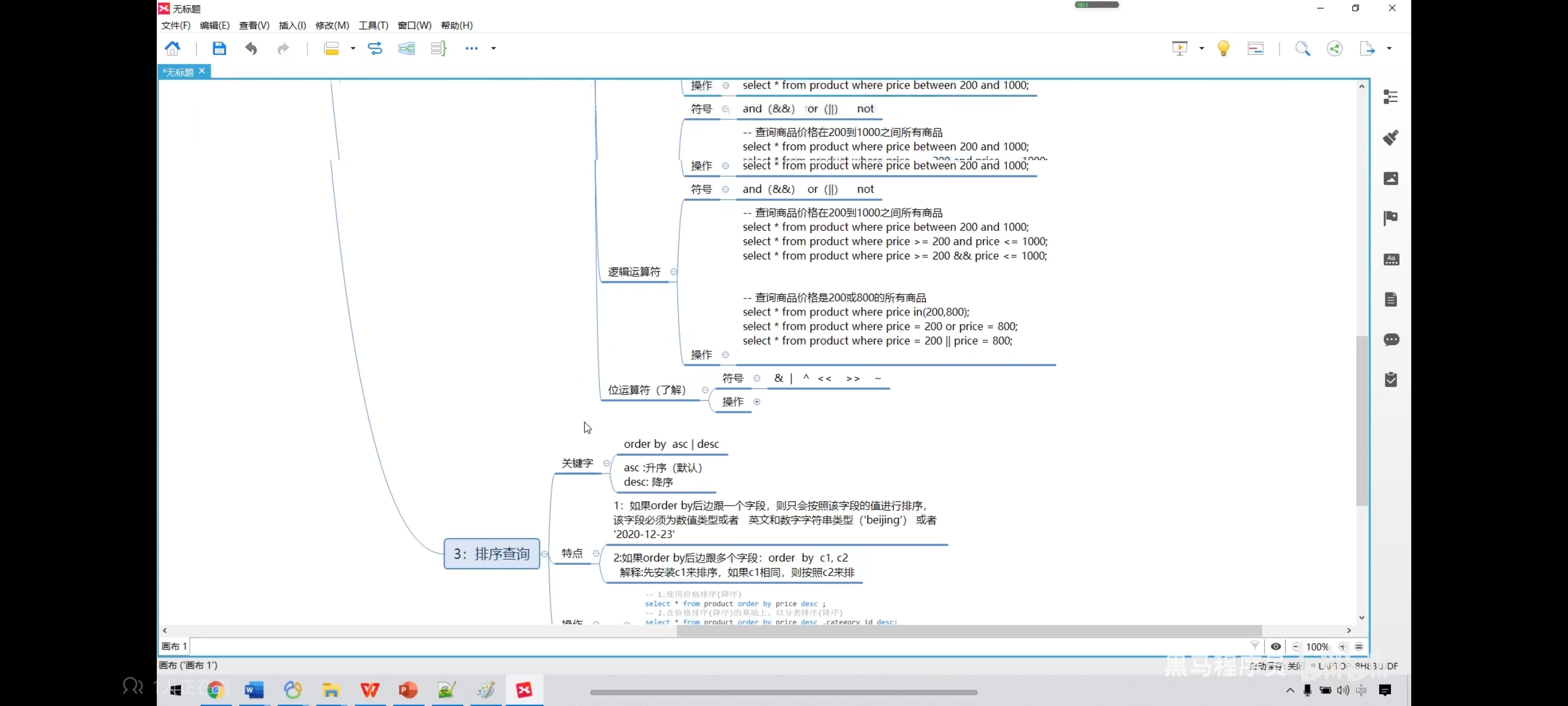
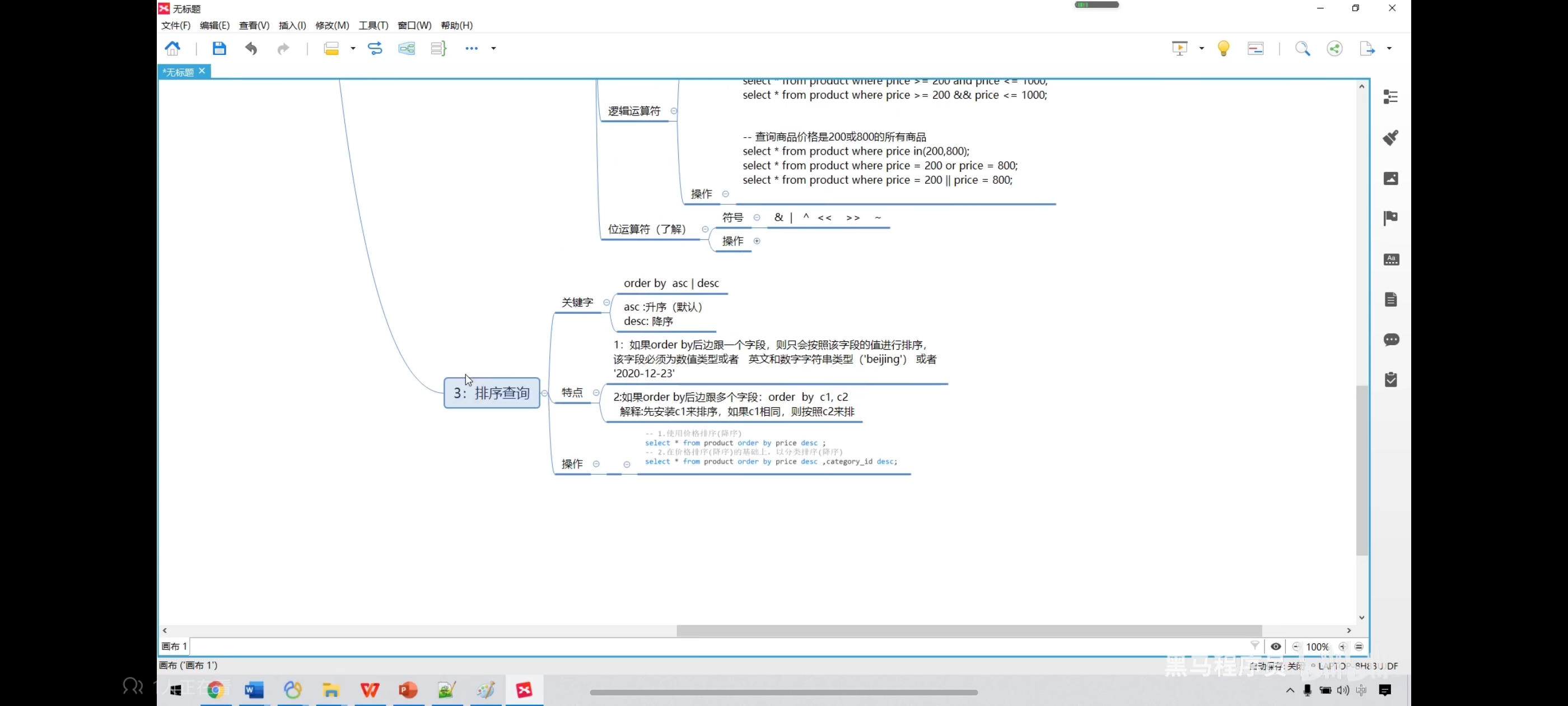
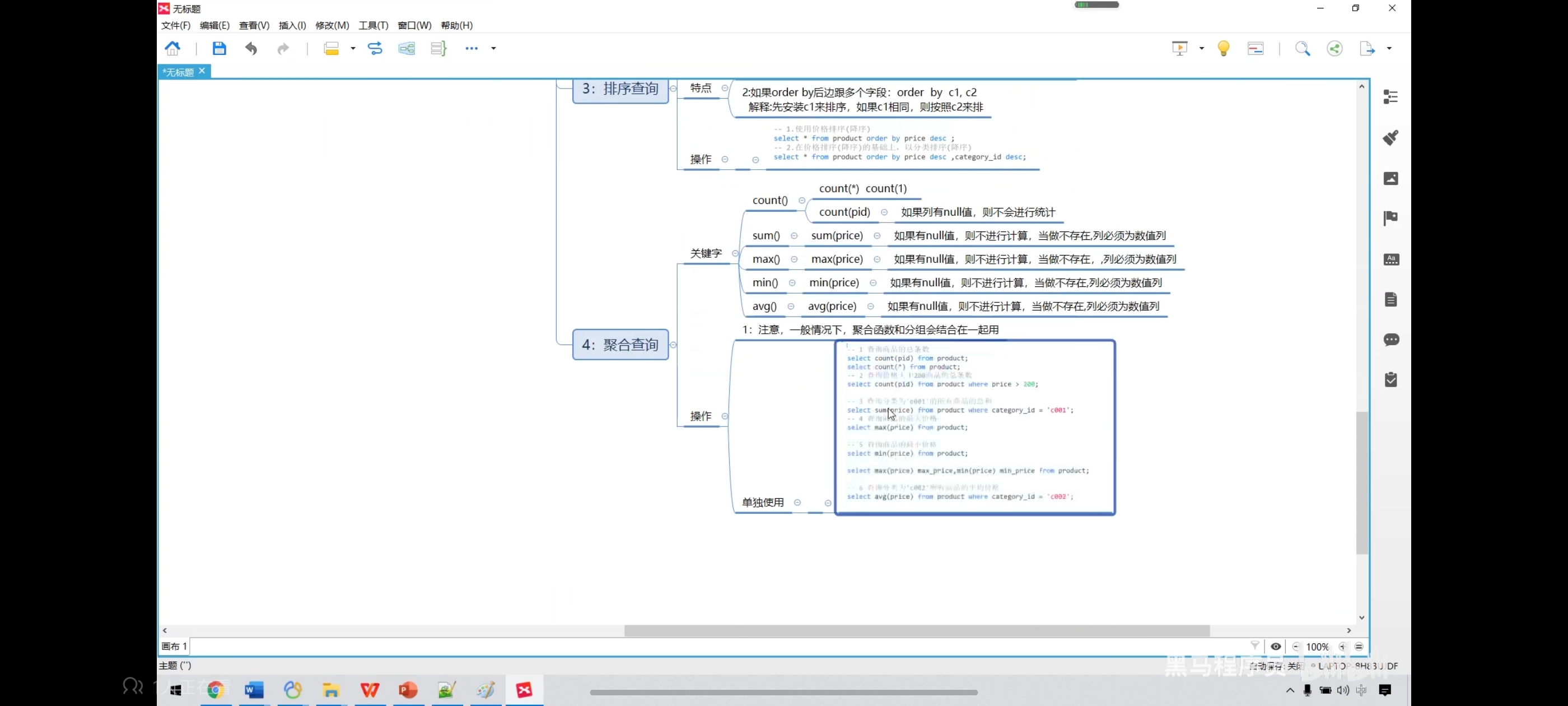
七、排序查询
写去重排序时记得只写一个字段名,如果写好几个就可能会导致无法一一对应。
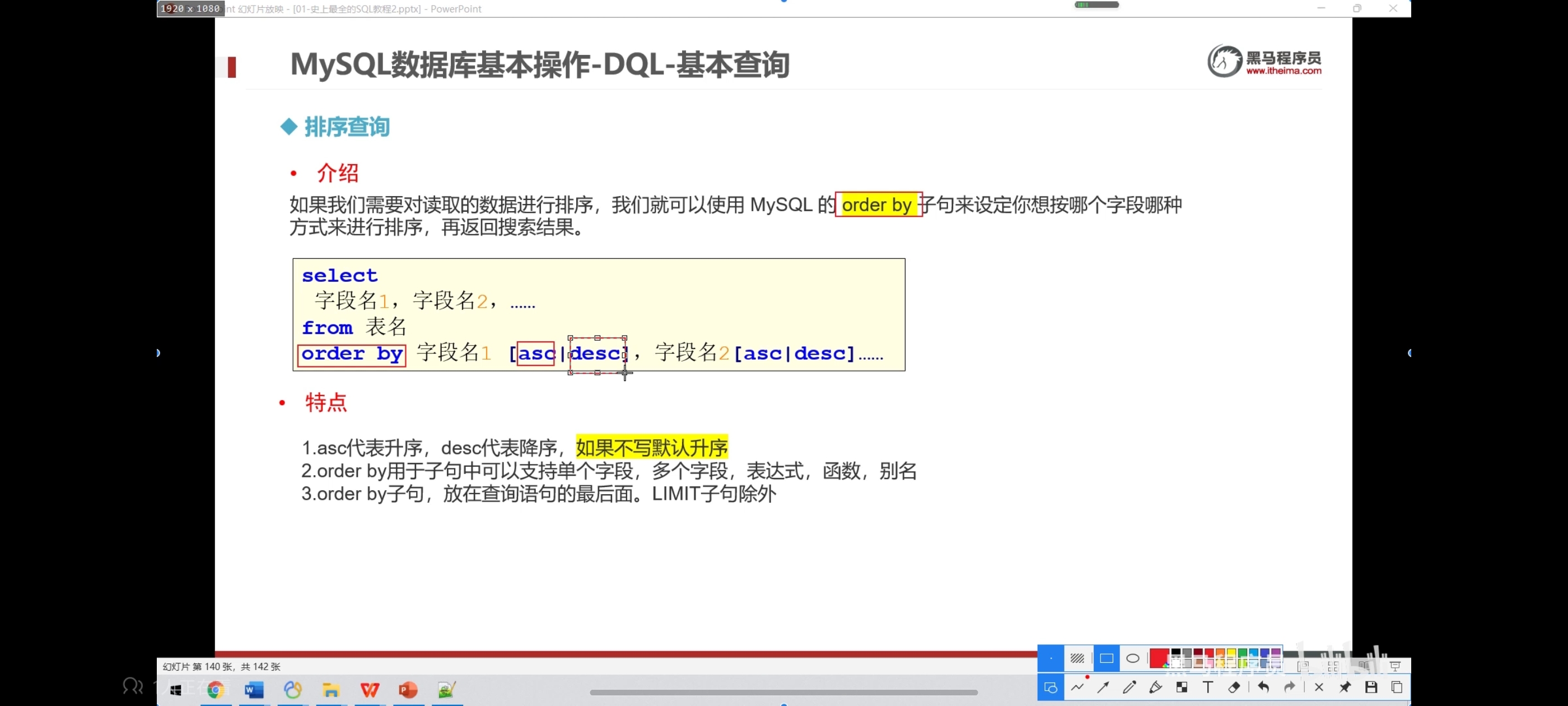
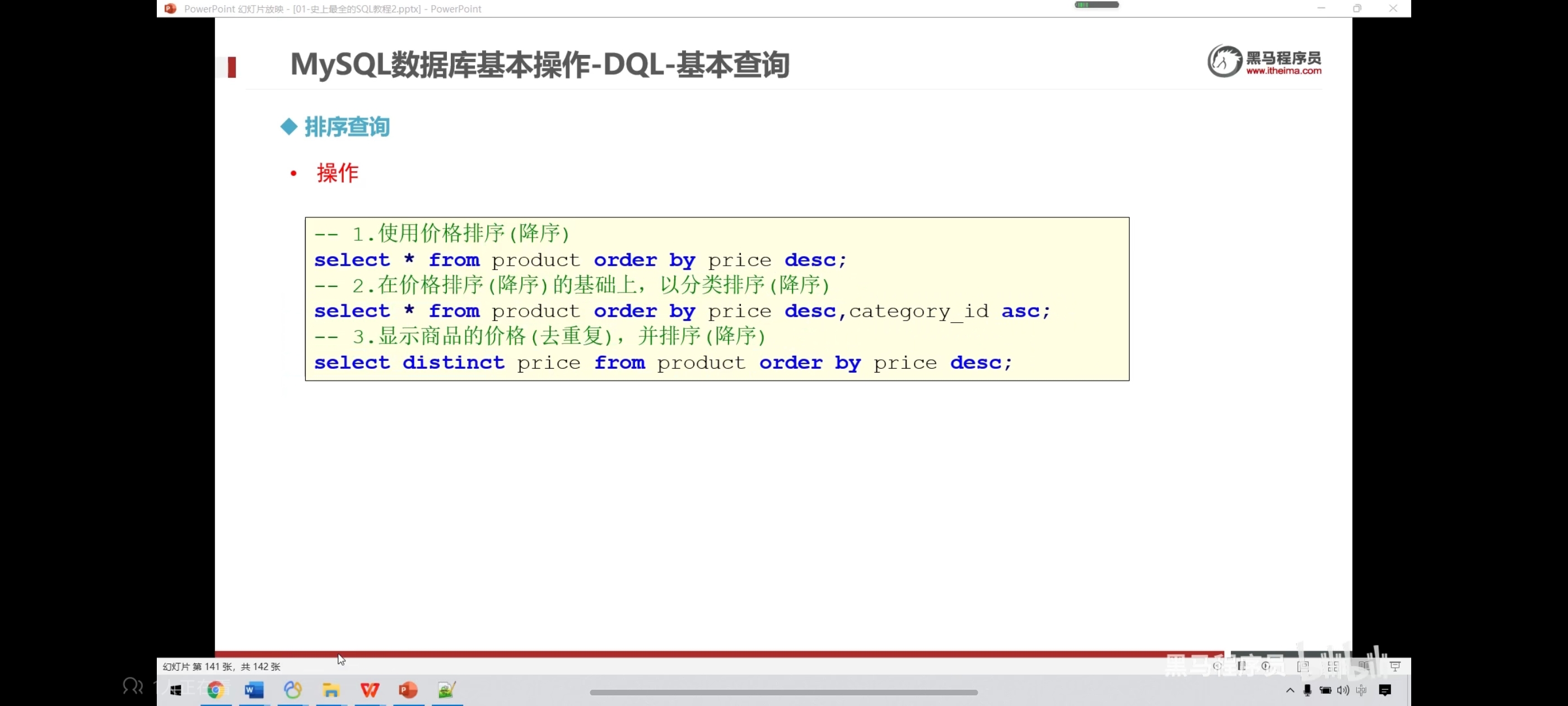
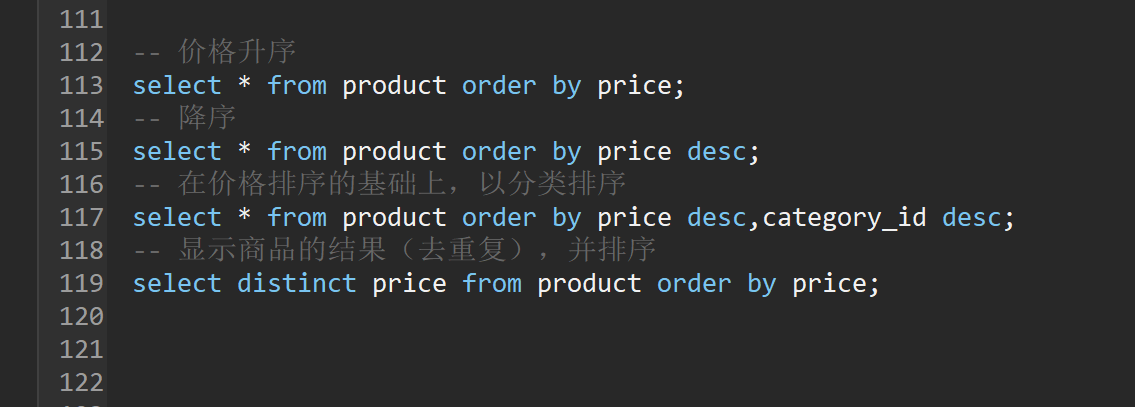
-- 价格升序
select * from product order by price;
-- 降序
select * from product order by price desc;
-- 在价格排序的基础上,以分类排序
select * from product order by price desc,category_id desc;
-- 显示商品的结果(去重复),并排序
select distinct price from product order by price;
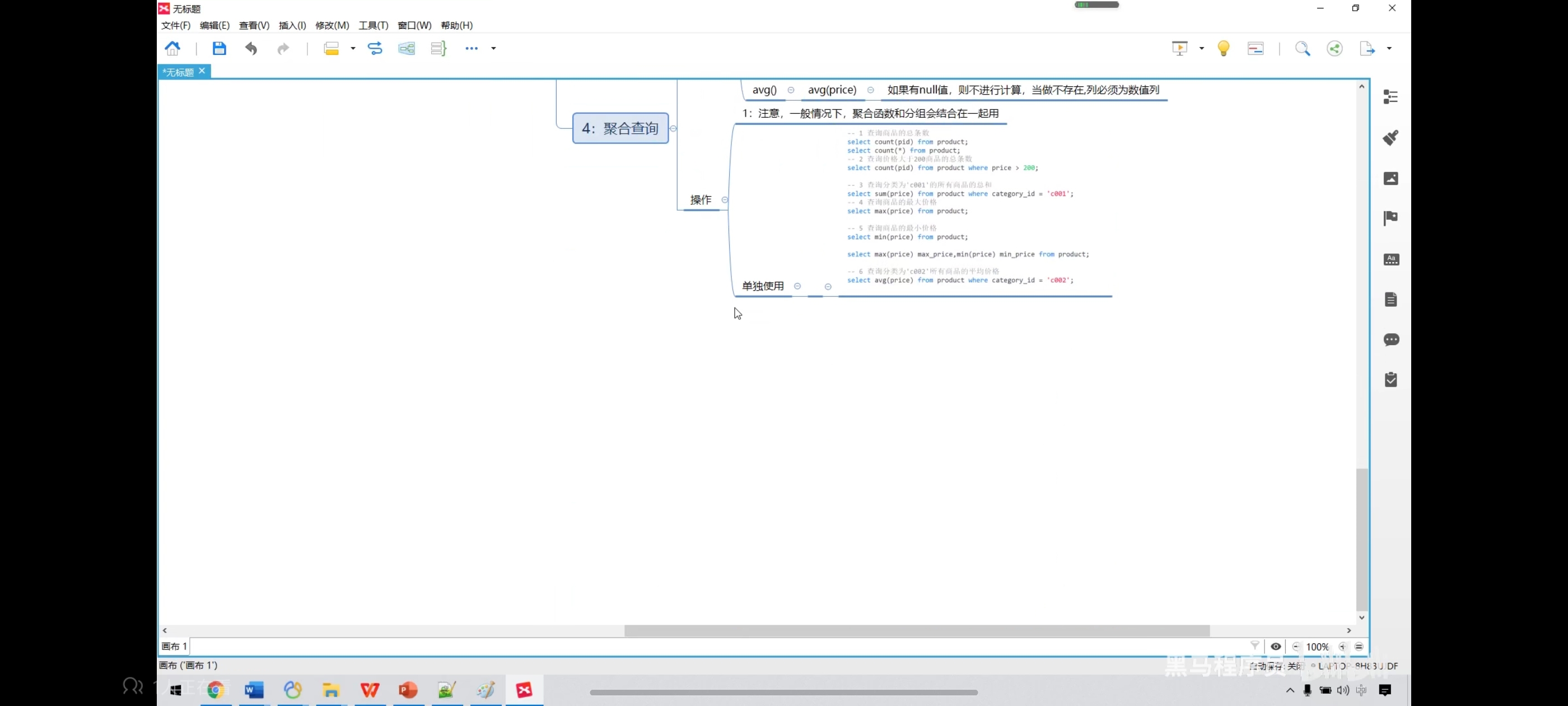
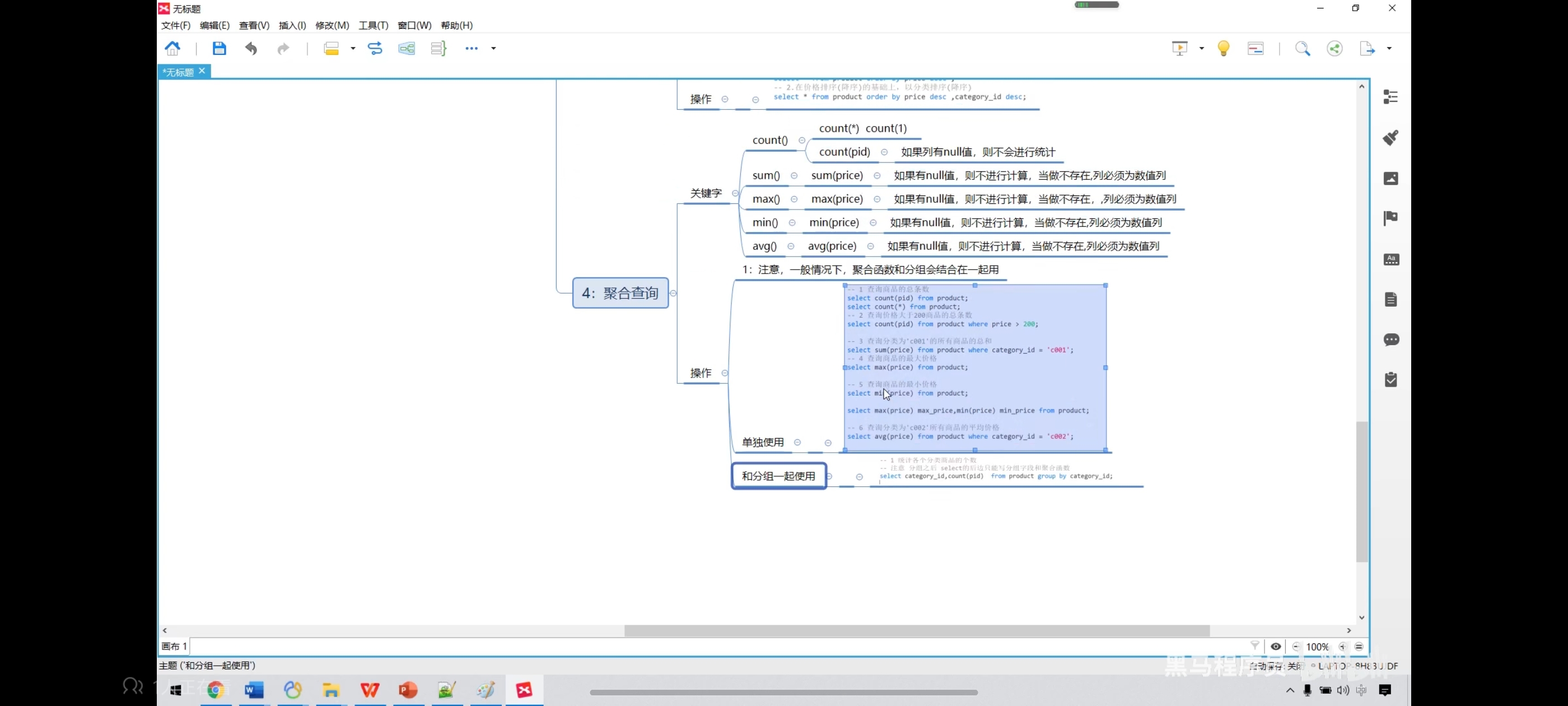
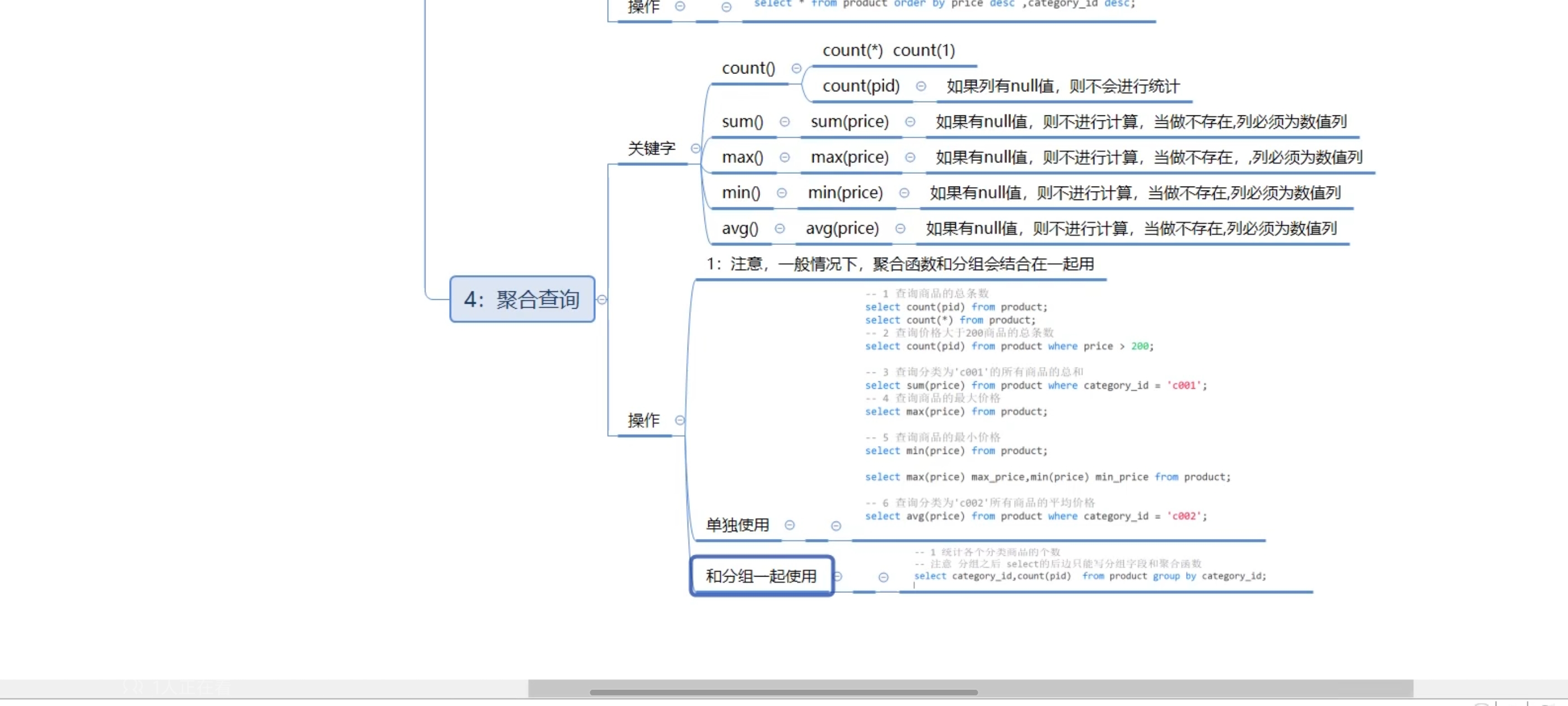
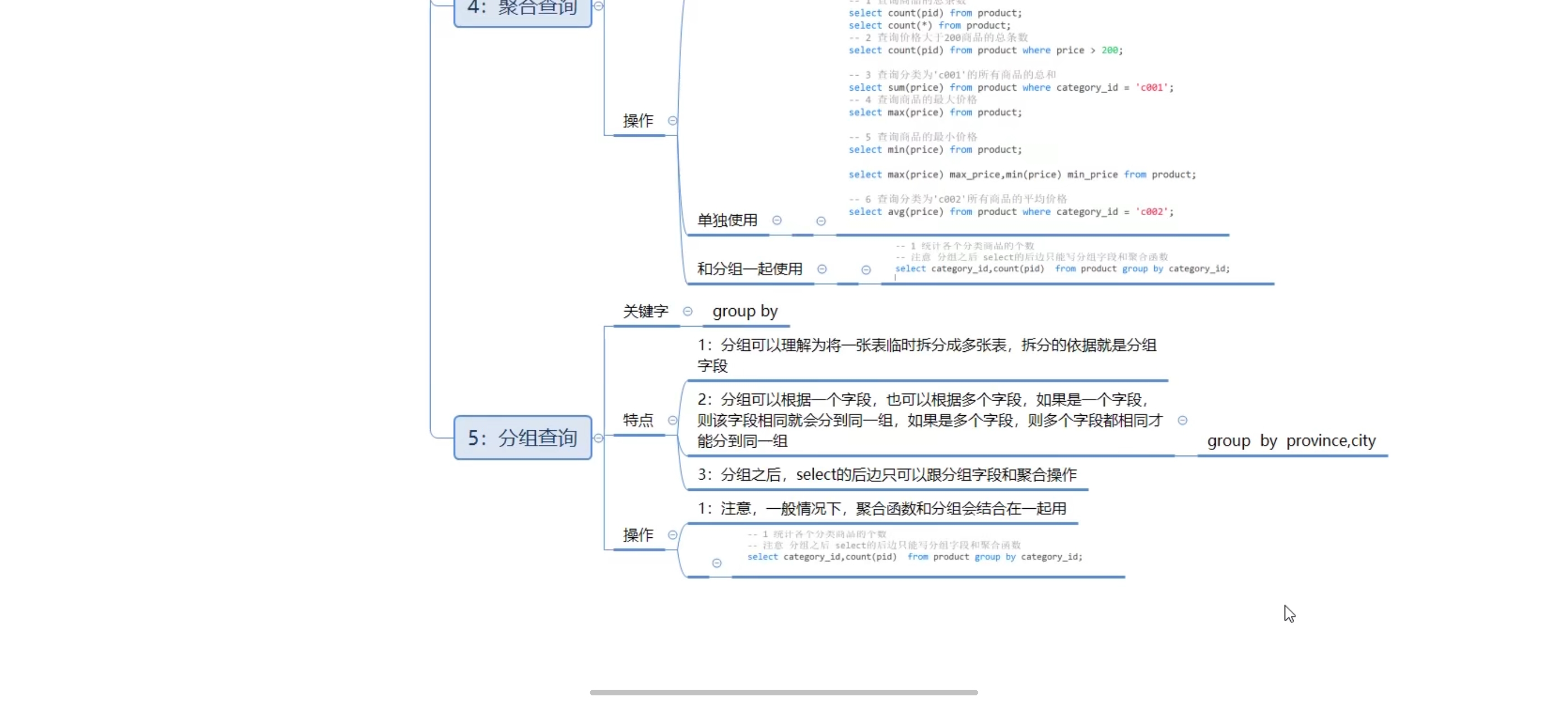
八、聚合查询
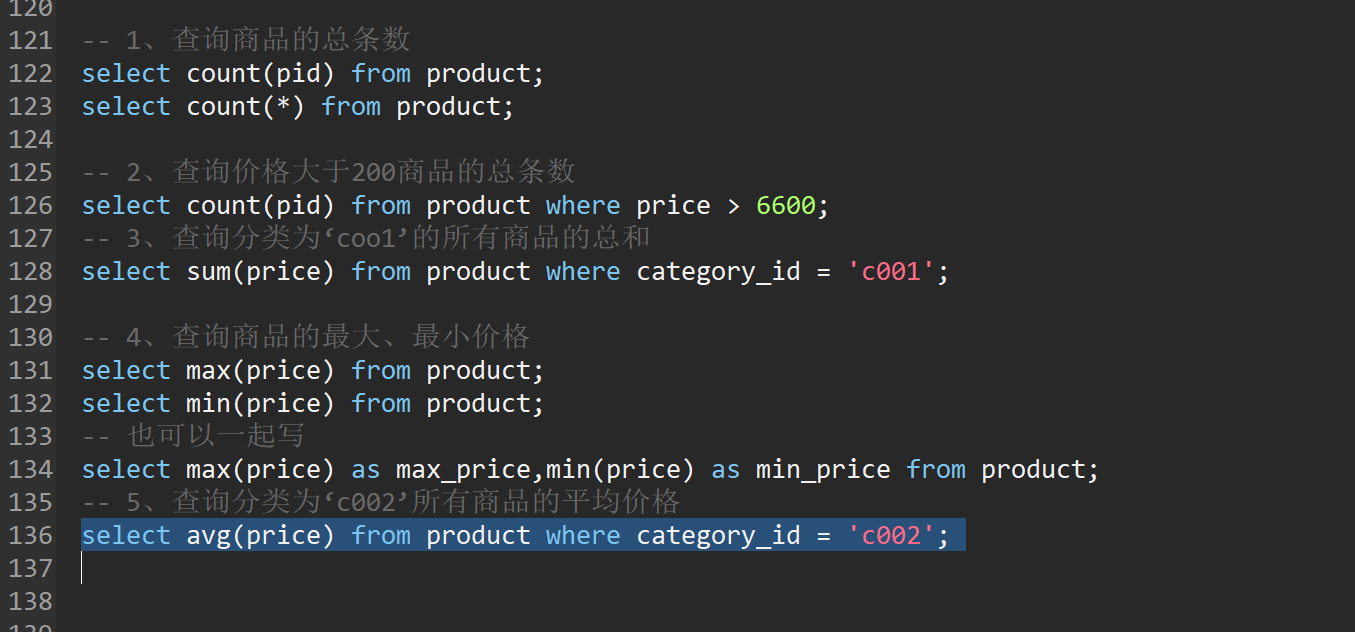
-- 1、查询商品的总条数
select count(pid) from product;
select count(*) from product;
-- 2、查询价格大于200商品的总条数
select count(pid) from product where price > 6600;
-- 3、查询分类为‘coo1’的所有商品的总和
select sum(price) from product where category_id = 'c001';
-- 4、查询商品的最大、最小价格
select max(price) from product;
select min(price) from product;
-- 也可以一起写
select max(price) as max_price,min(price) as min_price from product;
-- 5、查询分类为‘c002’所有商品的平均价格
select avg(price) from product where category_id = 'c002';
九、聚合查询-null值处理
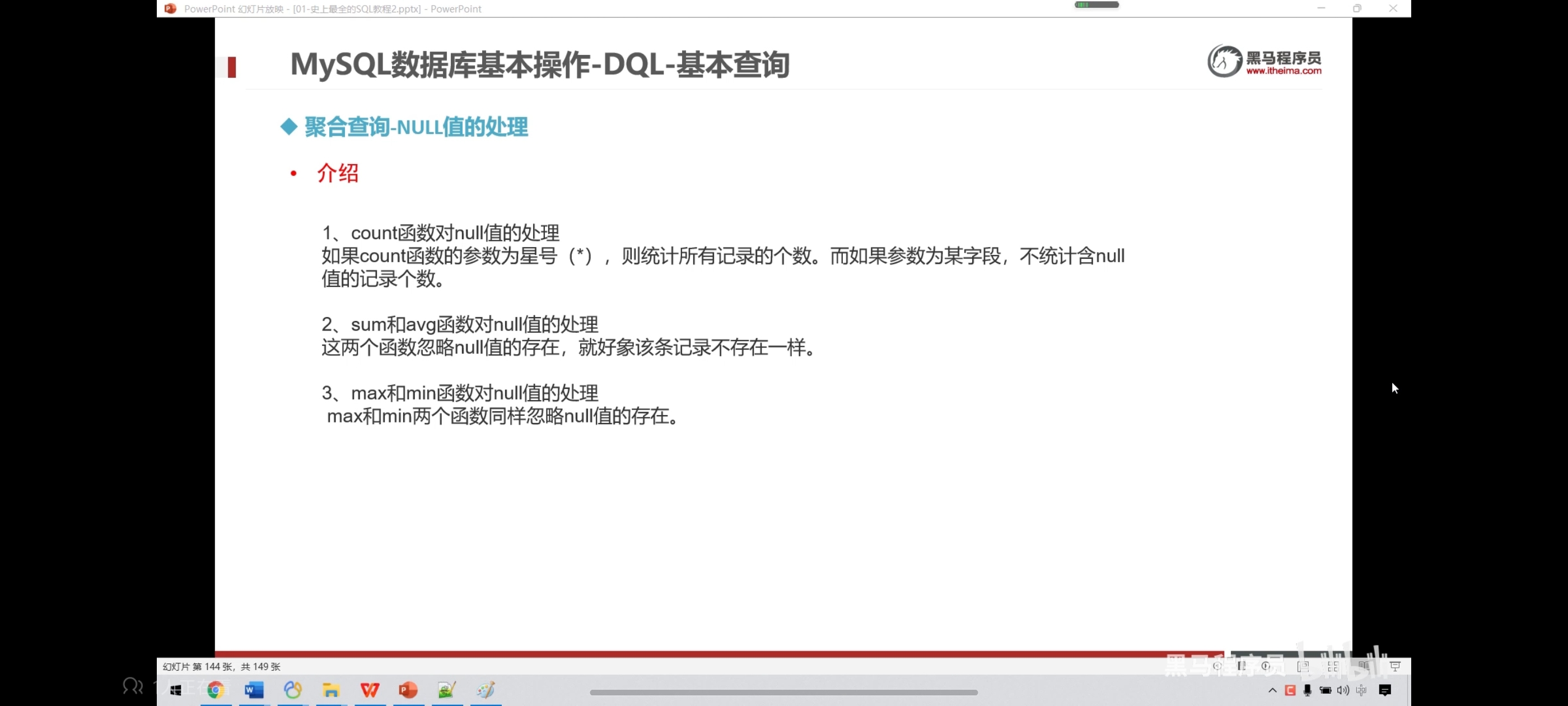
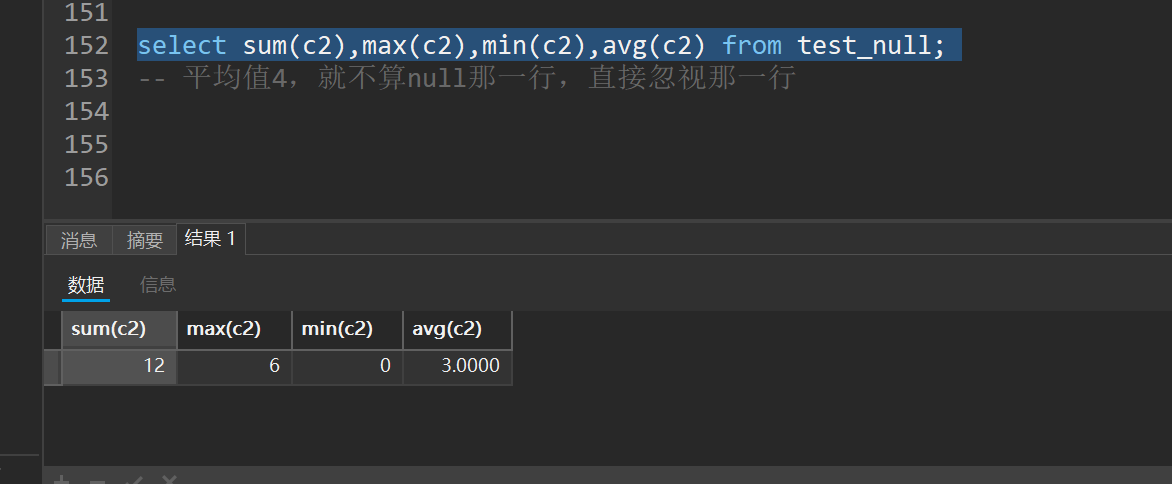
聚合查询里面都忽视null

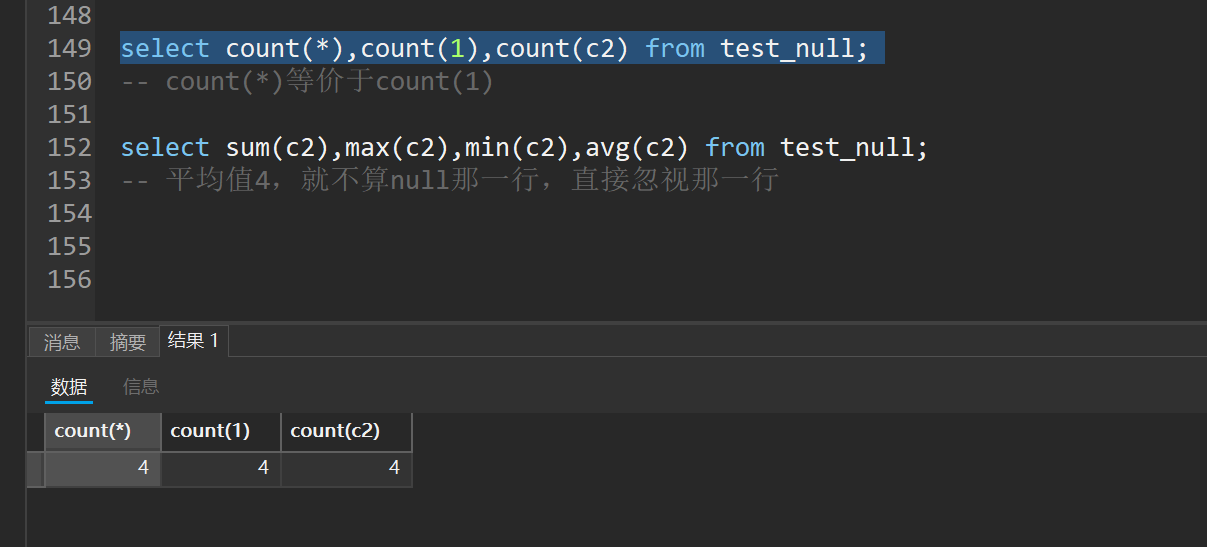
count(*) 和 count(1)等价
如果想处理null,可以把他初始化为0,这样就不影响聚合查询了
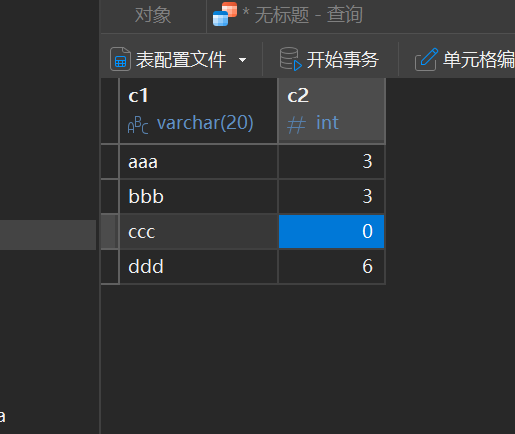
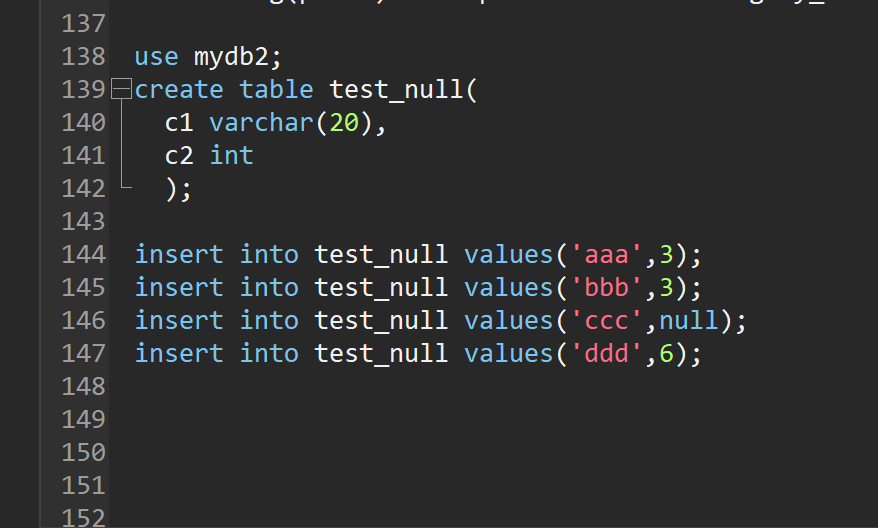
use mydb2;
create table test_null(
c1 varchar(20),
c2 int
);
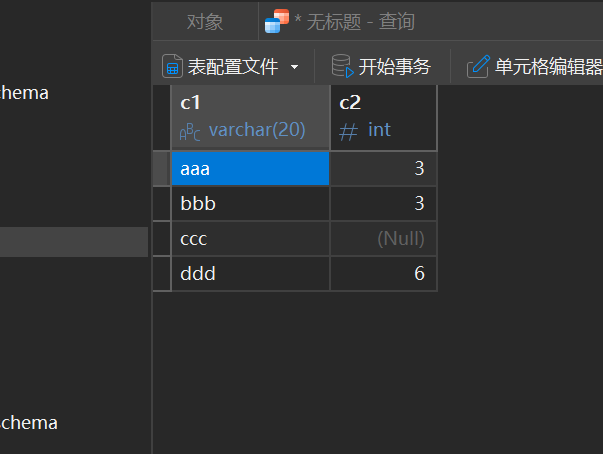
insert into test_null values('aaa',3);
insert into test_null values('bbb',3);
insert into test_null values('ccc',null);
insert into test_null values('ddd',6);
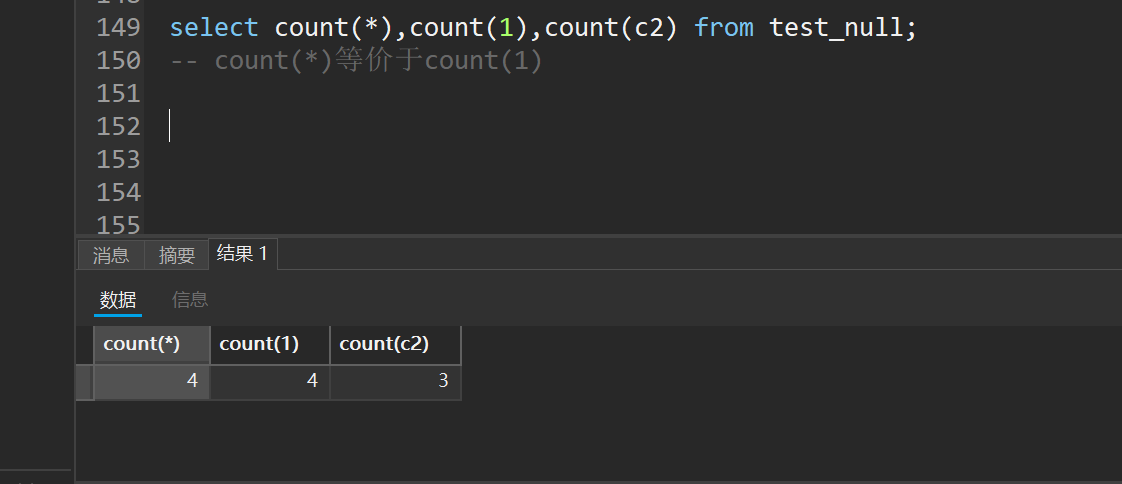
select count(*),count(1),count(c2) from test_null;
-- count(*)等价于count(1)
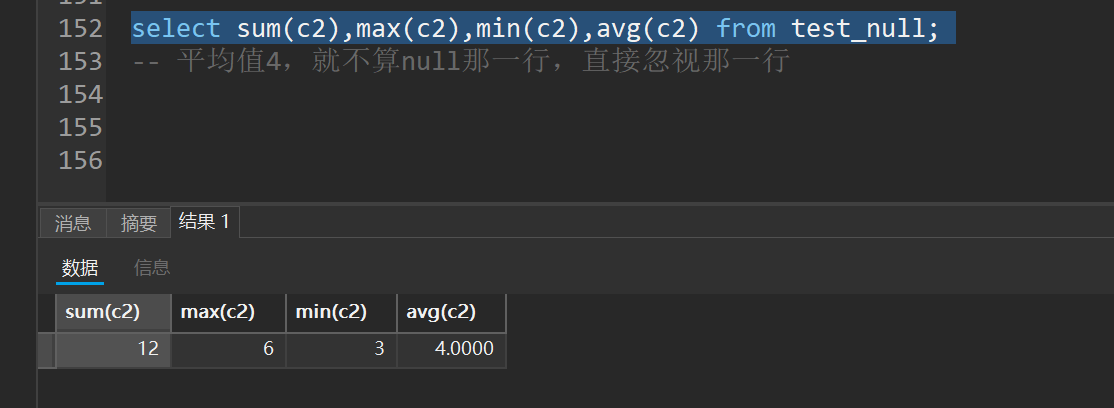
select sum(c2),max(c2),min(c2),avg(c2) from test_null;
-- 平均值4,就不算null那一行,直接忽视那一行
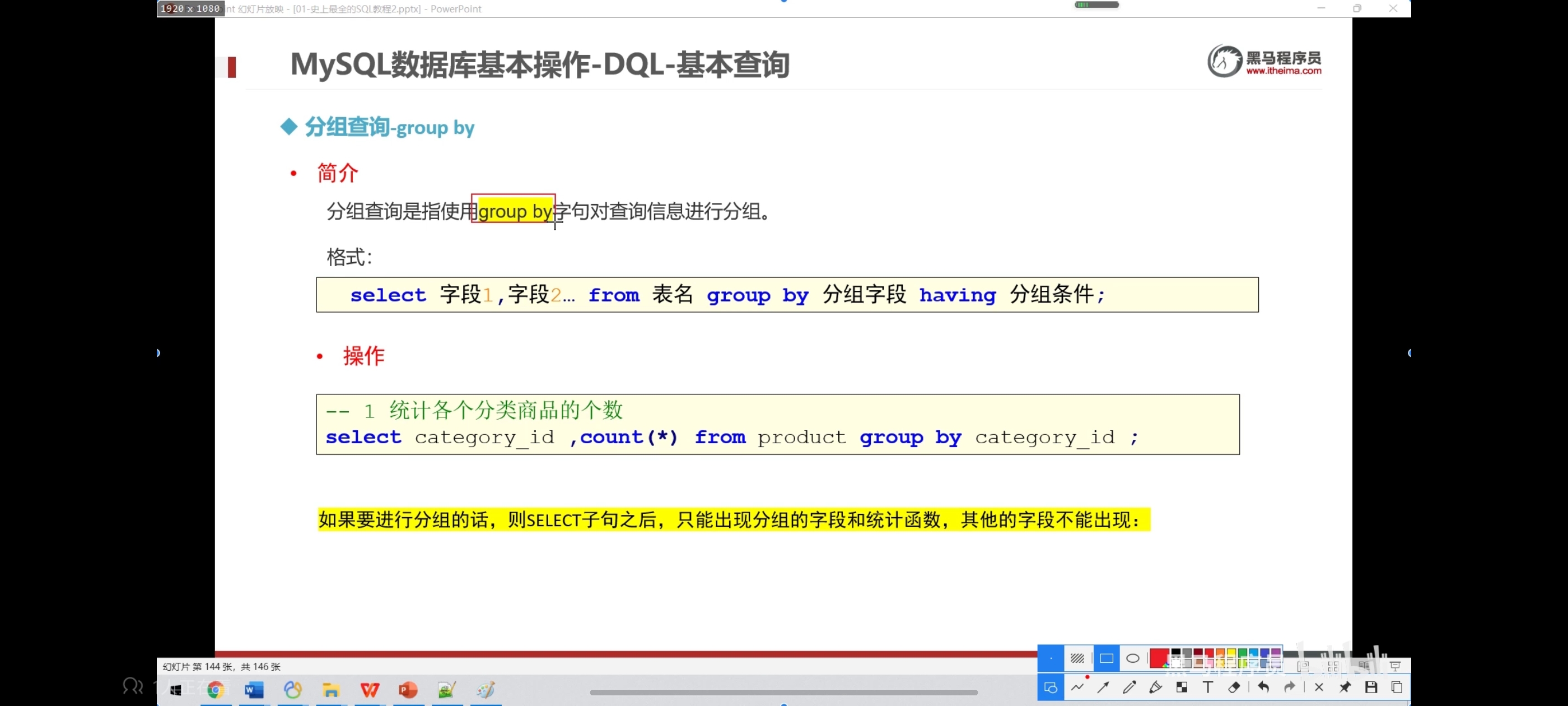
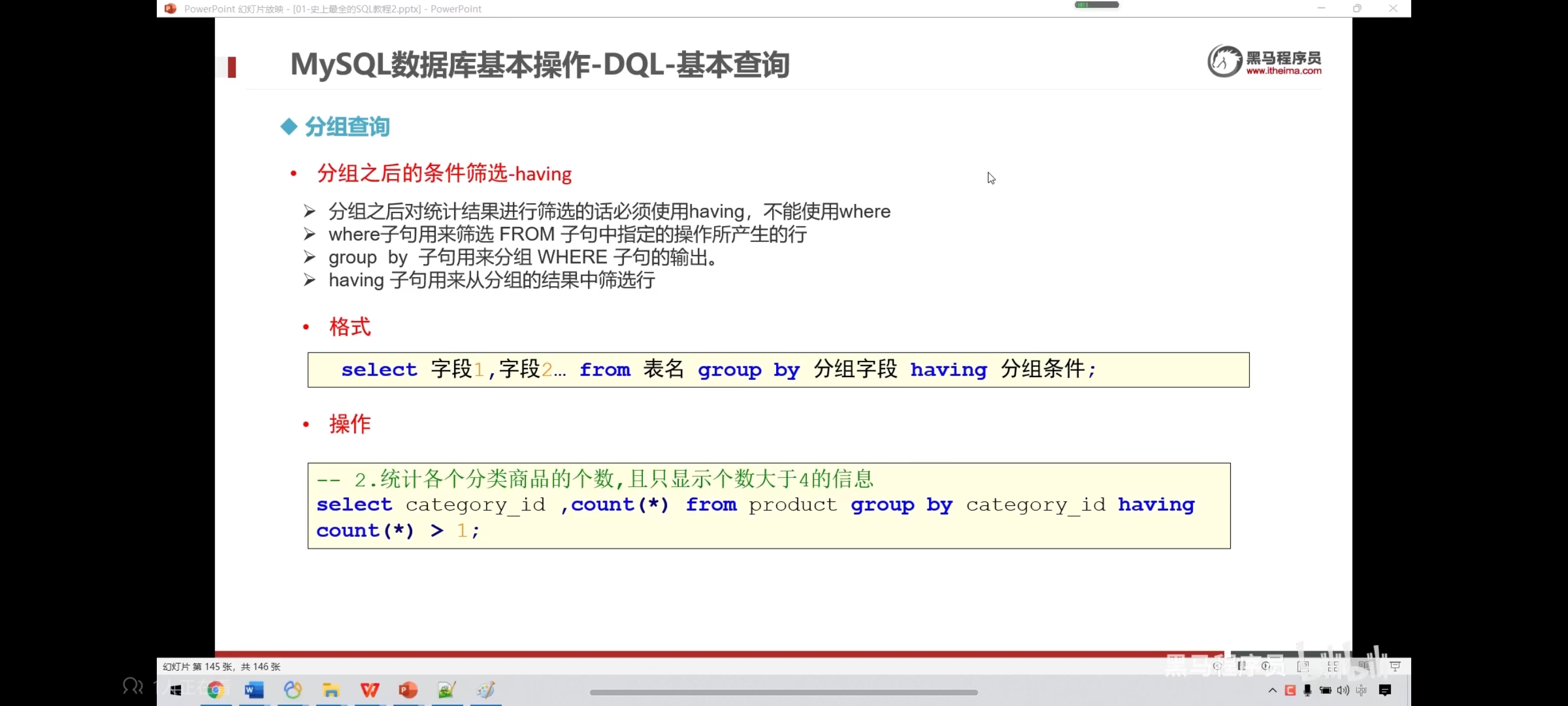
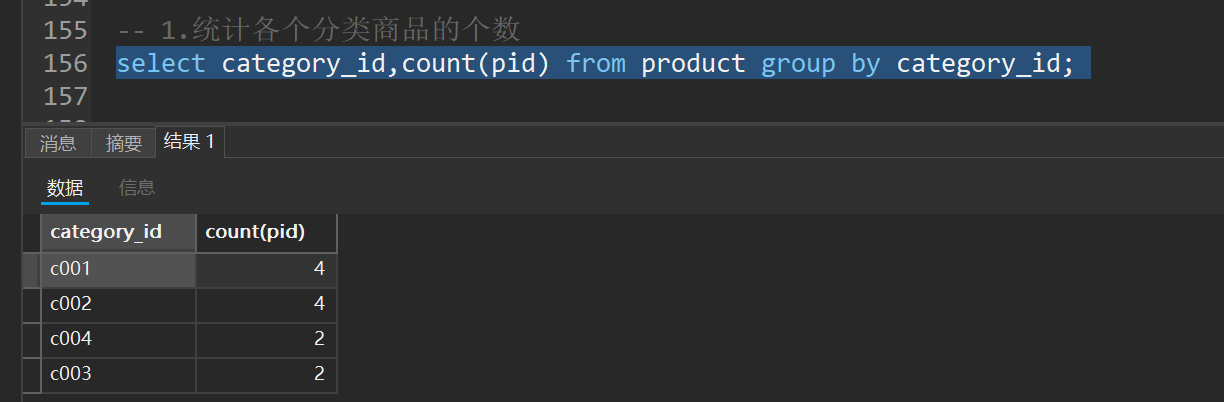
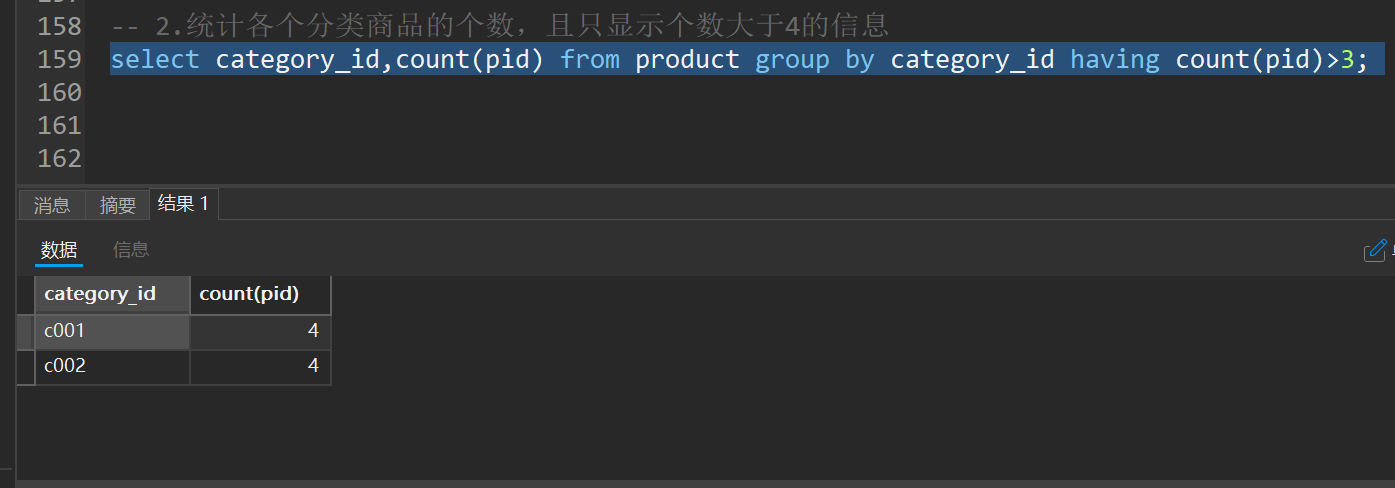
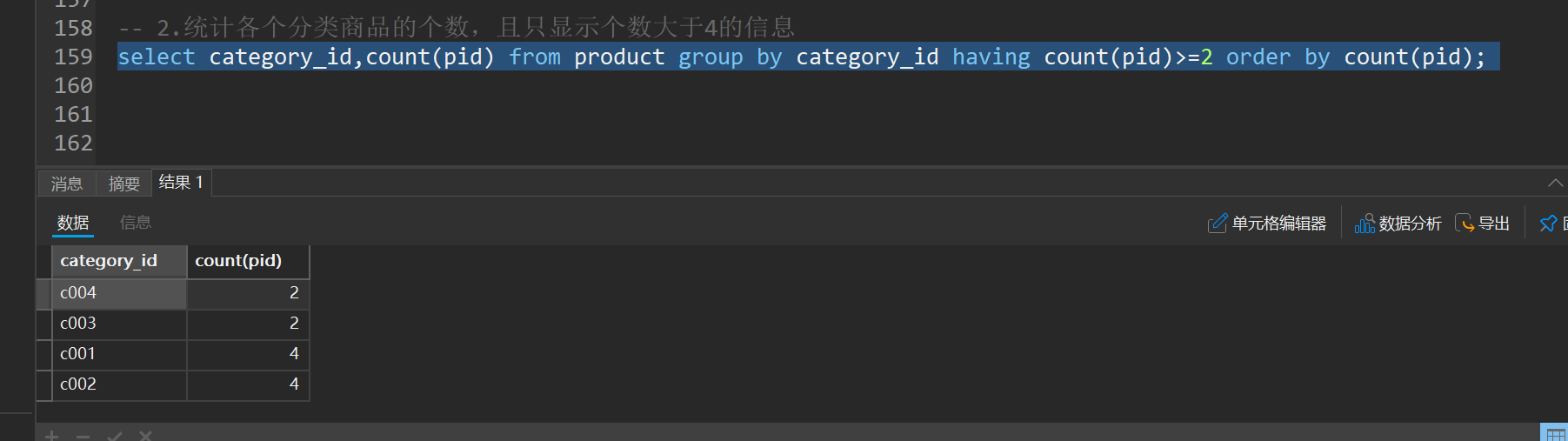
十、分组查询-group by
语法:select 字段1,字段2... from 表名 group by 分组字段 having 分租条件;
注意:分组之后select的后边只能写分组字段和聚合函数
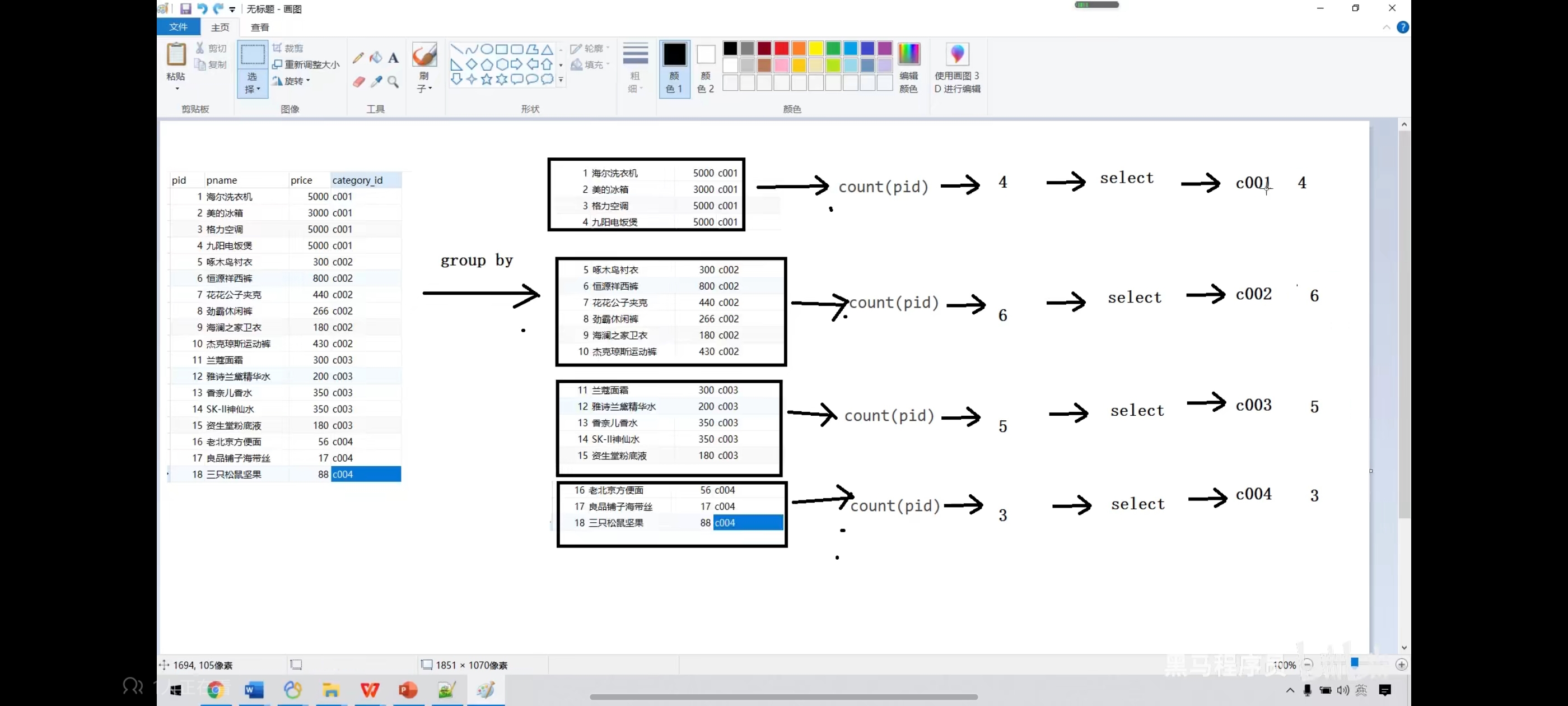
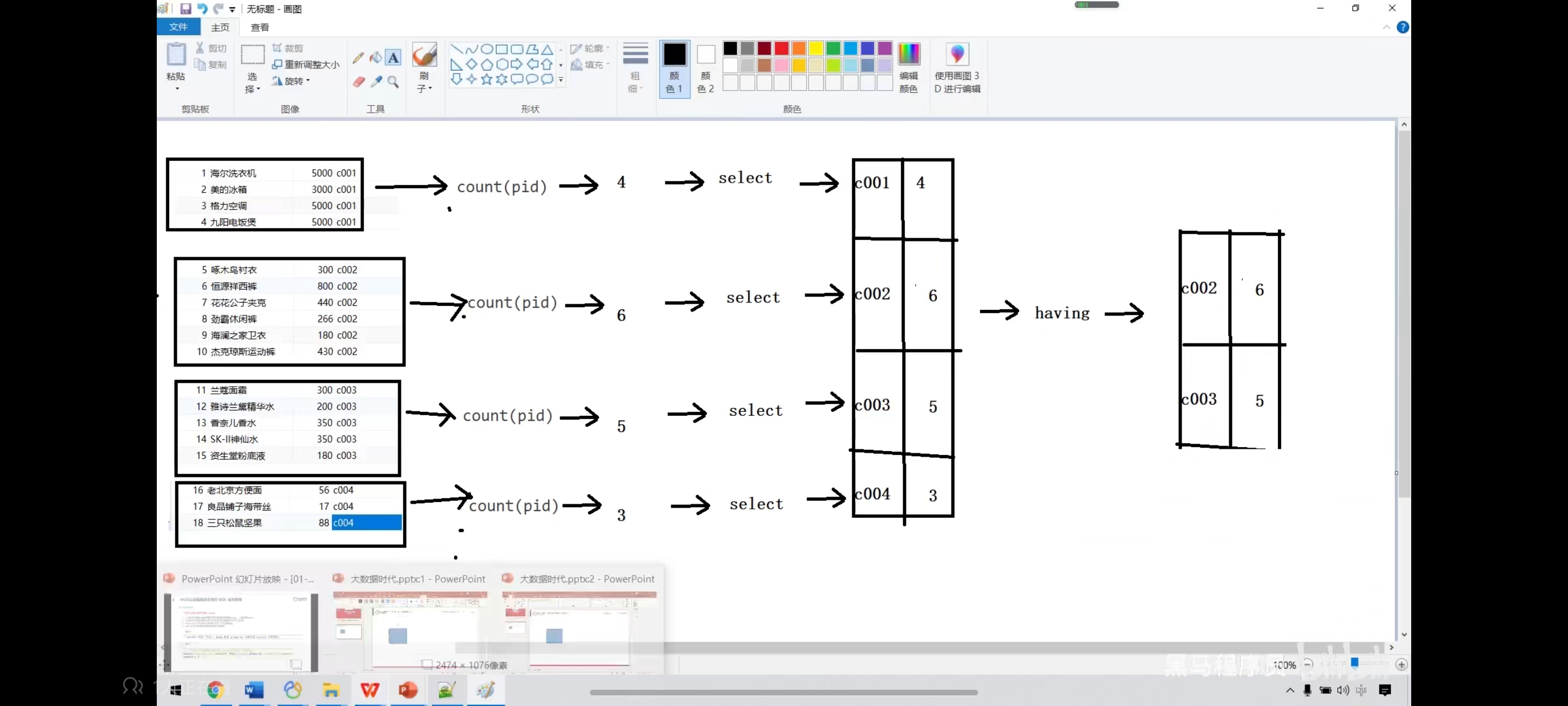
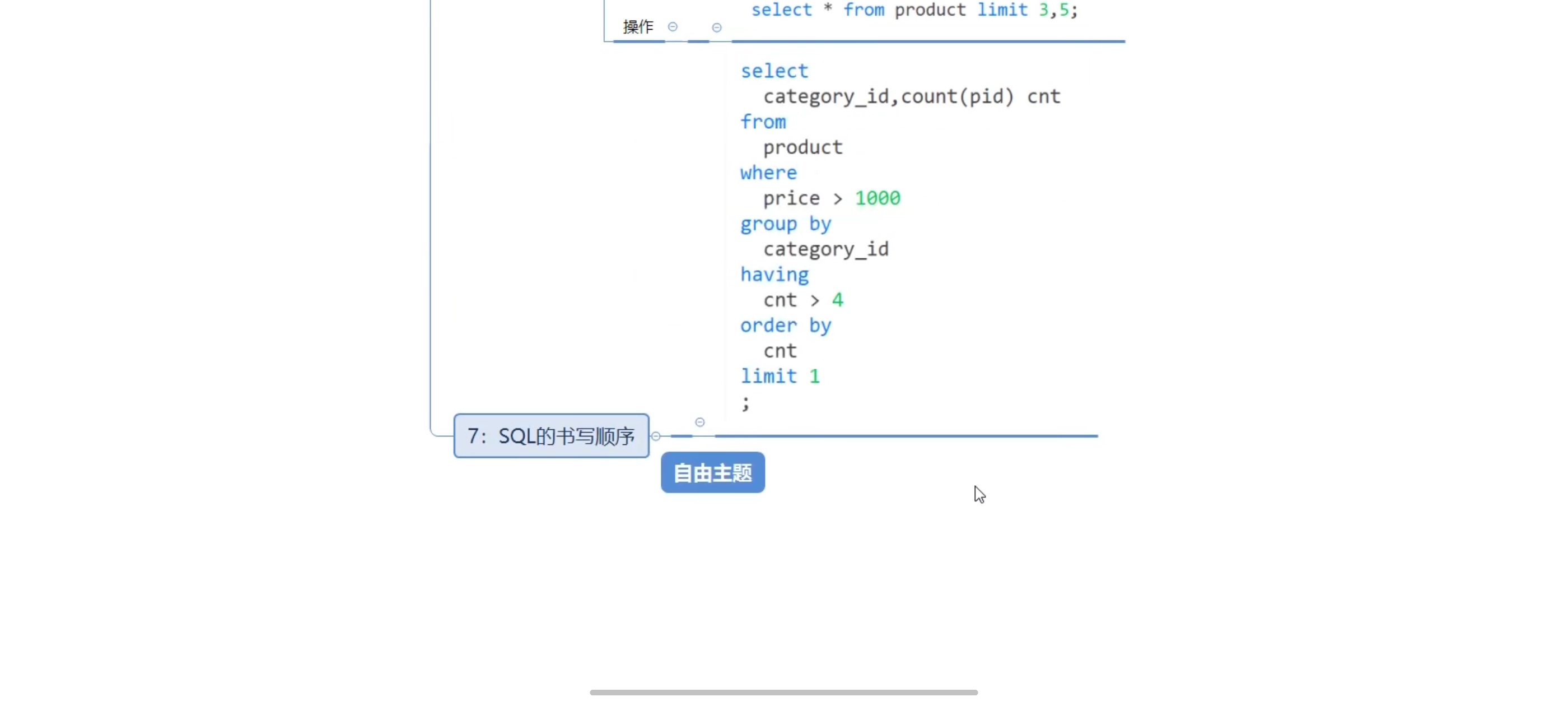
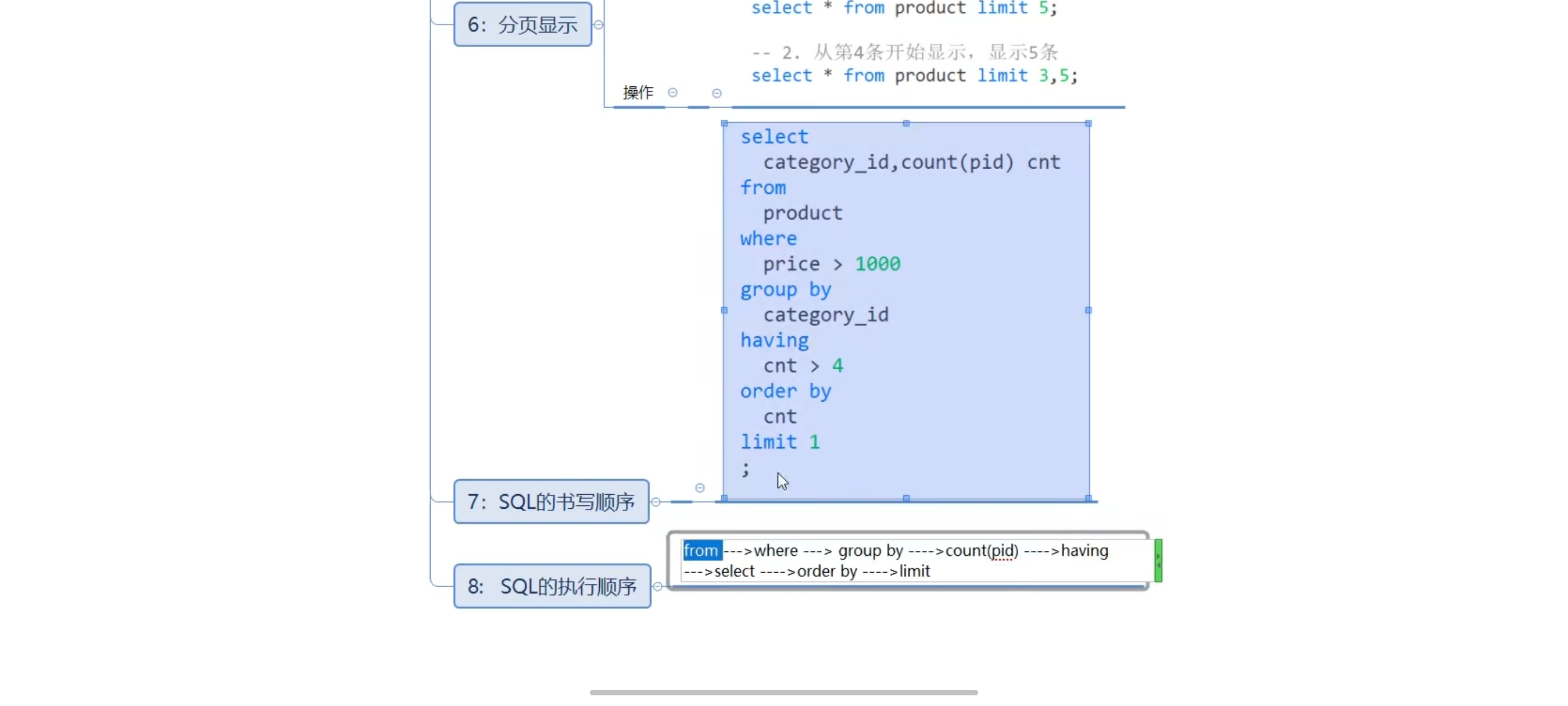
sql执行顺序:from group by count(pid) select having order by
书写顺序:from where group by having
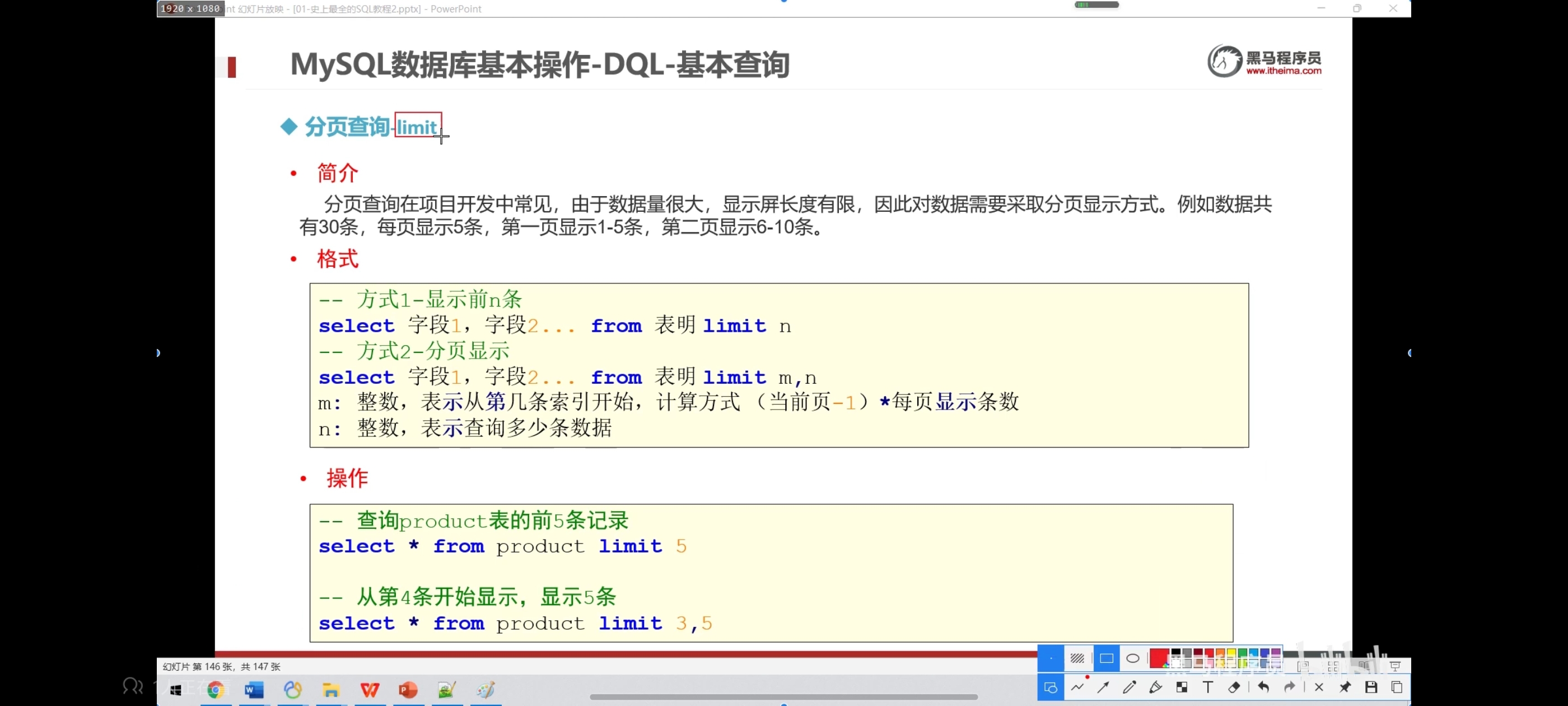
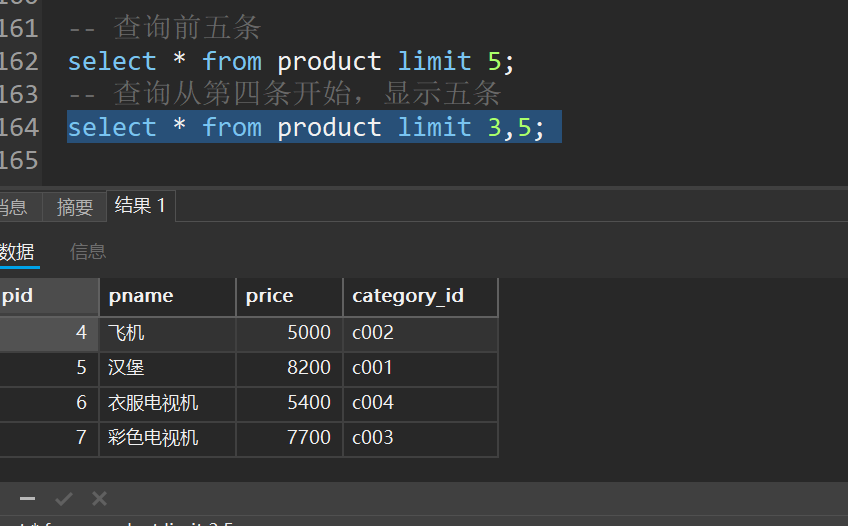
十一、分页查询-limit

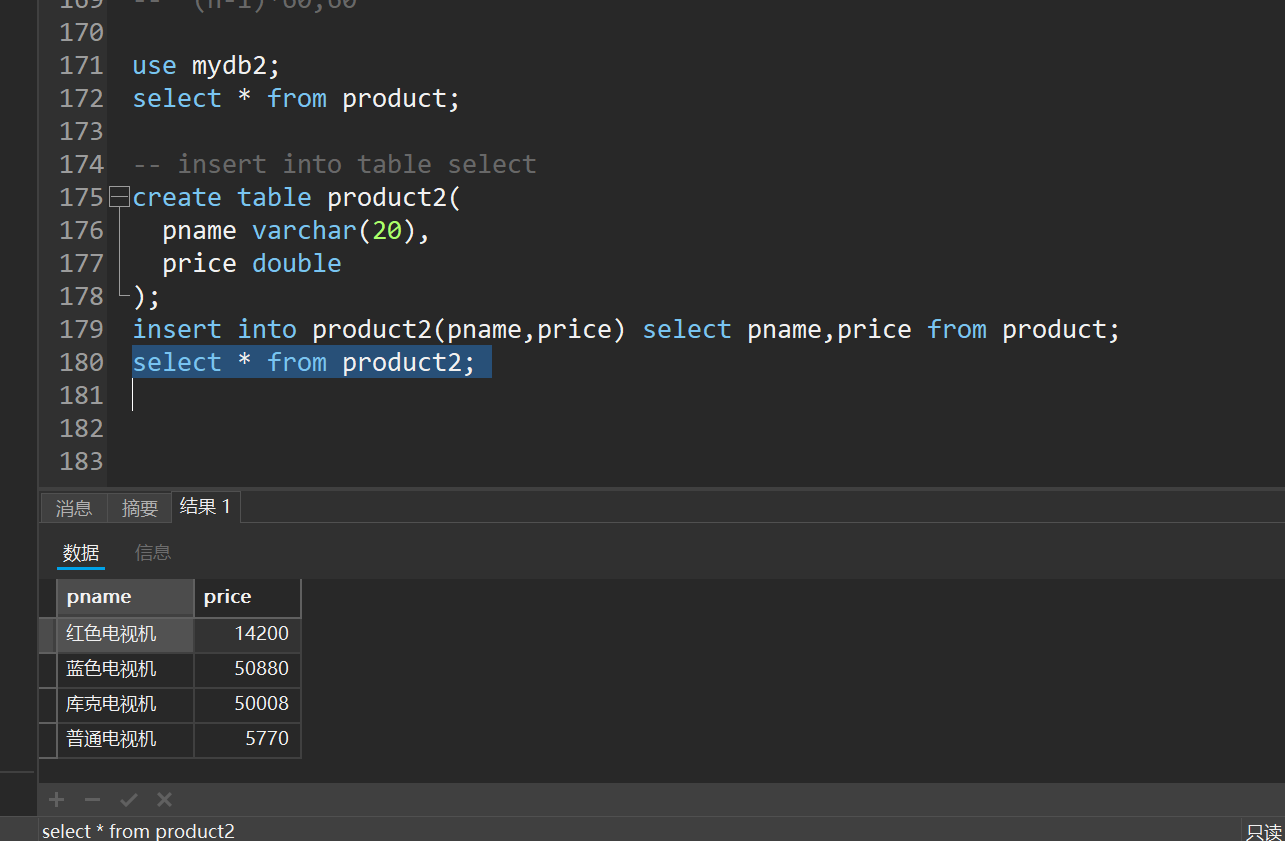
十二、insert_into_select语句
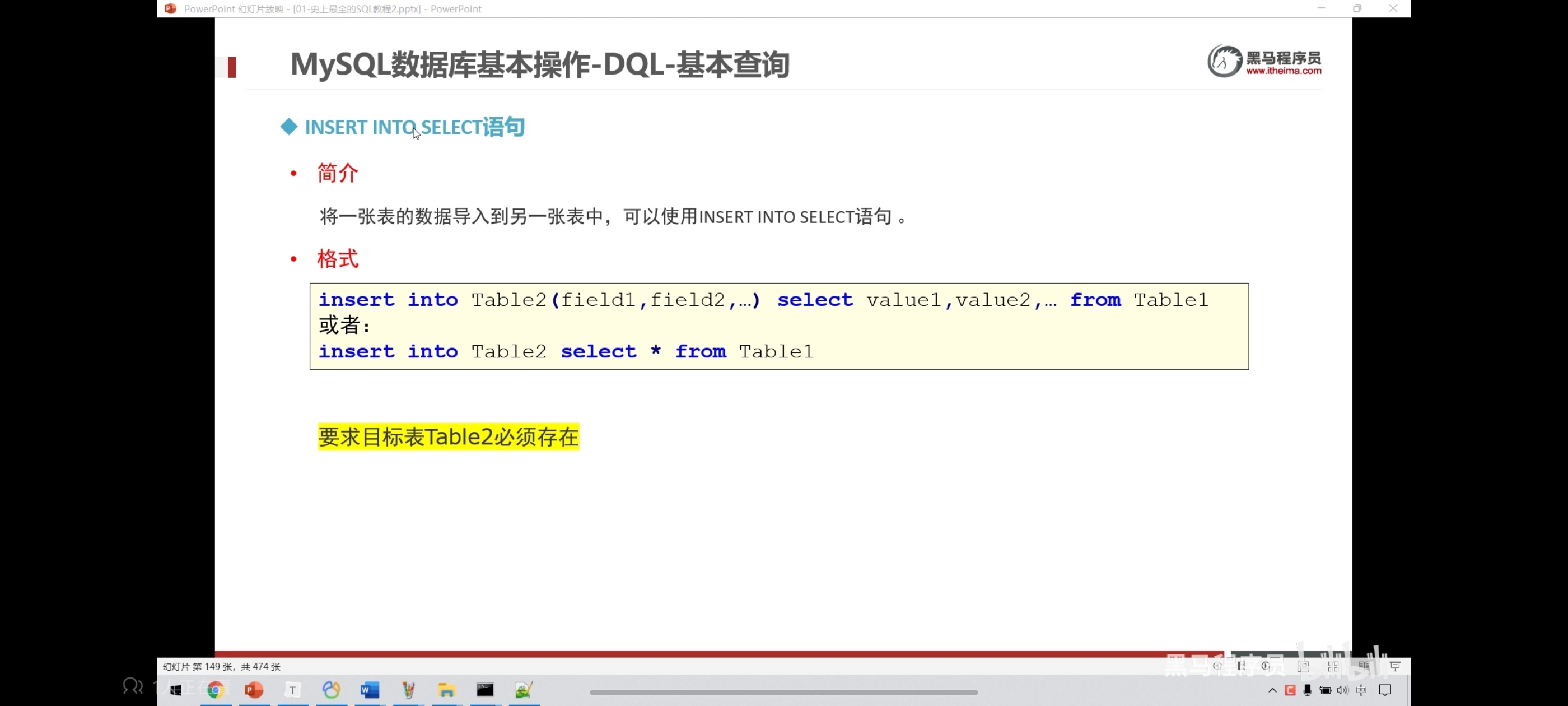
目标表必须存在
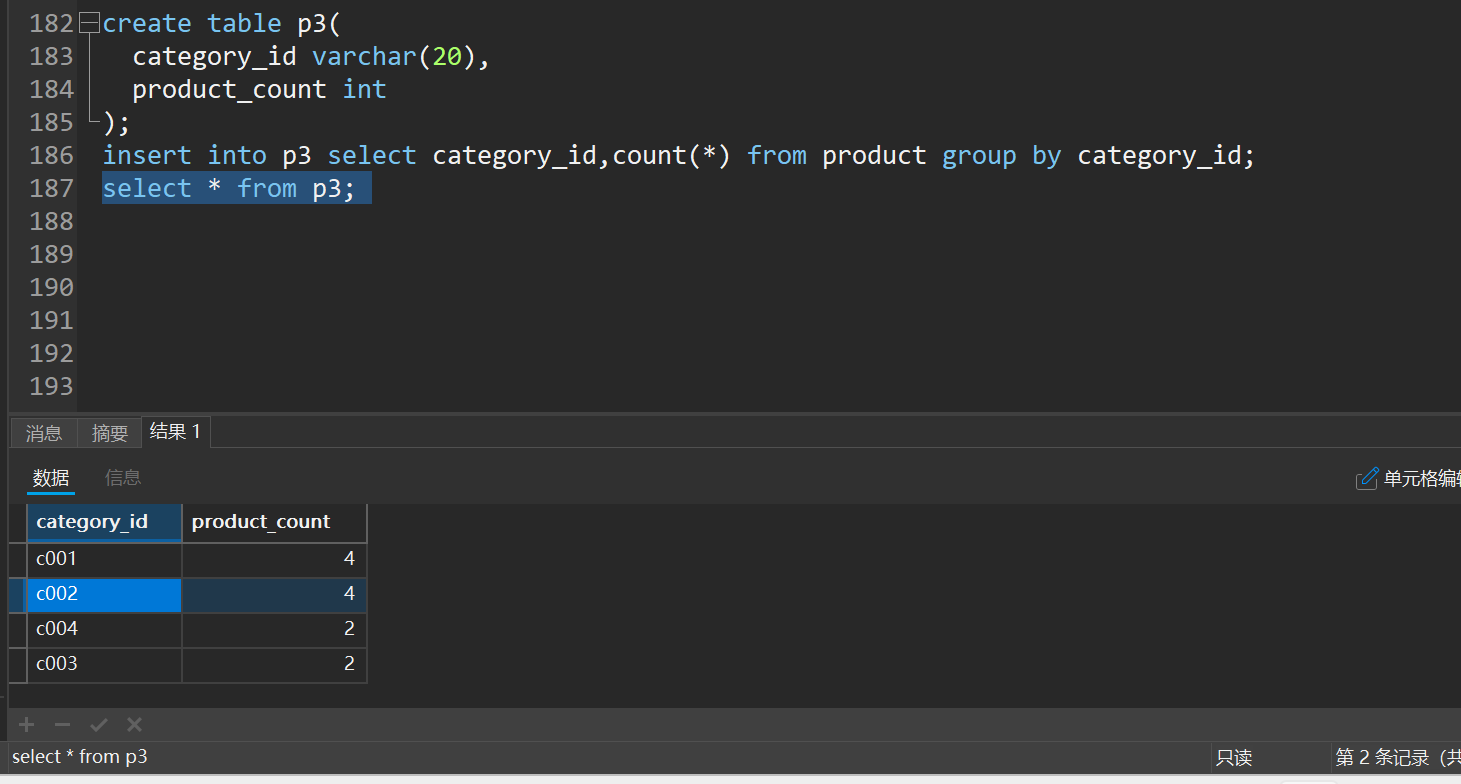
十三、总结
思维导图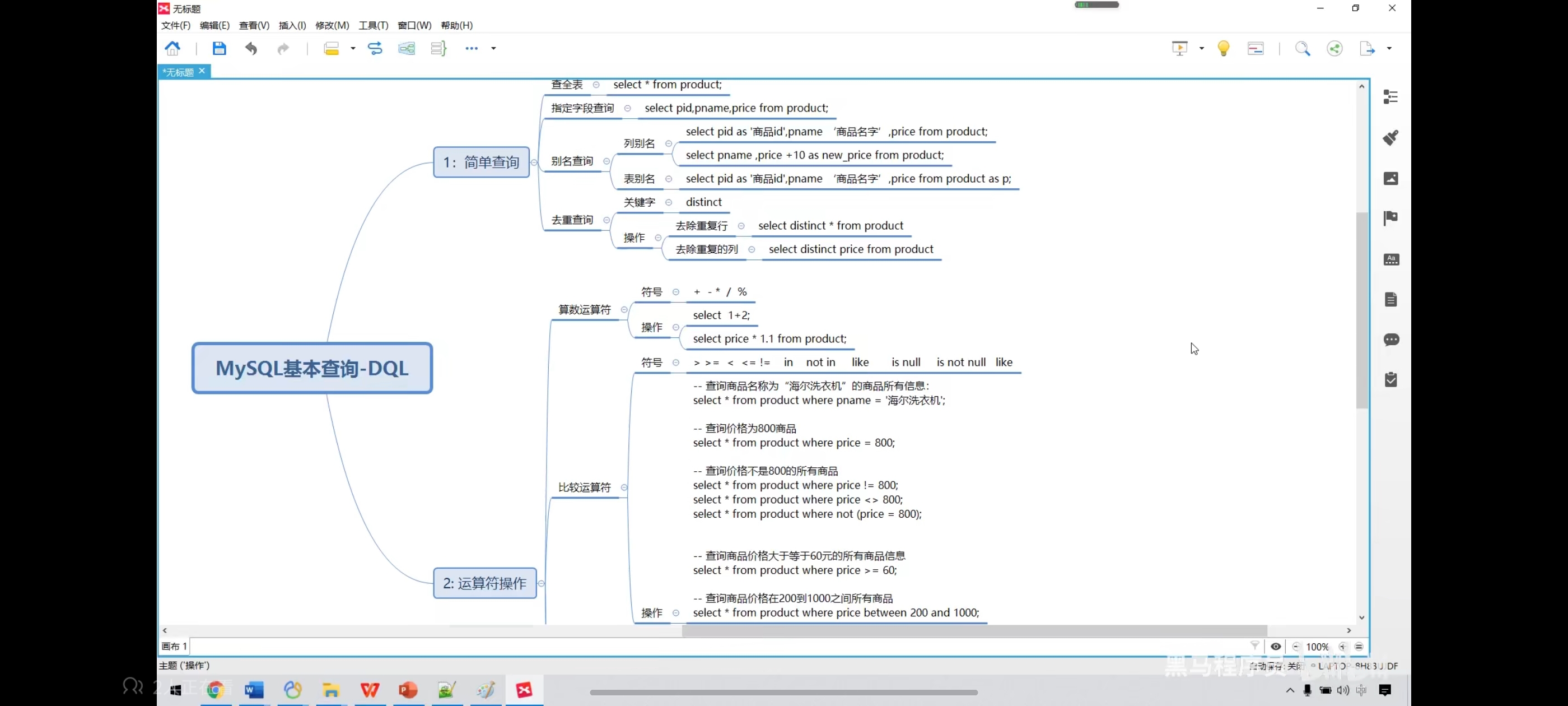


十四、练习
练习1:
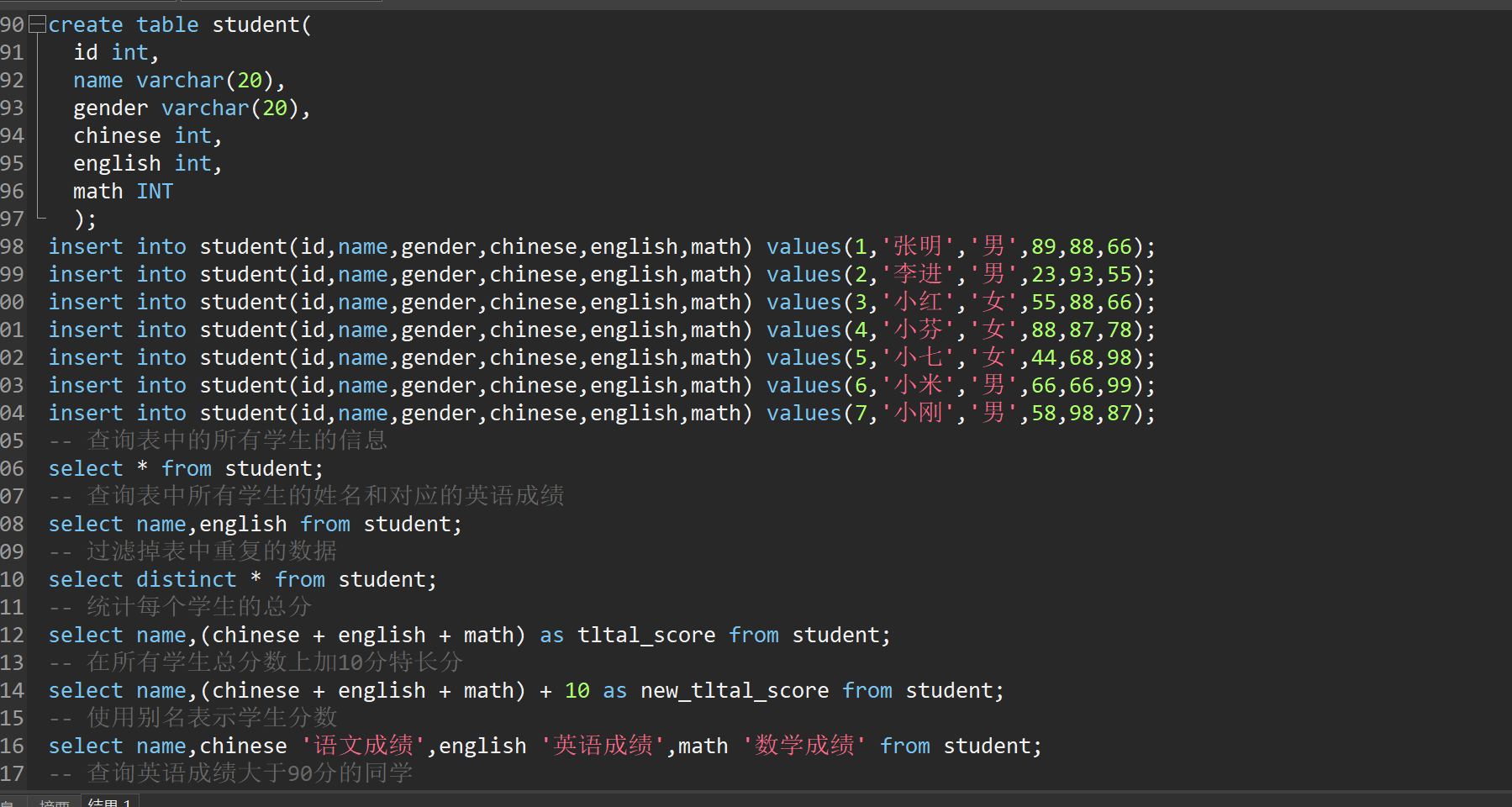
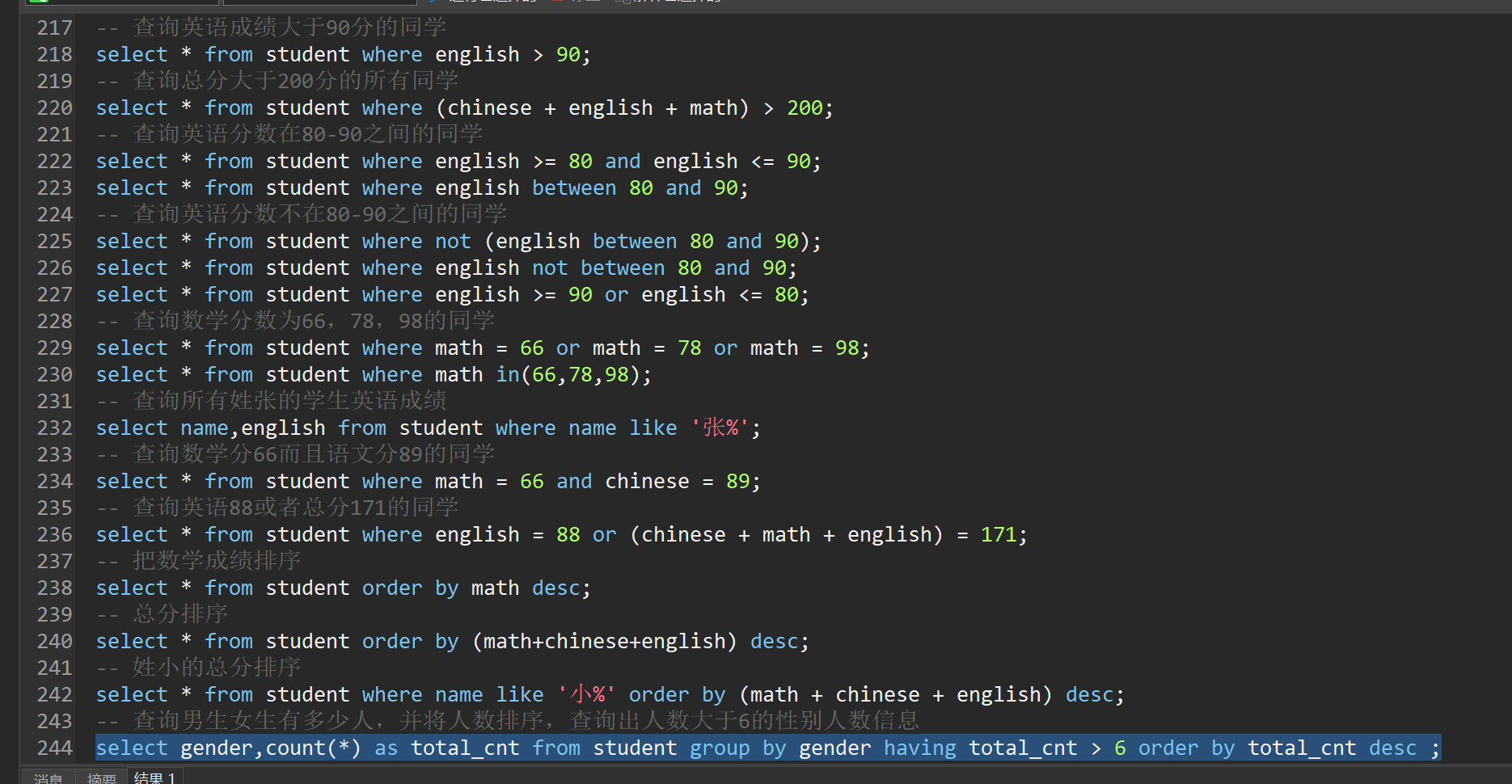
use mydb2;
create table student(
id int,
name varchar(20),
gender varchar(20),
chinese int,
english int,
math INT
);
insert into student(id,name,gender,chinese,english,math) values(1,'张明','男',89,88,66);
insert into student(id,name,gender,chinese,english,math) values(2,'李进','男',23,93,55);
insert into student(id,name,gender,chinese,english,math) values(3,'小红','女',55,88,66);
insert into student(id,name,gender,chinese,english,math) values(4,'小芬','女',88,87,78);
insert into student(id,name,gender,chinese,english,math) values(5,'小七','女',44,68,98);
insert into student(id,name,gender,chinese,english,math) values(6,'小米','男',66,66,99);
insert into student(id,name,gender,chinese,english,math) values(7,'小刚','男',58,98,87);
-- 查询表中的所有学生的信息
select * from student;
-- 查询表中所有学生的姓名和对应的英语成绩
select name,english from student;
-- 过滤掉表中重复的数据
select distinct * from student;
-- 统计每个学生的总分
select name,(chinese + english + math) as tltal_score from student;
-- 在所有学生总分数上加10分特长分
select name,(chinese + english + math) + 10 as new_tltal_score from student;
-- 使用别名表示学生分数
select name,chinese '语文成绩',english '英语成绩',math '数学成绩' from student;
-- 查询英语成绩大于90分的同学
select * from student where english > 90;
-- 查询总分大于200分的所有同学
select * from student where (chinese + english + math) > 200;
-- 查询英语分数在80-90之间的同学
select * from student where english >= 80 and english <= 90;
select * from student where english between 80 and 90;
-- 查询英语分数不在80-90之间的同学
select * from student where not (english between 80 and 90);
select * from student where english not between 80 and 90;
select * from student where english >= 90 or english <= 80;
-- 查询数学分数为66,78,98的同学
select * from student where math = 66 or math = 78 or math = 98;
select * from student where math in(66,78,98);
-- 查询所有姓张的学生英语成绩
select name,english from student where name like '张%';
-- 查询数学分66而且语文分89的同学
select * from student where math = 66 and chinese = 89;
-- 查询英语88或者总分171的同学
select * from student where english = 88 or (chinese + math + english) = 171;
-- 把数学成绩排序
select * from student order by math desc;
-- 总分排序
select * from student order by (math+chinese+english) desc;
-- 姓小的总分排序
select * from student where name like '小%' order by (math + chinese + english) desc;
-- 查询男生女生有多少人,并将人数排序,查询出人数大于6的性别人数信息
select gender,count(*) as total_cnt from student group by gender having total_cnt > 6 order by total_cnt desc ;
练习2:
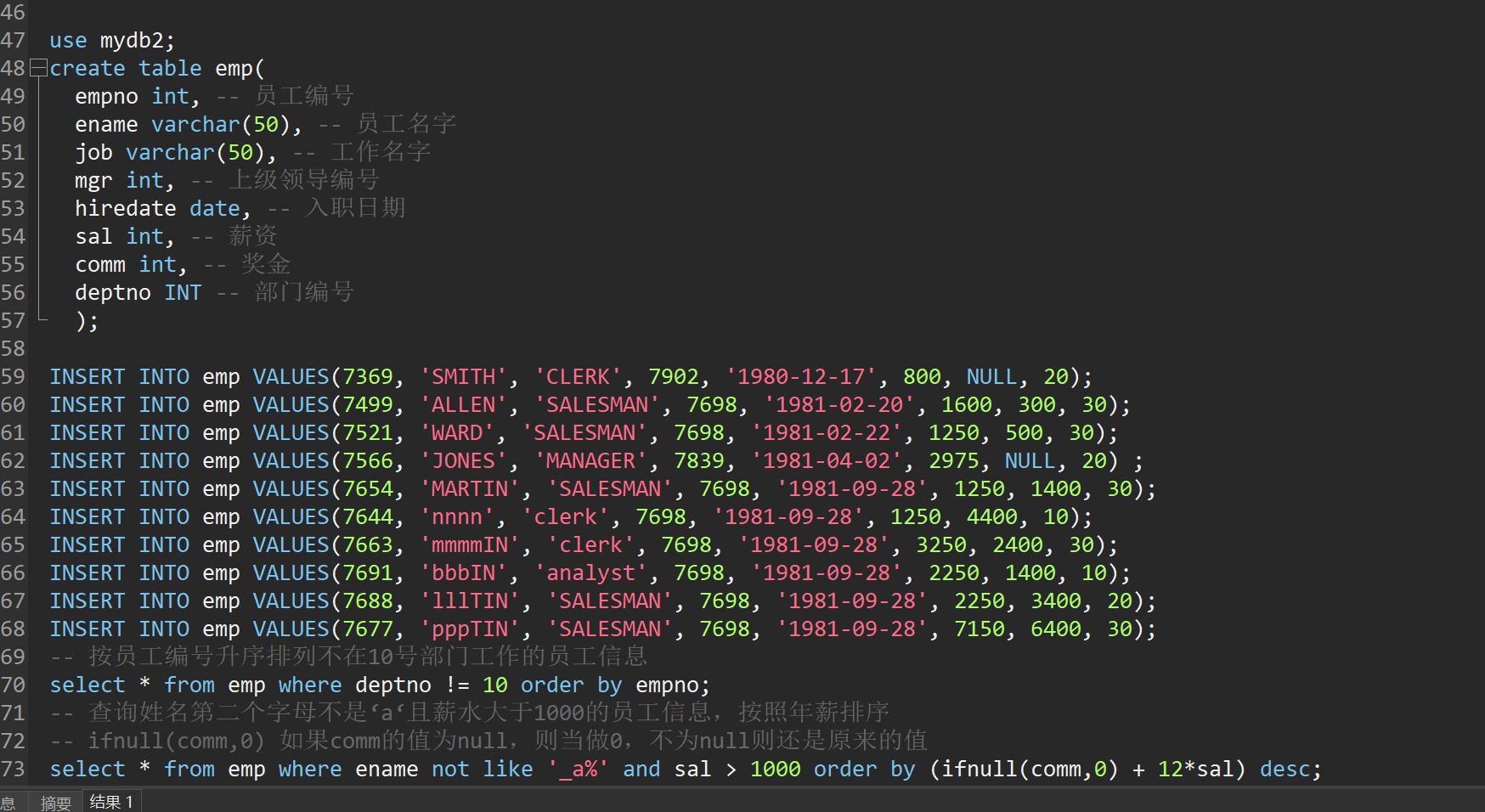
use mydb2;
create table emp(
empno int, -- 员工编号
ename varchar(50), -- 员工名字
job varchar(50), -- 工作名字
mgr int, -- 上级领导编号
hiredate date, -- 入职日期
sal int, -- 薪资
comm int, -- 奖金
deptno INT -- 部门编号
);
INSERT INTO emp VALUES(7369, 'SMITH', 'CLERK', 7902, '1980-12-17', 800, NULL, 20);
INSERT INTO emp VALUES(7499, 'ALLEN', 'SALESMAN', 7698, '1981-02-20', 1600, 300, 30);
INSERT INTO emp VALUES(7521, 'WARD', 'SALESMAN', 7698, '1981-02-22', 1250, 500, 30);
INSERT INTO emp VALUES(7566, 'JONES', 'MANAGER', 7839, '1981-04-02', 2975, NULL, 20) ;
INSERT INTO emp VALUES(7654, 'MARTIN', 'SALESMAN', 7698, '1981-09-28', 1250, 1400, 30);
INSERT INTO emp VALUES(7644, 'nnnn', 'clerk', 7698, '1981-09-28', 1250, 4400, 10);
INSERT INTO emp VALUES(7663, 'mmmmIN', 'clerk', 7698, '1981-09-28', 3250, 2400, 30);
INSERT INTO emp VALUES(7691, 'bbbIN', 'analyst', 7698, '1981-09-28', 2250, 1400, 10);
INSERT INTO emp VALUES(7688, 'lllTIN', 'SALESMAN', 7698, '1981-09-28', 2250, 3400, 20);
INSERT INTO emp VALUES(7677, 'pppTIN', 'SALESMAN', 7698, '1981-09-28', 7150, 6400, 30);
-- 按员工编号升序排列不在10号部门工作的员工信息
select * from emp where deptno != 10 order by empno;
-- 查询姓名第二个字母不是‘a‘且薪水大于1000的员工信息,按照年薪排序
-- ifnull(comm,0) 如果comm的值为null,则当做0,不为null则还是原来的值
select * from emp where ename not like '_a%' and sal > 1000 order by (ifnull(comm,0) + 12*sal) desc;
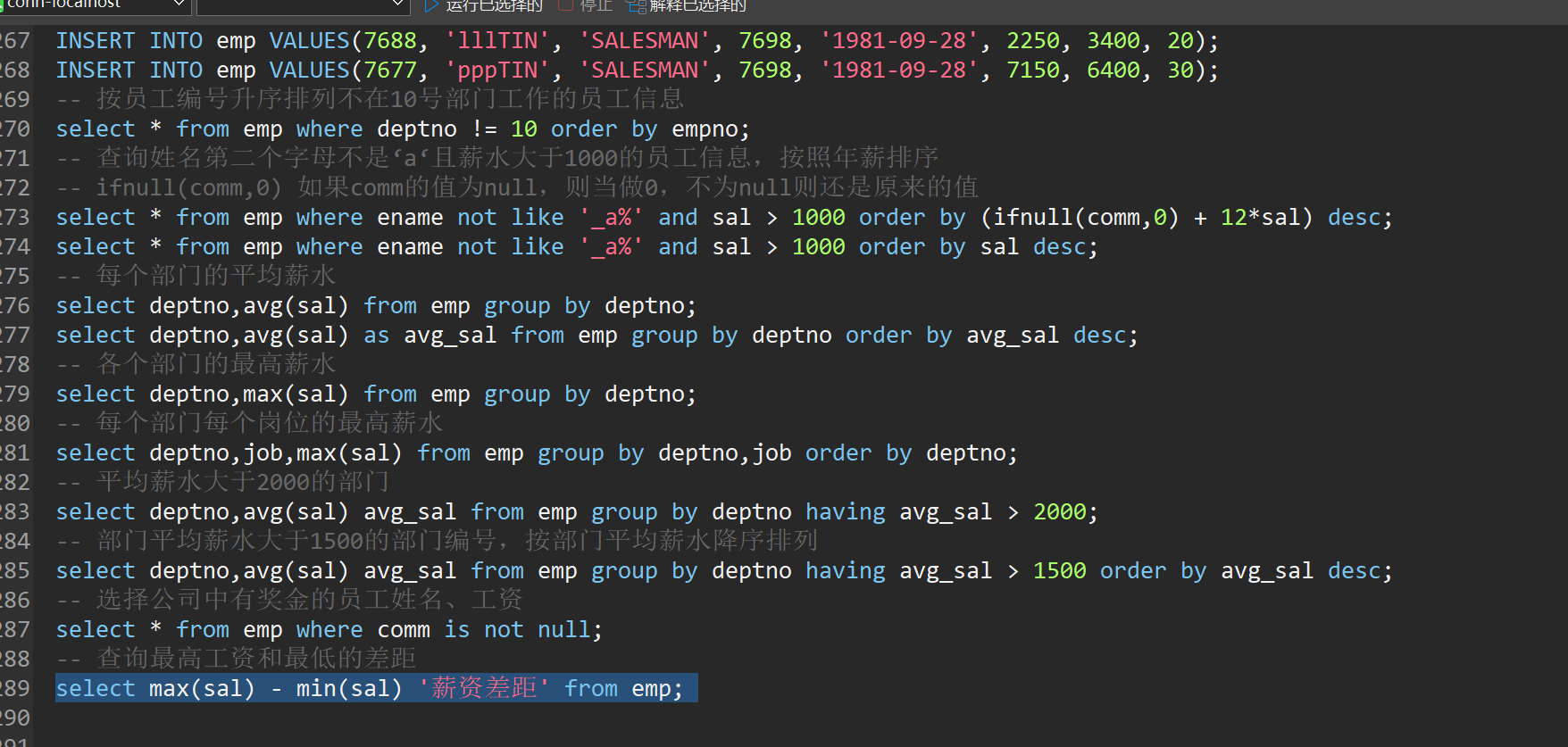
select * from emp where ename not like '_a%' and sal > 1000 order by sal desc;
-- 每个部门的平均薪水
select deptno,avg(sal) from emp group by deptno;
select deptno,avg(sal) as avg_sal from emp group by deptno order by avg_sal desc;
-- 各个部门的最高薪水
select deptno,max(sal) from emp group by deptno;
-- 每个部门每个岗位的最高薪水
select deptno,job,max(sal) from emp group by deptno,job order by deptno;
-- 平均薪水大于2000的部门
select deptno,avg(sal) avg_sal from emp group by deptno having avg_sal > 2000;
-- 部门平均薪水大于1500的部门编号,按部门平均薪水降序排列
select deptno,avg(sal) avg_sal from emp group by deptno having avg_sal > 1500 order by avg_sal desc;
-- 选择公司中有奖金的员工姓名、工资
select * from emp where comm is not null;
-- 查询最高工资和最低的差距
select max(sal) - min(sal) '薪资差距' from emp;
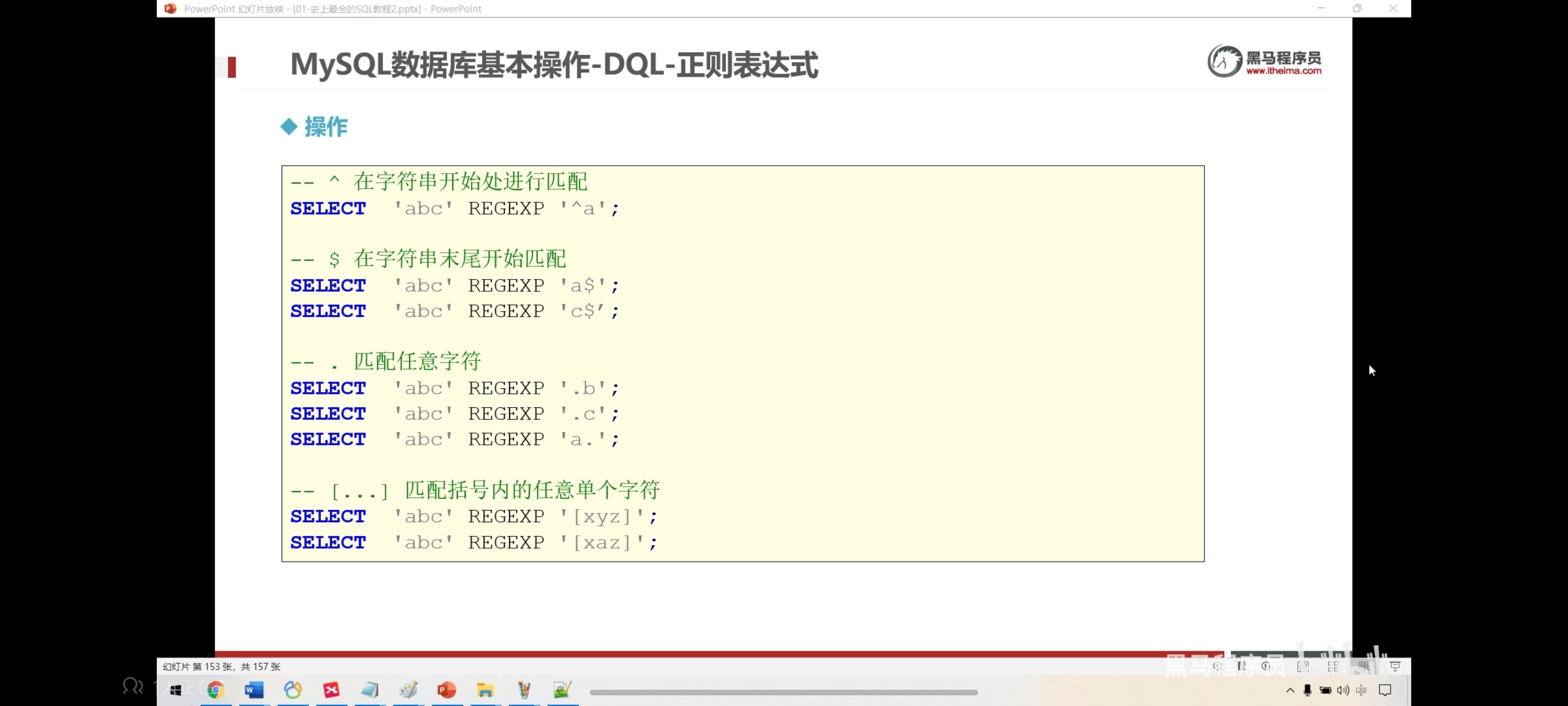
十五、正则表达式匹配查询
正则表达式就是一个字符串,然后定义了一个规则,可以用这个规则去匹配其他字符串


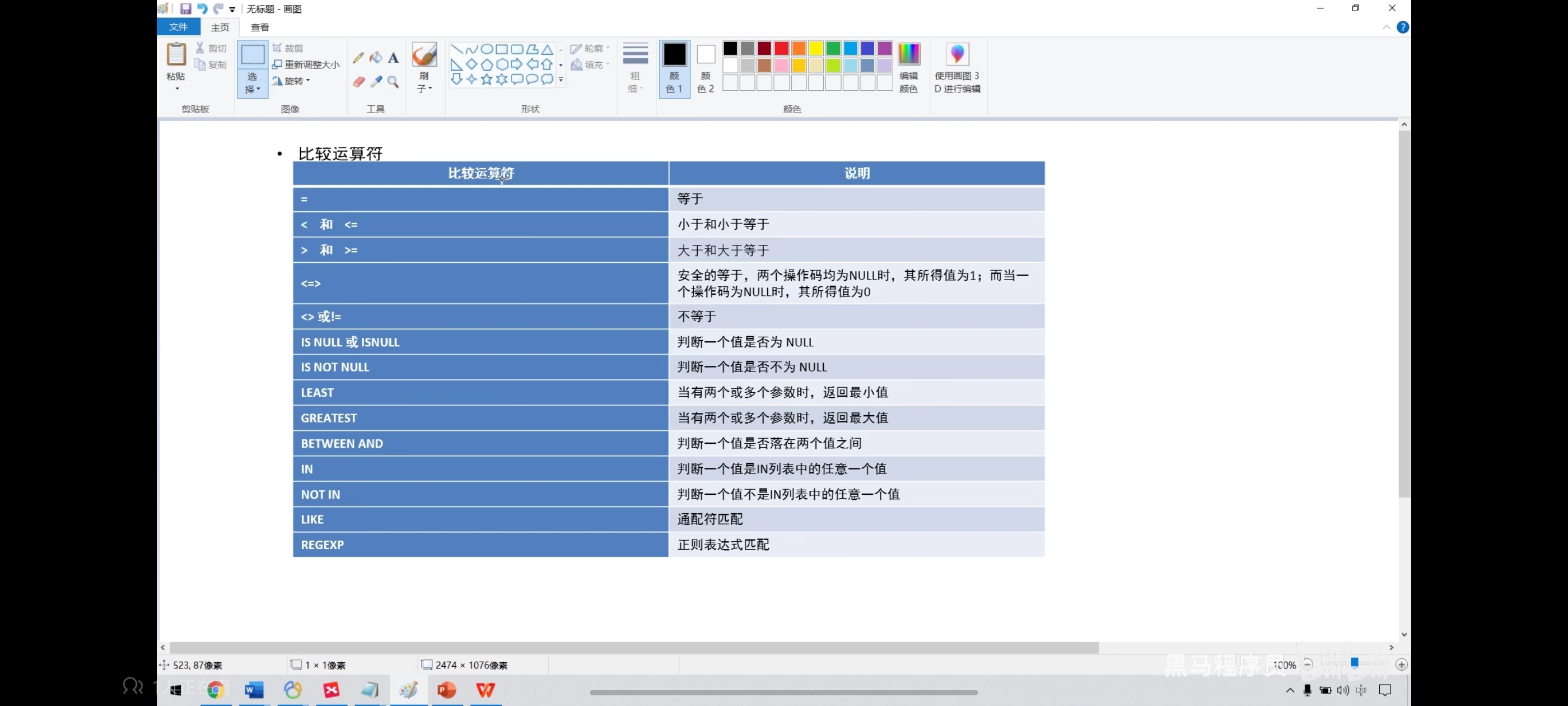
use mydb2;
-- 判断是不是a开头
select 'abc' regexp '^a';
select * from product where pname regexp '^海';
select 'abc' regexp 'a$';
select 'abc' regexp 'c$';
select * from product where pname regexp '机$';
select 'abc' regexp '.b';
-- . 可以匹配除了换行符之外的任意字符
select 'abc' regexp '.c';
select 'abc' regexp 'a.';
-- 正则表达式的任意字符是否在前边的字符串中出现
select 'abc' regexp '[xyz]';
select 'abc' regexp '[xaz]';
-- 注意^符号只有在[]里面才是取反的意思,在别的地方都是表示开始处匹配
select 'a' regexp '[^abc]'; -- 0
select 'x' regexp '[^abc]';
select 'abc' regexp '[^a]'; -- 1
select 'stab' regexp '.ta*b';
select 'stb' regexp '.ta*b';
select '' regexp 'a*';
select 'stab' regexp '.ta+b';
select 'stb' regexp '.ta+b';
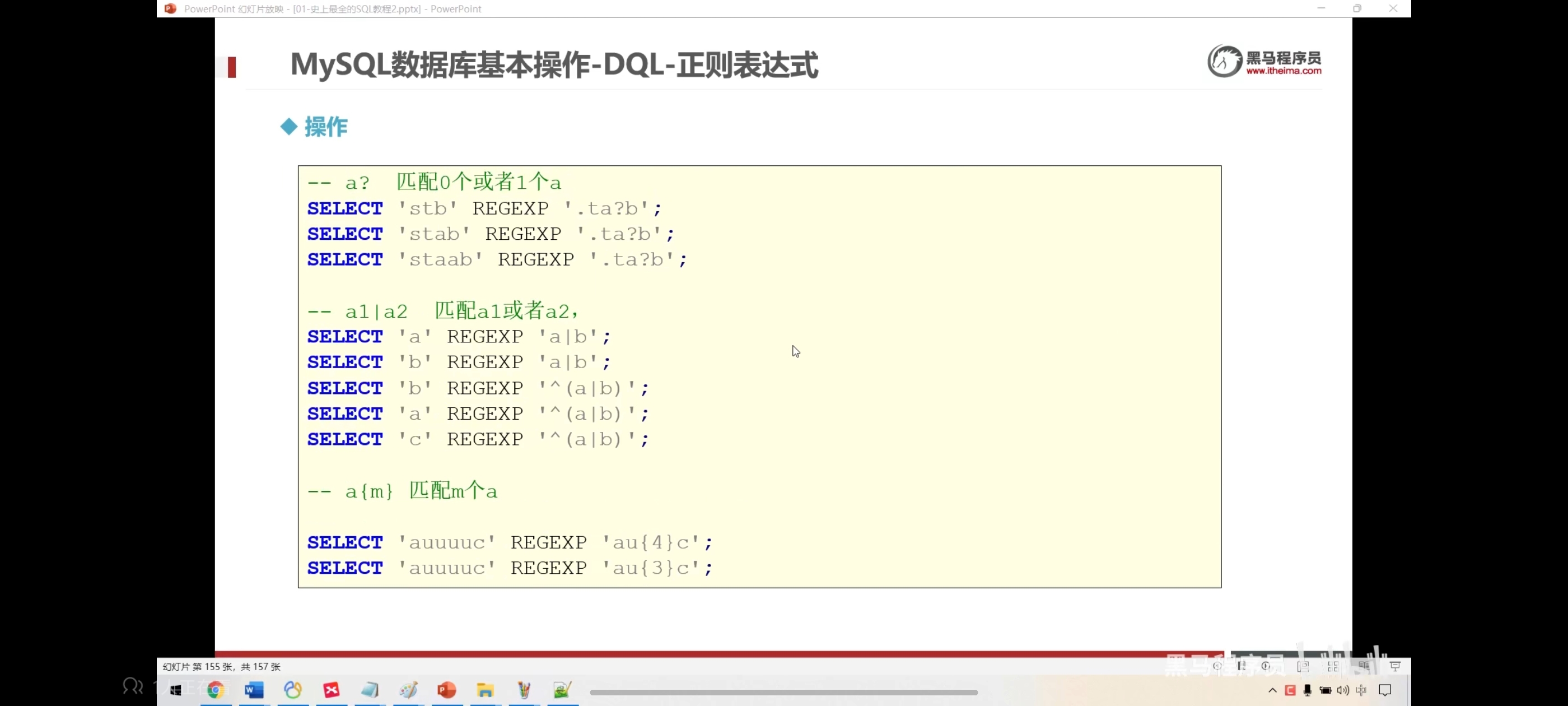
select 'stb' regexp '.ta?b';
select 'stab' regexp '.ta?b';
select 'staab' regexp '.ta?b';
select 'a' regexp 'a|b';
select 'b' regexp 'a|b';
select 'b' regexp '^(a|b)';-- ^以什么开头
select 'a' regexp '^(a|b)';
select 'c' regexp '^(a|b)';
select 'auuuuc' regexp 'au{4}c';
select 'auuuuc' regexp 'au{3}c';
select 'auuuuc' regexp 'au{3,}c';
select 'auuuuc' regexp 'au{4,}c';
select 'auuuuc' regexp 'au{5,}c';
select 'auuuuc' regexp 'au{3,5}c';
select 'auuuuc' regexp 'au{3,4}c';
select 'auuuuc' regexp 'au{5,22}c';
-- ()就是看成一个整体
select 'xababy' regexp 'x(abab)y';
select 'xababy' regexp 'x(ab)*y';
select 'xababy' regexp 'x(ab){1,2}y';
select 'xababy' regexp 'x(ab){3}y';