Volcano 实战快速入门 (一)
一、技术背景
随着大型语言模型(LLM)的蓬勃发展,其在 Kubernetes (K8s) 环境下的训练和推理对资源调度与管理提出了前所未有的挑战。这些挑战主要源于 LLM 对计算资源(尤其是 GPU)的巨大需求、分布式任务固有的复杂依赖性、多租户环境下的公平性保障以及对资源利用率(特别是昂贵的 GPU 资源)的极致追求。标准的 Kubernetes 调度器 kube-scheduler 主要面向无状态服务设计,在处理大规模、紧密耦合、资源密集型的批处理工作负载(如 LLM 训练)时显得力不从心。
Volcano 作为云原生计算基金会(CNCF)的首个也是目前唯一的容器批量计算项目,旨在弥补 Kubernetes 在批处理和高性能计算(HPC)领域的短板。它不仅仅是一个调度器,更是一个完整的批处理系统,引入了如 VolcanoJob、PodGroup 等关键抽象。Volcano 通过提供 Gang Scheduling(成组调度)、多种 Fair-share(公平共享)策略、先进的队列管理(包括分层队列和弹性队列)、拓扑感知(网络拓扑和 NUMA)以及优先级与抢占等核心功能,直接应对 LLM 场景下的资源管理难题。
1.1 Kubernetes 管理大模型(LLM)资源面临的核心挑战
-
极端规模与动态需求 (Extreme Scale & Dynamic Needs): LLM 的训练和推理需要海量的计算(数千 GPU/TPU)、存储(TB 级数据)资源,且需求波动巨大。这超出了传统 Kubernetes 资源管理和弹性伸缩的常规能力范围。
-
缺乏原子性调度 (Lack of Atomic Scheduling / Gang Scheduling): 分布式训练任务(如参数服务器和 Worker 组)要求所有组件同时启动(All-or-Nothing)。Kubernetes 默认以 Pod 为单位调度,缺乏对“任务组”的原生支持,易导致部分 Pod 启动后等待,造成资源死锁和 GPU 等昂贵资源的闲置浪费。
-
多租户公平性 (Multi-Tenant Fairness): 在共享集群中,如何在多个用户、团队或不同优先级任务间公平分配稀缺资源(尤其是 GPU)是一个难题。默认调度机制简单,易导致资源分配不均和“资源饥饿”现象。
-
GPU 利用率低下与碎片化 (GPU Underutilization & Fragmentation): 最大化昂贵的 GPU 利用率至关重要。静态分配、I/O 等待以及调度不当导致的 GPU 碎片化(集群总 GPU 充足但单个节点不足)普遍存在,难以维持高资源利用率。管理异构 GPU 增加了复杂性。
-
网络瓶颈与拓扑感知缺失 (Network Bottlenecks & Lack of Topology Awareness): 分布式训练对节点间通信带宽和延迟高度敏感。默认调度器通常不感知网络拓扑,可能将需要频繁通信的 Pod 分散部署,导致通信开销剧增,严重影响训练效率。
-
推理延迟 (Inference Latency): 满足 LLM 实时推理的低延迟要求,在 Kubernetes 的网络和服务抽象层下存在挑战,需要高效的路由和可能的边缘部署策略。
这些挑战主要源于 Kubernetes 默认调度器的设计侧重:它为微服务(数量多、相对独立、长周期)而非 LLM 类批处理任务(规模大、强依赖、资源密集、周期相对短)优化。其以 Pod 为中心、缺乏作业整体性和拓扑感知的调度逻辑难以满足 LLM 需求。
解决这些问题不仅关乎技术效率,更具经济与战略价值。提升 GPU 利用率、缩短训练时间、实现公平共享,能显著降低 AI 成本、加速创新并提升投资回报。
因此,LLM 的兴起迫切需要超越 K8s 默认能力的云原生批处理调度方案,这推动了 Volcano、YuniKorn、Koordinator 等旨在弥补 K8s 在高性能计算与大数据处理方面短板的项目的发展。
1.2. Volcano 简介
Volcano是CNCF 下首个也是唯一的基于Kubernetes的容器批量计算平台,主要用于高性能计算场景。它提供了Kubernetes目前缺 少的一套机制,这些机制通常是机器学习大数据应用、科学计算、特效渲染等多种高性能工作负载所需的。作为一个通用批处理平台,Volcano与几乎所有的主流计算框 架无缝对接,如Spark 、TensorFlow 、PyTorch 、 Flink 、Argo 、MindSpore 、 PaddlePaddle,Ray等。它还提供了包括异构设备调度,网络拓扑感知调度,多集群调度,在离线混部调度等多种调度能力。Volcano的设计 理念建立在15年来多种系统和平台大规模运行各种高性能工作负载的使用经验之上,并结合来自开源社区的最佳思想和实践。
a) 基础概念
VolcanoJob (vcjob): 是Volcano自定义的Job资源类型。区别于Kubernetes Job,vcjob提供了更多高级功能,如可指定调度器、支持最小运行pod数、 支持task、支持生命周期管理、支持指定队列、支持优先级调度等。Volcano Job更加适用于机器学习、大数据、科学计算等高性能计算场景
PodGroup: 一组强关联pod的集合,主要用于批处理工作负载场景,比如Tensorflow中的一组ps和worker。它是volcano自定义资源类型。
Queue: 是容纳一组podgroup的队列,也是该组podgroup获取集群资源的划分依据
NetworkTopology : 允许描述集群的网络结构,以支持网络拓扑感知调度,优化分布式任务的通信效率
b) 关键特性概览: Volcano 提供了一系列针对批处理和高性能计算优化的核心特性,主要包括:

1.3 生态支持:

二、环境搭建
2.1 基础环境
k3d 搭建轻量化k8s环境。当前也可以采用 kind,minkube 等等。这个就看个人习惯了。
mac 和 windows 都是可以的。不过前提安装好容器环境,windows11 提前配置好 wsl ubuntu22.04虚拟化环境。如果要测试大模型并行训练则需要带 GPU 的k8s环境
## 安装k3d
brew install k3d## k3d 创建k8s
k3d cluster create k8s-volcano \--servers 1 \--agents 2 \--k3s-arg "--disable=traefik@server:0" \--port "8080:80@loadbalancer" \--port "8443:443@loadbalancer" \--api-port 6550# 查看当前的k8s集群
k3d cluster list# 删除指定的k8s集群
k3d cluster delete k8s-***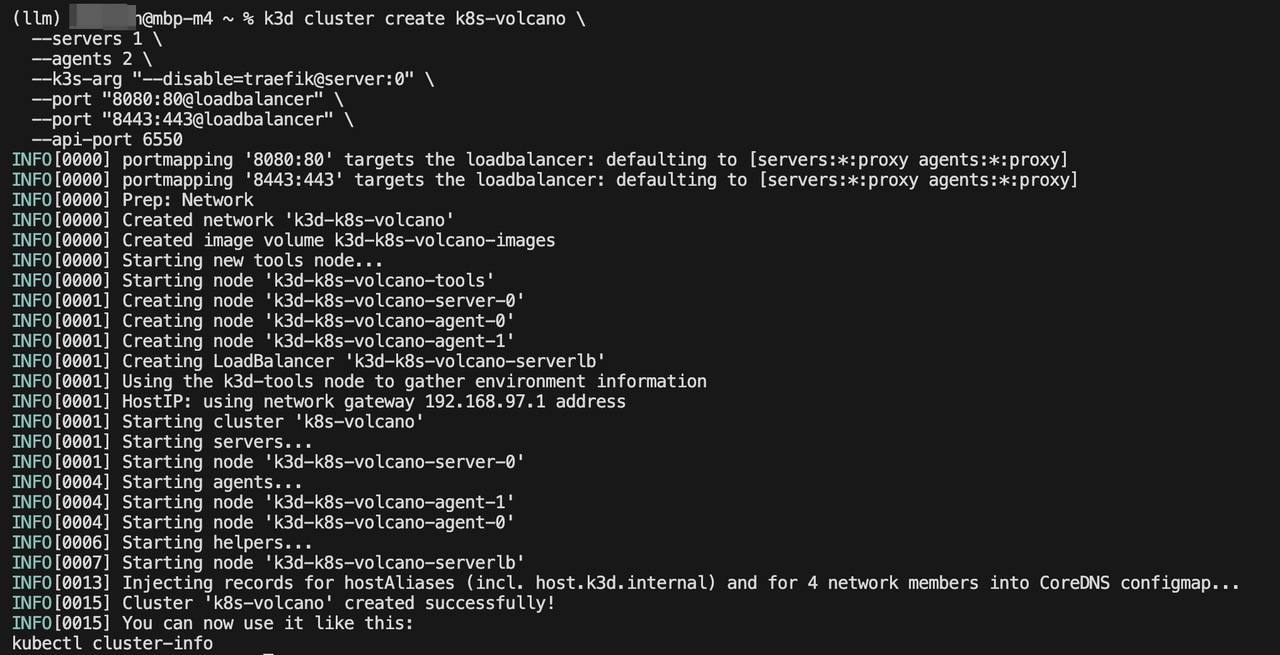

2.2 Volcano部署
## 直接安装
kubectl apply -f https://raw.githubusercontent.com/volcano-sh/volcano/master/installer/volcano-development.yaml
## 或者 通过helm安装
helm repo add volcano-sh https://volcano-sh.github.io/helm-charts
helm repo update
helm install volcano volcano-sh/volcano -n volcano-system --create-namespace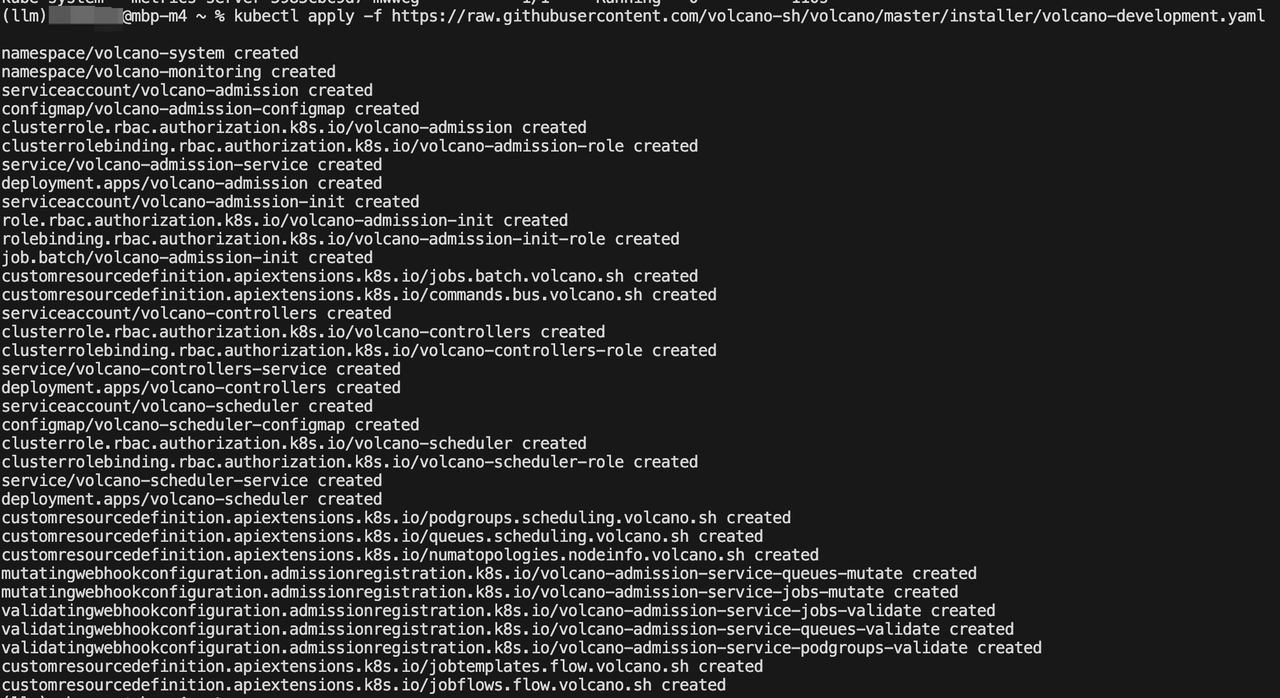
2.3 安装volcano-dashboard
### 直接安装
kubectl apply -f https://raw.githubusercontent.com/volcano-sh/dashboard/main/deployment/volcano-dashboard.yaml通过 nodeport 方式暴露服务

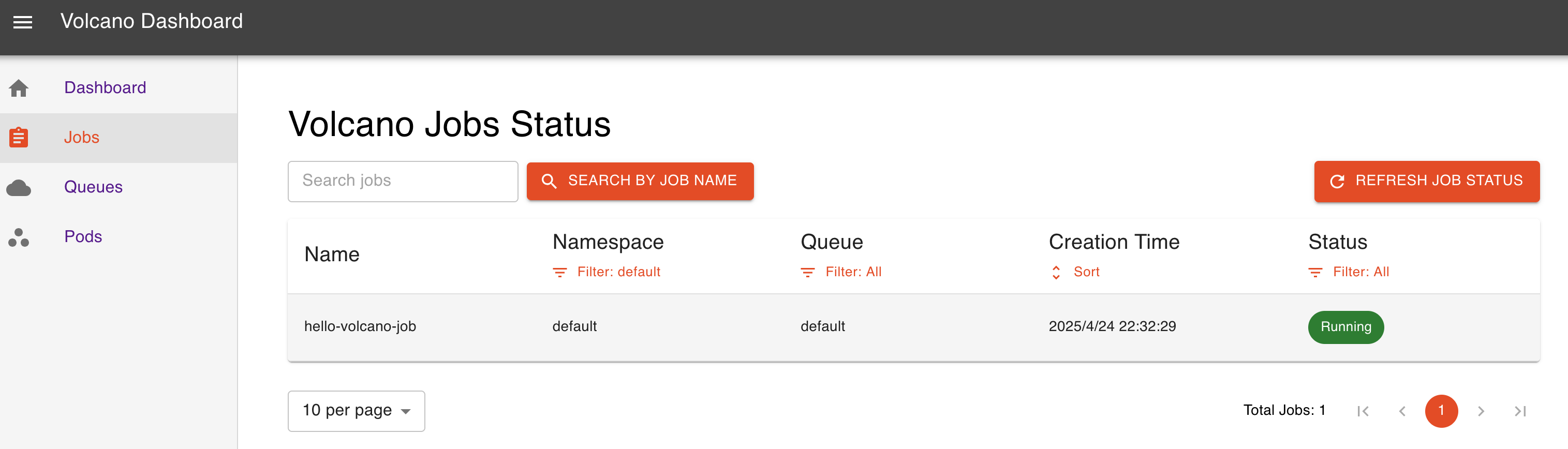
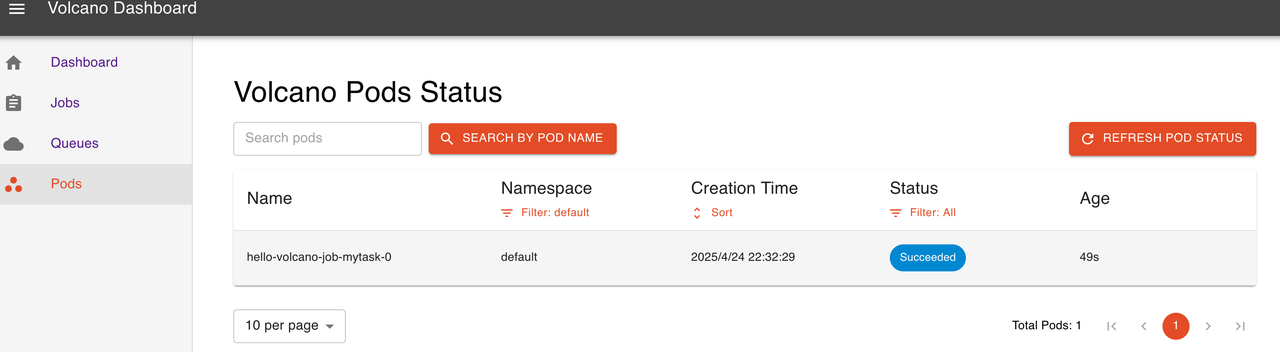
2.4 简单运行 demojob
cat <<EOF | kubectl apply -f -
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:name: hello-volcano-job
spec:schedulerName: volcanominAvailable: 1tasks:- name: mytaskreplicas: 1template:spec:containers:- name: hello-containerimage: busyboxcommand: ["sh", "-c", "echo 'Hello Volcano!' && sleep 300"]imagePullPolicy: IfNotPresentrestartPolicy: Never
EOF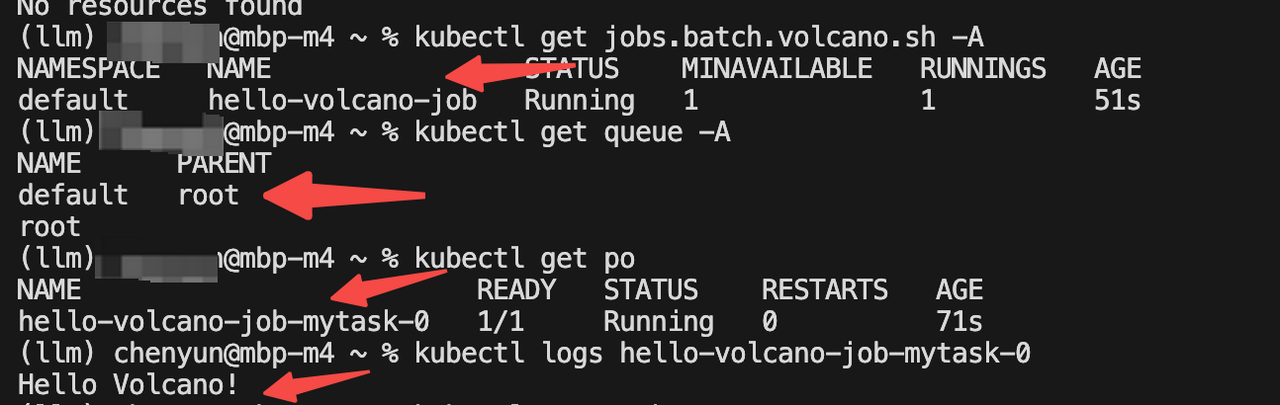
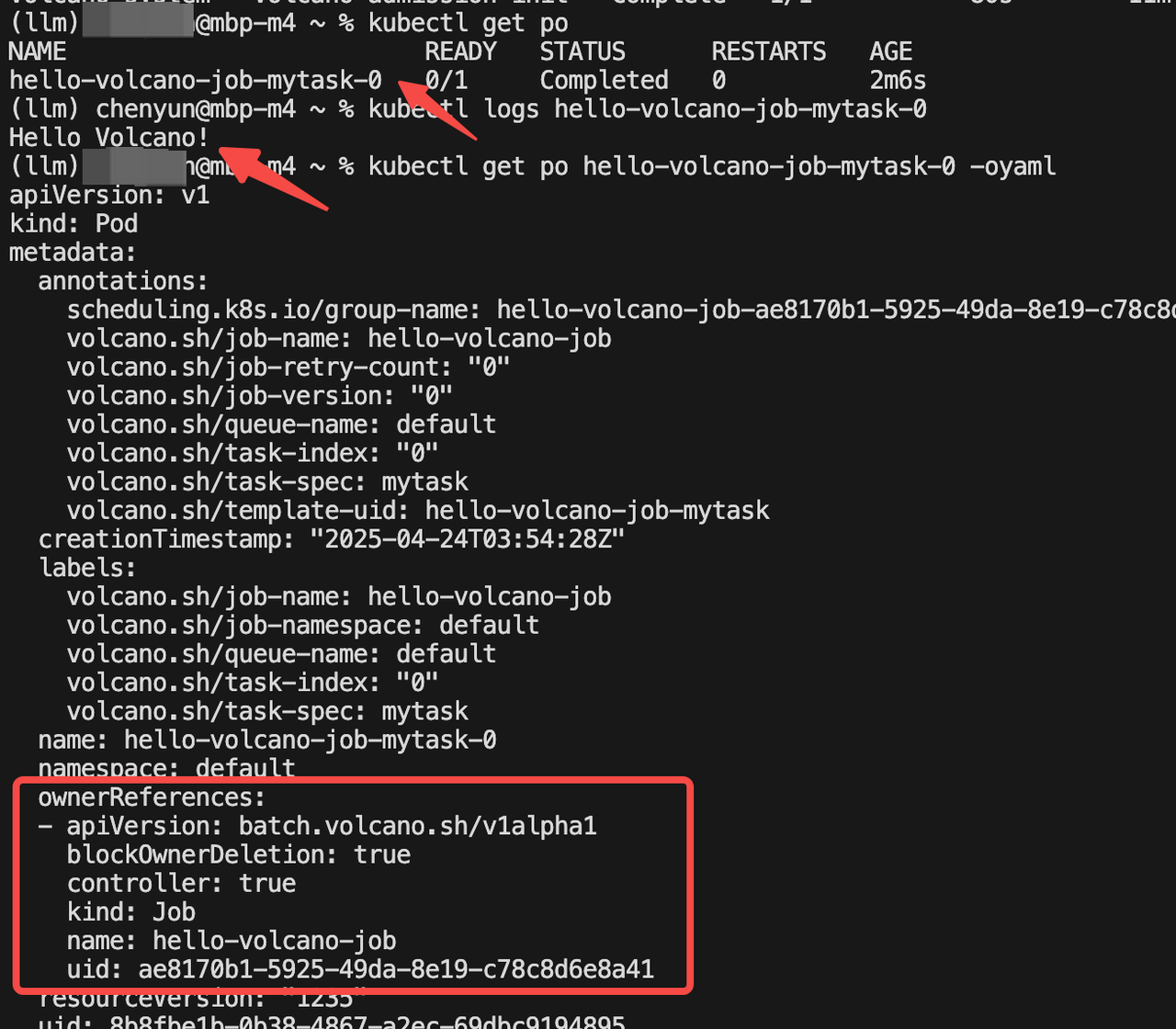
schedulerName: volcano
调度器指定volcano,这样在调度 job 的 Pod 时会使用volcano而不是默认的 Kubernetes 的调度器。
## 删除 job
kubectl get vcjob -A
kubectl delete vcjob hello-volcano-job 三、Volcano 基础功能实战
3.1 queue 资源管理
a) 部署两个不同权重队列
cat <<EOF | kubectl apply -f -
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
metadata:name: queue-a
spec:weight: 1
---
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
metadata:name: queue-b
spec:weight: 2
EOFkubectl get queues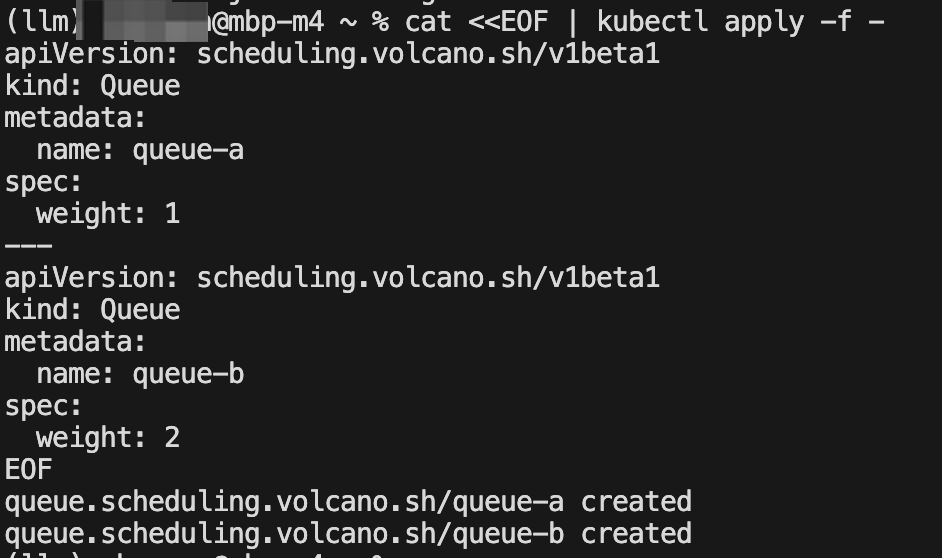
b) 部署job观察调度
# weight-test-job-template.yaml
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:name: job-a-1
spec:schedulerName: volcanoqueue: queue-aminAvailable: 1tasks:- name: maintaskreplicas: 1template:spec:containers:- name: cpu-eaterimage: busyboxcommand: ["sh", "-c", "echo 'Starting CPU load...'; i=0; while [ $i -lt 300 ]; do i=$((i+1)); : ; done & PID=$!; sleep 300; kill $PID; echo 'Finished.'"]resources:requests:cpu: "500m" memory: "100Mi" imagePullPolicy: IfNotPresentrestartPolicy: Never## 按照上述模型创建job 观察资源 调度优先级。
queue-a [job-a-1,job-a-2,job-a-3,job-a-4,job-a-5,job-a-6]
queue-b [job-b-1,job-b-2,job-b-3,job-b-4,job-b-5,job-b-6]queue-b应该会优先获得资源。不过需要多观察一些时间。
3.2 Gang Scheduling 调度
尝试调度配置(min=20)
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:name: job-a-1
spec:schedulerName: volcanoqueue: queue-aminAvailable: 20tasks:- name: maintaskreplicas: 20template:spec:containers:- name: cpu-eaterimage: busyboxcommand: ["sh", "-c", "echo 'Starting CPU load...'; i=0; while [ $i -lt 300 ]; do i=$((i+1)); : ; done & PID=$!; sleep 300; kill $PID; echo 'Finished.'"]resources:requests:cpu: "4" imagePullPolicy: IfNotPresentrestartPolicy: Never

可以观察没有调度
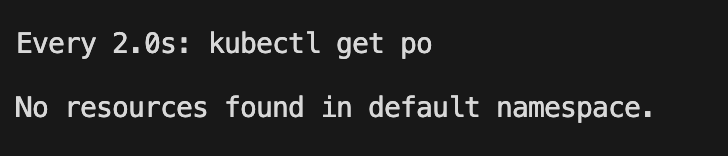
将 minAvailable 条件缩小到 4 个就可以发现已经在调度了
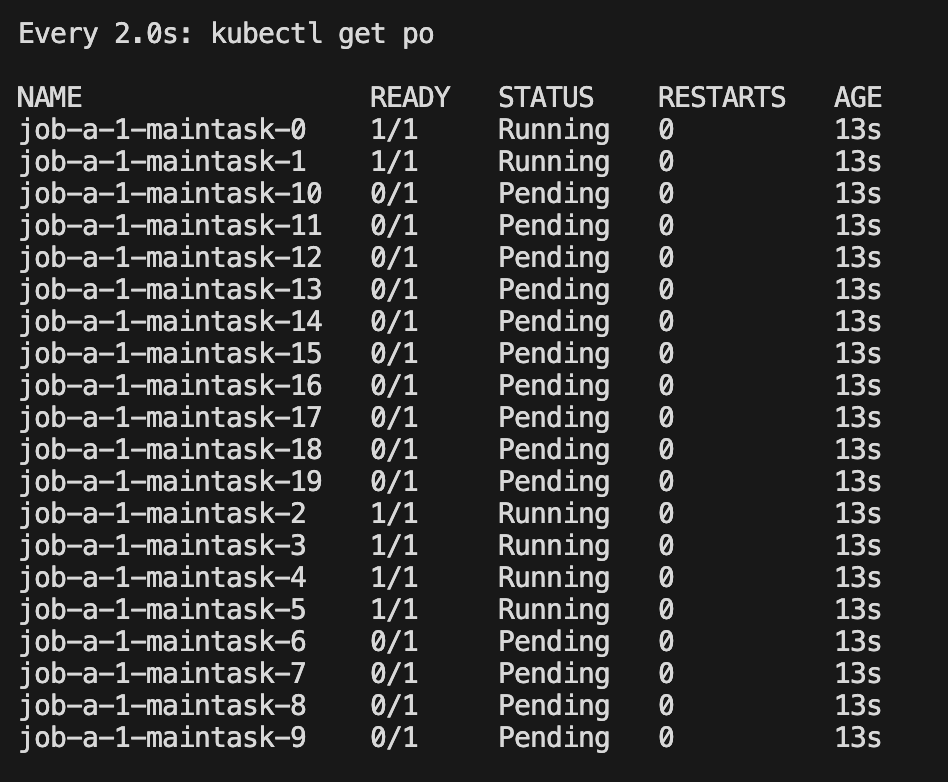

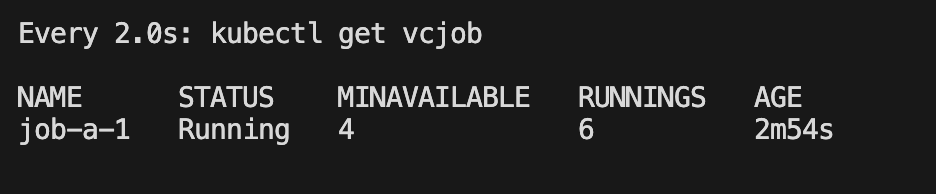
3.3 作业前后依赖
需要等task-a 调度完毕了才会调度task-b
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:name: workflow-job
spec:schedulerName: volcanoqueue: defaultminAvailable: 1tasks:- name: task-a replicas: 1template:spec:containers:- name: task-a-containerimage: busyboxcommand: ["sh", "-c", "echo 'Task A: Starting process...' && sleep 100 && echo 'Task A: Process finished successfully!'"]imagePullPolicy: IfNotPresentrestartPolicy: OnFailure - name: task-breplicas: 1dependsOn: name: ["task-a"]template:spec:containers:- name: task-b-containerimage: busyboxcommand: ["sh", "-c", "echo 'Task B: Starting process (triggered after Task A)...' && sleep 20 && echo 'Task B: Process finished.'"]imagePullPolicy: IfNotPresentrestartPolicy: OnFailure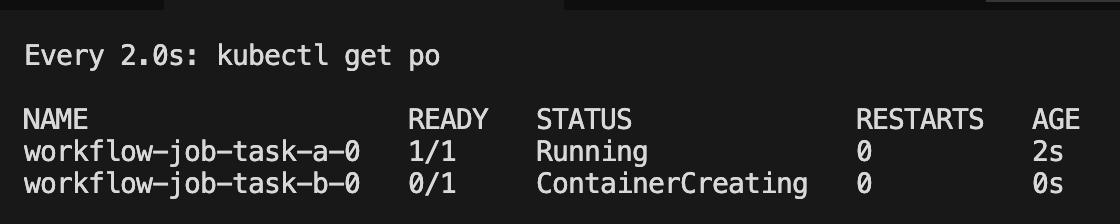

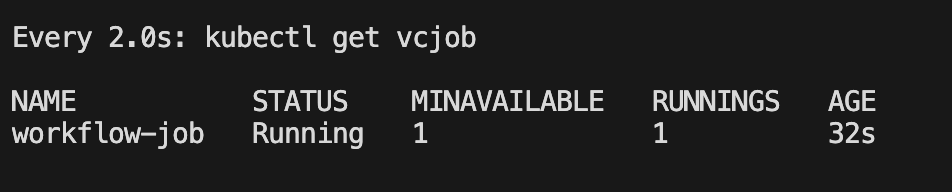
如果想要尝试高级 flow 调度需要再额外安装 flowjob 组件才可以实现更多 灵活 精细的 flow 策略
四、Volcano 进阶功能实战
这部分内容放到第二篇
4.1 MPI分布式训练
4.2 网络拓扑感知调度
4.3 负载感知调度
4.4 离线混部调度
4.5 多集群调度
4.6 多种策略综合调度
五、小结
volcano 使用起来复杂度不高,只要实现有想要调度的策略目标找到对应的文档配置即可。不过当前只是简单场景的复刻测试。复杂的生产项目不知道会不会别的坑或者问题。下篇 测试网络拓扑调度,负载感知重调度,多集群调度等。
参考:
Volcano![]() https://volcano.sh/zh/
https://volcano.sh/zh/
https://github.com/volcano-sh/volcano![]() https://github.com/volcano-sh/volcanohttps://github.com/kubeflow/mpi-operator
https://github.com/volcano-sh/volcanohttps://github.com/kubeflow/mpi-operator![]() https://github.com/kubeflow/mpi-operator
https://github.com/kubeflow/mpi-operator