【框架学习】Spring AI-功能学习与实战(一)
本文掌握的功能
- 流式对话
- 模型上下文记忆
- 模型对话隔离
- 多平台、多模型集成
- 百炼知识库实战
- 对话Token统计
Spring AI概念讲解
平台和模型
在Sping AI中可以通过引入多个平台的starter从而接入对应平台的模型和接口
平台:用有多个模型
模型:具体通过对话的实体
常见的Bean
ChatModel
各个引入平台的starter会根据配置文件,注入对应的ChatModel,提供对话功能,支持同步返回和流式返回
ChatClient
Spring Ai 会自动注入ChatClient.Builder 这个Bean,但是在多平台下会有多个,所以在多平台情况下,需要禁止Spring Ai自动注入,如下配置即可
spring:chat:client:enabled: false
与Model的区别是,Model只提供对话能力,但是ChatClient是一个抽象的封装,代表所有的模型,可以配置多种机制,实现复杂的情况。
可以通过下面的方式创建ChatClient
ChatClient chatClient = ChatClient.builder(chatModel).build();
Advisors
Spring AI Advisor的核心功能在于拦截并可能修改AI应用程序中聊天请求和响应流的组件。在这个系统中,AroundAdvisor是关键参与者,它允许开发人员在这些交互过程中动态地转换或利用信息。
使用Advisor的主要优势包括:
重复任务的封装:能够将常见的生成式AI模式打包成可重用的单元,简化开发过程。
数据转换:增强发送给语言模型(LLM)的数据,并优化返回给客户端的响应格式,以提高交互质量。
可移植性:创建可跨不同模型和用例工作的可重用转换组件,提升代码的灵活性和适应性。
或许你会觉得,这与我们在Spring中使用AspectJ的方式颇为相似。实际上,当你阅读完今天的文章后,会发现这不过是换了个名称而已,主要功能其实是一致的,都是为了增强应用程序的能力。
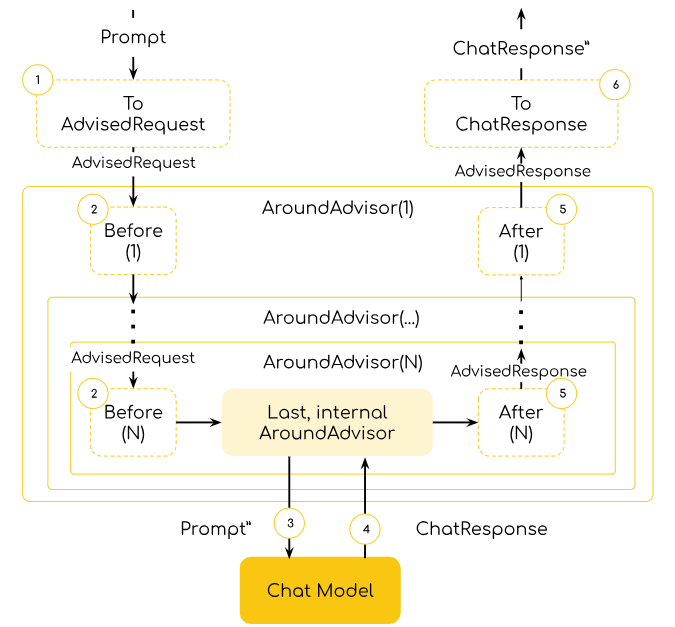
我来大致讲解一下整个流程:
首先,我们会封装各种请求参数配置,如前面AdvisedRequest的截图所示,这里就不再详细说明。接下来,链中的每个Advisor都会处理请求,可能对其进行修改,并将执行流程转发给链中的下一个Advisor。值得注意的是,某些Advisor也可以选择不调用下一个实体,从而阻止请求继续传递。
最终,Advisor将请求发送到Chat Model。聊天模型的响应将通过Advisor链传递回原请求路径,形成原始上下文和建议上下文的组合。每个Advisor都有机会处理或修改这个响应,确保其符合预期。最后,系统将返回一个AdvisedResponse给客户端。有点类似Netty的PipLine
接下来,我们将深入探讨如何实际使用Advisor。
内嵌的Advisor
作为Spring AI的一部分,系统内置了多个官方Advisor示例,这些示例不仅数量不多,而且功能各异,能够很好地展示Advisor的实际应用场景。我们不妨一起来逐一查看这些内置Advisor的作用和特点,深入了解它们如何在请求处理链中发挥各自的功能。
MessageChatMemoryAdvisor:是我们之前提到过的一个常用类,它在请求处理流程中扮演着重要的角色。这个Advisor的主要功能是将用户提出的问题和模型的回答添加到历史记录中,从而形成一个上下文记忆的增强机制。通过这种方式,系统能够更好地理解用户的需求,提供更加连贯和相关的响应。
需要注意的是,并非所有的AI模型都支持这种上下文记忆的存储和管理方式。某些模型可能没有实现相应的历史记录功能,因此在使用MessageChatMemoryAdvisor时,确保所使用的模型具备此支持是至关重要的。
PromptChatMemoryAdvisor:的功能在MessageChatMemoryAdvisor的基础上进一步增强,其主要作用在于上下文聊天记录的处理方式。与MessageChatMemoryAdvisor不同,PromptChatMemoryAdvisor并不将上下文记录直接传入messages参数中,而是巧妙地将其封装到systemPrompt提示词中。这一设计使得无论所使用的模型是否支持messages参数,系统都能够有效地增加上下文历史记忆。
QuestionAnswerAdvisor:的主要功能是执行RAG(Retrieval-Augmented Generation)检索,这一过程涉及对知识库的高效调用。当用户提出问题时,QuestionAnswerAdvisor会首先对知识库进行检索,并将匹配到的相关引用文本添加到用户提问的后面,从而为生成的回答提供更为丰富和准确的上下文。
此外,该Advisor设定了一个默认提示词,旨在确保回答的质量和相关性。如果在知识库中无法找到匹配的文本,系统将拒绝回答用户的问题。
SafeGuardAdvisor:的核心功能是进行敏感词校验,以确保系统在处理用户输入时的安全性和合规性。当用户提交的信息触发了敏感词机制,SafeGuardAdvisor将立即对该请求进行中途拦截,避免继续调用大型模型进行处理。
SimpleLoggerAdvisor:这是一个用于日志打印的工具,我们之前已经对其进行了练习和深入了解,因此在这里不再赘述。
VectorStoreChatMemoryAdvisor:该组件实现了长期记忆功能,能够将每次用户提出的问题及模型的回答存储到向量数据库中。在用户每次提问时,系统会进行一次检索,将检索到的信息累加到系统提示词的后面,以便为大模型提供更准确的上下文提示。然而,这里需要注意的是,如果没有妥善维护 chat_memory_conversation_id,可能会导致无限制的写入和检索,从而引发潜在的灾难性bug。因此,确保这一标识的管理和更新至关重要,以避免系统的不稳定性和数据混乱。
功能讲解
流式对话
目前流式对话有下面几种实现
- Spring Web Flux
- SSE 推送
这里采用Flux进行实现,为什么不用SSE呢,因为SSE是长连接,并且只支持服务端推送,需要代码中自行管理SSE的连接
具体实现:
通过ChatClient 或者 ChatModel 的stream接口即可实现
模型上下文记忆、会话隔离
模型对话记忆的持久化是通过Advisors机制来实现的,具体是有一个MessageChatMemoryAdvisor ,
在构建ChatClient的时候添加,如何即可支持上下文的存储,并且Spring AI官方抽象了一个接口,我们可以根据自己的需求定义自己的上下文存储实现,如下是实现基于Mongo的存储:
@Component
public class MongoChatMemory implements ChatMemory {@Resourceprivate ChatMessageMapper chatMessageMapper;@Overridepublic void add(String conversationId, List<Message> messages) {List<ChatMessage> chatMessageList = messages.stream().map(t -> {return ChatMessageConvert.messagetoChatMessage(conversationId, t);}).toList();chatMessageMapper.saveBatch(chatMessageList);}@Overridepublic List<Message> get(String conversationId, int lastN) {List<ChatMessage> chatMessageList = chatMessageMapper.selectByConversationIdAndLimit(conversationId, lastN);return chatMessageList.stream().map(ChatMessageConvert::toMessageByType).toList();}@Overridepublic void clear(String conversationId) {}@Bean(name = "mongoChatMemoryAdvisor")public MessageChatMemoryAdvisor mongoMessageChatMemoryAdvisor(ChatMemory mongoChatMemory) {return new MessageChatMemoryAdvisor(mongoChatMemory);}
}@Data
@CollectionName("aiChatMessage")
@MongoTextIndex(fields = {"text_content"})
@FieldNameConstants
@ToString
public class ChatMessage implements DbEntity {@ID(type = IdTypeEnum.AUTO)private Long id;@MongoHashIndex()private String conversationId;private String textContent;@MongoHashIndex()private String messageType;private List<MessageMedia> messageMediaList = new ArrayList<>();private Long createTime = Timer.currentTimestamp();private Long updateTime = Timer.currentTimestamp();private Integer del = DelEnum.UN_DEL.getCode();}@Data
@AllArgsConstructor
@ToString
class MessageMedia {private String id;private String mimeType;private Object data;private String name;
}@Component
public class ChatMessageMapper extends BaseMongoMapper<ChatMessage> {public List<ChatMessage> selectByConversationIdAndLimit(String conversationId, int lastN) {QueryWrapper<ChatMessage> eq = createMgoQuery().eq(ChatMessage.Fields.conversationId, conversationId).orderByAsc(ChatMessage.Fields.createTime);AggregateWrapper limit = new AggregateWrapper().match(eq).limit(lastN);return aggregateList(limit);}}最后在使用的时候,如下即可实现上下文记忆,主要需要传入会话的ID,以及上下文对话时,数据库返回的最大条数
ChatClient chatClient = ChatClient.builder(chatModel).build();Flux<ResponseEntity<String>> aiResponse = chatClient.prompt(message).advisors(mongoChatMemoryAdvisor, tokenCollect).advisors(a -> a.param(CHAT_MEMORY_CONVERSATION_ID_KEY, id).param(CHAT_MEMORY_RETRIEVE_SIZE_KEY, 100).param("Token", 0)).stream().chatResponse().map(t -> {log.info("AI的响应:{}", t);return t.getResult().getOutput().getText();}).map(ResponseEntity::success);
多平台、多模型
引入依赖以及在配置文件中进行配置
<dependency><groupId>com.alibaba.cloud.ai</groupId><artifactId>spring-ai-alibaba-starter</artifactId></dependency><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-openai-spring-boot-starter</artifactId></dependency>
spring:ai:dashscope:api-key: sk-xxxworkspace-id: llm-u55edq3kz6sjumr0openai:chat:options:stream-usage: trueapi-key: sk-xxxbase-url: https://xxxchat:client:enabled: false
这样就会自动注入多个平台的Bean
使用例子:
@Slf4j
@RestController
@CrossOrigin(origins = "*")
@RequestMapping("/test/mul")
public class MulPlatformController {@Autowiredprivate Map<String, ChatModel> chatModels;@Resourceprivate MessageChatMemoryAdvisor mongoChatMemoryAdvisor;@Resourceprivate TokenCollect tokenCollect;@GetMapping(value = "/chat/{model}/{id}", produces = MediaType.TEXT_EVENT_STREAM_VALUE)public Flux<ResponseEntity<String>> chat(@PathVariable("model") String model, @PathVariable("id") Long id, @RequestParam(name = "message") String message, HttpServletResponse httpServletResponse) {httpServletResponse.setCharacterEncoding("UTF-8");httpServletResponse.setHeader("Connection", "keep-alive");ChatModel chatModel = chatModels.get(model);if (chatModel == null) {return Flux.just(ResponseEntity.fail("模型不存在"));}log.info("请求体:{},{}", model, message);ChatClient chatClient = ChatClient.builder(chatModel).build();Flux<ResponseEntity<String>> aiResponse = chatClient.prompt(message).advisors(mongoChatMemoryAdvisor, tokenCollect).advisors(a -> a.param(CHAT_MEMORY_CONVERSATION_ID_KEY, id).param(CHAT_MEMORY_RETRIEVE_SIZE_KEY, 100).param("Token", 0)).stream().chatResponse().map(t -> {log.info("AI的响应:{}", t);return t.getResult().getOutput().getText();}).map(ResponseEntity::success);return aiResponse;}
}
public class AiPlatformConstant {private final static String ALI = "dashscopeChatModel";private final static String OPEN_AI = "openAiChatModel";
}对话Token统计
上面了解了Advisor的机制,那么我们就可以定义一个自己的Advisor用来统计Token
@AllArgsConstructor
@Slf4j
@Component
public class TokenCollect implements StreamAroundAdvisor {@Resourceprivate StringRedisTemplate stringRedisTemplate;@Overridepublic Flux<AdvisedResponse> aroundStream(AdvisedRequest advisedRequest, StreamAroundAdvisorChain chain) {log.info("TokenCollect-advisedRequest:{}", advisedRequest);Flux<AdvisedResponse> advisedResponseFlux = chain.nextAroundStream(advisedRequest);return advisedResponseFlux.map(t -> {Usage usage = t.response().getMetadata().getUsage();String id = t.adviseContext().get(CHAT_MEMORY_CONVERSATION_ID_KEY).toString();stringRedisTemplate.opsForValue().increment("userage:" + id, usage.getTotalTokens());log.info("TokenCollect-use:{},{}", id, usage);return t;});}//2409c4b2-a4ae-9e04-8ca9-646486814f53@Overridepublic String getName() {return "TokenCollect";}@Overridepublic int getOrder() {return 2;}}这样就可以统计会话消耗的总Token,但是单词提问的Token统计(Stream形式)待官方更新后看有没有实现的方式