SAM12
SAM1
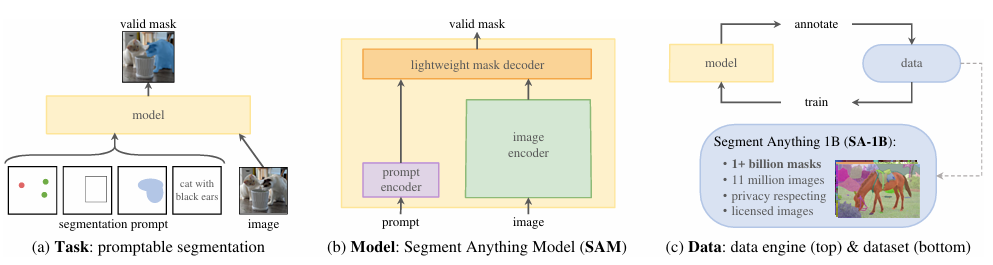
NLP中可以通过预测next token作为预训练任务,而在下游任务中可以使用prompt engineering做应用。因此,作者扩展了下NLP里prompt在图像分割里的用法, prompt可以是以下几种类型:
- point
- box
- mask
- 任意格式的文本
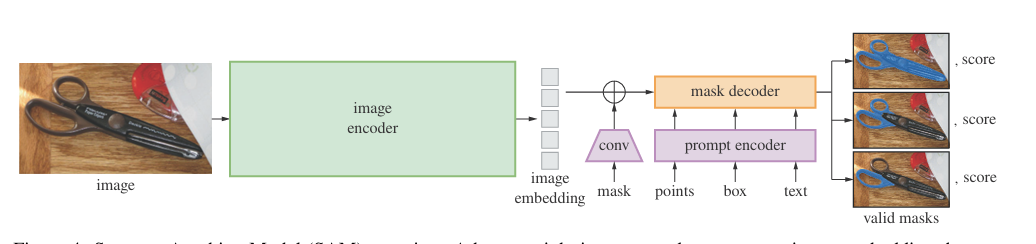
image encoder: ViT
point和box可以作为一类使用position encodings, text可以使用CLIP作为encoder, 而mask是一种密集型的prompt,可以使用卷积作为encoder
mask decoder使用一个transformer将image embedding和prompt embedding做双向的cross-attention;并且也有prompt embedding的self-attention。也有MLP和linear classifier分类分割区域

解决混淆的输入:对于一个prompt,模型会输出3个mask,实际上也可以输出更多的分割结果,3个可以看作一个物体的整体、部分、子部分,基本能满足大多数情况。使用IOU的方式,排序mask。在反向传播时,参与计算的只有loss最小的mask相关的参数