Flink介绍——实时计算核心论文之Flink论文
引入
通过前面的文章,我们梳理了大数据流计算的核心发展脉络:
- S4论文详解
- S4论文总结
- Storm论文详解
- Storm论文总结
- Kafka论文详解
- Kafka论文总结
- MillWheel论文详解
- MillWheel论文总结
- Dataflow论文详解
- Dataflow论文总结
而我们专栏的主角Flink正是站在前人的肩膀上,不断迭代,目前已经是实时流计算的最佳实践技术,下面我们就通过Flink的2015年发布的《Apache Flink: Stream and Batch Processing in a Single Engine》这篇论文,去一探究竟。
摘要
Apache Flink 是一个用于处理流数据和批数据的开源系统。Flink 基于这样一种理念构建:许多类型的数据处理应用,包括实时分析、持续数据管道、历史数据处理(批处理)以及迭代算法(机器学习、图分析),都可以表示为有容错能力的流水线数据流并加以执行。在本文中,我们介绍 Flink 的架构,并详细阐述如何将(看似多样的)一系列用例统一在单一执行模型之下。
1. 引言
传统上,数据流处理(例如复杂事件处理系统所代表的)和静态(批量)数据处理(例如 MPP 数据库和 Hadoop 所代表的)被视为两种截然不同的应用类型。它们使用不同的编程模型和 API 进行编程,并由不同的系统执行(例如,像 Apache Storm、IBM Infosphere Streams、Microsoft StreamInsight 或 Streambase 这样的专用流处理系统,与关系数据库或 Hadoop 执行引擎,包括 Apache Spark 和 Apache Drill 相对)。传统上,批数据处理在使用场景、数据规模和市场中占据了最大份额,而流数据分析主要服务于特定应用。
然而,越来越明显的是,如今大量的大规模数据处理用例处理的数据实际上是随着时间不断生成的。这些连续的数据流例如来自网络日志、应用程序日志、传感器,或者是数据库中应用程序状态的变化(事务日志记录)。如今的设置并没有将这些流视为流,而是忽略了数据生成的连续性和及时性。相反,数据记录(通常是人为地)被批量处理成静态数据集(例如,按小时、天或月的数据块),然后以与时间无关的方式进行处理。数据收集工具、工作流管理器和调度器协调批次的创建和处理,而这实际上是一个连续的数据处理管道。像 “lambda 架构”[21] 这样的架构模式将批处理和流处理系统结合起来,实现多条计算路径:一条用于及时获取近似结果的快速流处理路径,以及一条用于后期获取准确结果的批处理离线路径。所有这些方法都存在高延迟(由批次导致)、高复杂性(连接和协调多个系统,并两次实现业务逻辑)以及任意的不准确性等问题,因为时间维度并没有由应用程序代码明确处理。
Apache Flink 遵循一种范式,即在编程模型和执行引擎中,将数据流处理作为实时分析、连续流和批处理的统一模型。结合允许对数据流进行准任意重放的持久化消息队列(如 Apache Kafka 或 Amazon Kinesis),流处理程序在实时处理最新事件、在大窗口中定期连续聚合数据,或处理数 TB 的历史数据之间没有区别。相反,这些不同类型的计算只是在持久化流中的不同点开始处理,并在计算过程中维护不同形式的状态。通过高度灵活的窗口机制,Flink 程序可以在同一操作中计算早期近似结果以及延迟准确结果,从而无需为这两种用例组合不同的系统。Flink 支持不同的时间概念(事件时间、摄入时间、处理时间),以便为程序员在定义事件应如何关联方面提供高度的灵活性。
同时,Flink 认识到现在以及将来都存在对专用批处理(处理静态数据集)的需求。对静态数据的复杂查询仍然很适合批处理抽象。此外,对于遗留的流处理用例实现,以及对于尚不知道在流数据上执行此类处理的高效算法的分析应用程序,仍然需要批处理。批处理程序是流处理程序的特殊情况,其中流是有限的,并且记录的顺序和时间无关紧要(所有记录隐含地属于一个涵盖所有的窗口)。然而,为了以具有竞争力的易用性和性能支持批处理用例,Flink 有一个用于处理静态数据集的专用 API,对连接或分组等操作符的批处理版本使用专用的数据结构和算法,并使用专用的调度策略。结果是,Flink 在流运行时之上呈现为一个成熟且高效的批处理器,包括用于图分析和机器学习的库。Flink 源自 Stratosphere 项目 [4],是 Apache 软件基金会的顶级项目,由一个庞大且活跃的社区开发和支持(撰写本文时,有超过 180 名开源贡献者),并在多家公司的生产环境中使用。
本文的贡献如下:
- 我们提出了一种流和批数据处理的统一架构,包括仅与静态数据集相关的特定优化。
- 我们展示了如何将流处理、批处理、迭代和交互式分析表示为容错的流数据流(在第 3 节)。
- 我们讨论了如何通过展示流处理、批处理、迭代和交互式分析如何表示为流数据流,在这些数据流之上构建一个具有灵活窗口机制的成熟流分析系统(在第 4 节),以及一个成熟的批处理器(在第 4.1 节)。
2. 系统架构
在本节中,我们将 Flink 的架构阐述为一个软件栈和一个分布式系统。虽然 Flink 的 API 栈在不断发展,但我们可以区分出四个主要层:部署层、核心层、API 层和库层。
Flink 的运行时与应用程序编程接口(APIs)
图 1 展示了 Flink 的软件堆栈。Flink 的核心是分布式数据流引擎,用于执行数据流程序。一个 Flink 运行时程序是由有状态算子组成的有向无环图(DAG),这些算子通过数据流相互连接。Flink 中有两个核心 API:用于处理有限数据集的数据集(DataSet)API(通常称为批处理),以及用于处理可能无限的数据流的数据流(DataStream)API(通常称为流处理)。Flink 的核心运行时引擎可以看作是一个流式数据流引擎,DataSet 和 DataStream 这两个 API 所创建的运行时程序都能由该引擎执行。因此,它作为一个通用架构,对有界(批处理)和无界(流处理)处理进行了抽象。在核心 API 之上,Flink 集成了特定领域的库和 API,用于生成 DataSet 和 DataStream API 程序,目前有用于机器学习的 FlinkML、用于图处理的 Gelly 以及用于类似 SQL 操作的 Table。
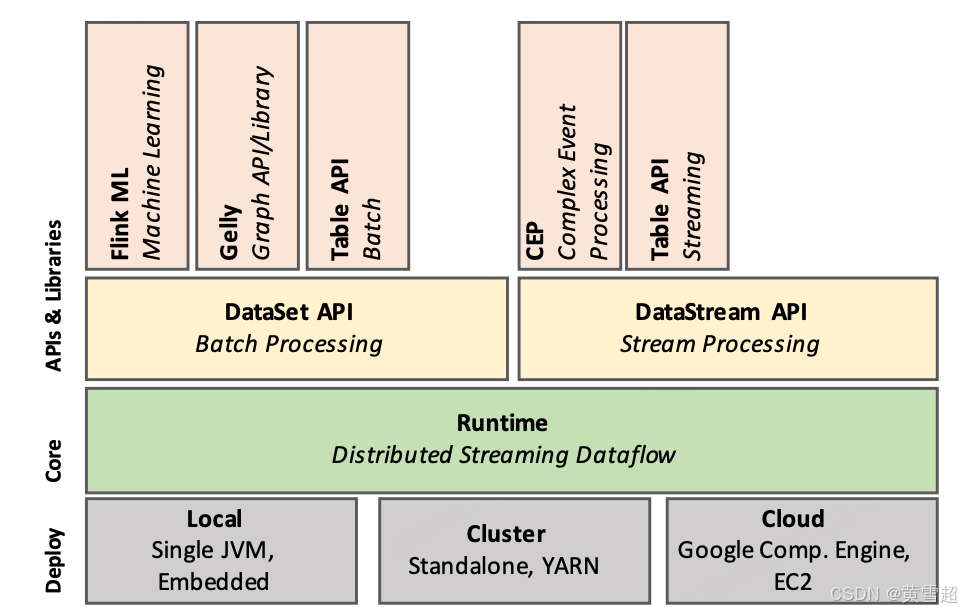
图 1:Flink 软件堆栈
如图 2 所示,一个 Flink 集群包含三种类型的进程:客户端、作业管理器(Job Manager)以及至少一个任务管理器(Task Manager)。客户端获取程序代码,将其转换为数据流图,然后提交给作业管理器。在这个转换阶段,还会检查算子之间交换数据的数据类型(模式),并创建序列化器和其他特定于类型 / 模式的代码。DataSet 程序还会经历基于成本的查询优化阶段,类似于关系型查询优化器所执行的物理优化(更多细节见 4.1 节)。
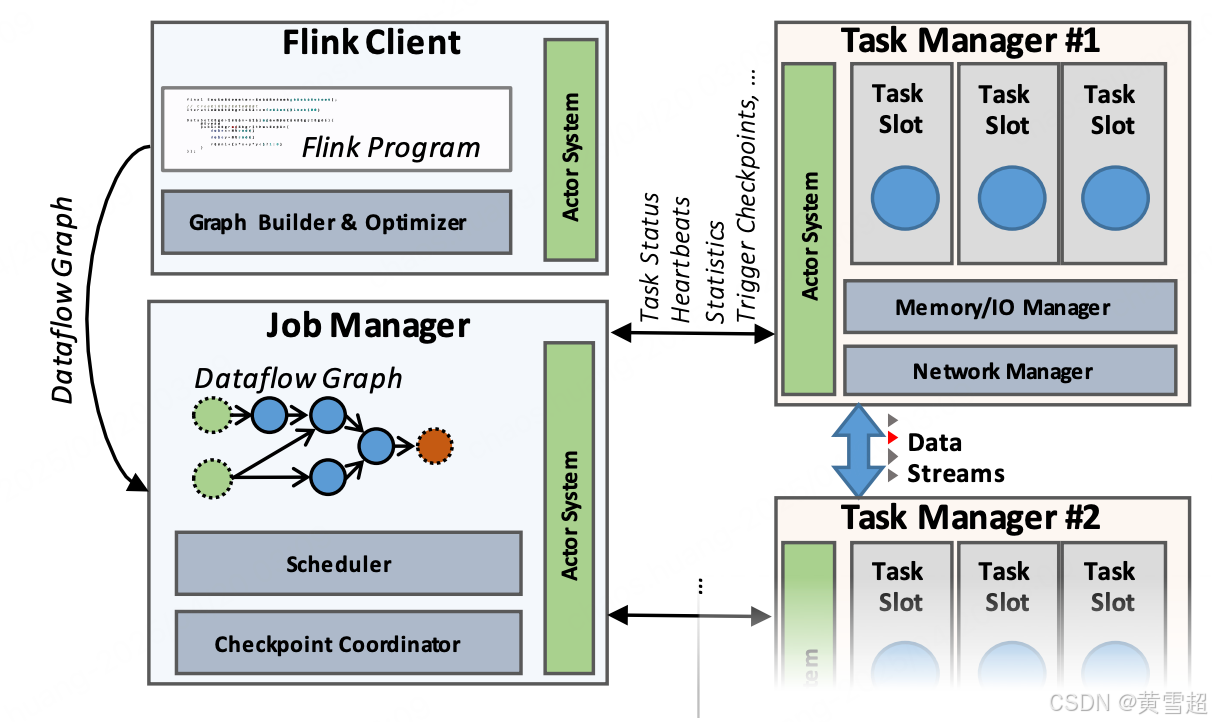
图 2:Flink 进程模型
作业管理器协调整个数据流的分布式执行。它跟踪每个算子和数据流的状态与进度,调度新的算子,并协调查点和恢复。在高可用设置中,作业管理器会在每次检查点时将一组最小化的元数据持久化到一个容错存储中,以便备用的作业管理器能够重构检查点并从该点恢复数据流的执行。实际的数据处理在任务管理器中进行。一个任务管理器执行一个或多个生成数据流的算子,并向作业管理器报告它们的状态。任务管理器维护缓冲池以缓冲或具体化数据流,并维护网络连接以便在算子之间交换数据流。
关键词拓展介绍:
- 有向无环图(Directed Acyclic Graph, DAG):在计算机科学中,尤其是在数据流处理和分布式计算领域经常使用。它是一种有向图,其中从任何节点出发沿着有向边前进,都无法回到该节点,即不存在回路。在 Flink 中,将运行时程序表示为 DAG 有助于清晰地描述算子之间的数据流动和依赖关系,使得系统能够高效地调度和执行任务。例如,在一个数据处理流程中,可能先有数据读取算子,然后数据经过过滤算子、转换算子等,这些算子按照特定顺序连接形成 DAG,Flink 可以基于此进行优化和并行执行。
- 算子(Operator):是 Flink 数据处理的基本单元,负责对数据流中的数据执行特定操作,如过滤、转换、聚合等。每个算子都有输入和输出,输入来自上游算子的数据流,处理后的数据通过输出传递给下游算子。有状态算子意味着算子在处理数据过程中会维护一些状态信息,比如窗口聚合算子需要记住窗口内的数据以进行计算。
- 序列化器(Serializer):在分布式系统中,数据需要在不同节点之间传输,而不同节点的内存布局和数据表示可能不同。序列化器的作用就是将数据对象转换为字节流的形式,以便在网络上传输或存储,在接收端再通过反序列化将字节流恢复为原始的数据对象。在 Flink 中,根据数据类型和模式创建合适的序列化器,能确保数据在不同算子和节点间准确无误地传输。
- 基于成本的查询优化(Cost - based Query Optimization):是一种数据库查询优化技术,它通过评估不同查询执行计划的成本(如 CPU 使用、内存占用、I/O 操作等),选择成本最低的执行计划来提高查询性能。在 Flink 的 DataSet 程序中应用这种优化,与关系型数据库的物理优化类似,能够根据数据量、算子复杂度等因素,合理安排数据处理的顺序和方式,从而提升批处理的效率。
3 通用架构:流式数据流
尽管用户可以使用多种 API 编写 Flink 程序,但所有 Flink 程序最终都会编译为一种通用表示形式:数据流图。数据流图由 Flink 的运行时引擎执行,该运行时引擎是批处理(DataSet)和流处理(DataStream)API 之下的通用层。
3.1 数据流图
如图 3 所示,数据流图是一种有向无环图(DAG),它由以下部分组成:(i)有状态算子;(ii)数据流,这些数据流表示由某个算子产生的数据,可供其他算子使用。由于数据流图是以数据并行的方式执行的,算子会被并行化为一个或多个称为子任务的并行实例,数据流也会被拆分为一个或多个流分区(每个产生数据的子任务对应一个分区)。有状态算子(无状态算子是其特殊情况)实现所有的处理逻辑(例如,过滤、哈希连接和流窗口函数)。其中许多算子是知名算法经典版本的实现。在第 4 节中,我们将详细介绍窗口算子的实现。数据流以各种模式在产生数据和使用数据的算子之间分发数据,例如点对点、广播、重新分区、扇出和合并。
关键词拓展介绍:
- 数据并行(Data - parallel):是分布式计算中的一种并行计算方式,它将数据划分为多个部分,不同的计算节点或任务并行处理不同的数据部分。在 Flink 中,通过将算子并行化为子任务,每个子任务处理数据流的一个分区,从而实现数据并行。这样可以充分利用集群的计算资源,提高处理大规模数据的效率。例如,在处理一个大数据集的聚合操作时,可以将数据集分成多个部分,由不同的子任务并行计算各个部分的聚合结果,最后再合并这些结果得到最终的聚合值。
- 点对点(Point - to - point):一种数据传输模式,在该模式下,数据从一个特定的生产者直接传输到一个特定的消费者,就像在一条专用的通道上传输数据,一对一的关系非常明确。在 Flink 的数据流中,如果一个算子的某个子任务只将数据发送给另一个算子的特定子任务,这就是点对点的数据分发模式。
- 广播(Broadcast):在这种数据分发模式中,一个算子产生的数据会被复制并发送到下游算子的所有并行实例(子任务)。常用于需要将一些全局配置信息或字典数据等发送给所有处理节点的场景。例如,在一个流处理任务中,如果需要所有节点都依据相同的规则进行数据过滤,就可以将这些规则以广播的方式发送给所有相关算子的子任务。
- 重新分区(Re - partition):指改变数据流中数据分区方式的操作。在 Flink 中,数据最初可能以某种分区方式分布,但根据后续算子的需求,可能需要重新分区,以实现更好的并行处理效果。比如,为了进行更高效的聚合操作,可能需要将原本按照某种键值随机分布的数据,重新按照聚合键进行分区。
- 扇出(Fan - out):类似于广播,但可能不是发送到所有下游实例,而是根据一定规则将数据分发给多个下游实例。例如,一个算子根据数据的不同特征,将数据分别发送到不同功能的下游算子进行处理,就像将一条数据 “扇出” 到多个分支。
- 合并(Merge):与扇出相反,它是将多个数据流合并为一个数据流的操作。在 Flink 中,多个上游算子产生的数据流可以通过合并操作汇聚到一个下游算子进行统一处理。例如,在进行多源数据的联合分析时,就需要先将不同来源的数据流合并。
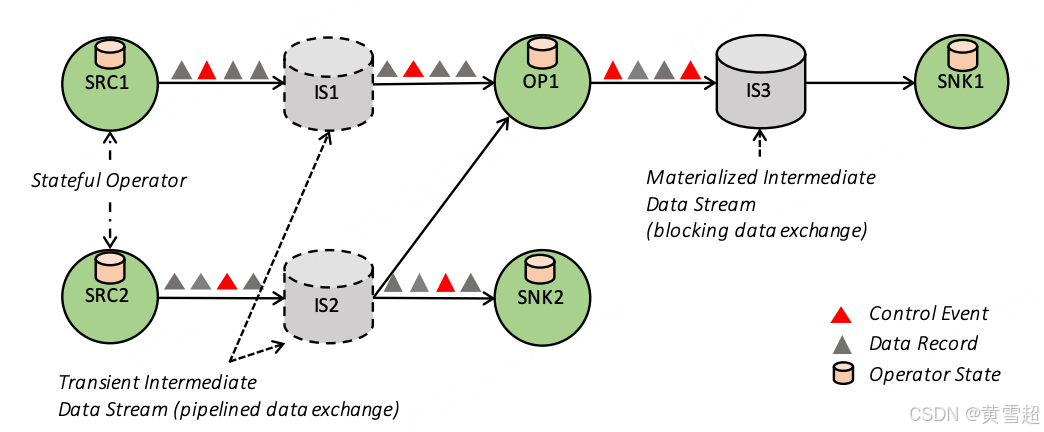
图 3:一个简单的数据流图
3.2 通过中间数据流进行数据交换
Flink 的中间数据流是算子之间数据交换的核心抽象。中间数据流代表了对算子产生的数据的一种逻辑引用,这些数据可以被一个或多个算子使用。中间流之所以是逻辑上的,是因为它们所指向的数据可能会也可能不会在磁盘上物化。数据流的特定行为由 Flink 的高层进行参数化设置(例如,DataSet API 使用的程序优化器)。
流水线式与阻塞式数据交换:流水线式中间流在并发运行的生产者和消费者之间交换数据,从而实现流水线式执行。因此,流水线式流会将消费者的背压反馈给生产者,通过中间缓冲池提供一定的弹性,以补偿短期的吞吐量波动。Flink 在连续流程序以及批处理数据流的许多部分都使用流水线式流,尽可能避免数据物化。另一方面,阻塞式流适用于有界数据流。阻塞式流会在将数据提供给消费者之前,先缓冲产生数据的算子的所有数据,从而将产生数据的算子和消费数据的算子分隔为不同的执行阶段。阻塞式流自然需要更多内存,经常会溢出到二级存储,并且不会传递背压。它们用于在需要时将连续的算子相互隔离,以及在诸如排序合并连接等可能导致分布式死锁的具有打破流水线的算子的场景中使用。
平衡延迟与吞吐量:Flink 的数据交换机制围绕缓冲区的交换来实现。当生产者端的数据记录准备好时,它会被序列化并拆分成一个或多个缓冲区(一个缓冲区也可以容纳多条记录),这些缓冲区可以转发给消费者。缓冲区会在以下两种情况之一被发送给消费者:(i)一旦缓冲区满了;(ii)当达到超时条件时。这使得 Flink 可以通过将缓冲区大小设置为较高的值(例如,几千字节)来实现高吞吐量,通过将缓冲区超时时间设置为较低的值(例如,几毫秒)来实现低延迟。图 4 展示了在 30 台机器(120 个核心)上的一个简单流过滤(grep)作业中,缓冲区超时时间对记录传输的吞吐量和延迟的影响。Flink 可以实现 20 毫秒的可观测的 99% 延迟。相应的吞吐量是每秒 150 万个事件。随着我们增加缓冲区超时时间,我们会看到延迟随着吞吐量的增加而增加,直到达到最大吞吐量(即缓冲区填满的速度比超时到期的速度快)。在缓冲区超时时间为 50 毫秒时,集群达到每秒超过 8000 万个事件的吞吐量,99% 延迟为 50 毫秒。
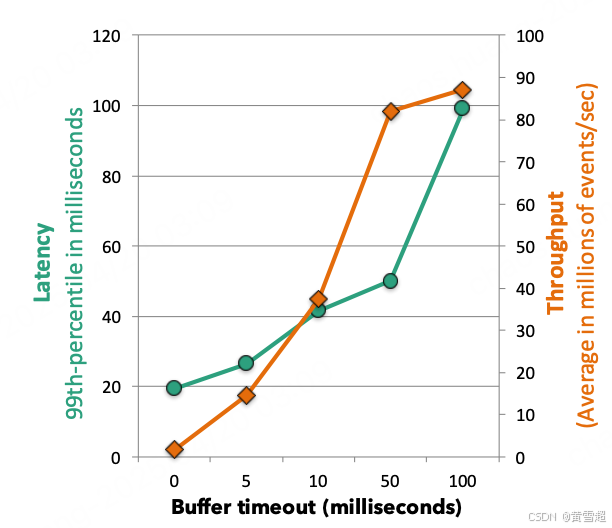
图 4:缓冲区超时对延迟和吞吐量的影响
控制事件:除了交换数据,Flink 中的流还会传递不同类型的控制事件。这些是由算子注入到数据流中的特殊事件,并与流分区内的所有其他数据记录和事件按顺序传递。接收算子在这些事件到达时,通过执行特定操作来做出反应。Flink 使用多种特殊类型的控制事件,包括:
- 检查点屏障,通过将流划分为检查点前和检查点后的数据来协调检查点(在 3.3 节讨论),
- 水位线,用于表示流分区内事件时间的进展(在 4.1 节讨论),
- 迭代屏障,用于表示流分区已到达超步(superstep)的末尾,用于基于循环数据流的批量 / 陈旧同步并行迭代算法(在 5.3 节讨论)。
如前所述,控制事件假定流分区会保留记录的顺序。为此,Flink 中消耗单个流分区的一元算子保证记录的先进先出(FIFO)顺序。然而,接收多个流分区的算子会按到达顺序合并流,以跟上流的速率并避免背压。因此,Flink 中的流数据流在任何形式的重新分区或广播之后,都不提供顺序保证,处理乱序记录的责任留给算子实现。我们发现这种安排提供了最有效的设计,因为大多数算子不需要确定性顺序(例如,哈希连接、映射),而需要补偿乱序到达的算子,例如事件时间窗口,可以作为算子逻辑的一部分更有效地做到这一点。
关键词拓展介绍:
- 背压(Back Pressure):在数据处理系统中,当数据的生产速度超过了消费速度时,就会出现背压现象。在 Flink 的流水线式数据交换中,消费者处理数据较慢时,会导致数据在中间缓冲区堆积,最终影响到生产者的生产速度,这种从消费者向生产者反馈的压力就是背压。通过中间缓冲池的弹性机制,Flink 可以在一定程度上应对背压,避免系统崩溃。
- 物化(Materialization):在数据处理中,物化指将逻辑上的数据(如中间计算结果)实际存储到物理介质
3.3 容错
Flink 提供可靠的执行,具备严格的 “精确一次处理” 一致性保证,并通过检查点和部分重执行来处理故障。为了有效地提供这些保证,系统的一般假设是数据源是持久且可重放的。此类数据源的示例包括文件和持久消息队列(例如,Apache Kafka)。在实际应用中,通过在源算子的状态中保留预写日志,非持久数据源也可以被纳入其中。
Apache Flink 的检查点机制基于分布式一致性快照的概念,以实现 “精确一次处理” 的保证。数据流可能具有无界性,这使得故障恢复时的重新计算不太现实,因为对于长时间运行的作业,可能需要重放数月的计算。为了限制恢复时间,Flink 会定期对算子的状态进行快照,包括输入流的当前位置。
核心挑战在于在不停止拓扑执行的情况下,对所有并行算子进行一致性快照。本质上,所有算子的快照都应对应于计算中的相同逻辑时间。Flink 中使用的机制称为异步屏障快照(ABS [7])。屏障是注入到输入流中的控制记录,它们对应于一个逻辑时间,并在逻辑上将流分为两部分:其影响将包含在当前快照中的部分,以及稍后将被快照的部分。
一个算子从上游接收屏障,首先执行对齐阶段,确保已接收所有输入的屏障。然后,算子将其状态(例如,滑动窗口的内容或自定义数据结构)写入持久存储(例如,存储后端可以是 HDFS 等外部系统)。一旦状态备份完成,算子就将屏障转发到下游。最终,所有算子都将记录其状态的快照,全局快照也就完成了。例如,在图 5 中,我们展示了快照 t2 包含所有算子状态,这些状态是在 t2 屏障之前消耗所有记录的结果。异步屏障快照与用于异步分布式快照的 Chandy - Lamport 算法有相似之处 [11]。然而,由于 Flink 程序的有向无环图(DAG)结构,异步屏障快照不需要对正在传输中的记录进行检查点操作,而仅依赖对齐阶段将这些记录的所有影响应用到算子状态上。这保证了需要写入可靠存储的数据量保持在理论最小值(即仅算子的当前状态)。
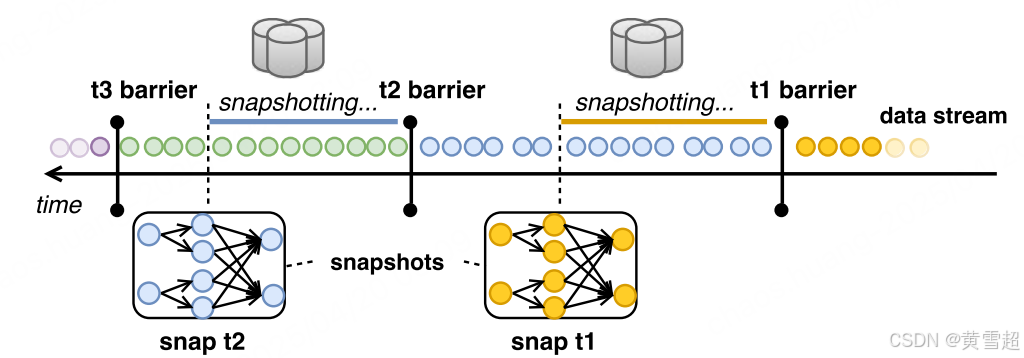
图 5:异步屏障快照
从故障中恢复时,会将所有算子状态恢复到上次成功快照时的相应状态,并从有快照的最新屏障处重新启动输入流。恢复时所需的最大重新计算量限制在两个连续屏障之间的输入记录数量。此外,通过额外重放直接上游子任务中缓冲的未处理记录,还可以对失败的子任务进行部分恢复 [7]。
异步屏障快照具有几个优点:i)它保证精确一次的状态更新,且从不暂停计算;ii)它与其他形式的控制消息完全解耦(例如,由触发窗口计算的事件解耦,从而不将窗口机制限制为检查点间隔的倍数);iii)它与用于可靠存储的机制完全解耦,允许根据 Flink 使用的更大环境,将状态备份到文件系统、数据库等。
关键词拓展介绍:
- 精确一次处理(Exactly - Once Processing):这是流处理系统中非常重要的一致性语义,意味着无论系统发生何种故障,每个输入记录都只会对最终结果产生一次影响。Flink 通过异步屏障快照等机制来确保这一语义,避免数据重复处理或处理不足的情况。
- 预写日志(Write - Ahead Log,WAL):一种日志记录策略,在对数据进行实际修改之前,先将修改操作记录到日志中。这样在系统故障后,可以通过重放日志来恢复数据到故障前的状态。在 Flink 处理非持久数据源时,利用预写日志可模拟数据源的持久性和可重放性。
- 有向无环图(Directed Acyclic Graph,DAG):在 Flink 程序中,DAG 用于表示数据流的拓扑结构,节点表示算子,边表示数据流的流向。DAG 结构使得 Flink 能够有效地对作业进行调度和优化,并且在异步屏障快照机制中,这种结构简化了检查点的处理过程,使得无需对正在传输中的记录进行检查点操作。
- 异步屏障快照(Asynchronous Barrier Snapshotting):是 Flink 实现分布式一致性检查点的关键技术。在分布式流处理系统中,为了保证在故障发生时能够恢复到某个一致状态,需要定期对系统状态进行快照。异步屏障快照通过在数据流中插入特殊的屏障(barrier)来标记快照的边界。这些屏障异步地在数据流中传播,使得各个算子可以独立地对自己的状态进行快照,而不会阻塞数据流的正常处理。这样既保证了系统的高可用性,又能在不影响正常数据处理的情况下获取准确的系统状态快照,以便在故障恢复时使用。
3.4 迭代数据流
增量处理和迭代对于图处理和机器学习等应用至关重要。数据并行处理平台对迭代的支持通常依赖于为每次迭代提交一个新作业,或者通过向正在运行的有向无环图(DAG)添加额外节点 [6, 25] 或反馈边 [23]。
Flink 中的迭代是作为迭代步骤来实现的,这些特殊算子自身可以包含一个执行图(图 6)。为了维持基于有向无环图的运行时和调度器,Flink 允许存在迭代 “头” 和迭代 “尾” 任务,它们通过反馈边隐式连接。这些任务的作用是为迭代步骤建立一个活动反馈通道,并为处理该反馈通道内传输的数据记录提供协调。实现任何类型的结构化并行迭代模型(如批量同步并行(BSP)模型)都需要协调,这是通过控制事件来实现的。我们将分别在 4.4 节和 5.3 节解释迭代在 DataStream 和 DataSet API 中是如何实现的。
关键词拓展介绍:
- 增量处理(Incremental Processing):在数据处理场景中,增量处理指的是系统能够处理新到达的数据,并基于之前处理的结果,以一种逐步的、递增的方式更新最终的处理结果,而不需要重新处理所有数据。例如在机器学习模型训练中,新的数据样本到达时,模型可以基于之前训练得到的参数,增量地更新模型,而无需从头开始训练。
- 批量同步并行(Bulk Synchronous Parallel,BSP)模型:一种并行计算模型,在该模型中,计算被组织成一系列的超步(superstep)。在每个超步中,所有处理器并行执行本地计算,然后进行同步通信,交换数据。这种模型的特点是简单且易于理解和实现,常用于大规模数据并行计算,例如图算法和机器学习算法的实现。在 Flink 中,实现类似 BSP 模型的迭代时,通过迭代 “头” 和 “尾” 任务以及控制事件来协调各部分的工作,以达到同步和数据交换的目的。
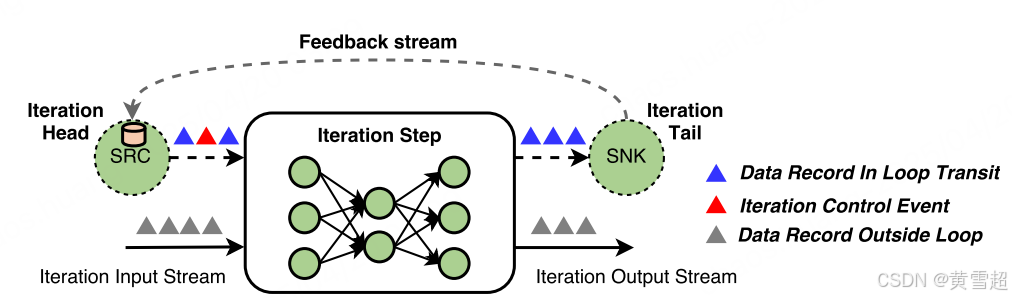
图 6:Apache Flink 的迭代模型
4. 基于数据流的流分析
Flink 的 DataStream API 在 Flink 运行时之上实现了一个完整的流分析框架,其中包括管理时间的机制,例如乱序事件处理、定义窗口,以及维护和更新用户定义的状态。流处理 API 基于 DataStream 的概念,DataStream 是给定类型元素的(可能无界的)不可变集合。由于 Flink 的运行时已经支持流水线式的数据传输、连续的有状态算子,以及用于一致性状态更新的容错机制,因此在其之上构建流处理器本质上归结为实现一个窗口系统和一个状态接口。如前所述,这些对于运行时来说是不可见的,运行时将窗口仅仅视为有状态算子的一种实现。
4.1 时间的概念
Flink 区分了两种时间概念:i)事件时间,它表示事件产生的时间(例如,与来自传感器(如移动设备)的信号相关联的时间戳);ii)处理时间,它是处理数据的机器的挂钟时间。
在分布式系统中,事件时间和处理时间之间存在任意偏差 [3]。这种偏差可能意味着基于事件时间语义获取答案时会出现任意延迟。为了避免任意延迟,这些系统会定期插入称为水位线的特殊事件,以标记全局进度。例如,在时间推进的情况下,水位线包含一个时间属性 t,表示所有小于 t 的事件都已进入算子。水位线有助于执行引擎以正确的事件顺序处理事件,并通过统一的进度度量对诸如窗口计算之类的操作进行序列化。
水位线起源于拓扑结构的数据源,在那里我们可以确定未来元素中固有的时间。水位线从数据源传播到数据流的其他算子。算子决定如何对水位线做出反应。简单操作,如 map 或 filter 只是转发它们接收到的水位线,而更复杂的基于水位线进行计算的算子(例如事件时间窗口)首先计算由水位线触发的结果,然后再转发水位线。如果一个操作有多个输入,系统仅将传入水位线中的最小值转发给该算子,从而确保结果的正确性。
基于处理时间的 Flink 程序依赖于本地机器时钟,因此时间概念不太可靠,这可能导致恢复时重放不一致。然而,它们具有较低的延迟。基于事件时间的程序提供了最可靠的语义,但由于事件时间与处理时间的滞后,可能会出现延迟。Flink 引入了第三种时间概念,作为事件时间的一种特殊情况,称为摄入时间,即事件进入 Flink 的时间。这实现了比事件时间更低的处理延迟,并且与处理时间相比能得到更准确的结果。
关键词拓展介绍:
- DataStream API:Flink 用于流处理的核心 API,它提供了丰富的操作符(如 map、filter、window 等)来处理无界数据流。通过 DataStream API,开发者可以方便地构建复杂的流处理应用,实现实时数据处理和分析。例如在实时监控系统中,可以使用 DataStream API 对传感器实时发送的数据进行处理和分析。
- 事件时间(Event - Time):在流处理中,事件时间是事件实际发生的时间,它通常通过事件携带的时间戳来表示。使用事件时间可以确保流处理结果的准确性,不受数据到达处理系统的顺序和时间的影响。例如在电商订单处理中,以订单生成时间(事件时间)来统计不同时间段的订单量,能更真实地反映业务情况。
- 处理时间(Processing - Time):指数据在 Flink 算子中实际被处理的时间,即机器的系统时钟时间。基于处理时间的处理具有较低的延迟,但由于不同机器的时钟可能存在偏差,以及故障恢复等情况,可能导致结果的不一致性。例如在实时流量统计场景中,如果使用处理时间,统计结果会受到系统处理速度和机器时钟的影响。
- 水位线(Watermark):是 Flink 中用于处理乱序事件的关键机制。它是一种特殊的事件,用于告知流处理引擎某个时间点之前的数据已经全部到达,从而可以触发相关窗口操作的计算。例如在一个实时计算每 5 分钟内订单金额总和的任务中,如果设置了合适的水位线,即使订单数据乱序到达,也能在水位线到达后准确计算出每个 5 分钟窗口内的订单金额总和。
- 摄入时间(Ingestion - Time):作为事件时间的特殊情况,它是事件进入 Flink 系统的时间。摄入时间在一定程度上平衡了事件时间的准确性和处理时间的低延迟特性。在一些对延迟有一定要求,同时又希望结果相对准确的场景中比较适用
4.2 有状态流处理
虽然 Flink 的 DataStream API 中的大多数算子看似是无副作用的函数式算子,但它们为高效的有状态计算提供支持。状态对于许多应用至关重要,例如机器学习模型构建、图分析、用户会话处理以及窗口聚合。根据用例的不同,存在大量不同类型的状态。例如,状态可以简单到像一个计数器或求和值,也可以更复杂,比如机器学习应用中常用的分类树或大型稀疏矩阵。流窗口是有状态算子,它将记录分配到作为算子状态一部分保存在内存中的持续更新的存储桶中。
在 Flink 中,状态通过以下方式被显式化并整合到 API 中:i)提供算子接口或注解,以便在算子作用域内静态注册显式局部变量;ii)提供算子状态抽象,用于声明分区的键值状态及其相关操作。用户还可以使用系统提供的 StateBackend 抽象来配置状态的存储和检查点方式,从而在流应用中实现高度灵活的自定义状态管理。Flink 的检查点机制(在 3.3 节中讨论)保证任何已注册的状态都是持久的,并具有精确一次更新语义。
关键词拓展介绍:
- 有状态流处理(Stateful Stream Processing):在流处理场景中,有状态流处理指的是算子在处理数据流时,能够记住之前处理过的数据的某些信息(即状态),并基于这些状态对新到来的数据进行处理。与无状态算子(如简单的 map 和 filter 算子,它们处理每个数据元素时不依赖之前元素的信息)不同,有状态算子可以根据过去的数据做出更复杂的决策。例如在实时计算用户活跃度时,算子需要记住每个用户之前的活动记录(状态),以便计算当前的活跃度。
- StateBackend:Flink 中的 StateBackend 是一个重要的抽象概念,用于定义状态如何存储和管理。它主要有三种类型:MemoryStateBackend、FsStateBackend 和 RocksDBStateBackend。MemoryStateBackend 将状态存储在内存中,适合数据量较小且对性能要求极高的场景,但在发生故障时恢复能力有限。FsStateBackend 将状态存储在文件系统(如 HDFS)中,适合中等规模数据,具有较好的故障恢复能力。RocksDBStateBackend 则利用 RocksDB 这种嵌入式数据库来存储状态,适用于大规模状态存储,并且在处理海量数据时能提供较好的性能和可靠性。用户可以根据应用的需求选择合适的 StateBackend 来优化状态管理。
4.3 流窗口
对无界流的增量计算,常常是在不断演变的逻辑视图上进行评估的,这些逻辑视图被称作窗口。Apache Flink 在有状态算子中融入了窗口机制,它通过一个由三个核心函数构成的灵活声明来配置:一个窗口分配器,以及可选的一个触发器和一个移除器。
这三个函数既可以从一组常见的预定义实现(例如滑动时间窗口)中选择,也可以由用户显式定义(即用户自定义函数)。
更具体地说,分配器负责将每条记录分配到逻辑窗口。例如,在事件时间窗口的情况下,这一分配决策可以基于记录的时间戳。请注意,在滑动窗口的情形下,一个元素可能属于多个逻辑窗口。可选的触发器定义了与窗口定义相关的操作何时执行。最后,可选的移除器决定每个窗口内保留哪些记录。Flink 的窗口分配过程独具优势,能够涵盖所有已知的窗口类型,如周期性时间窗口和计数窗口、标点窗口、地标窗口、会话窗口和增量窗口。需要注意的是,Flink 的窗口功能能够无缝处理乱序数据,与 Google Cloud Dataflow [3] 类似,并且原则上包含了这些窗口模型。例如,下面是一个窗口定义,窗口范围为 6 秒,每 2 秒滑动一次(窗口分配器)。一旦水位线越过窗口末尾,就计算窗口结果(触发器)。
stream.window(SlidingTimeWindows.of(Time.of(6, SECONDS), Time.of(2, SECONDS)).trigger(EventTimeTrigger.create())
全局窗口会创建单个逻辑组。下面的示例定义了一个全局窗口(即窗口分配器),每 1000 个事件调用一次操作(即触发器),同时保留最后 100 个元素(即移除器)。
stream.window(GlobalWindow.create()).trigger(Count.of(1000)).evict(Count.of(100))
请注意,如果上述流在进行窗口操作之前按键分区,那么上述窗口操作就是局部的,因此无需在工作节点之间进行协调。这种机制可用于实现各种各样的窗口功能 [3]。
关键词拓展介绍:
- 窗口分配器(Window Assigner):它是决定数据记录如何被分配到不同窗口的组件。除了示例中的滑动时间窗口分配器
SlidingTimeWindows,还有滚动时间窗口分配器TumblingTimeWindows,它将数据按照固定的时间长度切分成不重叠的窗口;会话窗口分配器SessionWindows,会根据数据记录的时间间隔来划分窗口,如果间隔超过一定时间,则认为是新的会话窗口。不同的窗口分配器适用于不同的业务场景,比如在统计网站每小时的访问量时,适合使用滚动时间窗口;而在分析用户的一次连续操作行为时,会话窗口更为合适。- 触发器(Trigger):用于确定窗口内的计算何时被触发。除了示例中的事件时间触发器
EventTimeTrigger,还有处理时间触发器ProcessingTimeTrigger,它基于处理时间来触发窗口计算;计数触发器CountTrigger,当窗口内的数据记录数量达到设定值时触发计算。选择合适的触发器能确保窗口计算在恰当的时机执行,满足不同的业务需求,比如在实时监控系统中,可能希望每收集到一定数量的数据就进行一次计算,这时计数触发器就比较适用。- 移除器(Evictor):它决定窗口内的数据记录在何时被移除。在示例中使用的计数移除器
CountEvictor,会按照设定的数量保留窗口内的记录。还有时间移除器TimeEvictor,可以根据数据记录的时间戳来移除窗口内较早的数据。移除器可以帮助控制窗口内的数据量,避免内存占用过高,同时也能对窗口内的数据进行筛选,只保留对计算有价值的数据。- 全局窗口(GlobalWindow):全局窗口会将所有数据记录分配到同一个窗口中。通常需要结合特定的触发器和移除器来使用,因为如果没有这些控制,窗口内的数据会持续累积。全局窗口在一些特殊场景下很有用,例如对整个数据流进行全局统计时,可以使用全局窗口结合合适的触发器和移除器来实现。
4.4 异步流迭代
流中的循环对于多种应用至关重要,例如增量构建和训练机器学习模型、强化学习以及图近似计算 [9, 15]。在大多数此类情况下,反馈循环无需协调。异步迭代满足了流应用程序的通信需求,并且与基于有限数据上结构化迭代的并行优化问题有所不同。如 3.4 节和图 6 所示,当未启用任何迭代控制机制时,Apache Flink 的执行模型已涵盖异步迭代。此外,为符合容错保证,反馈流在隐式迭代头算子中被视为算子状态,并且是全局快照的一部分 [7]。DataStream API 允许显式定义反馈流,并且可以轻易地支持流上的结构化循环 [23] 以及进度跟踪 [9]。
关键词拓展介绍:
- 异步流迭代(Asynchronous Stream Iterations):在流计算场景下,它为一些需要循环处理数据的应用提供了有效的解决方案。例如在机器学习模型的增量训练中,新的数据不断流入,模型需要基于新数据不断更新自身状态。异步流迭代允许这种更新操作异步进行,不会阻塞整个流处理流程,提高了系统的处理效率和响应性。
- 反馈流(Feedback Streams):在异步流迭代中,反馈流起着关键作用。它携带了经过一轮处理后的结果数据,这些数据会被反馈到流处理的起始阶段,参与下一轮的计算。比如在一个不断优化推荐模型的流处理系统中,每次根据新用户行为数据调整推荐模型后,模型生成的推荐结果(构成反馈流)会被送回与新的用户行为数据一起,再次优化推荐模型。在 Flink 中,反馈流作为算子状态的一部分,被纳入全局快照,这保证了在出现故障时,系统能够恢复到故障前的迭代状态,继续进行迭代计算,从而确保了容错性。
5. 基于数据流的批处理分析
有界数据集是无界数据流的一种特殊情况。因此,一个将其所有输入数据插入到一个窗口中的流处理程序可以构成一个批处理程序,并且上述 Flink 的特性应能完全涵盖批处理。然而,其一,语法(即批处理计算的 API)可以简化(例如,无需人为定义全局窗口);其二,处理有界数据集的程序适合进行额外的优化、更高效的容错记录管理以及分阶段调度。
Flink 对批处理的处理方式如下:
- 批处理计算与流计算由相同的运行时执行。运行时可执行文件可以通过阻塞数据流进行参数化,以便将大型计算分解为依次调度的孤立阶段。
- 当定期快照的开销过高时,将其关闭。取而代之的是,通过从最新的物化中间流(可能是数据源)重放丢失的流分区来实现故障恢复。
- 阻塞算子(例如排序)仅仅是一些碰巧会阻塞直到消耗完其全部输入的算子实现。运行时并不知道某个算子是否阻塞。这些算子使用 Flink 提供的托管内存(可以在 JVM 堆上或堆外),如果其输入超出内存限制,则可以溢出到磁盘。
- 专门的 DataSet API 为批处理计算提供了常见的抽象,即有界且容错的 DataSet 数据结构以及对 DataSet 的转换操作(例如连接、聚合、迭代)。
- 查询优化层将 DataSet 程序转换为高效的可执行程序。
下面我们将更详细地描述这些方面。
关键词拓展介绍:
- 有界数据集与无界数据流关系:从概念上,有界数据集可以看作是在某个时间点数据停止流入的无界数据流。在 Flink 中基于这种关系,使得流处理的很多机制可以复用在批处理上。例如流处理中的窗口机制,在批处理场景下,可将整个有界数据集视为一个窗口数据来处理。
- 批处理运行时:与流计算共用运行时,这体现了 Flink 统一流批处理的设计理念。通过阻塞数据流参数化运行时可执行文件来分阶段调度计算,这样做可以更好地管理资源和控制计算流程。例如在处理大规模批数据时,将计算分成多个阶段依次执行,避免一次性加载过多数据导致内存溢出等问题。
- 故障恢复策略:批处理中,当定期快照开销大时,采用从最新物化中间流重放丢失流分区的方式恢复故障。物化中间流是在计算过程中,将某些中间结果数据持久化存储下来,这样在出现故障时,可以从这些持久化的数据重新开始计算,减少了重新计算的范围,提高恢复效率。比如在一个多步骤的批处理作业中,中间步骤的结果被物化存储,若后续步骤出现故障,可从物化的中间结果处重新启动作业。
- 阻塞算子:像排序这样的阻塞算子在 Flink 批处理中,会一直阻塞直到处理完所有输入数据。Flink 提供的托管内存可用于这些算子的计算,并且支持内存溢出到磁盘,这使得即使处理超出内存容量的数据也能顺利进行。例如在对一个非常大的数据集进行排序时,数据可能无法一次性全部加载到内存,此时算子可以将部分数据暂存到磁盘,分批处理完成排序操作。
- DataSet API:它是 Flink 为批处理专门设计的 API,提供了 DataSet 数据结构以及各种对 DataSet 的转换操作。DataSet 数据结构是有界且容错的,这意味着在批处理过程中,如果出现故障,能够根据容错机制恢复到之前的状态继续处理。例如在进行两个大表的连接操作时,使用 DataSet API 可以方便地定义连接逻辑,并且不用担心数据丢失或处理中断等问题。
- 查询优化层:这一层的作用是将用户编写的 DataSet 程序转换为更高效的可执行程序。它会对程序中的算子操作进行分析和优化,例如对算子的执行顺序进行调整、对数据的传输方式进行优化等,以提高批处理作业的执行效率。比如在一个包含多个聚合和连接操作的批处理作业中,查询优化层可以根据数据的特点和操作的依赖关系,合理安排操作顺序,减少数据传输和中间结果存储的开销。
5.1 查询优化
Flink 的优化器基于并行数据库系统的技术,如计划等价、成本建模和有趣属性传播。然而,构成 Flink 数据流程序的、任意的、大量使用用户定义函数(UDF)的有向无环图(DAG),不允许传统优化器直接应用数据库技术 [17],因为算子向优化器隐藏了它们的语义。出于同样的原因,基数估计和成本估算方法同样难以应用。Flink 的运行时支持各种执行策略,包括重新分区和广播数据传输,以及基于排序的分组和基于排序与哈希的连接实现。Flink 的优化器基于有趣属性传播的概念枚举不同的物理计划,使用基于成本的方法在多个物理计划中进行选择。成本包括网络和磁盘 I/O 以及 CPU 成本。为了克服存在 UDF 时的基数估计问题,Flink 的优化器可以使用程序员提供的提示信息。
关键词拓展介绍:
- 计划等价(Plan Equivalence):在数据库查询优化中,计划等价指不同的查询执行计划可以产生相同的结果。例如,对于一个简单的查询 “从表 A 和表 B 中选择满足特定条件的数据”,可能有多种连接顺序(先连接 A 和 B,或者先对 A 进行过滤再与 B 连接等),这些不同的连接顺序形成的执行计划在结果上是等价的,但执行效率可能不同。Flink 优化器利用计划等价的概念,尝试找出执行效率最高的计划。
- 成本建模(Cost Modeling):用于估算不同查询执行计划的成本。成本通常包括网络传输数据的开销(网络 I/O)、读写磁盘数据的开销(磁盘 I/O)以及 CPU 处理数据的开销。通过对这些成本因素进行建模和估算,优化器可以比较不同物理计划的成本,选择成本最低的计划来执行。例如,对于一个涉及大量数据从一个节点传输到另一个节点进行连接操作的计划,其网络 I/O 成本会比较高;而如果有一个计划可以在本地节点通过磁盘缓存数据完成连接,磁盘 I/O 成本可能会高,但网络 I/O 成本会降低,优化器通过成本建模来综合评估哪种计划更优。
- 有趣属性传播(Interesting - property Propagation):这里的有趣属性可以是数据的某些特性,如数据的排序情况、数据的基数(大致的数据量)等。优化器在构建执行计划时,会根据算子的输入输出数据的有趣属性进行传播和推导。例如,如果一个算子对输入数据有排序要求,那么上游算子输出数据如果已经是有序的(这就是一个有趣属性),可以减少额外的排序操作,提高执行效率。优化器通过有趣属性传播,在不同的物理计划中找到利用这些属性来优化执行的方案。
- 基数估计(Cardinality Estimation):在查询优化中,准确估计每个算子输出数据的大致数量(基数)非常重要。因为这会影响到内存使用、数据传输量以及执行计划的选择等。例如,在连接操作中,如果能准确估计连接后的数据基数,就可以更好地分配内存和选择合适的连接算法(如哈希连接适用于较小基数的数据等)。但在 Flink 中,由于 UDF 的存在,数据的处理逻辑变得复杂,难以准确估计基数。例如一个 UDF 可能根据复杂的业务逻辑对数据进行过滤或转换,使得原始数据的基数变化难以预测。
5.2 内存管理
Flink 以数据库技术为基础,将数据序列化到内存段中,而非在 JVM 堆中分配对象来表示处于缓冲状态的传输中的数据记录。像排序和连接这类操作,尽可能直接对二进制数据进行处理,将序列化与反序列化的开销降至最低,且在必要时将部分数据溢出到磁盘。为处理任意对象,Flink 使用类型推断和自定义序列化机制。通过基于二进制表示及堆外内存进行数据处理,Flink 成功降低了垃圾回收开销,还采用了缓存高效且稳健的算法,这些算法在内存压力下也能平稳扩展。
关键词拓展介绍:
- 内存段(Memory Segments):Flink 中的内存段是一种低层级的内存分配单元,它独立于 JVM 堆内存。这意味着内存段不受 JVM 垃圾回收机制的常规影响,极大减少了因垃圾回收导致的性能抖动。例如,在执行大规模数据集的排序操作时,数据可直接存储在内存段中,排序操作直接在这些内存段上执行,避免了因在 JVM 堆中频繁创建和销毁对象而引发的大量垃圾回收活动。
- 序列化(Serialization):将对象转换为二进制数据流的过程。在 Flink 中,数据在进入内存段存储或在网络中传输前,会进行序列化。这样做的好处是,二进制数据占用空间通常比对象在内存中的表示形式更小,且更利于直接在内存段上进行处理。例如,一个包含复杂对象的数据集在进行网络传输时,序列化后的数据能以更紧凑的形式传输,减少网络带宽占用。
- 反序列化(Deserialization):与序列化相反,是将二进制数据流恢复为对象的过程。当数据从内存段中取出用于进一步处理,或在接收端接收到序列化数据后,需要进行反序列化。在 Flink 中,尽量减少序列化和反序列化的开销是提高性能的关键,因为这两个过程通常比较耗时。例如,对于频繁处理的数据,如在一个持续运行的流处理作业中,减少不必要的序列化和反序列化操作,能显著提升系统整体性能。
- 类型推断(Type Inference):Flink 通过分析数据的使用方式或上下文来自动确定数据类型的机制。这在处理任意对象时非常有用,因为它无需程序员显式指定所有数据类型,减少了编程工作量,同时也能更好地适配不同类型的数据。例如,在处理一个包含多种数据类型的输入流时,Flink 可以根据流中数据的初始几个记录推断出数据类型,从而选择合适的序列化和处理方式。
- 自定义序列化机制(Custom Serialization Mechanisms):Flink 允许用户根据自身需求定义特定的序列化方式。这在处理一些复杂对象或不常见数据类型时特别有用。例如,对于一些包含自定义数据结构或加密数据的对象,默认的序列化方式可能不适用,用户可以通过实现自定义序列化机制,确保这些对象能正确地序列化和反序列化,同时也可以优化序列化过程以满足性能需求。
5.3 批处理迭代
过去,迭代图分析、并行梯度下降和优化技术等已在批量同步并行(Bulk Synchronous Parallel,BSP)和陈旧同步并行(Stale Synchronous Parallel,SSP)等模型的基础上得以实现。
Flink 的执行模型通过使用迭代控制事件,允许在其之上实现任何类型的结构化迭代逻辑。例如,在 BSP 执行的情况下,迭代控制事件标记着迭代计算中超级步(superstep)的开始和结束。最后,Flink 引入了进一步新颖的优化技术,如增量迭代(delta iterations)的概念 [14],该技术可以利用稀疏计算依赖关系。Flink 的图 API Gelly 已经在使用增量迭代技术。
关键词拓展介绍:
- 批量同步并行(Bulk Synchronous Parallel,BSP)模型:一种并行计算模型,它将计算过程划分为一系列的超级步(superstep)。在每个超级步中,所有处理器并行执行本地计算,然后进行全局同步,交换数据。这种模型的优点是简单、易于理解和编程,适用于许多需要全局同步的算法,如迭代图分析算法。例如,在 PageRank 算法中,可以在每个超级步中计算节点的 PageRank 值,并在同步阶段交换信息以更新下一轮计算的值。
- 陈旧同步并行(Stale Synchronous Parallel,SSP)模型:对 BSP 模型的一种改进,在 SSP 模型中,处理器之间的同步不必是严格一致的。某些处理器可以使用稍微陈旧的数据进行计算,而不是等待所有处理器都完成上一步计算并同步数据。这种模型在处理大规模数据和分布式计算时,可以减少同步带来的等待时间,提高计算效率,特别适用于对数据一致性要求不是特别严格的算法,如一些机器学习中的梯度下降算法,在一定程度上允许陈旧数据不会显著影响最终结果的收敛。
- 迭代控制事件(Iteration - control events):Flink 中用于控制迭代逻辑的事件机制。通过这些事件,可以明确标记迭代的开始、结束以及其他关键阶段,使得任何类型的结构化迭代逻辑能够基于 Flink 执行模型顺利实现。例如,在实现迭代图分析算法时,可以利用迭代控制事件来管理每一轮迭代中节点数据的更新和同步操作,确保算法按照预期的迭代步骤执行。
- 增量迭代(Delta Iterations):Flink 引入的一种优化技术,它利用稀疏计算依赖关系。在某些迭代计算中,并不是每次迭代都需要对所有数据进行完整计算,可能只有部分数据的变化会影响到下一次迭代的结果。增量迭代技术专注于这些发生变化的数据(即增量部分)进行计算,从而减少不必要的计算量,提高计算效率。在图计算场景中,如果只有少数节点的属性发生变化,增量迭代可以只针对这些节点及其相关联的边进行计算,而不是对整个图进行全面计算。
- Gelly:Flink 的图计算 API,它提供了一系列用于图分析和处理的工具和算法。Gelly 基于 Flink 的执行模型,支持各种图算法的实现,并且已经应用了增量迭代等优化技术,帮助用户高效地处理大规模图数据。例如,用户可以使用 Gelly 轻松实现如最短路径算法、社区发现算法等常见的图分析任务。
6. 相关工作
如今,有大量用于分布式批处理和流分析处理的引擎。我们在下面对主要系统进行分类。
- 批处理:Apache Hadoop 是基于 MapReduce 范式进行大规模数据分析的最受欢迎的开源系统之一 [12]。Dryad [18] 在基于通用有向无环图(DAG)的数据流中引入了嵌入式用户定义函数,并且由 SCOPE [26] 进行了扩展,SCOPE 是基于 Dryad 的一种语言和 SQL 优化器。Apache Tez [24] 可以看作是 Dryad 中所提理念的开源实现。大规模并行处理(MPP)数据库 [13],以及像 Apache Drill 和 Impala [19] 这样的最新开源实现,将其应用程序编程接口(API)限制为 SQL 变体。与 Flink 类似,Apache Spark [25] 是一个数据处理框架,它实现了基于有向无环图(DAG)的执行引擎,提供 SQL 优化器,执行基于驱动程序的迭代,并将无界计算视为微批处理。相比之下,Flink 是唯一结合了以下几点的系统:(i)一个分布式数据流运行时,它利用流水线式流执行来处理批处理和流工作负载;(ii)通过轻量级检查点实现精确一次的状态一致性;(iii)原生迭代处理;(iv)复杂的窗口语义,支持乱序处理。
- 流处理:在学术和商业流处理系统方面已有大量前期工作,如 SEEP、Naiad、微软 StreamInsight 和 IBM Streams。这些系统中的许多都基于数据库领域的研究 [1, 5, 8, 10, 16, 22, 23]。上述大多数系统要么(i)是学术原型,要么(ii)是闭源商业产品,要么(iii)无法在商用服务器集群上进行横向扩展计算。数据流方面的最新方法实现了横向可扩展性和组合数据流操作符,但状态一致性保证较弱(例如,Apache Storm 和 Samza 中的至少一次处理)。值得注意的是,诸如 “乱序处理”(OOP)[20] 等概念受到了极大关注,并被 MillWheel [2] 采用,MillWheel 是谷歌内部版本,后来成为 Apache Beam / Google Dataflow [3] 的商业执行器。MillWheel 作为精确一次低延迟流处理和乱序处理概念的验证,因此对 Flink 的发展产生了很大影响。据我们所知,Flink 是唯一满足以下几点的开源项目:(i)支持事件时间和乱序事件处理;(ii)提供具有精确一次保证的一致性托管状态;(iii)实现高吞吐量和低延迟,同时适用于批处理和流处理。
关键词拓展介绍:
- MapReduce 范式:一种编程模型和相关实现,用于在大型集群上处理海量数据。它将数据处理过程分为两个主要阶段:Map(映射)阶段和 Reduce(归约)阶段。在 Map 阶段,输入数据被分割成多个小块,每个小块由一个 Map 任务处理,生成一系列键值对。在 Reduce 阶段,具有相同键的所有值被收集到一起,并由 Reduce 任务进行合并或聚合操作。例如,在统计文本文件中每个单词出现次数的任务中,Map 阶段可以将每个单词映射为键值对(单词,1),Reduce 阶段将相同单词的计数进行累加。
- 有向无环图(Directed Acyclic Graph, DAG):在数据处理中,DAG 常用于描述任务之间的依赖关系。图中的节点表示任务,边表示任务之间的数据流动方向,并且不存在环,即任务之间的依赖关系不会形成循环引用。例如,在一个复杂的数据处理流程中,可能有数据读取、清洗、转换、聚合等多个任务,这些任务之间的先后顺序和数据流向可以用 DAG 来清晰表示,以确保任务按照正确的顺序执行,避免出现死循环或不合理的依赖。
- 轻量级检查点(Lightweight Checkpointing):Flink 中用于实现精确一次状态一致性的重要机制。它通过定期记录任务的状态信息,在发生故障时能够快速恢复到故障前的状态,而不会丢失或重复处理数据。轻量级意味着这种检查点机制在记录状态时尽量减少对正常处理流程的影响,开销相对较小。例如,在一个长时间运行的流处理作业中,可能每间隔一定时间或处理一定数量的数据后进行一次轻量级检查点操作,这样当系统出现故障重启后,可以从最近的检查点处继续处理,保证数据处理的准确性和连续性。
- 乱序处理(Out-of-order Processing, OOP):在流处理中,数据到达系统的顺序可能与它们实际发生的顺序不一致,乱序处理就是指系统能够正确处理这种情况的能力。比如在处理物联网设备产生的传感器数据时,由于网络延迟等原因,较晚发生的事件数据可能会比早期发生的事件数据晚到达处理系统。支持乱序处理的系统能够根据事件自身携带的时间戳(如事件时间),在一定的时间窗口内等待迟到的数据,从而正确地对数据进行排序和处理,保证结果的准确性。
- Apache Storm:一个开源的分布式实时计算系统,主要用于处理高吞吐量的数据流。它能够在集群环境中快速处理大量的实时数据,具有高容错性。Storm 采用 “至少一次” 的处理语义,意味着在处理过程中数据可能会被重复处理,但能保证数据不会丢失。例如,在实时分析社交媒体数据的场景中,Storm 可以快速地对大量的推文进行实时处理,如情感分析、关键词提取等。
- Apache Samza:同样是一个分布式流处理框架,它构建在 Kafka 之上,利用 Kafka 的消息队列特性来实现数据的可靠传输和存储。Samza 也采用 “至少一次” 的处理语义,适用于需要处理大规模流数据的应用场景,如实时日志分析等。它支持水平扩展,能够在集群中动态增加或减少处理节点,以适应不同的数据负载。
- Apache Beam / Google Dataflow:Apache Beam 是一个统一的编程模型,用于定义批处理和流处理作业,它可以在不同的执行引擎上运行,如 Apache Flink 和 Google Cloud Dataflow。Google Dataflow 是 Google 基于 Apache Beam 模型提供的云数据处理服务。通过 Beam,开发者可以使用统一的编程接口编写代码,而无需关心底层具体的执行引擎细节,提高了代码的可移植性和复用性。例如,开发者可以编写一个数据处理作业,既可以在本地使用 Flink 执行,也可以部署到 Google Cloud 上使用 Dataflow 执行。
- MillWheel:Google 开发的流处理系统,它为精确一次低延迟流处理和乱序处理概念提供了实践验证。MillWheel 在处理大规模流数据时,能够保证数据仅被处理一次,同时实现较低的处理延迟,并且有效地处理乱序到达的数据。它的设计理念和技术实现对后来的流处理系统,如 Flink,产生了重要的影响,许多概念和技术被 Flink 借鉴和采用。
8. 结论
在本文中,我们介绍了 Apache Flink,这是一个实现了通用数据流引擎的平台,旨在执行流分析和批分析。Flink 的数据流引擎将算子状态和逻辑中间结果视为一等公民,并被具有不同参数的批处理和数据流应用程序编程接口(API)所使用。构建在 Flink 流数据流引擎之上的流 API 提供了保存可恢复状态以及对数据流窗口进行分区、转换和聚合的方法。虽然从理论上讲,批处理计算是流计算的一种特殊情况,但 Flink 对其进行了特殊处理,通过使用查询优化器优化其执行,并通过实现阻塞算子,在内存不足时优雅地溢出到磁盘。
参考文献
[1] D. J. Abadi, Y. Ahmad, M. Balazinska, U. Cetintemel, M. Cherniack, J.-H. Hwang, W. Lindner, A. Maskey, A. Rasin,E. Ryvkina, et al. The design of the Borealis stream processing engine. CIDR, 2005.
[2] T. Akidau, A. Balikov, K. Bekiroglu, S. Chernyak, J. Haberman, R. Lax, S. McVeety, D. Mills, P. Nordstrom, and S. Whittle. Millwheel: fault-tolerant stream processing at Internet scale. PVLDB, 2013.
[3] T. Akidau, R. Bradshaw, C. Chambers, S. Chernyak, R. J. Fernandez-Moctezuma, R. Lax, S. McVeety, D. Mills, F. Perry, E. Schmidt, et al. The dataflow model: a practical approach to balancing correctness, latency, and cost in massive-scale, unbounded, out-of-order data processing. PVLDB, 2015.
[4] A. Alexandrov, R. Bergmann, S. Ewen, J.-C. Freytag, F. Hueske, A. Heise, O. Kao, M. Leich, U. Leser, V. Markl, F. Naumann, M. Peters, A. Rheinlaender, M. J. Sax, S. Schelter, M. Hoeger, K. Tzoumas, and D. Warneke. The stratosphere platform for big data analytics. VLDB Journal, 2014.
[5] A. Arasu, B. Babcock, S. Babu, J. Cieslewicz, M. Datar, K. Ito, R. Motwani, U. Srivastava, and J. Widom. Stream: The stanford data stream management system. Technical Report, 2004.
[6] Y. Bu, B. Howe, M. Balazinska, and M. D. Ernst. HaLoop: Efficient Iterative Data Processing on Large Clusters. PVLDB, 2010.
[7] P. Carbone, G. Fora, S. Ewen, S. Haridi, and K. Tzoumas. Lightweight asynchronous snapshots for distributed dataflows. arXiv:1506.08603, 2015.
[8] B. Chandramouli, J. Goldstein, M. Barnett, R. DeLine, D. Fisher, J. C. Platt, J. F. Terwilliger, and J. Wernsing. Trill: a high-performance incremental query processor for diverse analytics. PVLDB, 2014.
[9] B. Chandramouli, J. Goldstein, and D. Maier. On-the-fly progress detection in iterative stream queries. PVLDB, 2009.
[10] S. Chandrasekaran and M. J. Franklin. Psoup: a system for streaming queries over streaming data. VLDB Journal, 2003.
[11] K. M. Chandy and L. Lamport. Distributed snapshots: determining global states of distributed systems. ACM TOCS,1985.
[12] J. Dean et al. MapReduce: simplified data processing on large clusters. Communications of the ACM, 2008.
[13] D. J. DeWitt, S. Ghandeharizadeh, D. Schneider, A. Bricker, H.-I. Hsiao, R. Rasmussen, et al. The gamma database machine project. IEEE TKDE, 1990.
[14] S. Ewen, K. Tzoumas, M. Kaufmann, and V. Markl. Spinning Fast Iterative Data Flows. PVLDB, 2012.
[15] J. Feigenbaum, S. Kannan, A. McGregor, S. Suri, and J. Zhang. On graph problems in a semi-streaming model.Theoretical Computer Science, 2005.
[16] B. Gedik, H. Andrade, K.-L. Wu, P. S. Yu, and M. Doo. Spade: the system s declarative stream processing engine. ACM SIGMOD, 2008.
[17] F. Hueske, M. Peters, M. J. Sax, A. Rheinlander, R. Bergmann, A. Krettek, and K. Tzoumas. Opening the Black Boxes in Data Flow Optimization. PVLDB, 2012.
[18] M. Isard, M. Budiu, Y. Yu, A. Birrell, and D. Fetterly. Dryad: distributed data-parallel programs from sequential building blocks. ACM SIGOPS, 2007.
[19] M. Kornacker, A. Behm, V. Bittorf, T. Bobrovytsky, C. Ching, A. Choi, J. Erickson, M. Grund, D. Hecht, M. Jacobs, et al. Impala: A modern, open-source sql engine for hadoop. CIDR, 2015.
[20] J. Li, K. Tufte, V. Shkapenyuk, V. Papadimos, T. Johnson, and D. Maier. Out-of-order processing: a new architecture for high-performance stream systems. PVLDB, 2008.
[21] N. Marz and J. Warren. Big Data: Principles and best practices of scalable realtime data systems. Manning Publications Co., 2015.
[22] M. Migliavacca, D. Eyers, J. Bacon, Y. Papagiannis, B. Shand, and P. Pietzuch. Seep: scalable and elastic event processing. ACM Middleware’10 Posters and Demos Track, 2010.
[23] D. G. Murray, F. McSherry, R. Isaacs, M. Isard, P. Barham, and M. Abadi. Naiad: a timely dataflow system. ACM SOSP, 2013.
[24] B. Saha, H. Shah, S. Seth, G. Vijayaraghavan, A. Murthy, and C. Curino. Apache tez: A unifying framework for modeling and building data processing applications. ACM SIGMOD, 2015.
[25] M. Zaharia, M. Chowdhury, M. J. Franklin, S. Shenker, and I. Stoica. Spark: Cluster Computing with Working Sets. USENIX HotCloud, 2010.
[26] J. Zhou, P.-A. Larson, and R. Chaiken. Incorporating partitioning and parallel plans into the scope optimizer. IEEE ICDE, 2010.