多头注意力
Multi-Head Attention
-
论文地址
https://arxiv.org/pdf/1706.03762
多头注意力介绍
-
多头注意力是Transformer模型的关键创新,通过并行执行多个独立的注意力计算单元,使模型能够同时关注来自不同表示子空间的信息。每个注意力头学习不同的语义特征,最后通过线性变换将多头的输出组合为最终结果。
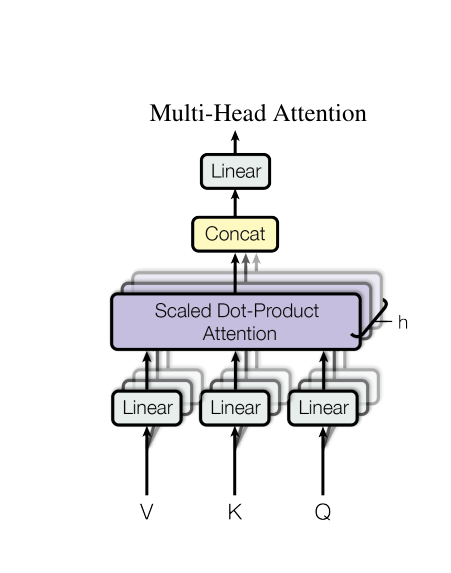
当n_heads=1时,多头注意力等价于标准缩放点积注意力。多头设计通过建立多个独立的"观察视角",使模型能够捕获更丰富的上下文信息。
数学公式
-
多头注意力通过以下三个步骤实现:
- 线性投影:对Q/K/V进行线性变换
- 并行注意力计算:在多个子空间中计算缩放点积注意力
- 输出融合:拼接多头结果并进行线性变换
公式表达为:
MultiHead ( Q , K , V ) = Concat ( h e a d 1 , . . . , h e a d h ) W O where h e a d i = Attention ( Q W i Q , K W i K , V W i V ) \text{MultiHead}(Q,K,V) = \text{Concat}(head_1,...,head_h)W^O \\ \text{where } head_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V) MultiHead(Q,K,V)=Concat(head1,...,headh)WOwhere headi=Attention(QWiQ,KWiK,VWiV)
其中:- W i Q ∈ R s e q _ l e n × d _ k W_i^Q \in \mathbb{R}^{seq\_len \times d\_k} WiQ∈Rseq_len×d_k:第i个头的查询投影矩阵
- W i K ∈ R s e q _ l e n × d _ k W_i^K \in \mathbb{R}^{seq\_len \times d\_k} WiK∈Rseq_len×d_k:第i个头的键投影矩阵
- W i V ∈ R s e q _ l e n × d _ k W_i^V \in \mathbb{R}^{seq\_len \times d\_k} WiV∈Rseq_len×d_k:第i个头的值投影矩阵
- W O ∈ R s e q _ l e n × d _ m o d e l W^O \in \mathbb{R}^{seq\_len \times d\_model} WO∈Rseq_len×d_model:输出投影矩阵
s e q _ l e n seq\_len seq_len 为序列长度, d _ m o d e l d\_model d_model 为embedding的维度, d _ k d\_k d_k 为每个注意力头的维度,假设头数量为n_heads ,且n_heads能被d_model给整数,则
d _ k = d _ m o d e l n _ h e a d s d\_k = \frac{d\_model}{n\_heads} d_k=n_headsd_model
代码实现
-
需要导入之前写的计算注意力分数的函数
https://blog.csdn.net/hbkybkzw/article/details/147462845
import torch from torch import nndef calculate_attention(query, key, value, mask=None):d_k = key.shape[-1]att_scaled = torch.matmul(query, key.transpose(-2, -1)) / d_k ** 0.5 # 缩放点积,注意区分这里的 d_k 是多头注意力中的“d_model”if mask is not None:att_scaled = att_scaled.masked_fill_(mask=mask, value=-1e9) # 或者value= -inf,这样在softmax的时候,掩码的部分就为0了att_softmax = torch.softmax(input=att_scaled, dim=-1) # softmaxatt_score = torch.matmul(att_softmax, value) # 注意力分数return att_score -
多头注意力模块
class MultiHeadAttention(nn.Module):def __init__(self, n_heads, d_model, dropout_prob=0.1):super(MultiHeadAttention, self).__init__()assert d_model % n_heads == 0 # 需要确保d_model一定要能被注意力头的数量整除# 定义四个全连接层(Q/K/V/Output)self.q_linear = nn.Linear(in_features=d_model, out_features=d_model, bias=False)self.k_linear = nn.Linear(in_features=d_model, out_features=d_model, bias=False)self.v_linear = nn.Linear(in_features=d_model, out_features=d_model, bias=False)self.linear = nn.Linear(in_features=d_model, out_features=d_model, bias=False)self.dropout = nn.Dropout(dropout_prob)self.n_heads = n_headsself.d_k = d_model // n_headsself.d_model = d_modeldef forward(self, q, k, v, mask=None):"""前向传播过程输入形状:[batch_size, seq_len, d_model]输出形状:[batch_size, seq_len, d_model]"""# 步骤1:线性投影并分割多头q = self.q_linear(q)q = q.reshape(q.shape[0], -1, self.n_heads, self.d_k) # [batch_size,seq_len,n_heads,d_k]q = q.transpose(1, 2) # [batch_size, n_heads, seq_len, d_k]# 等价于# q = self.q_linear(q).reshape(q.shape[0],-1,self.n_heads,self.d_k).transpose(1,2)k = self.k_linear(k)k = k.reshape(k.shape[0], -1, self.n_heads, self.d_k)k = k.transpose(1, 2)v = self.v_linear(v)v = v.reshape(v.shape[0], -1, self.n_heads, self.d_k)v = v.transpose(1, 2)# 步骤2:计算注意力(每个头独立计算)out = calculate_attention(q, k, v, mask) # [batch_size,seq_len,n_heads,d_k]# 步骤3:拼接多头结果并进行输出投影out = out.transpose(1, 2) # [batch_size,n_heads,seq_len,d_k]out = out.reshape(out.shape[0], -1, self.d_model) # [batch_size,seq_len,d_model]out = self.linear(out)out = self.dropout(out)return out -
关键操作解析
维度变换流程
操作步骤 张量形状变化示例 输入数据 [batch_size, seq_len, d_model] 步骤1-线性投影(保持维度) [batch_size, seq_len, d_model] 步骤1-分割多头(n_heads) [batch_size, seq_len, n_heads, d_k] 步骤1-维度转置(交换头与序列轴) [batch_size, n_heads , seq_len, d_k] 步骤2-计算注意力(各头独立) [batch_size, n_heads , seq_len, d_k] 步骤3-维度转置(交换头与序列轴) [batch_size , seq_len, n_heads ,d_k] 步骤3-拼接多头(恢复原始维度) [batch_size, seq_len, d_model]
使用示例
-
测试代码
if __name__ == "__main__":# 实例化模块:8头注意力,512维模型,20% dropoutmultihead_attention = MultiHeadAttention(n_heads=8, d_model=512, dropout_prob=0.2)# 模拟输入:batch_size=4,序列长度100,维度512x = torch.randn(4, 100, 512)# 前向传播(自注意力模式)output = multihead_attention(x, x, x)print("输入形状:", x.shape) # torch.Size([4, 100, 512])print("输出形状:", output.shape) # torch.Size([4, 100, 512])print("输出范数:", torch.norm(output)) # 约1.2-1.8(取决于初始化)