豆瓣图书数据采集与可视化分析(三)- 豆瓣图书数据统计分析
文章目录
- 前言
- 一、数据读取与保存
- 1. 读取清洗后数据
- 2. 保存数据到CSV文件
- 3. 保存数据到MySQL数据库
- 二、不同分类统计分析
- 1. 不同分类的图书数量统计分析
- 2. 不同分类的平均评分统计分析
- 3. 不同分类的平均评价人数统计分析
- 4. 不同分类的平均价格统计分析
- 5. 分类综合分析
- 三、不同年份统计分析
- 1. 不同年份出版的图书数量统计分析
- 2. 不同年份出版的图书平均评分分析
- 3. 不同年份出版的图书平均评价人数分析
- 4. 不同年份出版的图书平均价格分析
- 5. 年份综合分析
- 四、不同作者统计分析
- 1. 不同作者的图书数量统计分析
- 2. 不同作者的平均评分分析
- 3. 不同作者的平均评价人数分析
- 4. 不同作者的平均价格分析
- 5. 作者综合分析
- 五、不同出版社分析
- 1. 不同出版社的图书数量统计分析
- 2. 不同出版社的平均评分分析
- 3. 不同出版社的平均评价人数分析
- 4. 不同出版社的平均价格分析
- 5. 出版社综合分析
- 六、其他分析
- 1. 图书评分分布分析
- 2. 图书价格分布分析
- 3. 译者翻译的图书数量统计分析(前15)
- 4. 评价人数多的图书分析(前15)
- 5. 评分最高的图书分析(前15)
- 6. 评价人数最多且评分高的图书分析(前15)
- 七、完整代码
前言
本项目旨在通过对豆瓣图书数据集的详细分析,挖掘其中隐藏的规律和趋势,为图书出版行业、读者以及相关研究人员提供有价值的参考。从数据读取与保存这一基础环节出发,构建了完善的数据处理流程,确保能够高效地获取和存储清洗后的高质量数据,为后续分析筑牢根基。在数据分析阶段,从多个维度展开深入探究。在不同分类统计分析中,详细剖析了各类图书在数量、平均评分、平均评价人数以及平均价格等方面的表现,有助于出版方精准把握市场需求,读者快速定位感兴趣的图书类别。针对不同年份的统计分析,能够清晰洞察图书出版趋势随时间的演变,了解不同年份图书在质量、受欢迎程度和价格上的变化规律。而对不同作者和出版社的分析,则为评估创作者和出版机构的影响力提供了量化依据。此外,其他分析板块涵盖了图书评分分布、价格分布、热门图书筛选等多个视角,进一步丰富了对图书市场的认知。
一、数据读取与保存
1. 读取清洗后数据
def load_data(csv_file_path):try:data = pd.read_csv(csv_file_path)return dataexcept FileNotFoundError:print("未找到指定的 CSV 文件,请检查文件路径和文件名。")except Exception as e:print(f"加载数据时出现错误: {e}")
清洗后的部分数据如下图所示:
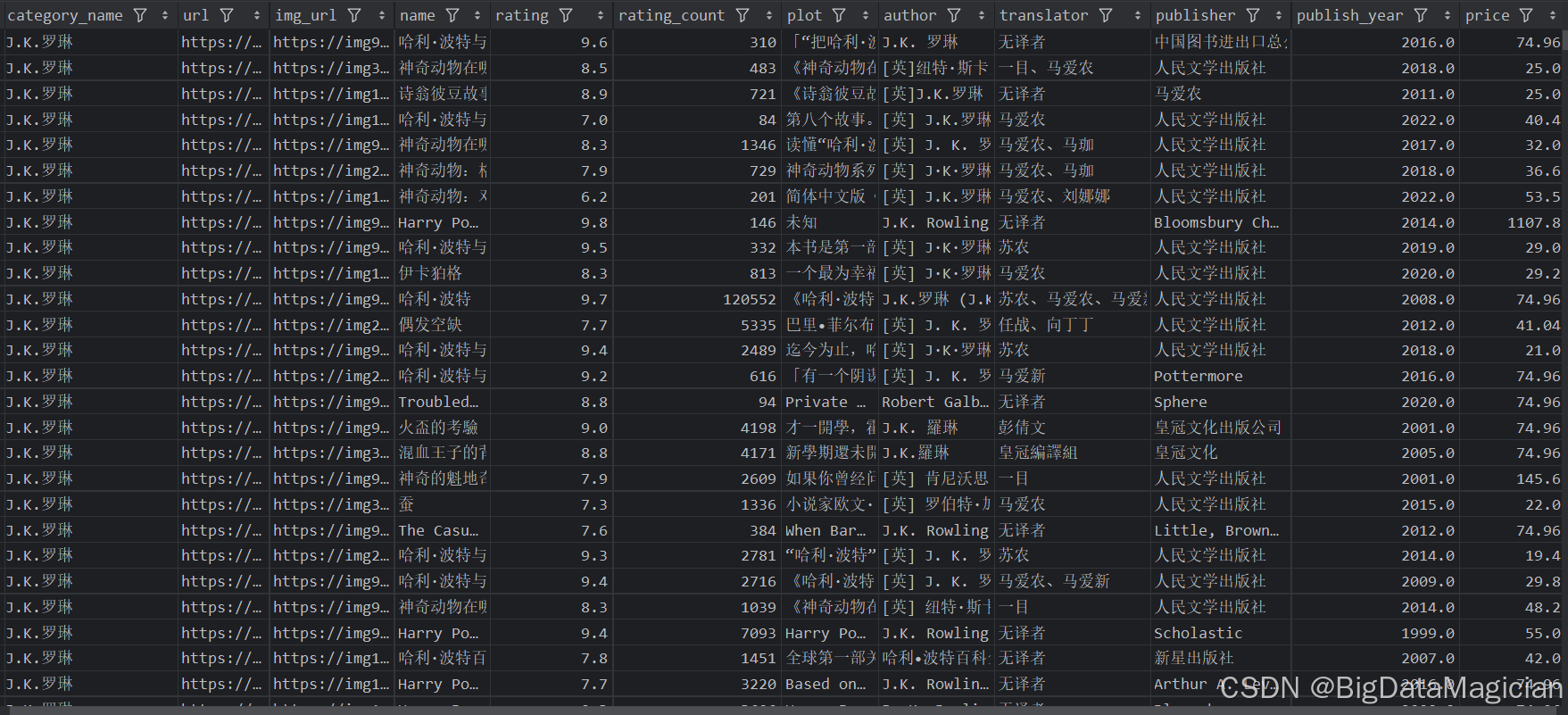
2. 保存数据到CSV文件
def save_to_csv(data, csv_file_path):# 使用 pathlib 处理文件路径path = Path(csv_file_path)# 检查文件所在目录是否存在,如果不存在则创建path.parent.mkdir(parents=True, exist_ok=True)data.to_csv(csv_file_path, index=False, encoding='utf-8-sig', mode='w', header=True)print(f'清洗后的数据已保存到 {csv_file_path} 文件')
3. 保存数据到MySQL数据库
def save_to_mysql(data, table_name):engine = create_engine(f'mysql+mysqlconnector://root:zxcvbq@127.0.0.1:3306/douban')data.to_sql(table_name, con=engine, index=False, if_exists='replace')print(f'清洗后的数据已保存到 {table_name} 表')
二、不同分类统计分析
1. 不同分类的图书数量统计分析
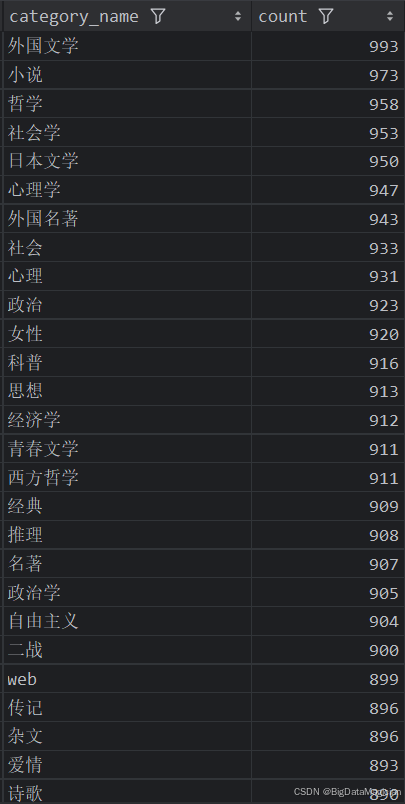
def category_count_analysis(data):# 统计每个分类的图书数量category_counts = data['category_name'].value_counts()category_counts = category_counts.reset_index()category_counts.columns = ['category_name', 'count']save_to_csv(category_counts, './结果输出层/数据分析结果数据/分类图书数量统计分析.csv')save_to_mysql(category_counts, '分类图书数量统计分析')
分析结果如下图所示:
2. 不同分类的平均评分统计分析
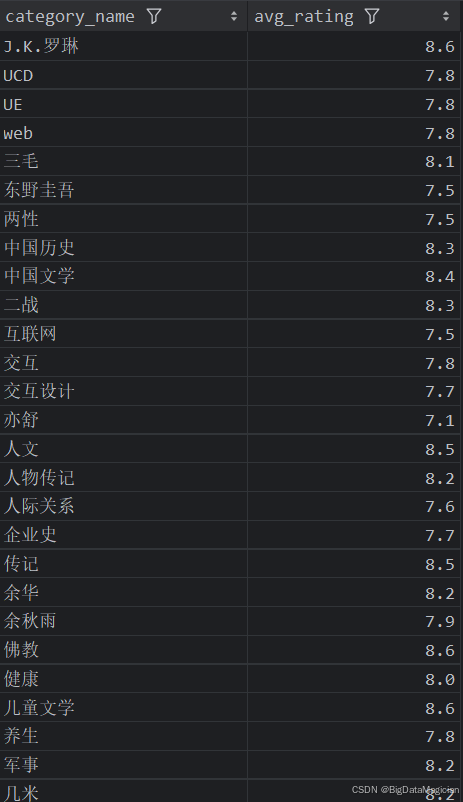
def category_rating_analysis(data):# 计算每个分类的平均评分category_ratings = data.groupby('category_name')['rating'].mean().round(1)category_ratings = category_ratings.reset_index()category_ratings.columns = ['category_name', 'avg_rating']save_to_csv(category_ratings, './结果输出层/数据分析结果数据/每个分类的平均评分统计分析.csv')save_to_mysql(category_ratings, '每个分类的平均评分统计分析')
分析结果如下图所示:
3. 不同分类的平均评价人数统计分析
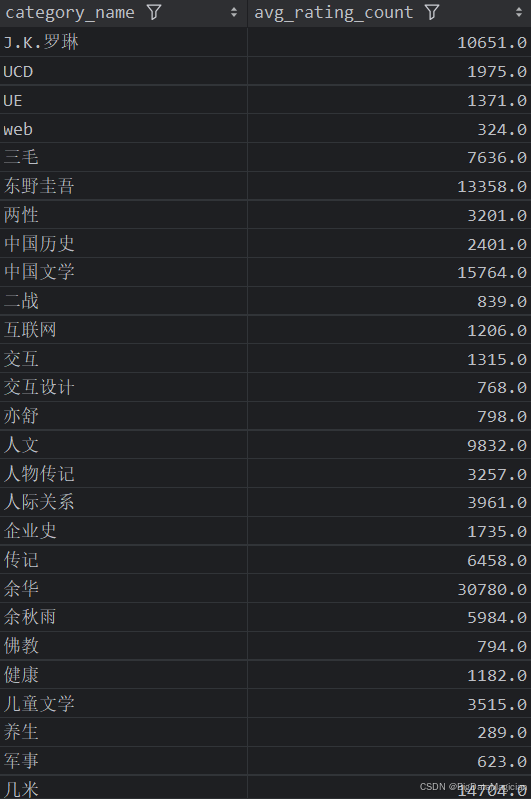
def category_rating_count_analysis(data):# 计算每个分类的平均评价人数category_rating_counts = data.groupby('category_name')['rating_count'].mean().round(0)category_rating_counts = category_rating_counts.reset_index()category_rating_counts.columns = ['category_name', 'avg_rating_count']save_to_csv(category_rating_counts, './结果输出层/数据分析结果数据/每个分类的平均评价人数统计分析.csv')save_to_mysql(category_rating_counts, '每个分类的平均评价人数统计分析')
分析结果如下图所示:
4. 不同分类的平均价格统计分析
def category_price_analysis(data):# 计算每个分类的平均价格category_prices = data.groupby('category_name')['price'].mean().round(1)category_prices = category_prices.reset_index()category_prices.columns = ['category_name', 'avg_price']save_to_csv(category_prices, './结果输出层/数据分析结果数据/每个分类的平均价格统计分析.csv')save_to_mysql(category_prices, '每个分类的平均价格统计分析')
分析结果如下图所示:
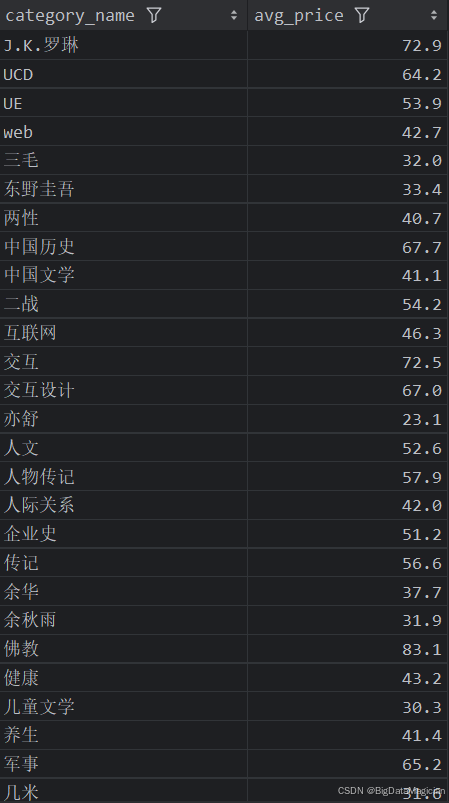
5. 分类综合分析
def category_analysis(data):# 统计每个分类的图书数量category_counts = data['category_name'].value_counts()category_counts = category_counts.reset_index()category_counts.columns = ['category_name', 'count']# 计算每个分类的平均评分category_ratings = data.groupby('category_name')['rating'].mean().round(1)category_ratings = category_ratings.reset_index()category_ratings.columns = ['category_name', 'avg_rating']# 计算每个分类的平均评价人数category_rating_counts = data.groupby('category_name')['rating_count'].mean().round(0)category_rating_counts = category_rating_counts.reset_index()category_rating_counts.columns = ['category_name', 'avg_rating_count']# 计算每个分类的平均价格category_prices = data.groupby('category_name')['price'].mean().round(1)category_prices = category_prices.reset_index()category_prices.columns = ['category_name', 'avg_price']# 合并四个结果merged_result = pd.merge(category_counts, category_ratings, on='category_name', how='outer')merged_result = pd.merge(merged_result, category_rating_counts, on='category_name', how='outer')merged_result = pd.merge(merged_result, category_prices, on='category_name', how='outer')# 保存合并后的结果到 CSV 文件save_to_csv(merged_result, './结果输出层/数据分析结果数据/每种分类的图书数量和平均评分和平均评价人数和平均价格统计分析.csv')save_to_mysql(merged_result, '每种分类的图书数量和平均评分和平均评价人数和平均价格统计分析')
分析结果如下图所示:
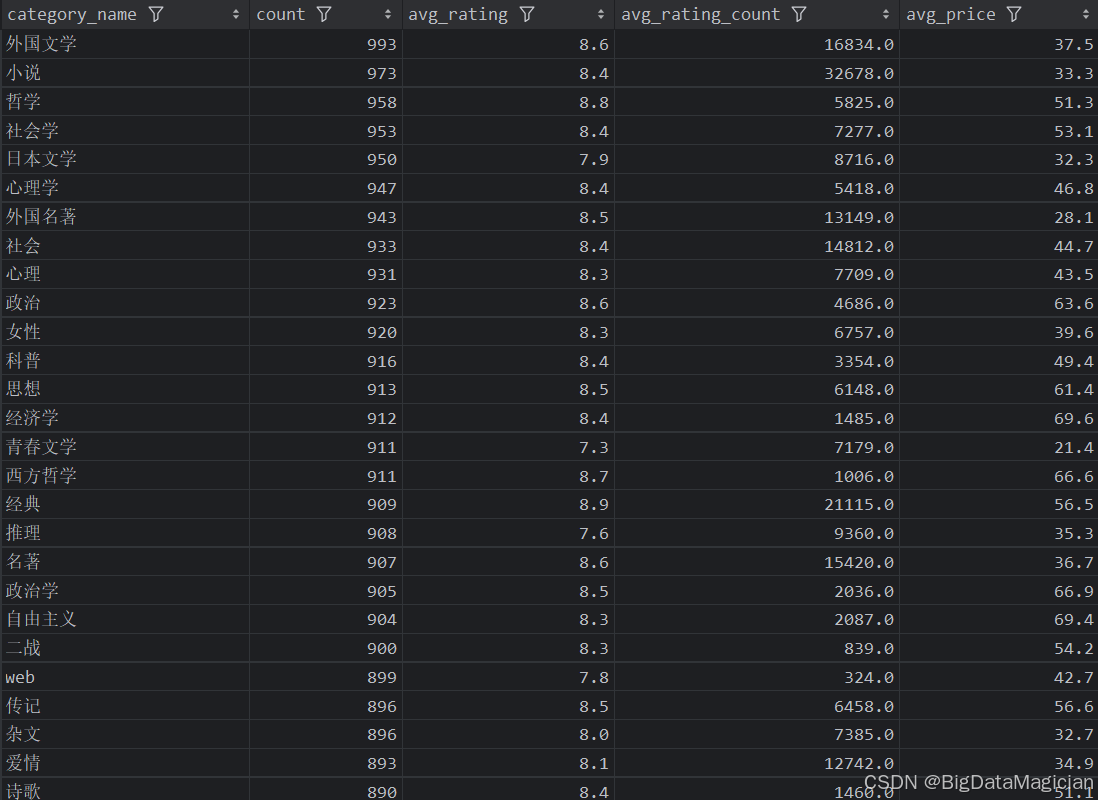
三、不同年份统计分析
1. 不同年份出版的图书数量统计分析
def year_count_analysis(data):# 统计每年出版的图书数量year_counts = data['publish_year'].value_counts()year_counts = year_counts.reset_index()# 按照年份升序排序year_counts = year_counts.sort_values(by='publish_year')year_counts.columns = ['publish_year', 'count']save_to_csv(year_counts, './结果输出层/数据分析结果数据/每年出版的图书数量统计分析.csv')save_to_mysql(year_counts, '每年出版的图书数量统计分析')
分析结果如下图所示:
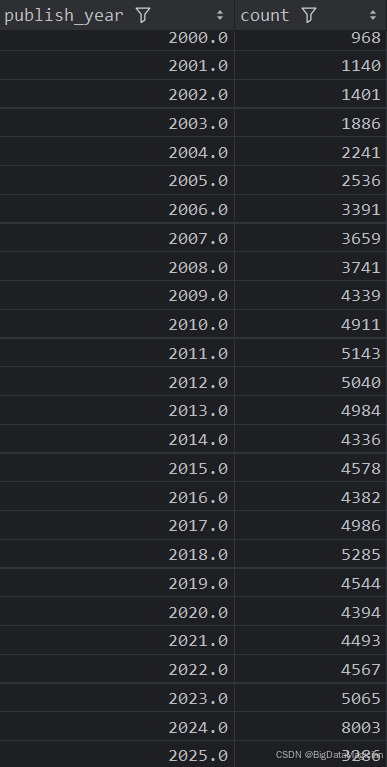
2. 不同年份出版的图书平均评分分析
def year_rating_analysis(data):year_ratings = data.groupby('publish_year')['rating'].mean().round(1)year_ratings = year_ratings.reset_index()year_ratings = year_ratings.sort_values(by='publish_year')year_ratings.columns = ['publish_year', 'avg_rating']save_to_csv(year_ratings, './结果输出层/数据分析结果数据/每年出版的图书平均评分分析.csv')save_to_mysql(year_ratings, '每年出版的图书平均评分分析')
分析结果如下图所示:
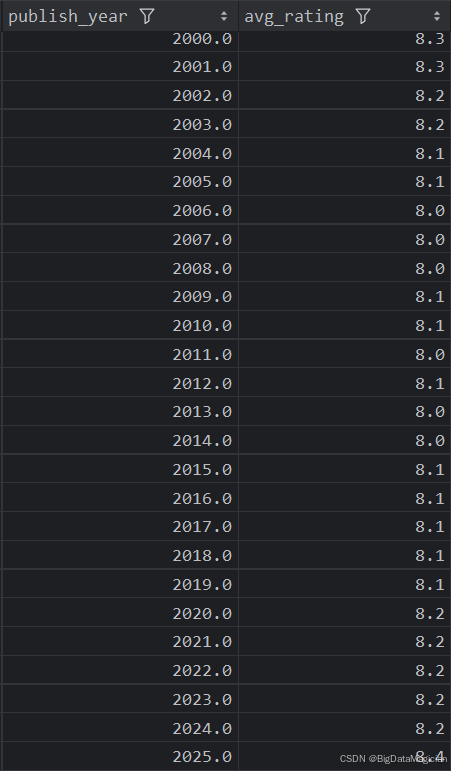
3. 不同年份出版的图书平均评价人数分析
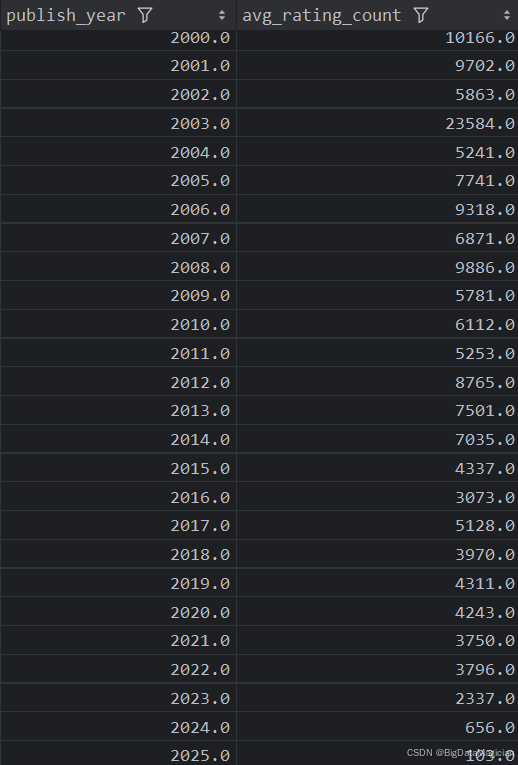
def year_rating_count_analysis(data):year_rating_counts = data.groupby('publish_year')['rating_count'].mean().round(0)year_rating_counts = year_rating_counts.reset_index()year_rating_counts = year_rating_counts.sort_values(by='publish_year')year_rating_counts.columns = ['publish_year', 'avg_rating_count']save_to_csv(year_rating_counts, './结果输出层/数据分析结果数据/每年出版图书平均评价人数分析.csv')save_to_mysql(year_rating_counts, '每年出版图书平均评价人数分析')
分析结果如下图所示:
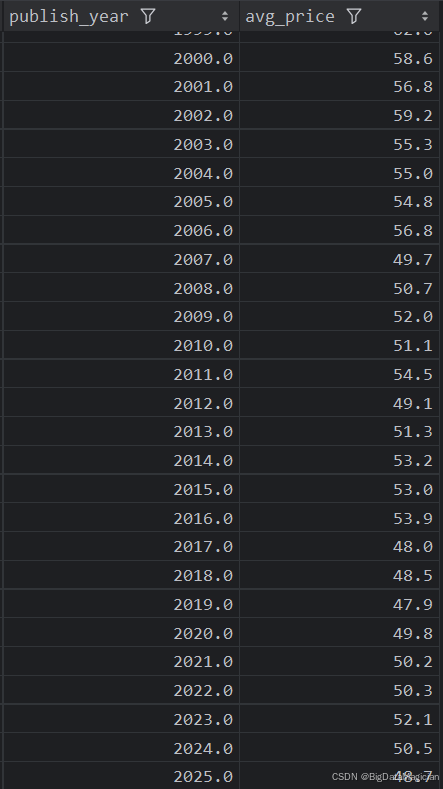
4. 不同年份出版的图书平均价格分析
def year_price_analysis(data):year_prices = data.groupby('publish_year')['price'].mean().round(1)year_prices = year_prices.reset_index()year_prices = year_prices.sort_values(by='publish_year')year_prices.columns = ['publish_year', 'avg_price']save_to_csv(year_prices, './结果输出层/数据分析结果数据/每年出版图书平均价格分析.csv')save_to_mysql(year_prices, '每年出版图书平均价格分析')
分析结果如下图所示:
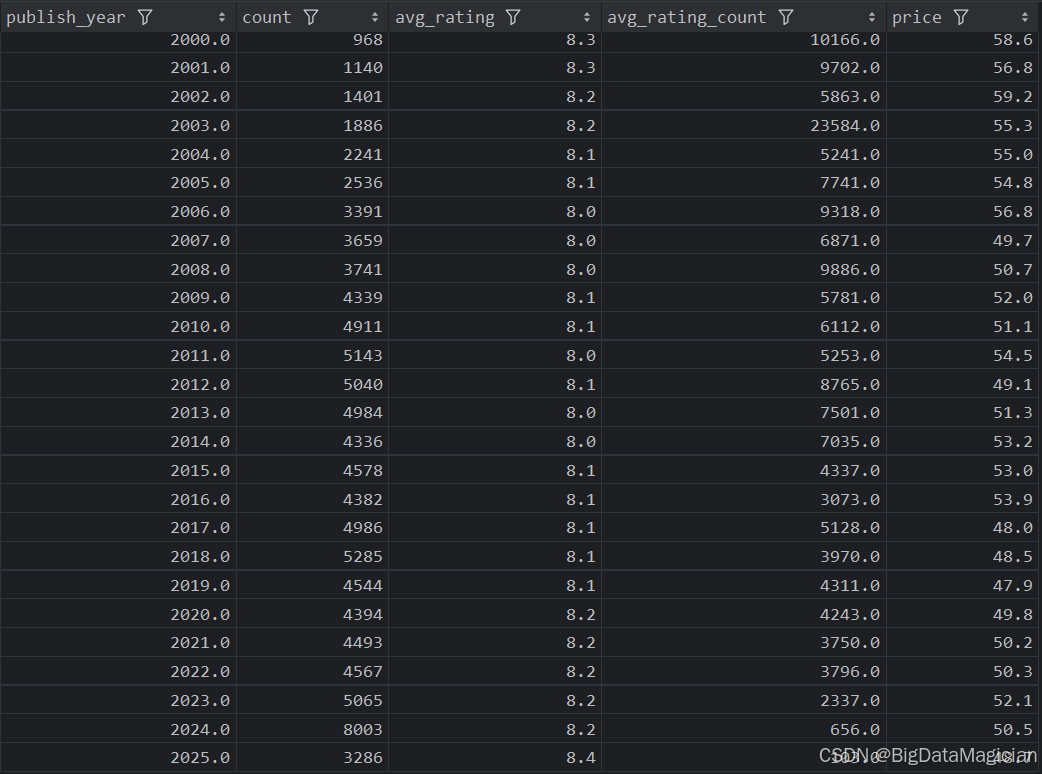
5. 年份综合分析
def year_analysis(data):# 每年出版的图书数量统计分析year_counts = data['publish_year'].value_counts()year_counts = year_counts.reset_index()year_counts = year_counts.sort_values(by='publish_year')year_counts.columns = ['publish_year', 'count']# 每年出版的图书平均评分分析year_ratings = data.groupby('publish_year')['rating'].mean().round(1)year_ratings = year_ratings.reset_index()year_ratings = year_ratings.sort_values(by='publish_year')year_ratings.columns = ['publish_year', 'avg_rating']# 每年出版的图书平均评价人数分析year_rating_counts = data.groupby('publish_year')['rating_count'].mean().round(0)year_rating_counts = year_rating_counts.reset_index()year_rating_counts = year_rating_counts.sort_values(by='publish_year')year_rating_counts.columns = ['publish_year', 'avg_rating_count']# 每年出版的图书平均价格分析year_prices = data.groupby('publish_year')['price'].mean().round(1)year_prices = year_prices.reset_index()year_prices = year_prices.sort_values(by='publish_year')# 合并四个结果merged_result = pd.merge(year_counts, year_ratings, on='publish_year', how='outer')merged_result = pd.merge(merged_result, year_rating_counts, on='publish_year', how='outer')merged_result = pd.merge(merged_result, year_prices, on='publish_year', how='outer')# 保存合并后的结果到 CSV 文件save_to_csv(merged_result, './结果输出层/数据分析结果数据/每年出版图书数量和平均评分和平均价格和平均评价人数分析.csv')save_to_mysql(merged_result, '每年出版图书数量和平均评分和平均价格和平均评价人数分析')
分析结果如下图所示:
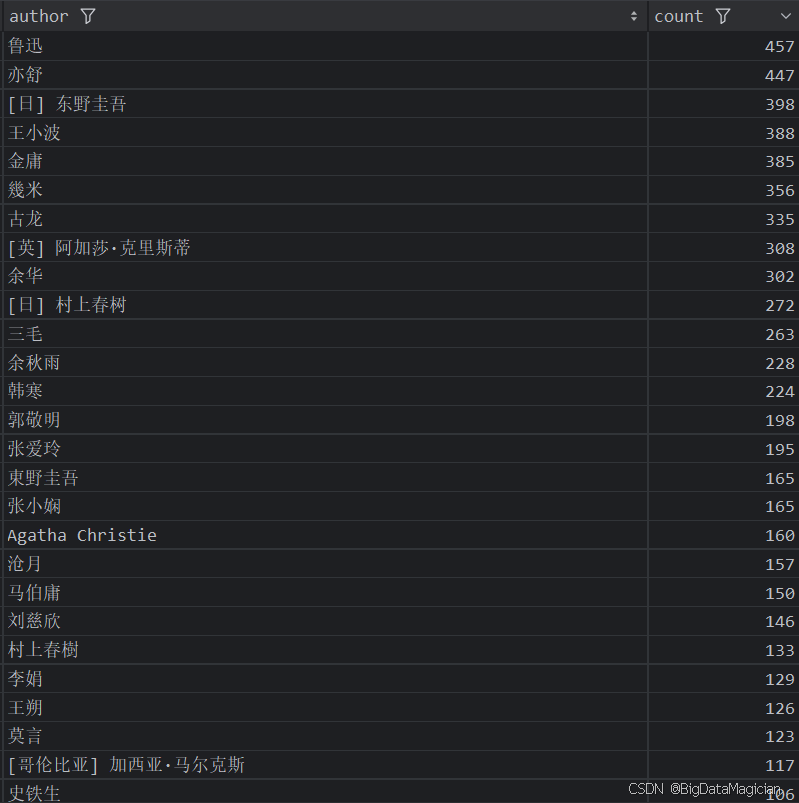
四、不同作者统计分析
1. 不同作者的图书数量统计分析
def author_count_analysis(data):# 统计每个作者的图书数量author_counts = data['author'].value_counts()author_counts = author_counts.reset_index()author_counts.columns = ['author', 'count']save_to_csv(author_counts, './结果输出层/数据分析结果数据/作者图书数量统计分析.csv')save_to_mysql(author_counts, '作者图书数量统计分析')
分析结果如下图所示:
2. 不同作者的平均评分分析
def author_rating_analysis(data):# 计算每个作者的平均评分author_ratings = data.groupby('author')['rating'].mean().round(1)author_ratings = author_ratings.reset_index()author_ratings.columns = ['author', 'avg_rating']save_to_csv(author_ratings, './结果输出层/数据分析结果数据/作者平均评分分析.csv')save_to_mysql(author_ratings, '作者平均评分分析')
分析结果如下图所示:
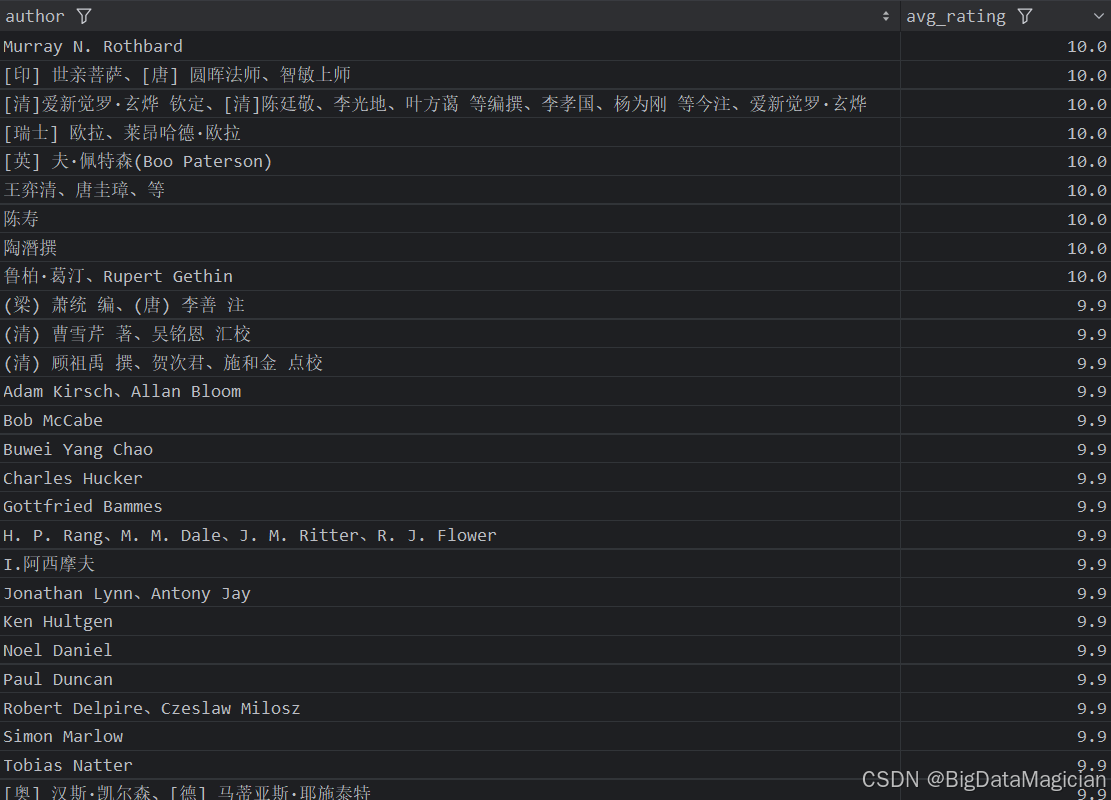
3. 不同作者的平均评价人数分析
def author_rating_count_analysis(data):# 计算每个作者的平均评价人数author_rating_counts = data.groupby('author')['rating_count'].mean().round(0)author_rating_counts = author_rating_counts.reset_index()author_rating_counts.columns = ['author', 'avg_rating_count']save_to_csv(author_rating_counts, './结果输出层/数据分析结果数据/作者平均评价人数分析.csv')save_to_mysql(author_rating_counts, '作者平均评价人数分析')
分析结果如下图所示:
4. 不同作者的平均价格分析
def author_price_analysis(data):# 计算每个作者的平均价格author_prices = data.groupby('author')['price'].mean().round(1)author_prices = author_prices.reset_index()author_prices.columns = ['author', 'avg_price']save_to_csv(author_prices, './结果输出层/数据分析结果数据/作者平均价格分析.csv')save_to_mysql(author_prices, '作者平均价格分析')
分析结果如下图所示:
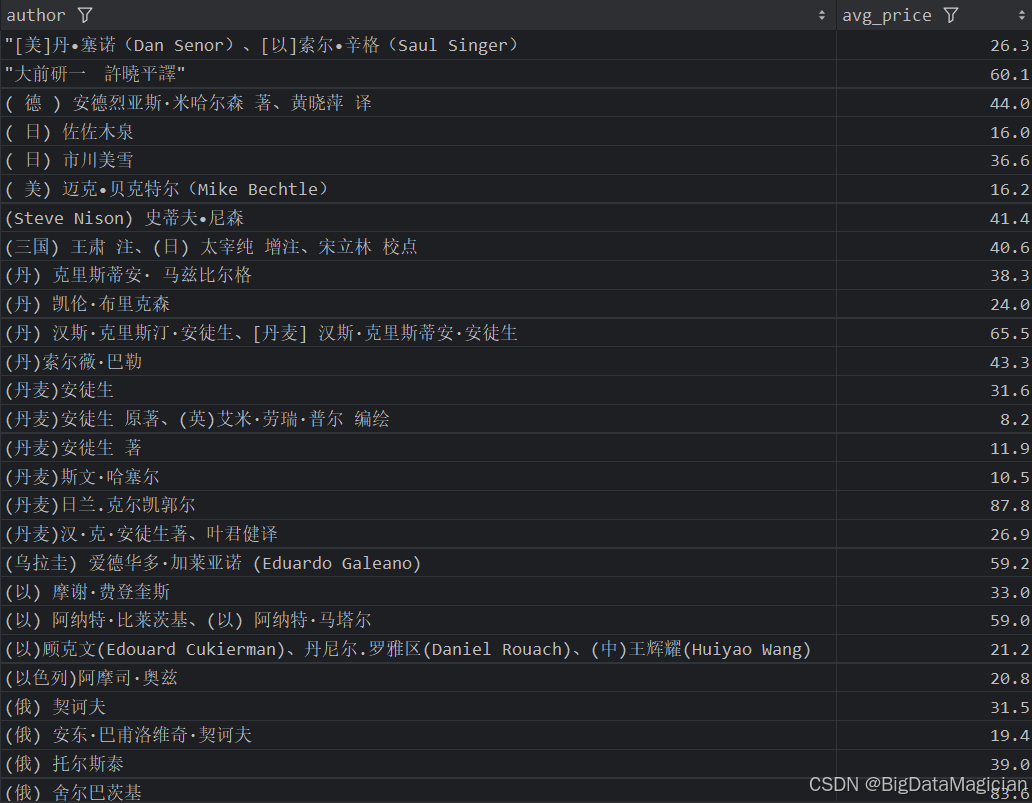
5. 作者综合分析
def author_analysis(data):# 每个作者的图书数量统计分析author_counts = data['author'].value_counts()author_counts = author_counts.reset_index()author_counts.columns = ['author', 'count']# 每个作者的平均评分分析author_ratings = data.groupby('author')['rating'].mean().round(1)author_ratings = author_ratings.reset_index()author_ratings.columns = ['author', 'avg_rating']# 每个作者的平均评价人数分析author_rating_counts = data.groupby('author')['rating_count'].mean().round(0)author_rating_counts = author_rating_counts.reset_index()author_rating_counts.columns = ['author', 'avg_rating_count']# 每个作者的平均价格分析author_prices = data.groupby('author')['price'].mean().round(1)author_prices = author_prices.reset_index()author_prices.columns = ['author', 'avg_price']# 合并四个结果merged_result = pd.merge(author_counts, author_ratings, on='author', how='outer')merged_result = pd.merge(merged_result, author_rating_counts, on='author', how='outer')merged_result = pd.merge(merged_result, author_prices, on='author', how='outer')# 保存合并后的结果到 CSV 文件save_to_csv(merged_result, './结果输出层/数据分析结果数据/作者图书数量和平均评分和平均价格和平均评价人数分析.csv')save_to_mysql(merged_result, '作者图书数量和平均评分和平均价格和平均评价人数分析')
分析结果如下图所示:
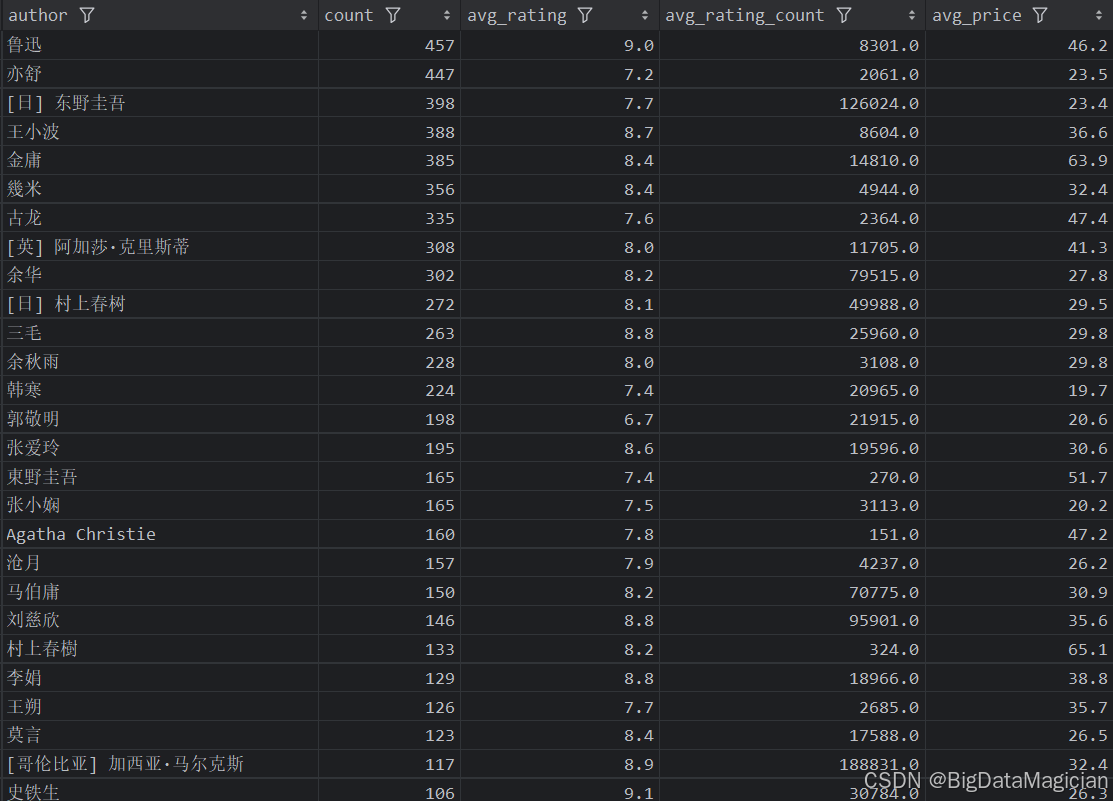
五、不同出版社分析
1. 不同出版社的图书数量统计分析
def publish_count_analysis(data):# 统计每个出版社的图书数量publish_counts = data['publisher'].value_counts()publish_counts = publish_counts.reset_index()publish_counts.columns = ['publisher', 'count']save_to_csv(publish_counts, './结果输出层/数据分析结果数据/出版社图书数量统计分析.csv')save_to_mysql(publish_counts, '出版社图书数量统计分析')
分析结果如下图所示:
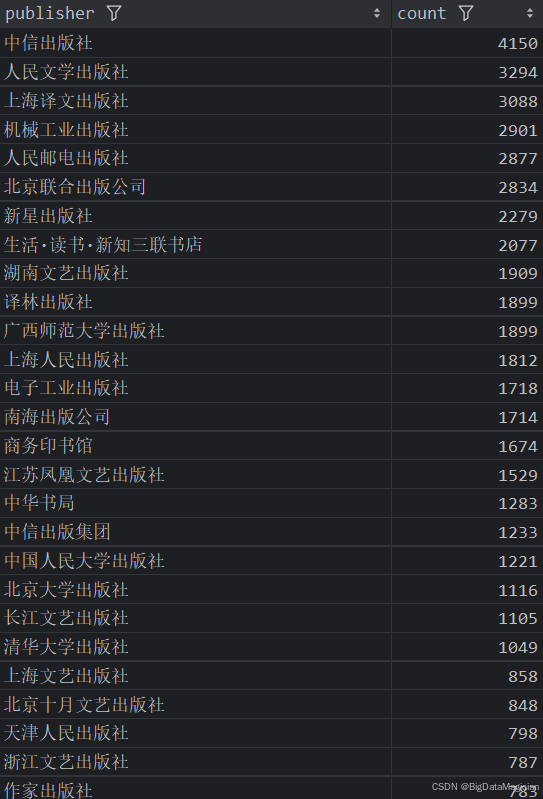
2. 不同出版社的平均评分分析
def publish_rating_analysis(data):# 计算每个出版社的平均评分publish_ratings = data.groupby('publisher')['rating'].mean().round(1)publish_ratings = publish_ratings.reset_index()publish_ratings.columns = ['publisher', 'avg_rating']save_to_csv(publish_ratings, './结果输出层/数据分析结果数据/出版社平均评分分析.csv')save_to_mysql(publish_ratings, '出版社平均评分分析')
分析结果如下图所示:
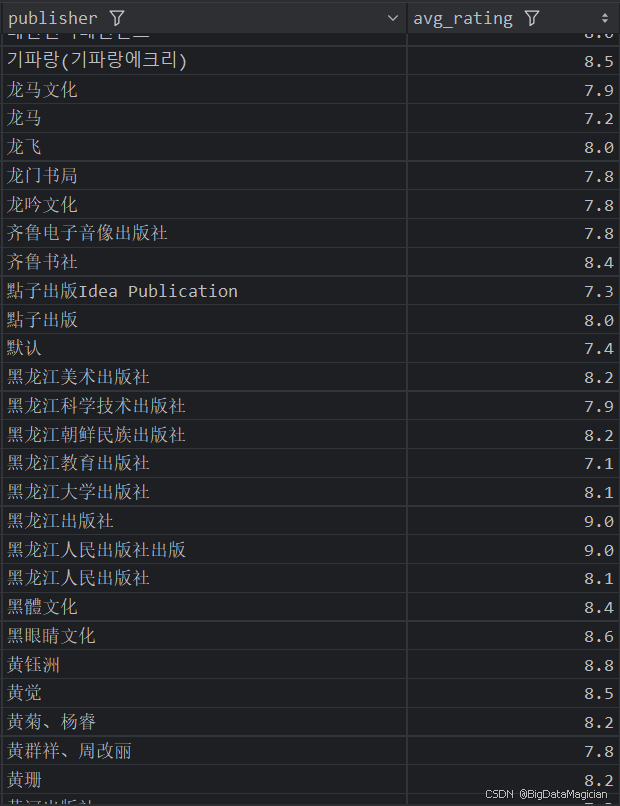
3. 不同出版社的平均评价人数分析
def publish_rating_count_analysis(data):# 计算每个出版社的平均评价人数publish_rating_counts = data.groupby('publisher')['rating_count'].mean().round(0)publish_rating_counts = publish_rating_counts.reset_index()publish_rating_counts.columns = ['publisher', 'avg_rating_count']save_to_csv(publish_rating_counts, './结果输出层/数据分析结果数据/出版社平均评价人数分析.csv')save_to_mysql(publish_rating_counts, '出版社平均评价人数分析')
分析结果如下图所示:
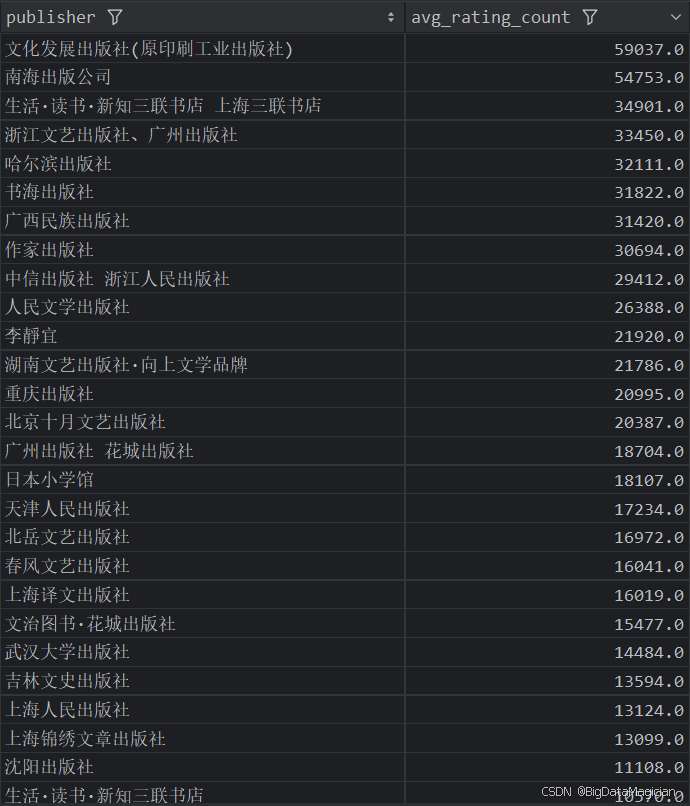
4. 不同出版社的平均价格分析
def publish_price_analysis(data):# 计算每个出版社的平均价格publish_prices = data.groupby('publisher')['price'].mean().round(1)publish_prices = publish_prices.reset_index()publish_prices.columns = ['publisher', 'avg_price']save_to_csv(publish_prices, './结果输出层/数据分析结果数据/出版社平均价格分析.csv')save_to_mysql(publish_prices, '出版社平均价格分析')
分析结果如下图所示:
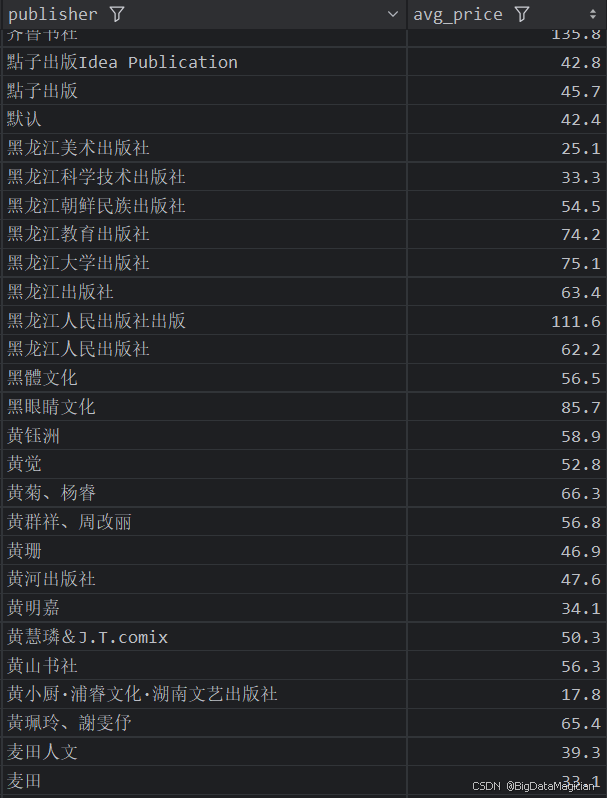
5. 出版社综合分析
def publish_analysis(data):# 每个出版社的图书数量统计分析publish_counts = data['publisher'].value_counts()publish_counts = publish_counts.reset_index()publish_counts.columns = ['publisher', 'count']# 每个出版社的平均评分分析publish_ratings = data.groupby('publisher')['rating'].mean().round(1)publish_ratings = publish_ratings.reset_index()publish_ratings.columns = ['publisher', 'avg_rating']# 每个出版社的平均评价人数分析publish_rating_counts = data.groupby('publisher')['rating_count'].mean().round(0)publish_rating_counts = publish_rating_counts.reset_index()publish_rating_counts.columns = ['publisher', 'avg_rating_count']# 每个出版社的平均价格分析publish_prices = data.groupby('publisher')['price'].mean().round(1)publish_prices = publish_prices.reset_index()publish_prices.columns = ['publisher', 'avg_price']# 合并四个结果merged_result = pd.merge(publish_counts, publish_ratings, on='publisher', how='outer')merged_result = pd.merge(merged_result, publish_rating_counts, on='publisher', how='outer')merged_result = pd.merge(merged_result, publish_prices, on='publisher', how='outer')# 保存合并后的结果到 CSV 文件save_to_csv(merged_result, './结果输出层/数据分析结果数据/出版社图书数量和平均评分和平均价格和平均评价人数分析.csv')save_to_mysql(merged_result, '出版社图书数量和平均评分和平均价格和平均评价人数分析')
分析结果如下图所示:
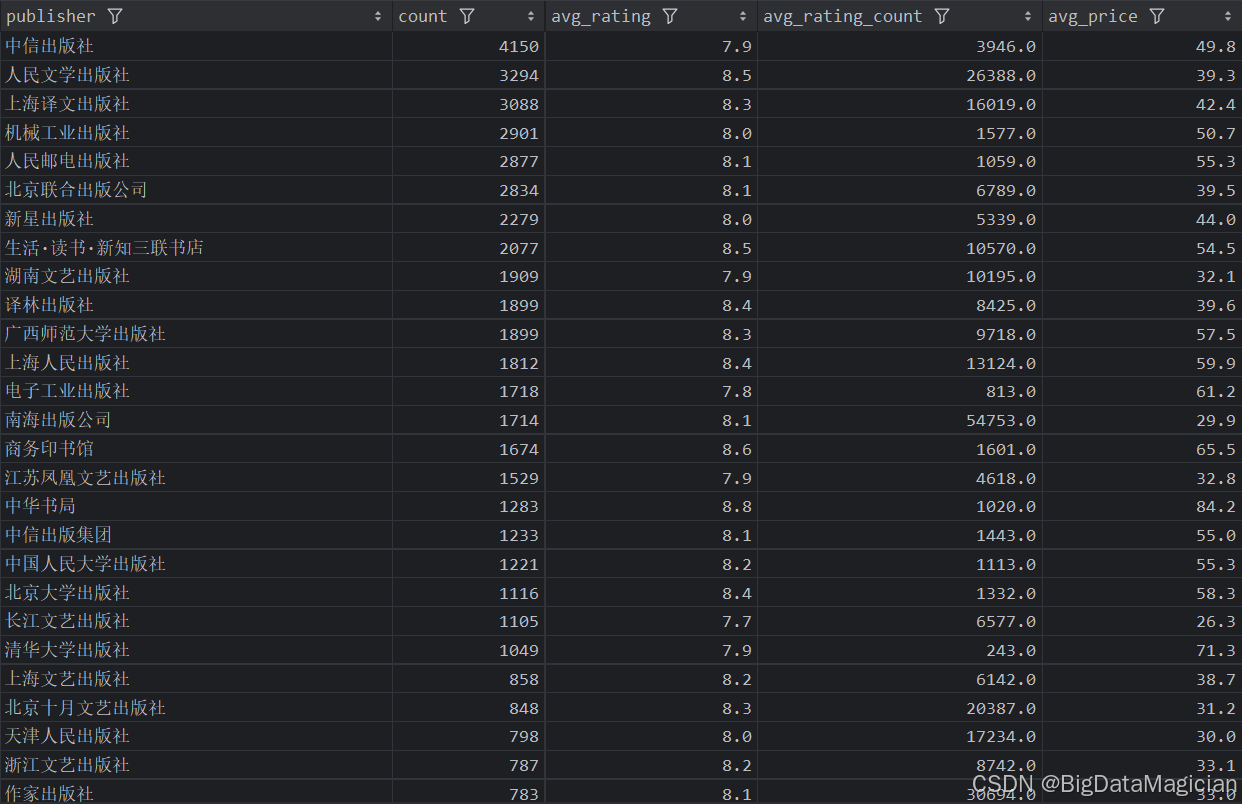
六、其他分析
1. 图书评分分布分析
def rating_analysis(data):# 定义评分区间bins = [0, 2, 4, 6, 8, 10]labels = ['0-2', '2-4', '4-6', '6-8', '8-10']# 使用 pd.cut 函数将评分进行分组data['rating_group'] = pd.cut(data['rating'], bins=bins, labels=labels, right=False)# 统计每个评分区间的图书数量rating_counts = data['rating_group'].value_counts()rating_counts = rating_counts.reset_index()rating_counts.columns = ['rating_range', 'count']save_to_csv(rating_counts, './结果输出层/数据分析结果数据/评分分布统计分析.csv')save_to_mysql(rating_counts, '评分分布统计分析')
2. 图书价格分布分析
def price_analysis(data):# 定义价格区间bins = [0, 50, 100, 150, 200, 250, 300, 350, 400, 450, 500]labels = ['0-50', '50-100', '100-150', '150-200', '200-250', '250-300', '300-350', '350-400', '400-450', '450-500']# 使用 pd.cut 函数将价格进行分组data['price_group'] = pd.cut(data['price'], bins=bins, labels=labels, right=False)# 统计每个价格区间的图书数量price_counts = data['price_group'].value_counts()price_counts = price_counts.reset_index()price_counts.columns = ['price_range', 'count']save_to_csv(price_counts, './结果输出层/数据分析结果数据/图书价格分布统计分析.csv')save_to_mysql(price_counts, '图书价格分布统计分析')
3. 译者翻译的图书数量统计分析(前15)
def translator_count_analysis(data):# 统计每个译者的图书数量translator_counts = data['translator'].value_counts()translator_counts = translator_counts.reset_index()translator_counts.columns = ['translator', 'count']translator_counts = translator_counts.sort_values(by='count', ascending=False)translator_counts = translator_counts.head(15)save_to_csv(translator_counts, './结果输出层/数据分析结果数据/译者图书数量统计分析.csv')save_to_mysql(translator_counts, '译者图书数量统计分析')
4. 评价人数多的图书分析(前15)
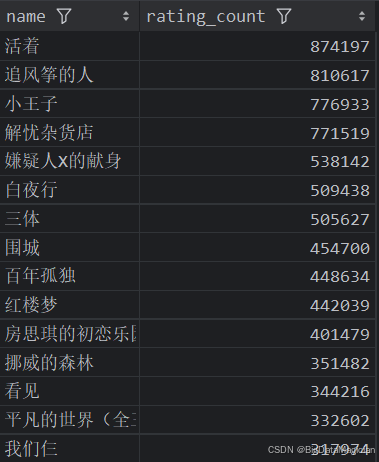
def high_rating_count_books_analysis(data):high_rating_count_books = data[['name', 'rating_count']]high_rating_count_books = high_rating_count_books.sort_values(by='rating_count', ascending=False)high_rating_count_books = high_rating_count_books.drop_duplicates(subset=['name'])high_rating_count_books = high_rating_count_books.head(15)save_to_csv(high_rating_count_books, './结果输出层/数据分析结果数据/评价人数多的图书分析.csv')save_to_mysql(high_rating_count_books, '评价人数多的图书分析')
分析结果如下图所示:
5. 评分最高的图书分析(前15)
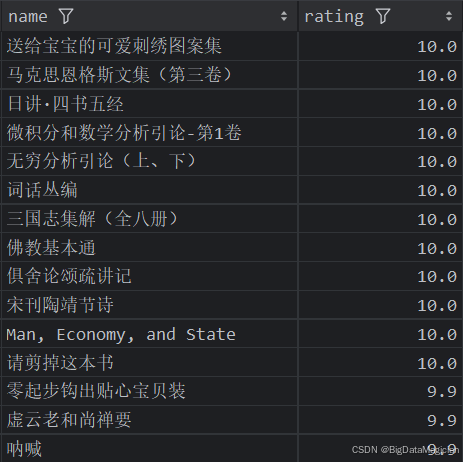
def high_rating_books_analysis(data):high_rating_books = data[['name', 'rating']]high_rating_books = high_rating_books.sort_values(by='rating', ascending=False)high_rating_books = high_rating_books.drop_duplicates(subset=['name'])high_rating_books = high_rating_books.head(15)save_to_csv(high_rating_books, './结果输出层/数据分析结果数据/评分最高的图书分析.csv')save_to_mysql(high_rating_books, '评分最高的图书分析')
分析结果如下图所示:
6. 评价人数最多且评分高的图书分析(前15)
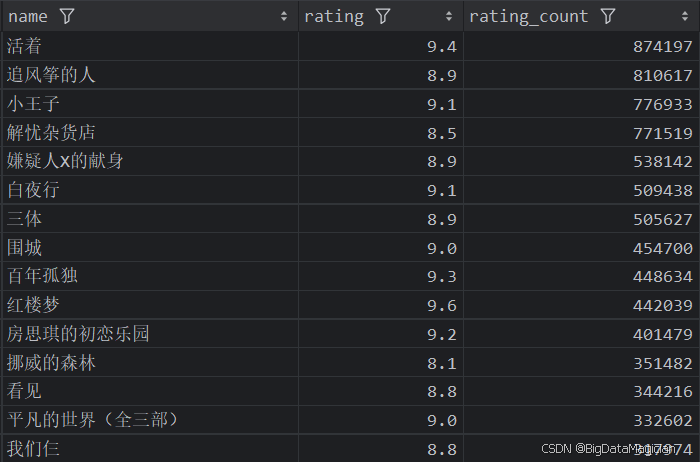
def high_rating_and_rating_count_books_analysis(data):high_rating_and_rating_count_books = data[['name', 'rating', 'rating_count']]high_rating_and_rating_count_books = high_rating_and_rating_count_books.sort_values(by=['rating_count', 'rating'], ascending=False)high_rating_and_rating_count_books = high_rating_and_rating_count_books.drop_duplicates(subset=['name'])high_rating_and_rating_count_books = high_rating_and_rating_count_books.head(15)save_to_csv(high_rating_and_rating_count_books, './结果输出层/数据分析结果数据/评分高且评价人数最多的图书分析.csv')save_to_mysql(high_rating_and_rating_count_books, '评分高且评价人数最多的图书分析')
分析结果如下图所示:
七、完整代码
from pathlib import Pathimport pandas as pd
from matplotlib import pyplot as plt
from sqlalchemy import create_engine# 设置支持中文的字体,这里以黑体为例
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 解决负号'-'显示为方块的问题def load_data(csv_file_path):try:data = pd.read_csv(csv_file_path)return dataexcept FileNotFoundError:print("未找到指定的 CSV 文件,请检查文件路径和文件名。")except Exception as e:print(f"加载数据时出现错误: {e}")# 保存分析后的数据为csv文件
def save_to_csv(data, csv_file_path):# 使用 pathlib 处理文件路径path = Path(csv_file_path)# 检查文件所在目录是否存在,如果不存在则创建path.parent.mkdir(parents=True, exist_ok=True)data.to_csv(csv_file_path, index=False, encoding='utf-8-sig', mode='w', header=True)print(f'清洗后的数据已保存到 {csv_file_path} 文件')# 保存分析后的数据到MySQL数据库
def save_to_mysql(data, table_name):engine = create_engine(f'mysql+mysqlconnector://root:zxcvbq@127.0.0.1:3306/douban')data.to_sql(table_name, con=engine, index=False, if_exists='replace')print(f'清洗后的数据已保存到 {table_name} 表')# 每种分类图书数量统计分析
def category_count_analysis(data):# 统计每个分类的图书数量category_counts = data['category_name'].value_counts()category_counts = category_counts.reset_index()category_counts.columns = ['category_name', 'count']save_to_csv(category_counts, './结果输出层/数据分析结果数据/分类图书数量统计分析.csv')save_to_mysql(category_counts, '分类图书数量统计分析')# 每种分类的平均评分统计分析
def category_rating_analysis(data):# 计算每个分类的平均评分category_ratings = data.groupby('category_name')['rating'].mean().round(1)category_ratings = category_ratings.reset_index()category_ratings.columns = ['category_name', 'avg_rating']save_to_csv(category_ratings, './结果输出层/数据分析结果数据/每个分类的平均评分统计分析.csv')save_to_mysql(category_ratings, '每个分类的平均评分统计分析')# 每种分类的平均评价人数统计分析
def category_rating_count_analysis(data):# 计算每个分类的平均评价人数category_rating_counts = data.groupby('category_name')['rating_count'].mean().round(0)category_rating_counts = category_rating_counts.reset_index()category_rating_counts.columns = ['category_name', 'avg_rating_count']save_to_csv(category_rating_counts, './结果输出层/数据分析结果数据/每个分类的平均评价人数统计分析.csv')save_to_mysql(category_rating_counts, '每个分类的平均评价人数统计分析')# 每种分类的平均价格统计分析
def category_price_analysis(data):# 计算每个分类的平均价格category_prices = data.groupby('category_name')['price'].mean().round(1)category_prices = category_prices.reset_index()category_prices.columns = ['category_name', 'avg_price']save_to_csv(category_prices, './结果输出层/数据分析结果数据/每个分类的平均价格统计分析.csv')save_to_mysql(category_prices, '每个分类的平均价格统计分析')# 每种分类的图书数量、平均评分、平均价格和平均评价人数统计分析
def category_analysis(data):# 统计每个分类的图书数量category_counts = data['category_name'].value_counts()category_counts = category_counts.reset_index()category_counts.columns = ['category_name', 'count']# 计算每个分类的平均评分category_ratings = data.groupby('category_name')['rating'].mean().round(1)category_ratings = category_ratings.reset_index()category_ratings.columns = ['category_name', 'avg_rating']# 计算每个分类的平均评价人数category_rating_counts = data.groupby('category_name')['rating_count'].mean().round(0)category_rating_counts = category_rating_counts.reset_index()category_rating_counts.columns = ['category_name', 'avg_rating_count']# 计算每个分类的平均价格category_prices = data.groupby('category_name')['price'].mean().round(1)category_prices = category_prices.reset_index()category_prices.columns = ['category_name', 'avg_price']# 合并四个结果merged_result = pd.merge(category_counts, category_ratings, on='category_name', how='outer')merged_result = pd.merge(merged_result, category_rating_counts, on='category_name', how='outer')merged_result = pd.merge(merged_result, category_prices, on='category_name', how='outer')# 保存合并后的结果到 CSV 文件save_to_csv(merged_result, './结果输出层/数据分析结果数据/每种分类的图书数量和平均评分和平均评价人数和平均价格统计分析.csv')save_to_mysql(merged_result, '每种分类的图书数量和平均评分和平均评价人数和平均价格统计分析')# 每年出版的图书数量统计分析
def year_count_analysis(data):# 统计每年出版的图书数量year_counts = data['publish_year'].value_counts()year_counts = year_counts.reset_index()# 按照年份升序排序year_counts = year_counts.sort_values(by='publish_year')year_counts.columns = ['publish_year', 'count']save_to_csv(year_counts, './结果输出层/数据分析结果数据/每年出版的图书数量统计分析.csv')save_to_mysql(year_counts, '每年出版的图书数量统计分析')# 每年出版的图书平均评分分析
def year_rating_analysis(data):year_ratings = data.groupby('publish_year')['rating'].mean().round(1)year_ratings = year_ratings.reset_index()year_ratings = year_ratings.sort_values(by='publish_year')year_ratings.columns = ['publish_year', 'avg_rating']save_to_csv(year_ratings, './结果输出层/数据分析结果数据/每年出版的图书平均评分分析.csv')save_to_mysql(year_ratings, '每年出版的图书平均评分分析')# 每年出版图书平均评价人数分析
def year_rating_count_analysis(data):year_rating_counts = data.groupby('publish_year')['rating_count'].mean().round(0)year_rating_counts = year_rating_counts.reset_index()year_rating_counts = year_rating_counts.sort_values(by='publish_year')year_rating_counts.columns = ['publish_year', 'avg_rating_count']save_to_csv(year_rating_counts, './结果输出层/数据分析结果数据/每年出版图书平均评价人数分析.csv')save_to_mysql(year_rating_counts, '每年出版图书平均评价人数分析')# 每年出版图书平均价格分析
def year_price_analysis(data):year_prices = data.groupby('publish_year')['price'].mean().round(1)year_prices = year_prices.reset_index()year_prices = year_prices.sort_values(by='publish_year')year_prices.columns = ['publish_year', 'avg_price']save_to_csv(year_prices, './结果输出层/数据分析结果数据/每年出版图书平均价格分析.csv')save_to_mysql(year_prices, '每年出版图书平均价格分析')# 每年出版图书数量、平均评分、平均价格和平均评价人数分析
def year_analysis(data):# 每年出版的图书数量统计分析year_counts = data['publish_year'].value_counts()year_counts = year_counts.reset_index()year_counts = year_counts.sort_values(by='publish_year')year_counts.columns = ['publish_year', 'count']# 每年出版的图书平均评分分析year_ratings = data.groupby('publish_year')['rating'].mean().round(1)year_ratings = year_ratings.reset_index()year_ratings = year_ratings.sort_values(by='publish_year')year_ratings.columns = ['publish_year', 'avg_rating']# 每年出版的图书平均评价人数分析year_rating_counts = data.groupby('publish_year')['rating_count'].mean().round(0)year_rating_counts = year_rating_counts.reset_index()year_rating_counts = year_rating_counts.sort_values(by='publish_year')year_rating_counts.columns = ['publish_year', 'avg_rating_count']# 每年出版的图书平均价格分析year_prices = data.groupby('publish_year')['price'].mean().round(1)year_prices = year_prices.reset_index()year_prices = year_prices.sort_values(by='publish_year')# 合并四个结果merged_result = pd.merge(year_counts, year_ratings, on='publish_year', how='outer')merged_result = pd.merge(merged_result, year_rating_counts, on='publish_year', how='outer')merged_result = pd.merge(merged_result, year_prices, on='publish_year', how='outer')# 保存合并后的结果到 CSV 文件save_to_csv(merged_result, './结果输出层/数据分析结果数据/每年出版图书数量和平均评分和平均价格和平均评价人数分析.csv')save_to_mysql(merged_result, '每年出版图书数量和平均评分和平均价格和平均评价人数分析')# 每个作者的图书数量统计分析
def author_count_analysis(data):# 统计每个作者的图书数量author_counts = data['author'].value_counts()author_counts = author_counts.reset_index()author_counts.columns = ['author', 'count']save_to_csv(author_counts, './结果输出层/数据分析结果数据/作者图书数量统计分析.csv')save_to_mysql(author_counts, '作者图书数量统计分析')# 每个作者的平均评分分析
def author_rating_analysis(data):# 计算每个作者的平均评分author_ratings = data.groupby('author')['rating'].mean().round(1)author_ratings = author_ratings.reset_index()author_ratings.columns = ['author', 'avg_rating']save_to_csv(author_ratings, './结果输出层/数据分析结果数据/作者平均评分分析.csv')save_to_mysql(author_ratings, '作者平均评分分析')# 每个作者的平均评价人数分析
def author_rating_count_analysis(data):# 计算每个作者的平均评价人数author_rating_counts = data.groupby('author')['rating_count'].mean().round(0)author_rating_counts = author_rating_counts.reset_index()author_rating_counts.columns = ['author', 'avg_rating_count']save_to_csv(author_rating_counts, './结果输出层/数据分析结果数据/作者平均评价人数分析.csv')save_to_mysql(author_rating_counts, '作者平均评价人数分析')# 每个作者的平均价格分析
def author_price_analysis(data):# 计算每个作者的平均价格author_prices = data.groupby('author')['price'].mean().round(1)author_prices = author_prices.reset_index()author_prices.columns = ['author', 'avg_price']save_to_csv(author_prices, './结果输出层/数据分析结果数据/作者平均价格分析.csv')save_to_mysql(author_prices, '作者平均价格分析')# 每个作者的图书数量、平均评分、平均价格和平均评价人数分析
def author_analysis(data):# 每个作者的图书数量统计分析author_counts = data['author'].value_counts()author_counts = author_counts.reset_index()author_counts.columns = ['author', 'count']# 每个作者的平均评分分析author_ratings = data.groupby('author')['rating'].mean().round(1)author_ratings = author_ratings.reset_index()author_ratings.columns = ['author', 'avg_rating']# 每个作者的平均评价人数分析author_rating_counts = data.groupby('author')['rating_count'].mean().round(0)author_rating_counts = author_rating_counts.reset_index()author_rating_counts.columns = ['author', 'avg_rating_count']# 每个作者的平均价格分析author_prices = data.groupby('author')['price'].mean().round(1)author_prices = author_prices.reset_index()author_prices.columns = ['author', 'avg_price']# 合并四个结果merged_result = pd.merge(author_counts, author_ratings, on='author', how='outer')merged_result = pd.merge(merged_result, author_rating_counts, on='author', how='outer')merged_result = pd.merge(merged_result, author_prices, on='author', how='outer')# 保存合并后的结果到 CSV 文件save_to_csv(merged_result, './结果输出层/数据分析结果数据/作者图书数量和平均评分和平均价格和平均评价人数分析.csv')save_to_mysql(merged_result, '作者图书数量和平均评分和平均价格和平均评价人数分析')# 每个出版社的图书数量统计分析
def publish_count_analysis(data):# 统计每个出版社的图书数量publish_counts = data['publisher'].value_counts()publish_counts = publish_counts.reset_index()publish_counts.columns = ['publisher', 'count']save_to_csv(publish_counts, './结果输出层/数据分析结果数据/出版社图书数量统计分析.csv')save_to_mysql(publish_counts, '出版社图书数量统计分析')# 每个出版社的平均评分分析
def publish_rating_analysis(data):# 计算每个出版社的平均评分publish_ratings = data.groupby('publisher')['rating'].mean().round(1)publish_ratings = publish_ratings.reset_index()publish_ratings.columns = ['publisher', 'avg_rating']save_to_csv(publish_ratings, './结果输出层/数据分析结果数据/出版社平均评分分析.csv')save_to_mysql(publish_ratings, '出版社平均评分分析')# 每个出版社的平均评价人数分析
def publish_rating_count_analysis(data):# 计算每个出版社的平均评价人数publish_rating_counts = data.groupby('publisher')['rating_count'].mean().round(0)publish_rating_counts = publish_rating_counts.reset_index()publish_rating_counts.columns = ['publisher', 'avg_rating_count']save_to_csv(publish_rating_counts, './结果输出层/数据分析结果数据/出版社平均评价人数分析.csv')save_to_mysql(publish_rating_counts, '出版社平均评价人数分析')# 每个出版社的平均价格分析
def publish_price_analysis(data):# 计算每个出版社的平均价格publish_prices = data.groupby('publisher')['price'].mean().round(1)publish_prices = publish_prices.reset_index()publish_prices.columns = ['publisher', 'avg_price']save_to_csv(publish_prices, './结果输出层/数据分析结果数据/出版社平均价格分析.csv')save_to_mysql(publish_prices, '出版社平均价格分析')# 每个出版社的图书数量、平均评分、平均价格和平均评价人数分析
def publish_analysis(data):# 每个出版社的图书数量统计分析publish_counts = data['publisher'].value_counts()publish_counts = publish_counts.reset_index()publish_counts.columns = ['publisher', 'count']# 每个出版社的平均评分分析publish_ratings = data.groupby('publisher')['rating'].mean().round(1)publish_ratings = publish_ratings.reset_index()publish_ratings.columns = ['publisher', 'avg_rating']# 每个出版社的平均评价人数分析publish_rating_counts = data.groupby('publisher')['rating_count'].mean().round(0)publish_rating_counts = publish_rating_counts.reset_index()publish_rating_counts.columns = ['publisher', 'avg_rating_count']# 每个出版社的平均价格分析publish_prices = data.groupby('publisher')['price'].mean().round(1)publish_prices = publish_prices.reset_index()publish_prices.columns = ['publisher', 'avg_price']# 合并四个结果merged_result = pd.merge(publish_counts, publish_ratings, on='publisher', how='outer')merged_result = pd.merge(merged_result, publish_rating_counts, on='publisher', how='outer')merged_result = pd.merge(merged_result, publish_prices, on='publisher', how='outer')# 保存合并后的结果到 CSV 文件save_to_csv(merged_result, './结果输出层/数据分析结果数据/出版社图书数量和平均评分和平均价格和平均评价人数分析.csv')save_to_mysql(merged_result, '出版社图书数量和平均评分和平均价格和平均评价人数分析')# 评分分布分析
def rating_analysis(data):# 定义评分区间bins = [0, 2, 4, 6, 8, 10]labels = ['0-2', '2-4', '4-6', '6-8', '8-10']# 使用 pd.cut 函数将评分进行分组data['rating_group'] = pd.cut(data['rating'], bins=bins, labels=labels, right=False)# 统计每个评分区间的图书数量rating_counts = data['rating_group'].value_counts()rating_counts = rating_counts.reset_index()rating_counts.columns = ['rating_range', 'count']save_to_csv(rating_counts, './结果输出层/数据分析结果数据/评分分布统计分析.csv')save_to_mysql(rating_counts, '评分分布统计分析')# 图书价格分布分析
def price_analysis(data):# 定义价格区间bins = [0, 50, 100, 150, 200, 250, 300, 350, 400, 450, 500]labels = ['0-50', '50-100', '100-150', '150-200', '200-250', '250-300', '300-350', '350-400', '400-450', '450-500']# 使用 pd.cut 函数将价格进行分组data['price_group'] = pd.cut(data['price'], bins=bins, labels=labels, right=False)# 统计每个价格区间的图书数量price_counts = data['price_group'].value_counts()price_counts = price_counts.reset_index()price_counts.columns = ['price_range', 'count']save_to_csv(price_counts, './结果输出层/数据分析结果数据/图书价格分布统计分析.csv')save_to_mysql(price_counts, '图书价格分布统计分析')# 译者翻译的图书数量统计分析(前15)
def translator_count_analysis(data):# 统计每个译者的图书数量translator_counts = data['translator'].value_counts()translator_counts = translator_counts.reset_index()translator_counts.columns = ['translator', 'count']translator_counts = translator_counts.sort_values(by='count', ascending=False)translator_counts = translator_counts.head(15)save_to_csv(translator_counts, './结果输出层/数据分析结果数据/译者图书数量统计分析.csv')save_to_mysql(translator_counts, '译者图书数量统计分析')# 价格、评分、评分人数和出版年份相关性分析
def correlation_analysis(data):# 计算价格、评分、评分人数和出版年份之间的相关性correlation = data[['price', 'rating', 'rating_count', 'publish_year']].corr()correlation = correlation.reset_index()# 保存统计结果到 CSV 文件save_to_csv(correlation, './结果输出层/数据分析结果数据/价格、评分、评分人数和出版年份相关性分析.csv')save_to_mysql(correlation, '价格、评分、评分人数和出版年份相关性分析')# 评价人数多的图书分析(前15)
def high_rating_count_books_analysis(data):high_rating_count_books = data[['name', 'rating_count']]high_rating_count_books = high_rating_count_books.sort_values(by='rating_count', ascending=False)high_rating_count_books = high_rating_count_books.drop_duplicates(subset=['name'])high_rating_count_books = high_rating_count_books.head(15)save_to_csv(high_rating_count_books, './结果输出层/数据分析结果数据/评价人数多的图书分析.csv')save_to_mysql(high_rating_count_books, '评价人数多的图书分析')# 评分最高的图书分析(前15)
def high_rating_books_analysis(data):high_rating_books = data[['name', 'rating']]high_rating_books = high_rating_books.sort_values(by='rating', ascending=False)high_rating_books = high_rating_books.drop_duplicates(subset=['name'])high_rating_books = high_rating_books.head(15)save_to_csv(high_rating_books, './结果输出层/数据分析结果数据/评分最高的图书分析.csv')save_to_mysql(high_rating_books, '评分最高的图书分析')# 评分高且评价人数最多的图书(前15)
def high_rating_and_rating_count_books_analysis(data):high_rating_and_rating_count_books = data[['name', 'rating', 'rating_count']]high_rating_and_rating_count_books = high_rating_and_rating_count_books.sort_values(by=['rating_count', 'rating'], ascending=False)high_rating_and_rating_count_books = high_rating_and_rating_count_books.drop_duplicates(subset=['name'])high_rating_and_rating_count_books = high_rating_and_rating_count_books.head(15)save_to_csv(high_rating_and_rating_count_books, './结果输出层/数据分析结果数据/评分高且评价人数最多的图书分析.csv')save_to_mysql(high_rating_and_rating_count_books, '评分高且评价人数最多的图书分析')if __name__ == '__main__':# 加载数据data = load_data('./中间处理层/清洗后的豆瓣图书数据集.csv')category_count_analysis(data)category_rating_analysis(data)category_rating_count_analysis(data)category_price_analysis(data)category_analysis(data)year_count_analysis(data)year_rating_analysis(data)year_rating_count_analysis(data)year_price_analysis(data)year_analysis(data)author_count_analysis(data)author_rating_analysis(data)author_rating_count_analysis(data)author_price_analysis(data)author_analysis(data)publish_count_analysis(data)publish_rating_analysis(data)publish_rating_count_analysis(data)publish_price_analysis(data)publish_analysis(data)rating_analysis(data)price_analysis(data)translator_count_analysis(data)correlation_analysis(data)high_rating_count_books_analysis(data)high_rating_books_analysis(data)high_rating_and_rating_count_books_analysis(data)