go学习-GMP模型
GMP 好理解还是 GPM 好理解?
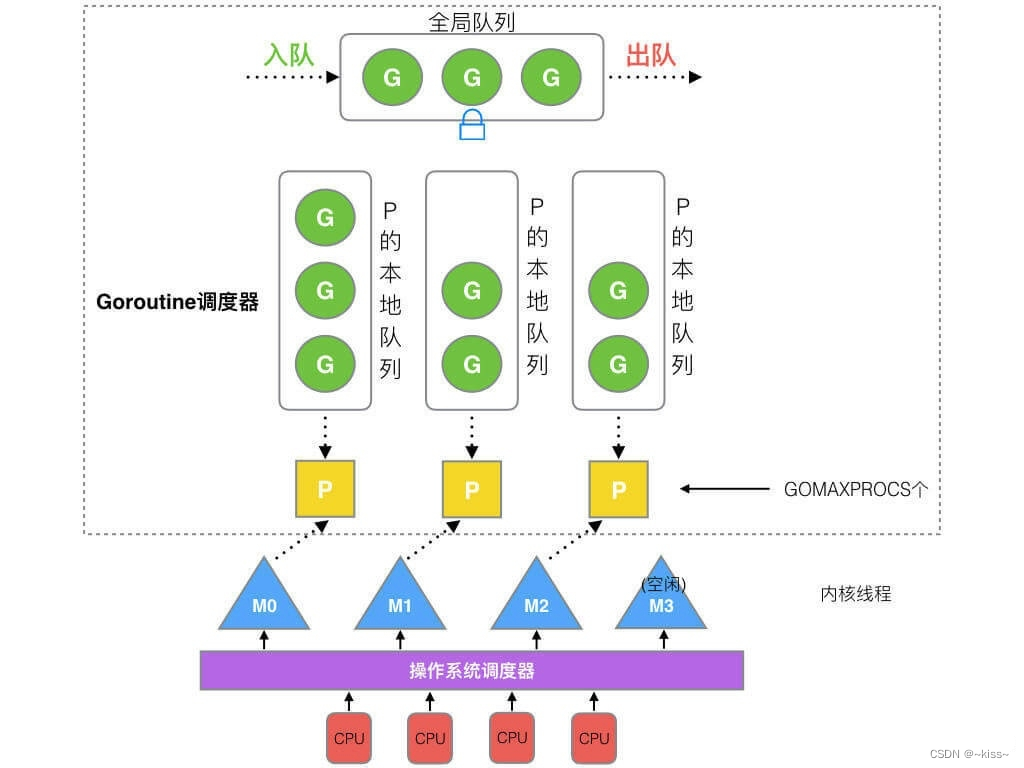
按照上述图,从上往下,GPM更适合理解
GMP 模型: Go 语言运行时系统中的 Goroutine、用于管理 Goroutine 调度的 Go Scheduler(P)、机器可用的逻辑处理器数量(M)。
理解GPM
G
每个 Goroutine 是一个轻量级“线程”,称之为“协程”,可由 Go 运行时系统并发执行
G与P的关系
Goroutine 通过 Go Scheduler 调度运行
Go Scheduler 负责在适当时间调度 Goroutine 的执行
并在必要时将 Goroutine 阻塞和调度到其他 Goroutine 执行上下文
P
P 是中介者,连接 Goroutine 和 M,由于 Go Scheduler 在用户 CPU 时间片内并行执行 Goroutine,因此也必须用 P 进行有效的调度。
Go 运行时系统可以自动调整 P 的数量,以确保它们与当前运行的 Goroutine 的数量大致相同,并且可以在需要更多/更少 P 时及时适应。
P 叫 go运行时的逻辑并发单元,每个OS线程需要获取一个P才能执行
每个P中都包含运行一个线程所需的全部资源(比如线程栈),包括存放G的就绪队列,以及分配堆内存所需的地址空间等
这些在运行main.main前就在runtime.main中(程序启动时)创建好,所以并发执行时就可以避免冲突
P的本地队列上限默认最多 GOMAXPROCS = 256 个,如果想要更改队列长度限制,使用 runtime.GOMAXPROCS(n) 调整
M
M 是处理器,绑定一个具体的OS线程(内核线程),Goroutine 运行的上下文在这里被调度并执行,所以也是 Goroutine 执行的上下文
管理 Goroutine 的运行状态、切换执行上下文
Go 运行时系统会根据机器硬件和条件动态地分配这些处理器,以确保 Goroutine 能够高效地并发运行
一个 M 最多有一个空闲的 P,有一个M阻塞,会创建或者唤醒一个新的M;若有空闲,则会回收或睡眠此M。
全局队列作为一个候选队列,可以同时为不同的 P 提供 Goroutine,从而使 Goroutine 尽快找到执行线程(M)
如果所有的 P 的本地队列都已满,并且全局队列也已满,Go 运行时系统将通过动态增加 M 的数量来解决压力
以尽快地使 Goroutine 开始运行,但OS是否愿意加M,则需要根据系统负载来定。
在默认情况下,全局队列的大小是默认 P 的数量的系数,最小值为 4,最大值为 32768
OS分配到当前Go程序的内核线程数
使用 runtime.NumCPU() 查询M数量,返回当前系统可用的逻辑处理器数量
返回值可能会因为不同的操作系统和系统配置而有所不同
有些操作系统可能会在系统负载高峰期动态增加或减少 M 的数量,以适应不同的负载需求
它只会返回运行时系统认为当前可用的逻辑处理器数量,而不是一成不变的固定值
当所有 P 的本地队列都已满,且全局队列也满时,有新的Goroutine就绪
- Go 运行时系统会请求操作系统分配更多线程,以进一步提高系统并发处理的能力,启动一个新线程,即新的 M (machine)
- 新的 M 将从全局队列中拿走一个等待 Goroutine 并开始运行它
- 新的 M 将在全局队列和所有本地队列之间轮询,直到所有队列都变得空闲或有 Goroutine 准备好运行,这将减少因 Goroutine 等待执行带来的延迟
GMP 特点
Go 语言的并发性能和可伸缩性得到了最大化的利用。
当 CPU 资源充足时,它可以在 Goroutine 和 P 之间平衡负载,并在适当的时候调度 Goroutine 到合适的 M 上以保证运行效率
Go 协程调度为什么优于线程
多进程/多线程问题
进程/线程数量越多,切换成本越大
多进程/多线程的壁垒:高内存占用,高CPU调度切换
同步竞争,如锁等
协程如何设计
N:1 : 无法利用多个CPU,出现阻塞瓶颈
1:1 :和多线程、多进程无区别,切换协程成本代价昂贵
M:N :能够利用多核,过度依赖协程调度器的优化和算法
如何高效
复用线程
避免频繁的创建、销毁线程,而是对线程的复用
Work stealing机制 (work偷窃)
当本线程的P队列中没有G可用并且全局队列为空时,会主动去其他线程的P队列中获取,避免线程的销毁
handle off 机制
当本线程的G运行阻塞时,会释放绑定的P队列,把P队列转移到其他空闲的线程上去
利用并行
GOMAXPROCS设置P的数量,最多有GOMAXPROCS个线程分布在CPU上运行
抢占
一个Goroutine 最多占用CPU 10ms 就会交给其他协程,防止其被饿死
Go 语言的抢占是基于协作式调度的,而切换的主动权在 Goroutine 执行上
- 通过代码的设计来主动让 Goroutine 放弃控制权,以便让其它 Goroutine 获得执行时间片
使用 runtime.Gosched() 主动让当前 Goroutine 放弃 CPU 控制权,使当前 Goroutine 立即进入就绪状态,并重新排队等待下一次调度 - 内部编写超时限制的代码来防止 Goroutine 长时间执行
Go如何调整协程优先级?
在 Go 语言中,所有 Goroutine 都有相同的默认优先级,不能直接通过代码来调整 Goroutine 的优先级
这个是不是一个协程的缺点?我觉着是
全局G队列
当M执行work stealing 机制时,无法从其他P中获取G,就会从全局队列中获取
总结
G是买家,M是卖家,M根据最近的行情,动态调整,也可以去抢其他M的活
G呢,买的东西也不知道是哪个M操办的,G之间是公平的
参考文档
https://juejin.cn/post/7119307307728994335