mysql知识总结 索引篇
mysql知识总结 索引篇
- 1. 索引问题常见分类
- 1. 什么是索引
- 2. 索引的分类
- 3. 从数据结构分类
- 4. 通过二级索引查询商品数据的过程
- 5. 为什么选择B+树作为索引呢?
本文是阅读 小林coding 后的读书笔记
原文可以点击上面超链接到达
也可以直接百度搜索 小林coding
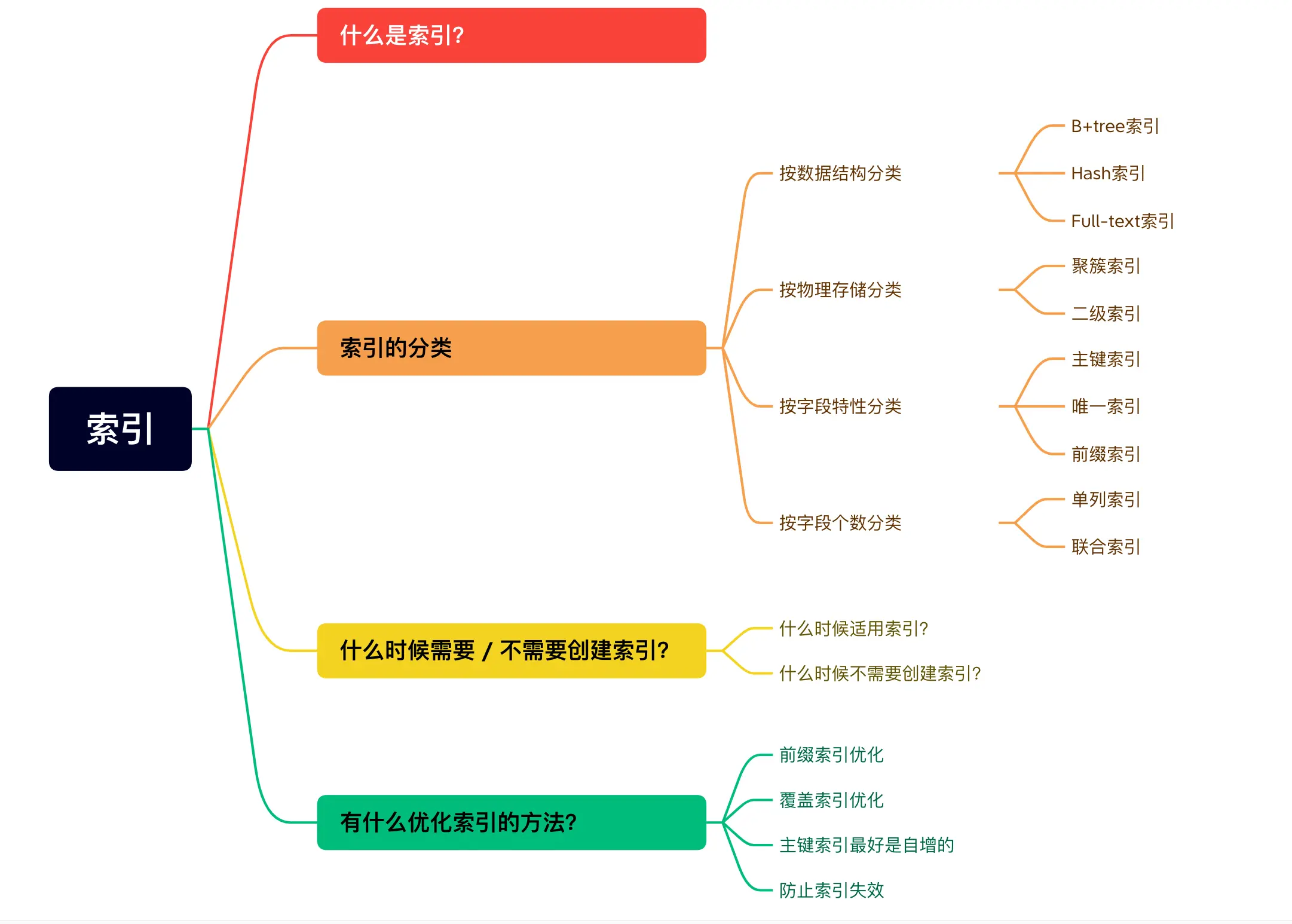
1. 索引问题常见分类
1. 什么是索引
索引就是目录
比如说我们想要查询一本书的某内容 最呆的方法就是一页一页的取翻嘛
但是这样子的效率就很低 所以说我们发明了目录 索引也是同样的道理
什么是存储引擎
所谓存储引擎 说白了就是如何存储数据 如何建立索引 如何更新 删除 查找数据的实现方法
2. 索引的分类
索引可以分为哪些类 分别是什么
索引可以分为
- 按数据结构分类
有B+数索引 哈希索引 full-text索引
- 按物理存储分类
聚簇索引和二级索引(辅助索引)
- 按照字段特性分类
主键索引 唯一索引 普通索引 前缀索引
- 按照字段个数分类
单例索引 联合索引
3. 从数据结构分类
从数据结构分类有 B+树索引 hash索引 full-text索引
其中innodb引擎支持B+树索引和 full-text索引
当我们创建表的时候 innodb会根据不同的场景选择不同的列作为索引
- 如果有主键 默认使用主键作为为聚簇索引的索引键
- 如果没有主键 选择第一个不包含null值的唯一列作为索引键
- 如果都没有 innodb将生成一个隐藏的自增id列作为聚簇索引的索引键
其他索引又被称为二级索引和非聚簇索引 默认的数据结构也是B+ tree
我们用下面的例子来理解B+树
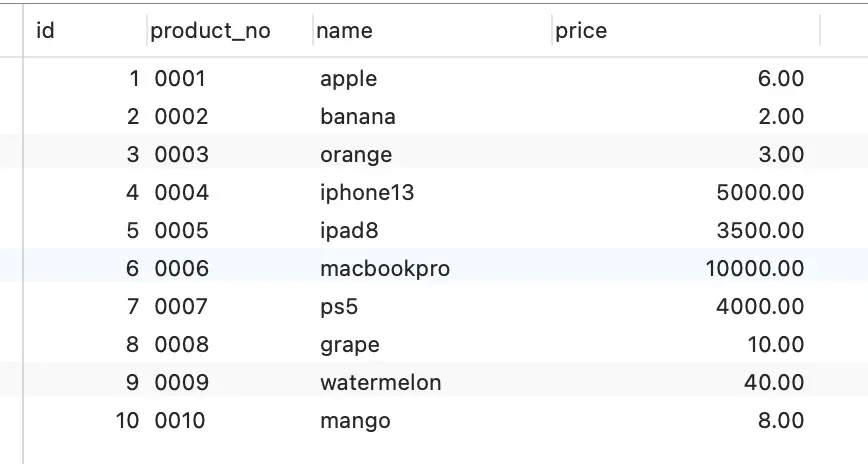
B+树是一颗多叉树 叶子节点才存放数据 非叶子节点存放索引 节点的数据是按照索引顺序存放的
每一层父节点的索引值都会出现在子节点的索引值中 因此在子节点中 包含了所有的索引值信息
并且每一个节点都有两个指针 分别指向上一个和下一个叶子节点

假如说我们执行下面的语句
select * from product where id = 5
这条sql语句使用主键索引来查询id为5的商品
查询过程中 B+树会自上而下的查找
- 将5节点和1 10 20比较 发现节点1~10之间
- 将5节点和4 7比较 发现节点在4~7之间
- 在子节点中寻找 发现5这条数据
我们发现 这里经过了三次IO
B+树存储千万级别的数据只需要3~4层的高度就可以满足 这意味着查询千万级别的表只需要3到4次IO
B+树相对B树来说 更矮更胖 所以说IO次数更小
一般来说1000万左右的数据是三层 1000万之后是四层 四层之后性能就会开始显著下降
这里的原因主要有亮点
- 到1000万数据的时候分裂成四层 多了一层io
- buffer pool瓶颈
哈希索引
innodb 不支持手动创建哈希索引 但是它通过自适应哈希索引在内部优化特定场景
它会自动检测高频访问的索引页 为其创建哈希索引
full-text索引
加速文本内容(如文章、评论、商品描述等)搜索
4. 通过二级索引查询商品数据的过程
主键索引的B+tree和二级索引的B+tree区别如下
主键索引的叶子节点里存放的是真实的数据
二级索引的叶子节点里面存放的是主键值 而不是真实的存储数据
当我们使用二级索引查询的时候 首先会查询到它的主键值
之后再进行回表查询 到主键索引中查询到相关的数据
当我们能够查询到的数据可以在辅助索引中找到的时候 就不必进行回表查询了 这就叫做覆盖索引
5. 为什么选择B+树作为索引呢?
- 和B树对比
B树非叶子节点上也有数据 所以说它是一棵更高更瘦的树 而我们需要更矮更胖的树来减少IO次数
B+树的叶子节点之间使用双向链表进行链接 适合范围查找
- 和二叉树相比
这个和B树一样 太高太瘦了
- 和hash相比
虽然说在做等值查询的时候很快 时间复杂度为O(1)但是面对范围查询的时候效率就很差了