课程9. 机器翻译,Seq2Seq与Attention
课程9. 机器翻译,Seq2Seq与Attention
- 机器翻译的任务. Seq2Seq 架构
- 通过实战理解
- 加载和预处理数据
- 构建 Seq2Seq 模型
- 编码器
- 解码器
- Seq2Seq网络
- 训练
- Seq2Seq 架构问题
- 注意力机制(Attention)
- 注意选项
- Transformer 架构介绍——BERT
课程计划
- 机器翻译的任务. Seq2Seq 架构
- 实践:机器翻译
- 注意力机制
- (可选)Transformer 架构介绍. BERT.
机器翻译的任务. Seq2Seq 架构
之前,我们考虑了一个语言建模问题,我们必须根据先前标记的使用情况预测后续标记的概率分布。
今天,我们将尝试通过预测整个标记序列而不是单个标记来概括这个问题。在这种情况下,预测序列将以某种方式与输入序列相关。具体来说,我们将考虑机器翻译的问题。
因此,机器翻译的任务是在给定一系列标记(源句)的情况下找到最可能的标记序列(翻译句):
猫 坐在地板上
( x 1 , x 2 , x 3 , x 4 x_1, \ \ \ \ \ x_2, \ \ x_3, \ x_4 x1, x2, x3, x4)
一只 猫 正坐在地板上
( y 1 , y 2 , y 3 , y 4 , y 5 y 6 y 7 y_1, y_2, y_3, \ \ y_4, \ y_5 \ y_6\ \ y_7 y1,y2,y3, y4, y5 y6 y7)
机器翻译任务:
Y ^ = a r g m a x Y P ( Y ∣ X , θ ) \widehat{Y} = argmax_{Y} P(Y|X, \theta) Y =argmaxYP(Y∣X,θ)
在这种情况下,它被描述为
P ( Y ∣ X , θ ) = P ( y 1 ∣ X , θ ) ⋅ P ( y 2 ∣ y 1 , X , θ ) ⋅ … P ( y n ∣ y n − 1 , y n − 2 , … , y 1 , X , θ ) P(Y|X, \theta) = P(y_1 | X, \theta) \cdot P(y_2 |y_1, X, \theta) \cdot \dots P(y_n | y_{n-1}, y_{n-2}, \dots, y_1, X, \theta) P(Y∣X,θ)=P(y1∣X,θ)⋅P(y2∣y1,X,θ)⋅…P(yn∣yn−1,yn−2,…,y1,X,θ)
我们看到,机器翻译问题的公式与语言建模问题的公式类似:模型也必须自回归地生成一个标记序列。不同之处在于,在机器翻译的情况下,添加了一个条件,考虑到必须生成输出序列。因此,机器翻译任务可以称为条件语言建模任务。
我们来谈谈如何使用 RNN 解决机器翻译问题。为此,让我们简要回顾一下语言建模模型的结构。
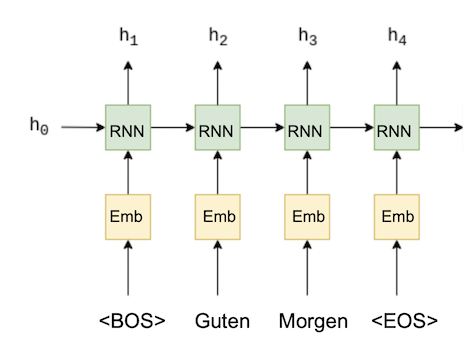
语言模型 - RNN 在每个时间时刻将一个标记作为输入,并生成下一个标记的概率分布作为输出。
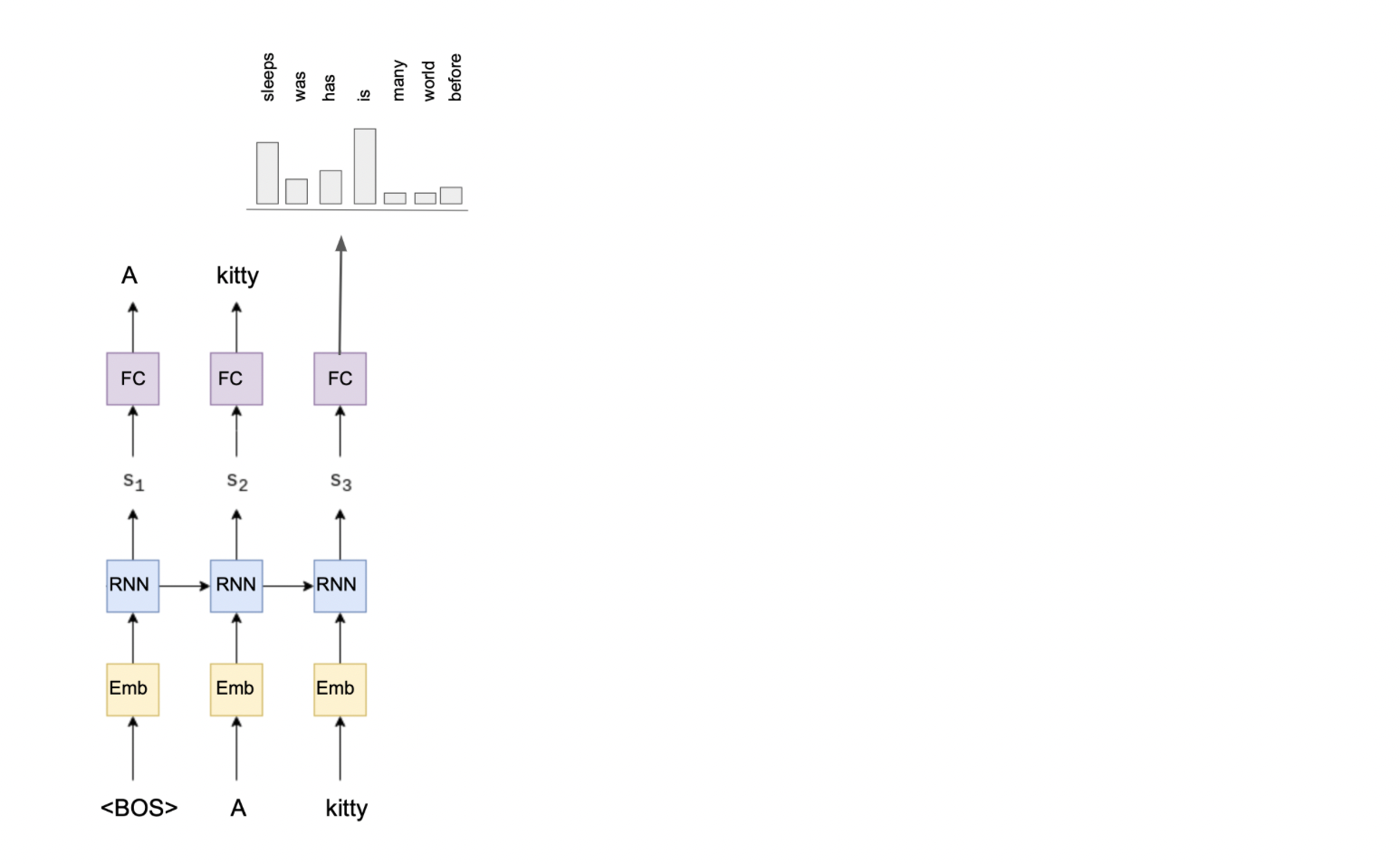
在上一课中,我们讨论了如何根据前面的标记生成文本。本质上,我们还生成了一系列标记。但随后我们考虑到这个序列是由相同语言模型生成的(因为它是相同的语言、相同的文本风格等)。
在机器翻译任务中,我们本质上有两个模型:源语言模型和目标语言模型。它们可能有所不同,因为它们可以使用不同的语言。可能存在不同的语法规则。
因此,让我们尝试为机器翻译任务建立一个 RNN 模型。它将由两部分组成:
- 编码器部分,对源句子进行逐个标记的处理。这部分将是一个 RNN 网络,其最后不会有完全连接层。
- 解码器部分,将逐个标记地生成翻译句子标记。这部分也将是一个RNN网络。它将以与语言建模网络相同的方式构建。它与实际的语言建模网络会有一个区别:隐藏状态向量不会随机设置,而是使用编码器的隐藏状态向量,该向量是在编码器处理完原句后获得的。
编码器在处理完原句之后的隐藏状态向量会包含原句的相关信息。并根据这些信息,解码器会生成翻译句子。
这种类型的模型称为序列到序列(Seq2Seq),因为它以序列作为输入并产生一个序列作为输出。
让我们看一下幻灯片,我们将在其中详细讨论该模型的工作原理。
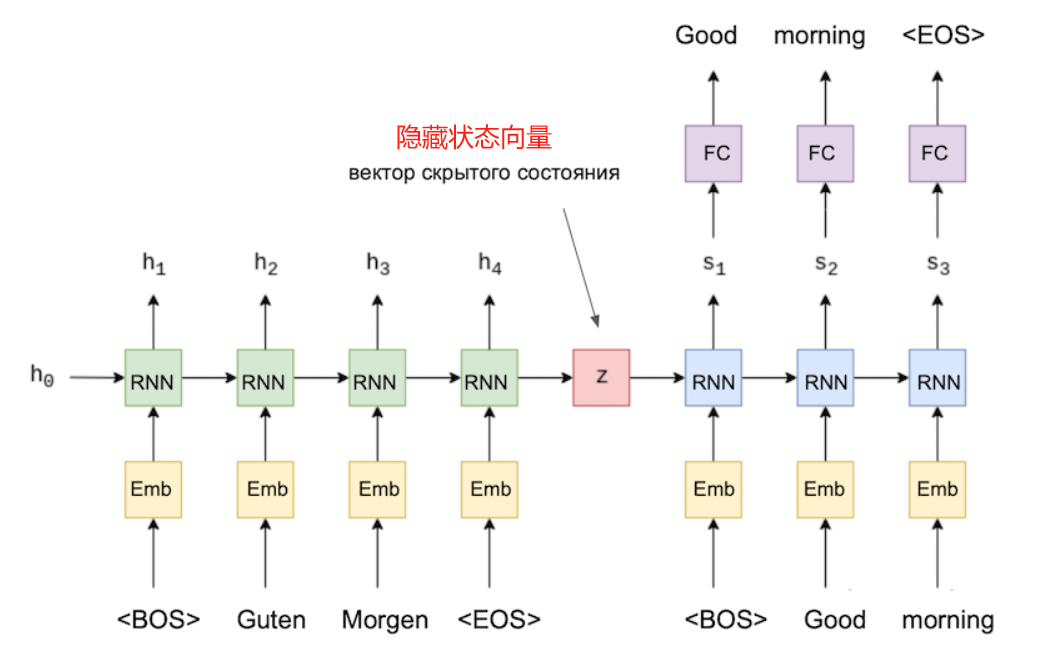
这里我们注意以下几点:假设我们有一个以这种方式训练的模型。然后可以使用该模型的编码器部分来获取句子嵌入。
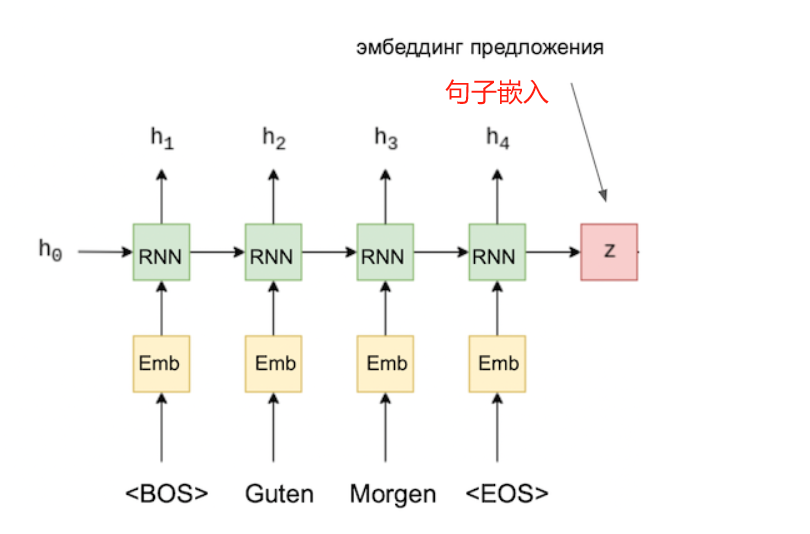
针对其他任务训练的其他模型也可用于获取对象嵌入(文本、图像等)。例如,ELMO 嵌入的思想基于训练语言模型并根据输入的文本获取其层的输出。
通过实战理解
让我们尝试解决从德语到英语的机器翻译问题。
加载和预处理数据
让我们安装必要的库:
! pip install torch==2.1.0
! pip install torchtext==0.16.0
! pip install portalocker>=2.0.0
! pip install numpy==1.25.0
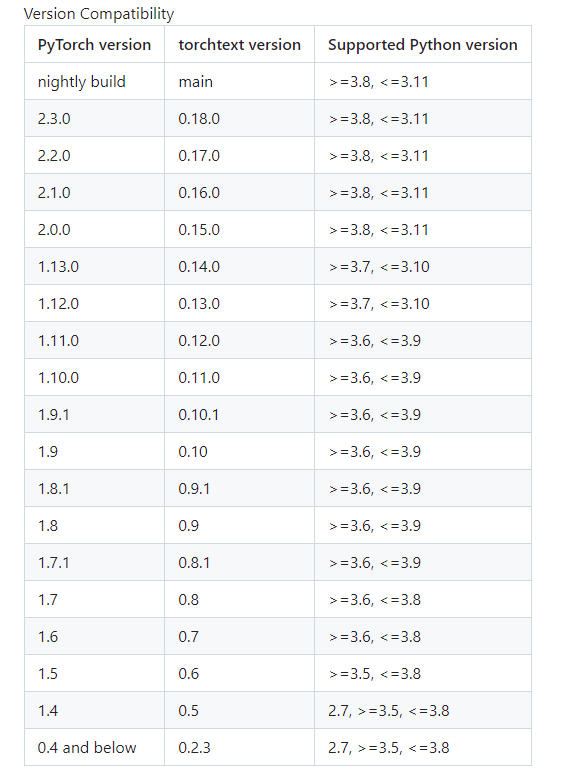
特别注意版本对应问题:
torch、python、torchdata、torchtext、numpy都要对应上才行
import torch
import torchtext
import portalocker
import torchdata
import numpy as npprint(f"NumPy version: {np.__version__}")
print(f"torch version: {torch.__version__}")
print(f"torchtext version: {torchtext.__version__}")
print(f"portalocker version: {portalocker.__version__}")
print(f"torchdata version: {torchdata.__version__}")
输出:
NumPy version: 1.25.0
torch version: 2.1.0+cu121
torchtext version: 0.16.0+cpu
portalocker version: 3.1.1
torchdata version: 0.7.0
让我们加载一个平行文本语料库。这是 Multi30k 语料库,它是一个包含约 30,000 个英语和德语平行句子的数据集。我们将解决德语到英语的机器翻译问题。
from torchtext.datasets import Multi30ktrain_iter = Multi30k(split="train")# torchtext.datasets.Multi30k 生成 IterableDataset 类的对象。
# 将其转换为简单的元素数组
train_data = list(train_iter)print(f"Amount of training data: {len(train_data)}")
print(train_data[0])
输出:
Amount of training data: 29001
(‘Zwei junge weiße Männer sind im Freien in der Nähe vieler Büsche.’, ‘Two young, White males are outside near many bushes.’)
导入标记器:
from nltk.tokenize import WordPunctTokenizertokenizer = WordPunctTokenizer()
print(tokenizer.tokenize("Good morning!"))
输出:
[‘Good’, ‘morning’, ‘!’]
我们将编写一个 tokenize 函数,用它将数据中的所有句子分解成标记:
def tokenize(sent):return tokenizer.tokenize(sent.rstrip().lower()) # 转换为小写并拆分成标记src, trg = train_data[0] # 取第一对“源语言”-“目标语言”
# 来自训练集print(tokenize(src))
print(tokenize(trg))
输出:
[‘zwei’, ‘junge’, ‘weiße’, ‘männer’, ‘sind’, ‘im’, ‘freien’, ‘in’, ‘der’, ‘nähe’, ‘vieler’, ‘büsche’, ‘.’]
[‘two’, ‘young’, ‘,’, ‘white’, ‘males’, ‘are’, ‘outside’, ‘near’, ‘many’, ‘bushes’, ‘.’]
让我们得到英语和德语的词典。为此,我们将使用 torchtext.vocab.vocab
from collections import Counterfrom torchtext.vocab import vocab as Vocabsrc_counter = Counter()
trg_counter = Counter()
for src, trg in train_data:src_counter.update(tokenize(src))trg_counter.update(tokenize(trg))src_vocab = Vocab(src_counter, min_freq=2) # 最小出现频率 - 2
trg_vocab = Vocab(trg_counter, min_freq=2)
让我们向字典中添加 4 个附加标记:
- UNK — 我们将用它来替换字典中没有的单词;
- BOS — 句子开始;
- EOS — 句子结束;
- PAD 是用于填充的标记。
unk_token, bos_token, eos_token, pad_token = "<UNK>", "<BOS>", "<EOS>", "<PAD>"for vocab in [src_vocab, trg_vocab]:vocab.insert_token(unk_token, index=0)vocab.set_default_index(0) # 我们相信<UNC>标记是默认使用的-它将用于字典中没有的新单词。for vocab in [src_vocab, trg_vocab]:for token in [bos_token, eos_token, pad_token]:if token not in vocab:vocab.append_token(token)
print(f"Unique tokens in source (de) vocabulary: {len(src_vocab)}")
print(f"Unique tokens in target (en) vocabulary: {len(trg_vocab)}")
输出:
Unique tokens in source (de) vocabulary: 7892
Unique tokens in target (en) vocabulary: 5903
我们将句子的所有预处理都合并到编码函数中。它将对产品进行标记,并向其中添加 BOS 和 EOS 实用代币。
def encode(sent, vocab): # 函数接受任何短语和与其对应的词典# 即源语言或目标语言的词典tokenized = [bos_token] + tokenize(sent) + [eos_token]return [vocab[tok] for tok in tokenized] # 返回一个标记索引序列,而不是一个短语src, trg = train_data[100]
print(encode(src, src_vocab))
print(encode(trg, trg_vocab))
输出:
[7889, 421, 422, 8, 26, 160, 199, 46, 157, 193, 55, 26, 423, 424, 13, 7890]
[5900, 434, 232, 14, 18, 163, 149, 289, 33, 111, 362, 435, 11, 5901]
剩下的就是编写一个函数,从一组句子中创建批次。我们记得,对于 RNN,一批中的所有元素必须具有相同的长度。与上一课一样,我们将修复此长度并将 PAD 标记添加到批次中的短句中。这样我们将确保每个批次包含相同长度的元素。
import torch
from torch.nn.utils.rnn import pad_sequence
from torch.utils.data import DataLoader# 该函数用于指定如何从数据集构建批次
def collate_batch(batch):# 初始化两个列表,分别用于存储源序列和目标序列src_list, trg_list = [], []# 遍历批次中的每个样本for src, trg in batch:# 使用源词汇表对源序列进行编码src_encoded = encode(src, src_vocab)# 将编码后的源序列转换为张量,并添加到源序列列表中src_list.append(torch.tensor(src_encoded))# 使用目标词汇表对目标序列进行编码trg_encoded = encode(trg, trg_vocab)# 将编码后的目标序列转换为张量,并添加到目标序列列表中trg_list.append(torch.tensor(trg_encoded))# 使用填充标记对源序列列表进行填充,使其长度一致src_padded = pad_sequence(src_list, padding_value=src_vocab[pad_token])# 使用填充标记对目标序列列表进行填充,使其长度一致trg_padded = pad_sequence(trg_list, padding_value=trg_vocab[pad_token])return src_padded, trg_padded
好吧,最后,让我们使用 collate_batch 创建一个基于 train_data 的训练 DataLoader:
batch_size = 256
train_dataloader = DataLoader(train_data, batch_size, shuffle=True, collate_fn=collate_batch)
src_batch, trg_batch = next(iter(train_dataloader))
src_batch.shape, trg_batch.shape
输出:
(torch.Size([36, 256]), torch.Size([37, 256]))
我们还将为数据的验证部分创建一个数据加载器:
val_data = list(Multi30k(split="valid"))
val_dataloader = DataLoader(val_data, batch_size, collate_fn=collate_batch)
构建 Seq2Seq 模型
现在我们将构建一个Seq2Seq模型。它由两部分组成——编码器和解码器。
编码器
编码器模型将是具有 GRU 层的单层双向 RNN。 GRU 是一个稍微修改过的 RNN 层,它可以让 RNN 记忆机制更好地工作(但仍然不是完美的)。
双向 RNN 层本质上是两层,其中一层从左到右“读取”文本,另一层从右到左“读取”。可以用如下方式来说明:
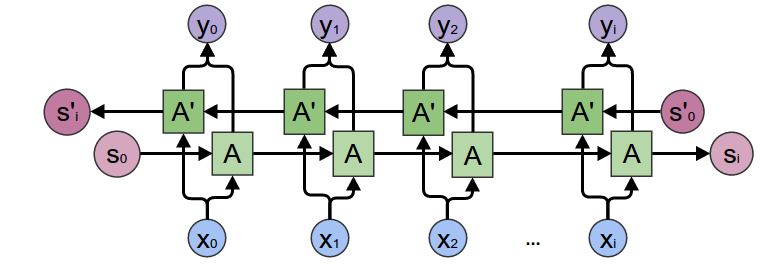
为了清楚起见,我们再次说明一下 RNN 结构:
import torch.nn as nn
import torch.nn.functional as F# 编码器,接收一批令牌索引序列作为输入,并输出隐藏状态
class Encoder(nn.Module):def __init__(self, input_dim, emb_dim, enc_hid_dim, dec_hid_dim, dropout):super().__init__()# 嵌入层self.embedding = nn.Embedding(input_dim, emb_dim)# 对嵌入层使用 dropoutself.dropout = nn.Dropout(dropout)# 单层双向 GRUself.rnn = nn.GRU(emb_dim, enc_hid_dim, bidirectional = True)# 全连接层self.fc = nn.Linear(enc_hid_dim * 2, dec_hid_dim)def forward(self, src):# 应用嵌入层和 dropoutembedded = self.dropout(self.embedding(src))# 通过 GRU 层outputs, hidden = self.rnn(embedded)# 获取 GRU 两个方向的最后隐藏状态# 每个状态的维度为 (256, 512)hidden = torch.tanh(self.fc(torch.cat((hidden[0,:,:], hidden[1,:,:]), dim = 1)))return outputs, hidden
解码器
解码器将是单层 GRU。解码器和编码器之间的主要区别在于,解码器的前向不仅接受标记作为输入,还接受来自编码器的隐藏状态作为输入。
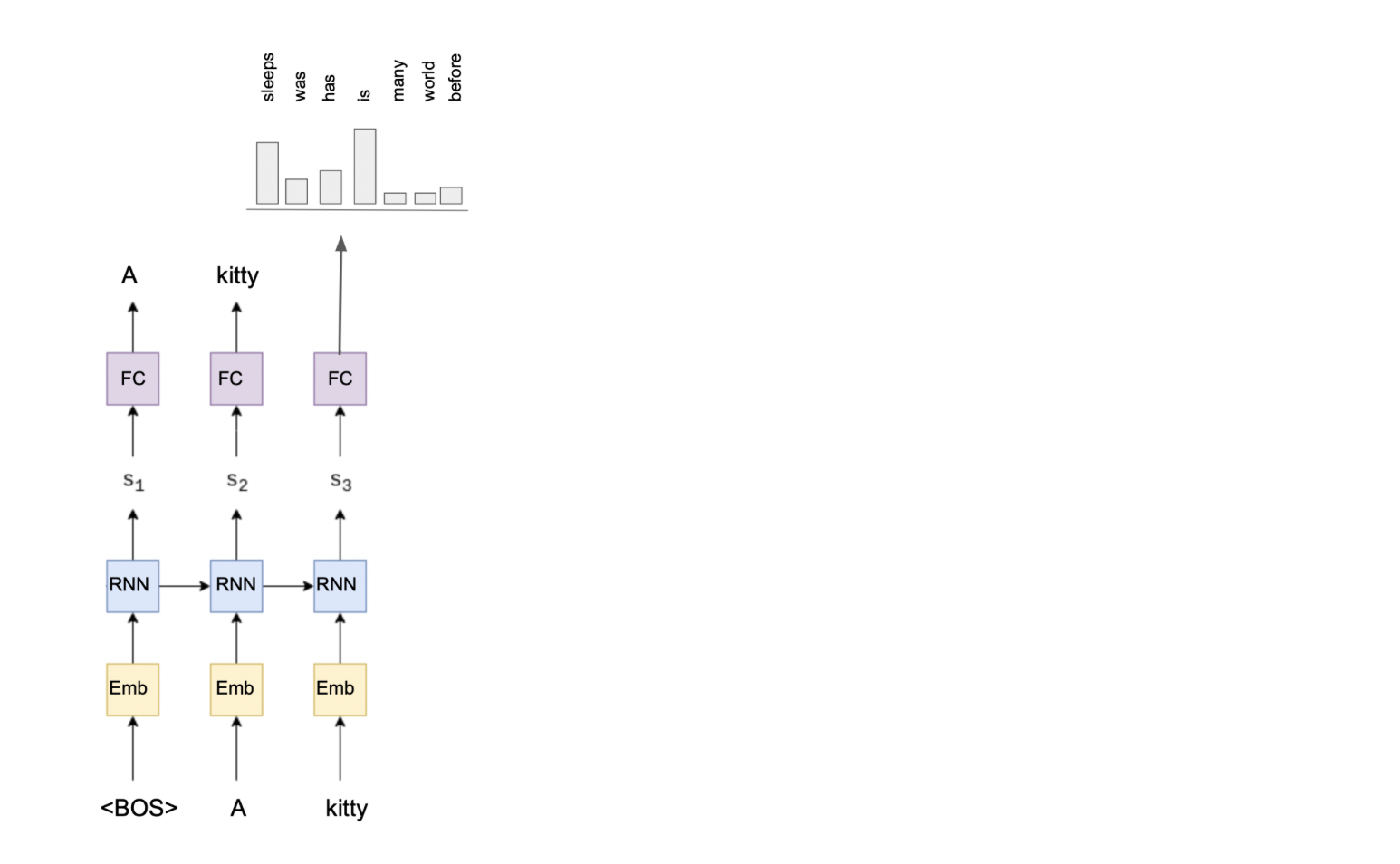
class Decoder(nn.Module):def __init__(self, output_dim, emb_dim, enc_hid_dim, dec_hid_dim, dropout):super().__init__()# 保存输出维度self.output_dim = output_dim# 解码器的嵌入层self.embedding = nn.Embedding(output_dim, emb_dim)# 对嵌入层使用 dropoutself.dropout = nn.Dropout(dropout)# 单层普通 GRUself.rnn = nn.GRU(emb_dim, dec_hid_dim)# 全连接层self.fc_out = nn.Linear(dec_hid_dim, output_dim)def forward(self, input, hidden):# 将输入从 (batch_size) 调整为 (1, batch_size)input = input.unsqueeze(0)# 经过嵌入层和 dropout 后,形状为 (1, batch_size, emb_dim)embedded = self.dropout(self.embedding(input))# 通过 GRU 层,输入嵌入后的张量和隐藏状态(添加一维)output, hidden = self.rnn(embedded, hidden.unsqueeze(0))# 将 output 从 (1, batch_size, emb_dim) 调整为 (batch_size, emb_dim)output = output.squeeze(0)# 通过全连接层得到预测结果prediction = self.fc_out(output)# 返回下一个令牌的概率预测以及当前步骤的隐藏状态return prediction, hidden.squeeze(0)
Seq2Seq网络
最后,我们将编码器和解码器组装成一个大的 Seq2Seq 网络:
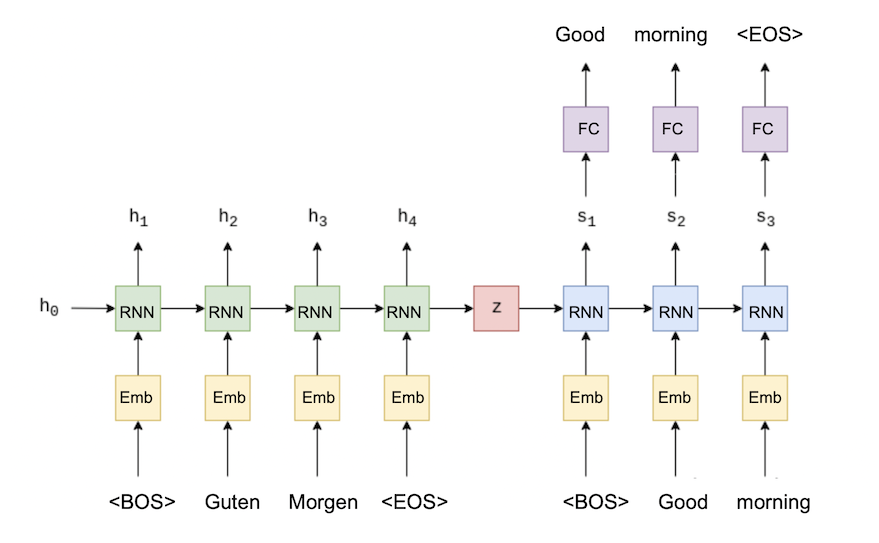
import randomclass Seq2Seq(nn.Module):def __init__(self, encoder, decoder, device):super().__init__()# 编码器self.encoder = encoder# 解码器self.decoder = decoder# 设备(如 CPU 或 GPU)self.device = devicedef forward(self, src, trg, teacher_forcing_ratio = 0.5):# 获取输入批次的大小batch_size = src.shape[1]# 获取目标序列的长度trg_len = trg.shape[0]# 获取目标词汇表的大小trg_vocab_size = self.decoder.output_dim# 创建一个用于存储解码器输出的零张量,形状为 (trg_len, batch_size, trg_vocab_size)outputs = torch.zeros(trg_len, batch_size, trg_vocab_size).to(self.device)# 调用编码器,得到编码器的输出和隐藏状态encoder_outputs, hidden = self.encoder(src)# 将目标序列的第一个标记(通常是 <bos> 开始标记)作为解码器的初始输入input = trg[0, :]# 遍历目标序列,从第二个标记开始for t in range(1, trg_len):# 将输入和之前的隐藏状态传入解码器,得到当前步骤的输出和新的隐藏状态output, hidden = self.decoder(input, hidden)# 将当前步骤的输出存储到 outputs 张量中outputs[t] = output# 决定是否使用教师强制(teacher forcing)# teacher_force = random.random() < teacher_forcing_ratio# 获取当前步骤输出中概率最大的标记的索引top1 = output.argmax(1)# 准备下一次迭代的输入# 如果使用教师强制,则使用目标序列中的下一个标记作为输入;否则,使用当前步骤预测的标记input = trg[t] # if teacher_force else top1# 返回解码器的所有输出return outputs
我们启动Encoder、Decoder和Seq2Seq模型:
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")# 创建编码器
enc = Encoder(len(src_vocab), emb_dim=256, enc_hid_dim=512, dec_hid_dim=512, dropout=0.5).to(device)
# 创建解码器
dec = Decoder(len(trg_vocab), emb_dim=256, enc_hid_dim=512, dec_hid_dim=512, dropout=0.5).to(device)
# 创建 Seq2Seq 模型
model = Seq2Seq(enc, dec, device=device)
optimizer = torch.optim.Adam(model.parameters())
# 损失不会在填充标记上计算
criterion = nn.CrossEntropyLoss(ignore_index=trg_vocab[pad_token])
训练
我们训练模型:
from torch.nn.utils import clip_grad_norm_
from tqdm.auto import tqdm, trange# 训练的总轮数
n_epochs = 10
# 梯度裁剪的阈值
clip = 1
# 开始训练的轮次循环
for epoch in trange(n_epochs, desc="Epochs"):# 将模型设置为训练模式model.train()# 初始化训练损失为 0train_loss = 0# 遍历训练数据集for src, trg in tqdm(train_dataloader, desc="Train", leave=False):# 将源序列和目标序列移动到指定设备(如 GPU)上src, trg = src.to(device), trg.to(device)# 将源序列和目标序列输入模型,得到模型的输出# 对于目标序列的每个前缀,模型会预测下一个标记output = model(src, trg)# 去掉输出和目标序列中的第一个元素(通常是 <bos> 开始标记),用于损失计算output = output[1:].view(-1, output.shape[-1])trg = trg[1:].view(-1)# 计算损失loss = criterion(output, trg)# 反向传播,计算梯度loss.backward()# 对模型的参数进行梯度裁剪,防止梯度爆炸clip_grad_norm_(model.parameters(), clip)# 根据计算得到的梯度更新模型的参数optimizer.step()# 清空梯度,为下一次迭代做准备optimizer.zero_grad()# 累加当前批次的损失到总训练损失中train_loss += loss.item()# 计算平均训练损失train_loss /= len(train_dataloader)# 打印当前轮次的训练损失print(f"Epoch {epoch} train loss = {train_loss} ")# 将模型设置为评估模式model.eval()# 初始化验证损失为 0val_loss = 0# 不计算梯度,减少内存消耗,提高推理速度with torch.no_grad():# 遍历验证数据集for src, trg in tqdm(val_dataloader, desc="Val", leave=False):# 将源序列和目标序列移动到指定设备上src, trg = src.to(device), trg.to(device)# 将源序列和目标序列输入模型,得到模型的输出output = model(src, trg)# 去掉输出和目标序列中的第一个元素,用于损失计算output = output[1:].view(-1, output.shape[-1])trg = trg[1:].view(-1)# 计算损失loss = criterion(output, trg)# 累加当前批次的损失到总验证损失中val_loss += loss.item()# 计算平均验证损失val_loss /= len(val_dataloader)# 打印当前轮次的验证损失print(f"Epoch {epoch} val loss = {val_loss} ")
输出:
# 获取目标词汇表的索引到词的映射列表
trg_itos = trg_vocab.get_itos()
# 将模型设置为评估模式
model.eval()
# 生成的最大长度
max_len = 50# 不计算梯度,以提高推理速度并减少内存消耗
with torch.no_grad():# 遍历验证数据集中的前 10 个样本for src, trg in val_data[:10]:# 对源句子进行编码,将其转换为词汇表中的索引序列encoded = encode(src, src_vocab)# 将编码后的序列转换为 PyTorch 张量,并添加一个维度以模拟批量输入encoded = torch.tensor(encoded)[:, None].to(device)# 将源句子通过模型的编码器,得到编码器的输出和隐藏状态encoder_outputs, hidden = model.encoder(encoded)# 设置第一个预测的标记为起始标记(bos)pred_tokens = [trg_vocab[bos_token]]# 循环生成翻译后的句子,一次生成一个标记for _ in range(max_len):# 将上一个预测的标记作为当前解码器的输入decoder_input = torch.tensor([pred_tokens[-1]]).to(device)# 将输入和隐藏状态传入解码器,得到预测结果和新的隐藏状态pred, hidden = model.decoder(decoder_input, hidden)# 获取预测结果中概率最大的标记的索引_, pred_token = pred.max(dim=1)# 如果预测的标记是结束标记(eos),则停止生成if pred_token == trg_vocab[eos_token]:# 为了输出更简洁,不将结束标记添加到预测结果中break# 将预测的标记添加到预测标记列表中pred_tokens.append(pred_token.item())# 打印源句子,转换为小写并去除右侧的空白字符print(f"src: '{src.rstrip().lower()}'")# 打印目标句子,转换为小写并去除右侧的空白字符print(f"trg: '{trg.rstrip().lower()}'")# 打印预测的句子,将预测标记列表中的索引转换为对应的单词print(f"pred: '{' '.join(trg_itos[i] for i in pred_tokens[1:])}'")print()
输出:

Seq2Seq 架构问题
上述机器翻译的网络架构是2014-2015年的标准。然而,当时它的质量不如统计(基于短语的)翻译模型。这主要是由于该架构存在的一个问题:有关原始句子的所有信息都由 RNN 层学习,并最终包含在单个向量 z 中。
为什么这是一个问题:
- RNN 容易被“遗忘”。尽管 RNN 具有“记忆”机制,但随着时间的推移,这种记忆中的信息会被抹去。即使更强大的 LSTM 仍然无法正确处理非常大的序列(此外,处理大序列需要花费大量时间);
- 不同长度的句子由相同的机制处理。即使最长的句子的所有信息都被收集在一个隐藏状态向量 z 中。事实证明,可以传输到解码器的信息量受到向量 z 的体积的限制。
- 在解码过程中,解码器在每一步都会根据其隐藏状态向量生成一个新的标记。在解码过程中,这个隐藏状态向量会丢失来自编码器的信息,最终生成的标记可能与原始句子关系不大。
长期以来,研究人员一直在试图找出如何克服这一限制。人们发明了许多方法来提高质量,但问题并未得到彻底解决。而在2015年,注意力机制的思想被提出,使得克服这个问题成为可能。现在我们来见见他。
注意力机制(Attention)
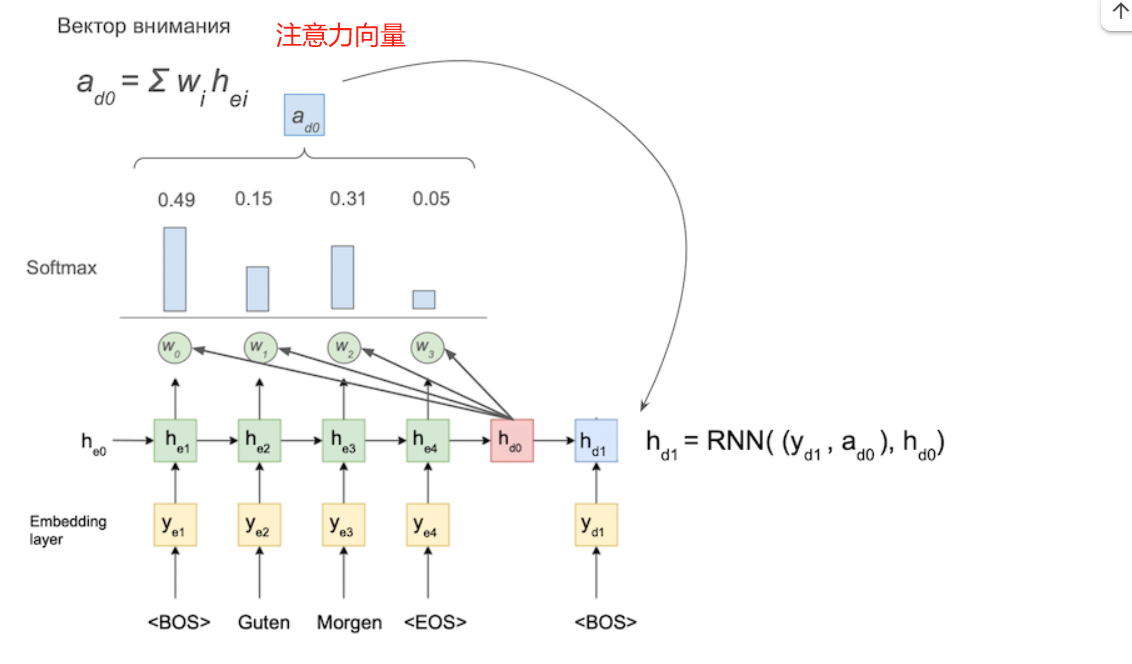
我们来看一下演示文稿,详细讨论注意力机制。
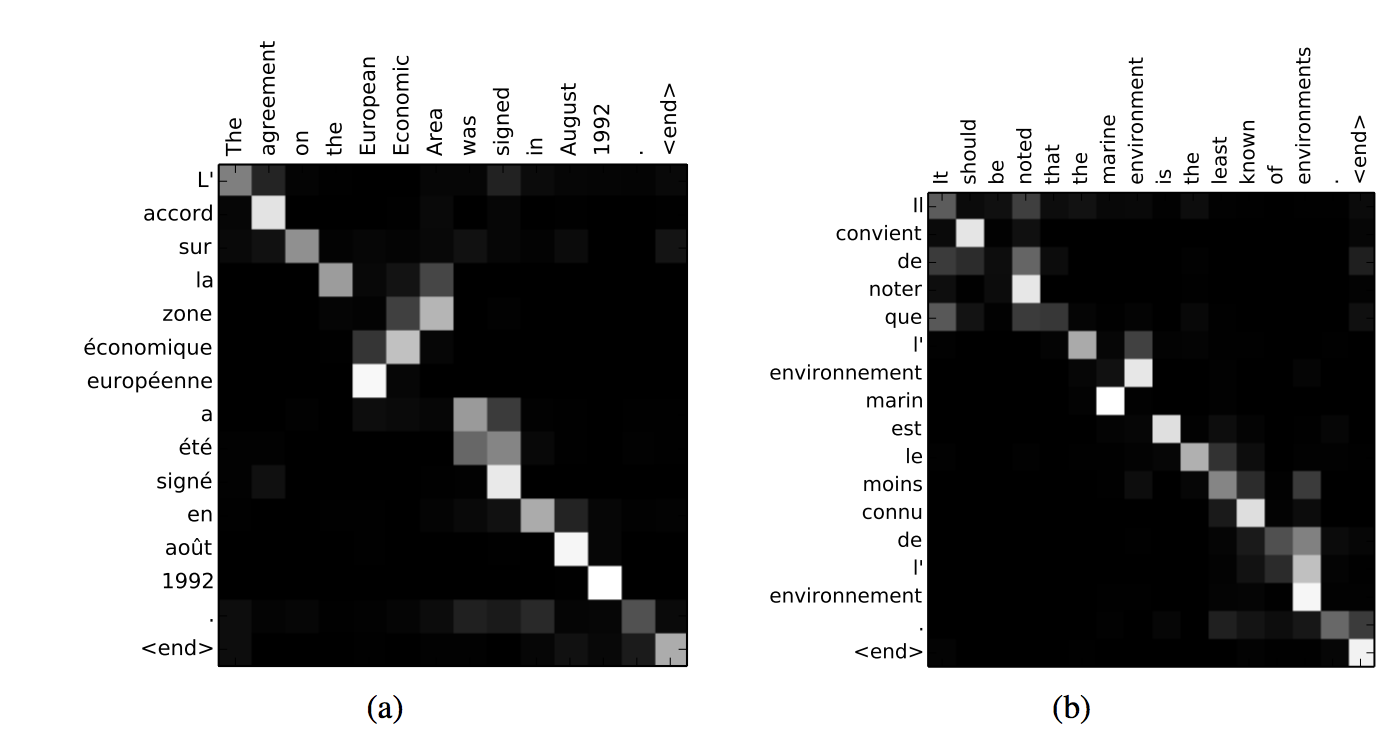
注意力机制让我们能够解读模型的工作:
注意选项
令 h e 1 , . . . , h e N h_{e1},...,h_{eN} he1,...,heN 为编码器的隐藏状态, h d t h_{dt} hdt 为解码器在时间 t t t 的状态。
那么时刻 t t t的注意力向量(注意力分数) a d t a_{dt} adt可以表示如下:
a d t = [ a i , t , . . . , a N , t ] a_{dt} = [a_{i,t},...,a_{N, t}] adt=[ai,t,...,aN,t].
其中每个 a i , t = f ( h e i , h d t ) a_{i, t}=f(h_{ei}, h{dt}) ai,t=f(hei,hdt)。
那些。为了计算每个当前时刻 t t t的注意力向量,需要针对编码器的每个状态和解码器的当前状态计算某个注意力函数(Attention)的值。
要计算Attention值,可以使用不同的操作(不同的函数f)。让我们看看最受欢迎的功能。
1.点积注意力机制。这是最经典的Attention类型,在大多数解决方案中都会用到。它被计算为标量积:
f ( h e i , h d t ) = h d t T h e i f(h_{ei}, h{dt}) = h_{dt}^Th_{ei} f(hei,hdt)=hdtThei
2.乘法注意力。这里我们添加一些固定的中间权重矩阵 W W W:
f ( h e i , h d t ) = h d t T ∗ W ∗ h e i f(h_{ei}, h{dt}) = h_{dt}^T*W*h_{ei} f(hei,hdt)=hdtT∗W∗hei
- 附加注意力。在这里,我们通过使用具有某些激活函数(例如双曲正切)的完全连接层的某些类似物来进一步使计算复杂化,将编码器和解码器的隐藏状态向量的某些线性组合作为输入。我们将结果乘以某个权重向量 v v v:
f ( h e i , h d t ) = v T ∗ t a n h ( W 1 ∗ h e i + W 2 ∗ h d t ) f(h_{ei}, h{dt}) = v^T*tanh(W_1*h_{ei}+W_2*h_{dt}) f(hei,hdt)=vT∗tanh(W1∗hei+W2∗hdt)
通常,点积被用作注意函数,因为这种运算在计算速度方面非常高效。加法和乘法注意力是这种方法的概括,允许在计算注意力时考虑每个状态的一些权重(这就是辅助矩阵 W W W、 W 1 W_1 W1 和 W 2 W_2 W2 的用途)。
Transformer 架构介绍——BERT
上面讨论的注意力机制是目前大多数现代解决方案(ChatGPT、BERT 等)中使用的强大 Transformer 模型中的关键工具。
在这些架构中,除了机制之外,还使用了一些附加特征(例如,对于每个标记,除了其向量表示之外,还考虑标记的序数)。但我们不会详细讨论这一点。
我们只想说,这样的架构使我们能够有效地解决已经考虑的问题,例如文本分类问题。
例如,BERT(来自 Transformer 的双向编码器表示)架构基于以下假设:
- 这是一个利用Attention机制的语言模型。
- 在训练过程中,解决了一个 masked 语言建模问题(首先根据所有前面的 token 预测某个 token 的概率——正向语言建模,然后根据所有后续单词计算某个 token 的概率——反向语言建模的任务,然后根据这些概率基于整个上下文计算出最终某个 token 的概率)。
- 对于分类任务,使用特殊标记 <CLF>,该标记添加到句子的开头。因此,在预测这个标记的过程中,我们得到了模型的隐藏状态向量,该向量考虑了原始句子中的所有标记。正是这个标记可以作为整个文本的向量表示,以解决文本数据分析问题(分类、回归等)。
- 因此,作为文本的向量表示,我们可以使用 <CLF> 标记的向量表示,它将包含有关原始文本的所有信息。这意味着我们可以将这个向量输入到一个简单的分类算法中。
正如你所看到的,注意力机制是一个相当复杂的过程。需要计算编码器和解码器所有隐藏状态对的注意力值。因此,就训练时间而言,Transformer 是一种相当昂贵的架构。因此,通常使用预先训练的模型。
特别是,有一个库“transformers”,它已经包含各种预先训练的模型,包括各种 BERT。