KafkaSpark-Streaming
kafka与其他组件的整合
Kafka 生产者 生成数据并采集
使用kafka作为消费者从bloom中获取数据,并将数据打印到控制台或传入HDFS。
Kafka 消费者 获取数据
Kafka 有两种分配策略,一是 RoundRobin(轮询),一是 Range。
Range是Kafka默认的分区分配策略。它是面向主题分配的。将分区按照几等份分配给一个消费组内订阅了该主题的消费者。缺点是会导致消费者消费数据的不均匀。
当消费者的个数发生变化的时候就会触发分区分配策略。
ACKS机制
对于某些不太重要的数据,对数据的可靠性要求不是很高,能够容忍数据的少量丢失,
所以没必要等 ISR 中的 follower 全部接收成功。所以 Kafka 为用户提供了三种可靠性级别,用户根据对可靠性和延迟的要求进行权衡,选择以下的配置。
acks 参数配置:
0:producer 不等待 broker 的 ack,这一操作提供了一个最低的延迟,broker 一接收到还没有写入磁盘就已经返回,当 broker 故障时有可能丢失数据;
1:producer 等待 broker 的 ack,partition 的 leader 落盘成功后返回 ack,如果在 follower同步成功之前 leader 故障,那么将会丢失数据;
-1(all):producer 等待 broker 的 ack,partition 的 leader 和 follower 全部落盘成功后才返回 ack。但是如果在 follower 同步完成后,broker 发送 ack 之前,leader 发生故障,那么会造成数据重复。
Spark-Streaming
无状态转化操作
无状态转化操作就是把简单的 RDD 转化操作应用到每个批次上,也就是转化 DStream 中的每一个 RDD。部分无状态转化操作列在了下表中。
注意,针对键值对的 DStream 转化操作(比如reduceByKey())要添加import StreamingContext._才能在 Scala 中使用。

需要记住的是,尽管这些函数看起来像作用在整个流上一样,但事实上每个 DStream 在内部是由许多 RDD(批次)组成,且无状态转化操作是分别应用到每个 RDD 上的。
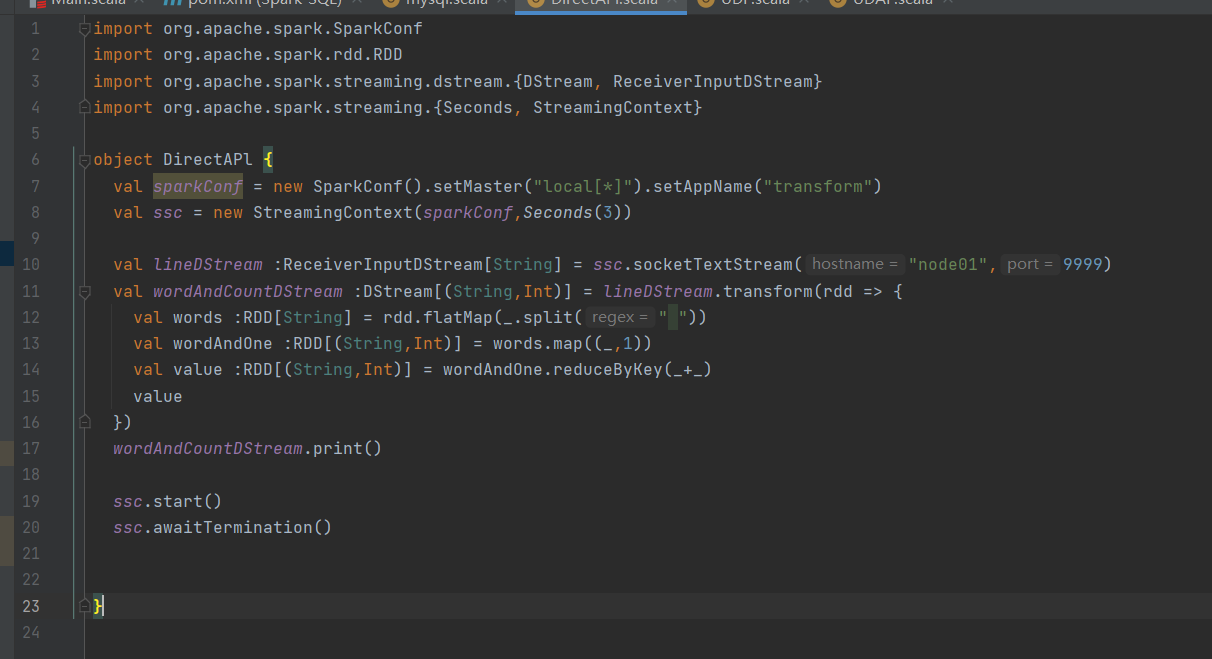
Transform
Transform 允许 DStream 上执行任意的 RDD-to-RDD 函数。即使这些函数并没有在 DStream的 API 中暴露出来,通过该函数可以方便的扩展 Spark API。该函数每一批次调度一次。其实也就是对 DStream 中的 RDD 应用转换。

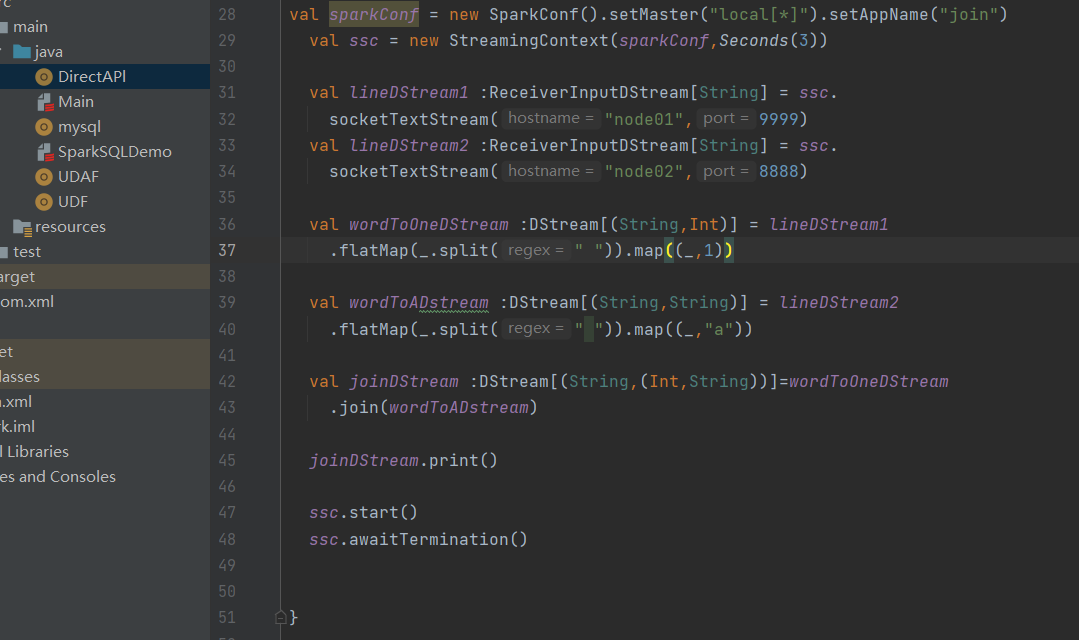
join
两个流之间的 join 需要两个流的批次大小一致,这样才能做到同时触发计算。计算过程就是对当前批次的两个流中各自的 RDD 进行 join,与两个 RDD 的 join 效果相同。