深度学习--自然语言处理统计语言与神经语言模型
文章目录
- 前言
- 一、语言转换方法
- 1、数据预处理
- 2、特征提取
- 3、模型输入
- 4、模型推理
- 二、语言模型
- 1、统计语言模型
- 1) 机器学习词向量转换
- 2)解释:
- 3) 统计语言模型存在的问题
- 2、神经语言模型
- 1)one—hot编码
- 2)解决维度灾难
- 3) 词嵌入embedding
- 4)word2vec训练词向量的模型
- (1)CBOW
- (2)SkipGram
- (3) CBOW模型训练过程
- 应用
前言
传统的语言模型是基于词袋模型(Bag-of-Words)和one-hot编码展开工作的,即在传统的语言模型中要生成一个句子,其实是拿一堆词语进行拼凑,拼凑出一个句子后我们需要有一个评委来对这个机器生成的句子进行打分和评价,语言模型就是这么一位评委,它会给每个句子打出一个概率值,以表明他们与人类语言的接近程度。
一、语言转换方法
如何将语言转换为模型可以直接识别的内容
1、数据预处理
- 首先,需要对原始语言数据进行预处理。这包括分词、去除停用词 等操作,以便将语言数据转换成可以被模型处理的形式。
2、特征提取
- 在将语言转换为模型可识别的内容之前,需要将语言数据转换为数值特征。常见的特征提取方法包括TF-IDF、词嵌入(如Word2Vec、GloVe)等。这些方法可以将文本中的单词或短语转换为向量表示,便于输入到模型中进行处理。
3、模型输入
- 将特征转换为模型可以接受的输入形式。具体形式取决于所使用的模型类型。例如,对于神经网络模型,可以通过将特征表示为张量或矩阵的形式来输入模型。
4、模型推理
- 将输入的特征数据输入到训练好的模型中进行推理或者生成。根据任务的不同,可以使用不同的模型,如分类模型、序列生成模型等。
二、语言模型
语言模型分为两种
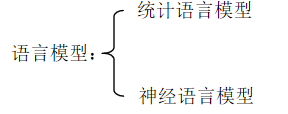
1、统计语言模型
统计语言模型通过概率分布的形式来描述任意语句(字符串)s属于某种语言集合的可能性。给定一个句子W(由多个单词w1, w2, w3,…组成),统计语言模型的目标是计算该句子在文本中出现的概率P(W),即P(W) = P(w1, w2, w3,…, wn)。这一概率的计算通常基于统计学方法,如最大熵模型、N-gram模型等。
1) 机器学习词向量转换
之前机器学习中使用词向量转换的方法,将单词表示为向量的技术,能够捕捉单词之间的语义和语法关系。
案例:
有以下4段文本字符串,可将其当做四个文本文档,将其转化为数值类型特征矩阵
text = [’ dog cat fish ’ , ’ dog cat cat ’ , ’ fish bird ’ , ’ bird ’ ]
对这四个文档进行分词,然后转化为数值类型,代码如下:
from sklearn.feature_extraction.text import CountVectorizer # 导入库将文本集合转换为词频矩阵texts = ['dog cat fish','dog cat cat','fish bird','bird'] # 随机建立个数据,每个文本字符串代表一个文档
cont = []
cv = CountVectorizer(max_features=6,ngram_range=(1,2)) # 建立一个模型,参数为最大特征数,转换后的特征矩阵将最多包含6列,以及词前后拼接长度范围
cv_fit = cv.fit_transform(texts) # 训练数据,返回一个稀疏矩阵
print(cv_fit) # 打印稀疏矩阵
print(cv.get_feature_names_out()) # 打印所有特征值
print(cv_fit.toarray()) # 将稀疏矩阵转变为矩阵类型
运行结果如下:
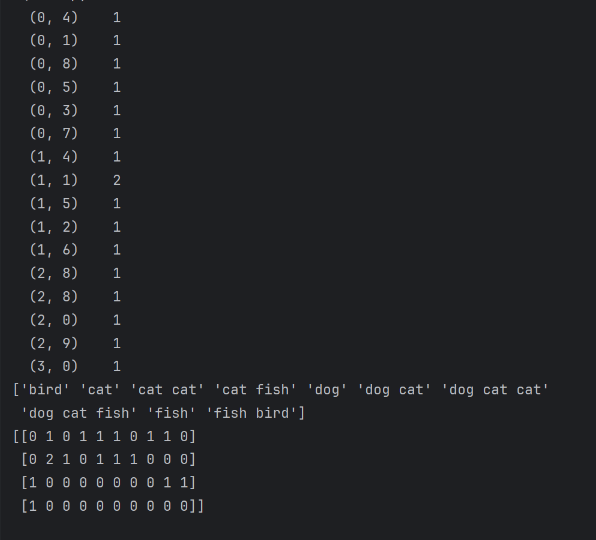
2)解释:
稀疏矩阵

代码通过创建模型将转换后的特征矩阵最多包含6列,以及词前后拼接长度范围为(1,2)
拿图中的“(0,3) 1” 举例:
- "0"是texts列表中的"dog cat fish"文档
- “3"是分词后结果中的第四个词"dog”
- "1"是dog在texts列表中出现的次数
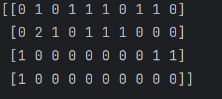
- 此图其中每一行代表一篇文章,每一列代表是否有总分词库中的词,由此来形成矩阵。
3) 统计语言模型存在的问题
- 由于参数空间的爆炸式增长,它无法处理(N>3)的数据。
- 没有考虑词与词之间内在的联系性。例如,考虑"the cat is walking in the bedroom"这句话。如果我们在训练语料中看到了很多类似“the dog is walking in the bedroom”或是“the cat is running in the bedroom”这样的句子;那么,哪怕我们此前没有见过这句话"the cat is walking in the bedroom",也可以从“cat”和“dog”(“walking”和“running”)之间的相似性,推测出这句话的概率。
2、神经语言模型
神经语言模型可以通过训练大量的文本数据,学习出单词之间的语义和上下文关系。在训练过程中,模型会根据已经观察到的文本序列,通过优化方法调整模型参数,使得模型能更准确地预测下一个词或句子。
1)one—hot编码
在处理自然语言时,通常将词语或者字做向量化,例如one-hot编码,例如我们有一句话为:“我爱北京天安门”,我们分词后对其进行one-hot编码,结果可以是:
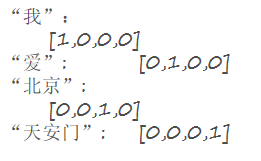
- 即文章的第一个词表示为词库索引的第一个词,将其表示为1,其余词表示为0,第二个词表示为第二个特征为1,其余特征为0,以此类推。
- 假如此时有一篇文章有很多很多个词,将其分词后的得到的词库有1000个单词(不重复),那么按照上述独热编码的方式,将这这篇文章转变为向量格式,然后则会有第一个词表示为000…0001,第二个词表示为000…0010,每个词表示的有999个0和1个1,每一行代表一个单词的特征,列数表示词库中词的个数,行数表示文档内词的个数,此时则会出现矩阵为非常稀疏,出现维度灾难,例如将上述文档“我爱北京天安门”以独热编码的格式表达,假设此时语料库中有4960个词,那么将这个文档表达后的形式为下列所示:
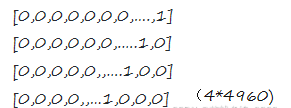
2)解决维度灾难

- 通过神经网络训练,将每个词都映射到一个较短的词向量上来,这个较短的词向量维度是多大呢? 一般需要在训练时自己来指定。现在很常见的例如300维。
3) 词嵌入embedding
词向量的意思是将自然语言转换为向量的过程,那么词嵌入就是神经语言模型中的一种词向量转换的一种方法。
将高维度的词向量转换为低维度的词向量表示的方法,我们称之为词嵌入。
4)word2vec训练词向量的模型

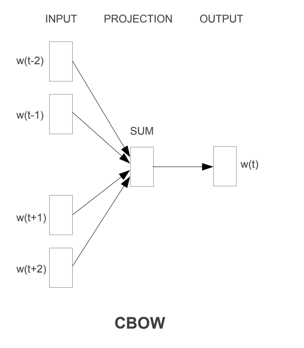
(1)CBOW
- 目标是在给定上下文(周围词)的情况下预测中心词。
- 例如,在句子“我喜欢学习”中,如果上下文是“我”和“学习”,模型的目标是预测“喜欢”。
- 即输入“我”和“学习”的独热编码,预测“喜欢”的独热编码
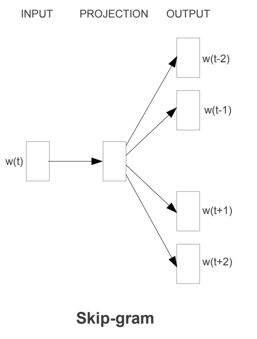
(2)SkipGram
- SkipGram跟CBOW恰恰相反
- 以当前词预测其上下文词汇,即当前词预测前后两个单词,这里的两个单词也是自定义个数的
(3) CBOW模型训练过程
1、当前词的上下文词语的one-hot编码输入到输入层。
2、这些词分别乘以同一个矩阵W(VN)后分别得到各自的1N 向量。
3、将多个这些1N 向量取平均为一个1N 向量。
4、将这个1N 向量乘矩阵 W’(NV) ,变成一个1*V 向量。
5、将1V 向量softmax归一化后输出取每个词的概率向量1V
6、将概率值最大的数对应的词作为预测词。
7、将预测的结果1V 向量和真实标签1V 向量(真实标签中的V个值中有一个是1,其他是0)计算误差。
8、在每次前向传播之后反向传播误差,不断调整 W(VN)和 W’(VN)矩阵的值。
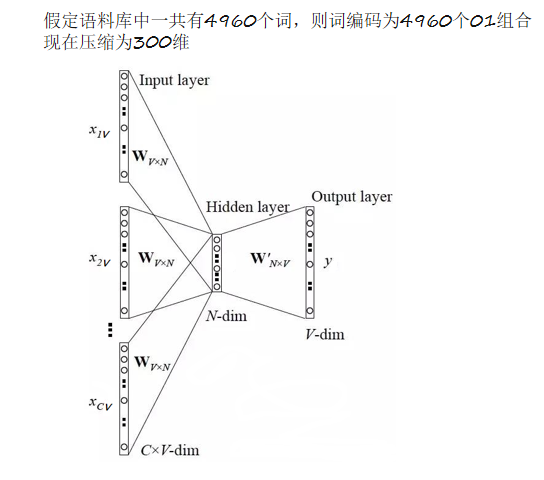
拿一个词语为4960个的语料库来举例,使用CBOW模型完成词嵌入:

-
假设选取上下各选两个词语,输入层每一个神经元接收一个词语的独热编码,然后将其乘以第一个权重w1(4960 *300)的矩阵,将结果(1 * 300)的矩阵传入中间层。
-
中间层将输入层传入的四个结果组合成一个(4 * 300)的矩阵,然后再对每一列进行求和得到(1 * 300)的矩阵,将该矩阵传入输出层。
-
输出层接收到中间层传入的(1 * 300)的矩阵,将其乘以第二个权重w2(300 * 4960)的矩阵,得到(1 *
4960)的矩阵,每一列就是每个词语的预测结果。 -
对矩阵进行归一化,得到的每一列都是一个词语的概率值。
-
概率值最大的即为预测词。
-
然后将该词的预测结果与真实标签进行误差计算。
-
在每次向前传播之后反向传播误差,不断调整w1和w2的值。
应用
CBOW模型生成的词向量可以用于各种自然语言处理任务,如文本分类、情感分析、机器翻译、问答系统等。词向量可以作为这些任务的输入特征,提高模型的性能和泛化能力。