BitNet: 微软开源的 1-bit 大模型推理框架
GitHub:https://github.com/microsoft/BitNet
更多AI开源软件:发现分享好用的AI工具、AI开源软件、AI模型、AI变现 - 小众AI
微软专为 CPU 本地推理和极致压缩(低比特)大模型设计的推理框架。它支持对 1-bit/1.58-bit 量化模型进行高效、低能耗的推理,兼容 BitNet、Llama3-8B-1.58、Falcon3 等模型,适用于在本地或边缘设备上运行大模型推理任务,无需 GPU。

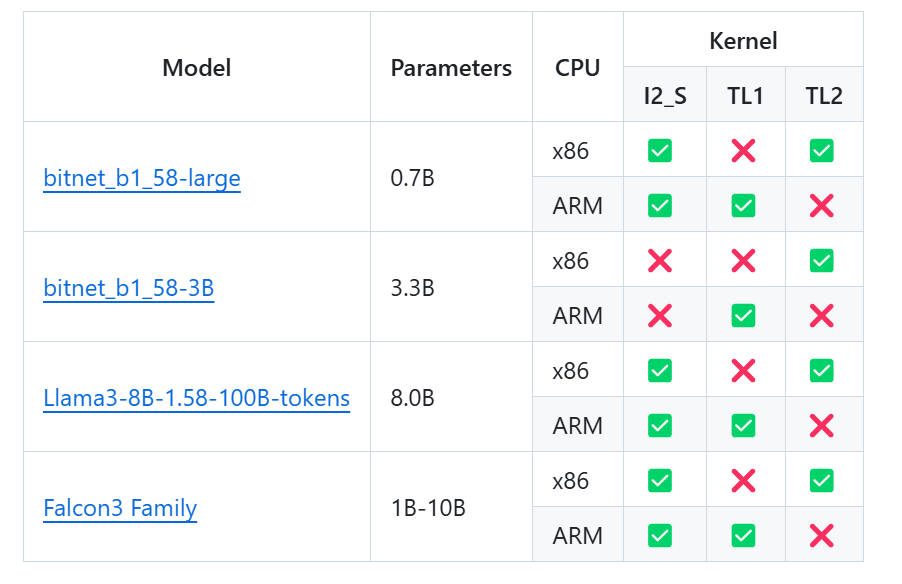
模型支持
安装
要求
-
python>=3.9
-
cmake>=3.22
-
clang>=18
-
对于 Windows 用户,请安装 Visual Studio 2022。在安装程序中,至少打开以下选项(这也会自动安装所需的附加工具,如 CMake):
- 使用 C++ 进行桌面开发
- 适用于 Windows 的 C++-CMake 工具
- 适用于 Windows 的 Git
- 适用于 Windows 的 C++-Clang 编译器
- LLVM 工具集 (clang) 的 MS-Build 支持
-
对于 Debian/Ubuntu 用户,您可以使用自动安装脚本下载
bash -c "$(wget -O - https://apt.llvm.org/llvm.sh)"
-
-
conda (强烈推荐)
从源构建
重要
如果您使用的是 Windows,请记住始终使用 VS2022 的开发人员命令提示符/PowerShell 来执行以下命令。如果您发现任何问题,请参阅下面的常见问题解答。
- 克隆存储库
git clone --recursive https://github.com/microsoft/BitNet.git
cd BitNet
- 安装依赖项
# (Recommended) Create a new conda environment
conda create -n bitnet-cpp python=3.9
conda activate bitnet-cpppip install -r requirements.txt
- 生成项目
# Manually download the model and run with local path
huggingface-cli download microsoft/BitNet-b1.58-2B-4T-gguf --local-dir models/BitNet-b1.58-2B-4T
python setup_env.py -md models/BitNet-b1.58-2B-4T -q i2_s
usage: setup_env.py [-h] [--hf-repo {1bitLLM/bitnet_b1_58-large,1bitLLM/bitnet_b1_58-3B,HF1BitLLM/Llama3-8B-1.58-100B-tokens,tiiuae/Falcon3-1B-Instruct-1.58bit,tiiuae/Falcon3-3B-Instruct-1.58bit,tiiuae/Falcon3-7B-Instruct-1.58bit,tiiuae/Falcon3-10B-Instruct-1.58bit}] [--model-dir MODEL_DIR] [--log-dir LOG_DIR] [--quant-type {i2_s,tl1}] [--quant-embd][--use-pretuned]Setup the environment for running inferenceoptional arguments:-h, --help show this help message and exit--hf-repo {1bitLLM/bitnet_b1_58-large,1bitLLM/bitnet_b1_58-3B,HF1BitLLM/Llama3-8B-1.58-100B-tokens,tiiuae/Falcon3-1B-Instruct-1.58bit,tiiuae/Falcon3-3B-Instruct-1.58bit,tiiuae/Falcon3-7B-Instruct-1.58bit,tiiuae/Falcon3-10B-Instruct-1.58bit}, -hr {1bitLLM/bitnet_b1_58-large,1bitLLM/bitnet_b1_58-3B,HF1BitLLM/Llama3-8B-1.58-100B-tokens,tiiuae/Falcon3-1B-Instruct-1.58bit,tiiuae/Falcon3-3B-Instruct-1.58bit,tiiuae/Falcon3-7B-Instruct-1.58bit,tiiuae/Falcon3-10B-Instruct-1.58bit}Model used for inference--model-dir MODEL_DIR, -md MODEL_DIRDirectory to save/load the model--log-dir LOG_DIR, -ld LOG_DIRDirectory to save the logging info--quant-type {i2_s,tl1}, -q {i2_s,tl1}Quantization type--quant-embd Quantize the embeddings to f16--use-pretuned, -p Use the pretuned kernel parameters
实战演习
基本场景
# Run inference with the quantized model
python run_inference.py -m models/BitNet-b1.58-2B-4T/ggml-model-i2_s.gguf -p "You are a helpful assistant" -cnv
usage: run_inference.py [-h] [-m MODEL] [-n N_PREDICT] -p PROMPT [-t THREADS] [-c CTX_SIZE] [-temp TEMPERATURE] [-cnv]Run inferenceoptional arguments:-h, --help show this help message and exit-m MODEL, --model MODELPath to model file-n N_PREDICT, --n-predict N_PREDICTNumber of tokens to predict when generating text-p PROMPT, --prompt PROMPTPrompt to generate text from-t THREADS, --threads THREADSNumber of threads to use-c CTX_SIZE, --ctx-size CTX_SIZESize of the prompt context-temp TEMPERATURE, --temperature TEMPERATURETemperature, a hyperparameter that controls the randomness of the generated text-cnv, --conversation Whether to enable chat mode or not (for instruct models.)(When this option is turned on, the prompt specified by -p will be used as the system prompt.)
基准测试
我们提供脚本来运行推理基准测试,从而提供模型。
usage: e2e_benchmark.py -m MODEL [-n N_TOKEN] [-p N_PROMPT] [-t THREADS] Setup the environment for running the inference required arguments: -m MODEL, --model MODEL Path to the model file. optional arguments: -h, --help Show this help message and exit. -n N_TOKEN, --n-token N_TOKEN Number of generated tokens. -p N_PROMPT, --n-prompt N_PROMPT Prompt to generate text from. -t THREADS, --threads THREADS Number of threads to use.
以下是每个参数的简要说明:
- -m, : 模型文件的路径。这是运行脚本时必须提供的必需参数。--model
- -n, : 推理过程中要生成的 Token 数量。它是一个可选参数,默认值为 128。--n-token
- -p, :用于生成文本的提示标记的数量。这是一个可选参数,默认值为 512。--n-prompt
- -t, : 用于运行推理的线程数。它是一个可选参数,默认值为 2。--threads
- -h, : 显示帮助消息并退出。使用此参数可显示使用信息。--help
例如:
python utils/e2e_benchmark.py -m /path/to/model -n 200 -p 256 -t 4
此命令将使用位于 的模型运行推理基准测试,利用 4 个线程从 256 个令牌提示符生成 200 个令牌。/path/to/model
对于任何公共模型都不支持的模型布局,我们提供了脚本来生成具有给定模型布局的虚拟模型,并在您的机器上运行基准测试:
python utils/generate-dummy-bitnet-model.py models/bitnet_b1_58-large --outfile models/dummy-bitnet-125m.tl1.gguf --outtype tl1 --model-size 125M# Run benchmark with the generated model, use -m to specify the model path, -p to specify the prompt processed, -n to specify the number of token to generate
python utils/e2e_benchmark.py -m models/dummy-bitnet-125m.tl1.gguf -p 512 -n 128