Flink部署与应用——部署方式介绍
引入
我们通过Flink相关论文的介绍,对于Flink已经有了初步理解,这里简单的梳理一下Flink常见的部署方式。
Flink 的部署方式
StandAlone模式
介绍
StandAlone模式是Flink框架自带的分布式部署模式,不依赖其他的资源调度框架,特点:
- 分布式多台物理主机部署
- 依赖于Java8或Java11JDk环境
- 仅支持Session模式提交Job
- 支持高可用配置
但是有以下缺点:
- 资源利用弹性不够(资源总量是定死的;job退出后也不能立刻回收资源)
- 资源隔离度不够(所有job共享集群的资源)
- 所有job共用一个jobmanager,负载过大
- 只能运行Flink程序,不能能运行其他的编程模型
OnYarn模式
介绍
YARN是一个通用的资源调度框架,特点是:
- 可以运行多种编程模型,例如MR、Storm、Spark、Flink等
- 性能稳定,运维经验丰富
- 灵活的资源分配和资源隔离
- 每提交一个application都会有一个专门的ApplicationMater(JobManager)
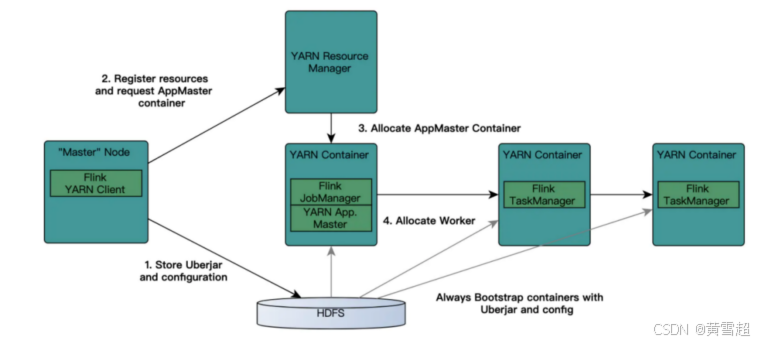
ResouManager(NM):
- 负责处理客户端请求
- 监控NodeManager
- 启动和监控APPlicationMaster
- 资源的分配和调度
NodeManager:
- 管理单个Worker节点上的资源
- 处理来自ResourceManager的命令
- 处理来自ApplicationMaster的命令
- 汇报资源状态
ApplicationMaster:
- 负责数据的切分
- 为应用申请计算资源,并分配给Task
- 任务的监控与容错
- 运行在Worker节点上
Container:
- 资源抽象,封装了节点上的多维度资源,如CPU,内存,网络资源等
Flink On Yarn 的三种模式
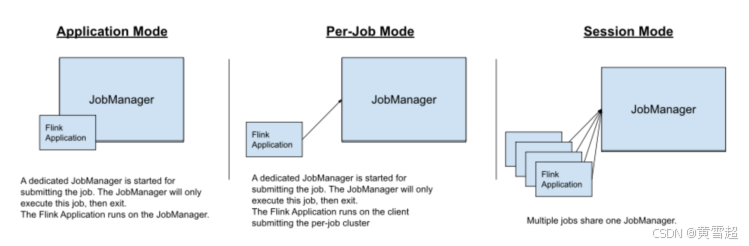
Flink程序可以运行为以下3种模式:
- Application Mode【生产中建议使用的模式】:每个job独享一个集群,job退出集群则退出,用户类的main方法在集群上运行
- Per-Job Mode:每个job独享一个集群,job退出集群则退出,用户类的main方法在client端运行;(大job,运行时长很长,比较合适;因为每起一个job,都要去向yarn申请容器启动jm,tm,比较耗时)
- Yarn Session Mode:多个job共享同一个集群<jobmanager/taskmanager>、job退出集群也不会退出,用户类的main方法在client端运行;(需要频繁提交大量小job的场景比较适用;因为每次提交一个新job的时候,不需要去向yarn注册应用)
上述3种模式的区别点在:
集群的生命周期和资源的隔离保证
用户类的main方法是运行在client端,还是在集群端
yarn application模式提交
bin/flink run-application -t yarn-application \
-yjm 1024 -yqu default -ys 2 \
-ytm 1024 -p 4 \
-c com.chaos.flink.java.KafkaSinkYarn /root/flink_test-1.0.jar
- bin/flink run-application :这是用于运行 Flink 应用程序的命令入口。
- -t yarn-application :指定在 YARN 集群上运行应用程序。
- -yjm 1024 :设置 JobManager 的内存大小为 1024 MB。
- -yqu default :指定 YARN 队列的名称为 default。
- -ys 2 :设置 YARN 服务,这里可能是指 YARN 的一些特定配置,比如在 YARN 上运行的实例数量。
- -ytm 1024 :设置 TaskManager 的内存大小为 1024 MB。
- -p 4 :设置 Flink 作业的并行度为 4。
- -c com.chaos.flink.java.KafkaSinkYarn :指定主类的完整类名为 com.chaos.flink.java.KafkaSinkYarn,这是应用程序的入口类。
- /root/flink_test-1.0.jar :指定要运行的 Flink 应用程序的 JAR 包路径。
yarn perJob模式提交
Yarn-Per-Job 模式:每个作业单独启动集群,隔离性好,JM(JobManager) 负载均衡,main 方法在客户端执行。在 per-job 模式下,每个 Job 都有一个 JobManager,每个TaskManager 只有单个 Job。
特点: 一个任务会对应一个 Job,每提交一个作业会根据自身的情况,都会单独向 yarn申请资源,直到作业执行完成,一个作业的失败与否并不会影响下一个作业的正常提交和运行。独享 Dispatcher 和 ResourceManager,按需接受资源申请;适合规模大长时间运行的作业。
提交命令 (申请容器启动flink集群以及提交job,是合二为一的)
bin/flink run -m yarn-cluster -yjm 1024 \
-ytm 1024 -yqu default -ys 2 -p 4 \
-c com.chaos.TaskDemo /root/flink_test-1.0.jar
- -m:master的运行模式
- -yjm:JobManager的所在Yarn容器的内存大小
- -ytm:TaskManager的所在Yarn容器额内存大小
- -yqu:Yarn任务队列的名称
- -ys:每个TaskManager的slot数量
- -p:并行度
- -c:main方法全类名
yarn session模式提交
Yarn-Session 模式:所有作业共享集群资源,隔离性差,JM 负载瓶颈,main 方法在客户端执行。适合执行时间短,频繁执行的短任务,集群中的所有作业 只有一个 JobManager,另外,Job 被随机分配给 TaskManager
特点: Session-Cluster 模式需要先启动集群,然后再提交作业,接着会向 yarn 申请一块空间后,资源永远保持不变。如果资源满了,下一个作业就无法提交,只能等到 yarn 中的其中一个作业执行完成后,释放了资源,下个作业才会正常提交。所有作业共享 Dispatcher 和 ResourceManager;共享资源;适合规模小执行时间短的作业。
- 基本操作命令
# 提交命令: bin/yarn-session.sh –help# 停止命令: yarn application -kill application_1550836652097_0002 - 具体操作步骤
- 先开辟资源启动session模式集群
# 老版本: bin/yarn-session.sh -n 3 -jm 1024 -tm 1024 # -n --> 指定需要启动多少个Taskmanager# 新版本: bin/yarn-session.sh -jm 1024 -tm 1024 -s 2 -m yarn-cluster -ynm hello -qu default -jm:jobmanager memory -tm:taskmanager memory -m yarn-cluster:集群模式(yarn集群模式) -s:规定每个taskmanager上的taskSlot数(槽位数) -nm:自定义appliction名称 -qu:指定要提交到的yarn队列 - 启动的服务进程
YarnSessionClusterEntrypoint(AppMaster,即JobManager)
注意:此刻并没有taskmanager,也就是说,taskmanager是在后续提交job时根据资源需求动态申请容器启动的。 - 向已运行的session模式集群提交job
bin/flink run -d -yid application_1550579025929_62420 -p 4 -c com.chaos.flink.java.TaskDemo /root/flink_test-1.0.jar
- 先开辟资源启动session模式集群
Flink On Yarn 的优劣势
优势:
- 与现有大数据平台无缝对接(Hadoop2.4+)
- 部署集群与任务提交都非常简单
- 资源管理统一通过Yarn管理,提升整体资源利用率类
- 基于Native方式,TaskManager资源按需申请和启动,防止资源浪费
- 容错保证:借助于Hadoop Yarn提供的自动failover机制,能保证JobManager,TaskManager节点异常恢复
劣势:
- 资源隔离问题,尤其是网络资源的隔离,Yarn做的还不够完善
- 离线和实时作业同时运行相互干扰等问题需要重视
- Kerberos认证超期问题导致Checkpoint无法持久化
On Kubernetes模式
介绍
Flink on Kubernetes 是将 Apache Flink 部署在 Kubernetes 集群上的一种方式,使用户能够利用 Kubernetes 的强大功能进行资源管理、弹性伸缩和高可用性管理。
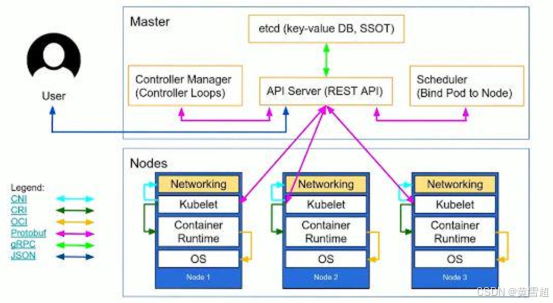
Master节点:
- 负责整个集群的管理,资源管理
- 运行APIServer,ControllerManager,Scheduler服务
- 提供Etcd高可用键值存储服务,用来保存Kubernetes集群所有对象的状态信息和网络信息
Node:
- 集群操作的单元,Pod运行宿主机
- 运行业务负载,业务负载会以Pod的形式运行
Kubelet:
- 运行在Node节点上,维护和管理该Node上的容器
Container Runtime:
- Docker容器运行环境,负责容器的创建和管理
Pod:
- 运行在Node节点上,多个相关Container的组合
- Kubunetes创建和管理的最小单位
核心概念
- ReplicationController(RC):RC是K8s集群中最早的保证Pod高可用的API对象,通过监控运行中的Pod来保证集群中运行指定数目的Pod副本。
- Service:Service是对一组提供相同功能的Pods的抽象,并为它们提供一个统一的入口。
- PersistentVolume(PV):容器的数据都是非持久化的,在容器消亡以后数据也跟着丢失,所以Docker提供了Volume机制以便将数据持久化存储。
- ConfigMap:ConfigMap用于保存配置数据的键值对,可以用来保存单个属性,也可以用来保存配置文件。
Flink On Kubunetes的三种模式
Session 模式:启动一个长期运行的 Flink 集群,所有作业共享该集群资源。适合多个作业需要共享资源的场景。
Application 模式:为每个作业启动一个独立的 Flink 集群,作业之间资源隔离,互不影响。
Native Kubernetes 模式:Flink 原生支持 Kubernetes,通过 Kubernetes API 进行资源管理和调度,能够动态分配和释放 TaskManager。
Flink On Kubunetes的优缺点
优点:
-
强大的资源管理与弹性伸缩:Kubernetes 可根据作业负载动态分配和释放资源,实现 Flink 集群的弹性伸缩。这提高了资源利用率,降低了成本,尤其在业务波动时可快速调整资源以满足需求。
-
高可用性与容错能力:Kubernetes 能自动重启故障 Pod 并重新调度 TaskManager,确保 Flink 作业持续运行,保障数据处理的可靠性和稳定性。
-
深度云原生集成:Flink on Kubernetes 与云原生生态系统深度融合,可与云服务(如对象存储、消息队列)无缝协作,便于构建完整的云原生数据处理解决方案。
-
简化的部署与运维:通过 Flink Kubernetes Operator 提供的抽象接口,用户可以更高效地部署和管理 Flink 集群,减少手动操作,降低运维负担。
-
多租户支持:Kubernetes 的命名空间功能可实现多租户隔离,为多团队或项目共用集群提供了便利,提高了资源的隔离性和安全性。
缺点:
-
部署复杂度增加:与在专用集群上部署 Flink 相比,Flink on Kubernetes 需要熟悉 Kubernetes 的概念和工具(如 Pod、Deployment、Service 等),增加了学习曲线和部署前的准备工作。
-
资源管理的潜在挑战:Kubernetes 的资源调度策略可能与 Flink 的需求不完全匹配,导致资源分配效率降低。例如,在某些情况下,Kubernetes 的默认调度算法可能无法满足 Flink 对数据本地性的要求,影响作业性能。
-
性能开销:在 Kubernetes 上运行 Flink 会引入额外的性能开销,包括容器的启动时间和 Kubernetes 的调度延迟。此外,如果 Kubernetes 集群的资源紧张,可能导致 Flink 作业的性能下降。
-
网络配置复杂性:在 Kubernetes 集群中,网络配置可能较为复杂,需要确保 Flink 的各个组件之间能够正确通信。
-
长期运行作业的资源管理:对于长期运行的 Flink 作业,需要持续监控和管理资源使用情况。Kubernetes 的资源配额和限制机制可以帮助控制资源使用,但需要合理配置以避免对作业的性能产生负面影响。