RefFormer论文精读
基本信息
- 标题:Referencing Where to Focus: Improving Visual Grounding with Referential Query
- 作者:Yabing Wang¹, Zhuotao Tian², Qingpei Guo³, Zheng Qin¹, Sanping Zhou¹, Ming Yang³, Le Wang¹*
- 机构:¹ 西安交通大学 ² 哈尔滨工业大学(深圳) ³ 蚂蚁集团
- 会议:NIPS2024
- github地址:无
摘要部分
Visual Grounding(视觉定位)旨在根据给定的自然语言表达,在图像中定位所提及的对象。近年来,基于DETR的视觉定位方法因其无需依赖额外的努力(例如预先生成的候选区域或预定义的锚框)即可直接预测目标对象的坐标而受到了广泛关注。然而,现有研究主要集中于设计更强大的多模态解码器,这些解码器通常通过随机初始化或使用语言嵌入来生成可学习的查询(queries)。这种原始的查询生成方法不可避免地增加了模型的学习难度,因为它在解码开始时没有包含任何与目标相关的信息。此外,它们在查询学习过程中仅使用最深层的图像特征,忽略了其他层特征的重要性。
为了解决这些问题,我们提出了一种名为RefFormer的新方法。它包含一个查询适应模块,该模块可以无缝集成到CLIP中,并生成参照查询(referential query)以为解码器提供先验上下文,同时还有一个任务特定的解码器。通过将参照查询整合到解码器中,我们可以有效地降低解码器的学习难度,并准确地聚焦于目标对象。此外,我们提出的查询适应模块还可以充当适配器,在无需调整骨干网络参数的情况下保留CLIP中的丰富知识。大量的实验证明了我们提出方法的有效性和效率,在五个视觉定位基准测试上均优于最先进的方法。
提出的问题
- The queries that are inputted to the decoder in these methods are typically generated through random initialization or by utilizing linguistic embeddings.(这些解码器通常通过随机初始化或使用语言嵌入来生成可学习的查询(queries))
- 这种与目标无关的查询不可避免地增加了解码器的学习难度。
- 在查询学习过程中,这些方法倾向于只关注骨干网络的最深层视觉特征,而忽略了对于定位任务至关重要且存在于低层和中层特征中的纹理信息。
动机和方案
- 我们能否为解码器生成与目标相关的参照查询(referential queries),以减轻解码器面临的学习难度?
- 我们如何有效地将多层视觉上下文信息融入查询学习过程?
- 考虑到 CLIP 携带着丰富的视觉-语言对齐知识,因此我们将其作为我们方法的骨干网络。
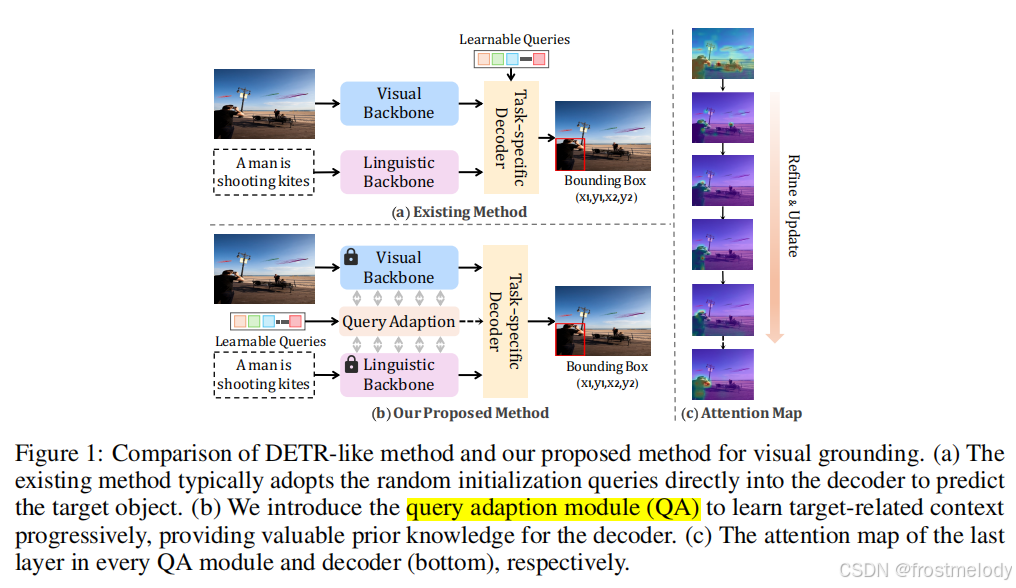
- 提出了一种名为 RefFormer 的新方法。我们的方法整合了一个查询适应(QA)模块,用于生成参照查询,它为解码器提供了与目标相关的上下文(如图 1 (b) 所示)
- 策略性地将 QA 模块插入到 CLIP 的不同层中,查询可以自适应地从多层图像特征图中学习目标相关信息,并逐层迭代地精炼所获取的信息。此外,我们提出的 RefFormer 还可以充当适配器(adapter),使得 CLIP 可以保持冻结(参数不更新,降低训练成本),并保留其原有的丰富知识。
- 它采用了双向交互机制,通过引入少量可训练的参数来执行多模态融合,并在整个特征提取过程中通过残差连接将新的任务特定知识注入到 CLIP 中。
相关工作部分
In the object detection field, DETR presents an end-to-end object detection model that is built in an encoder-decoder transformer architecture. However, it suffers from slow training convergence. To address this issue, some follow-up works [55, 19, 49, 45, 20, 26, 24, 54] solve this issue by optimizing the learnable queries in DETR. For instance, Anchor DETR [45] directly treats 2D reference points as queries, while DAB-DETR [24] further investigates the role of queries in DETR and proposes the use of 4D anchor boxes as queries. In contrast to these model-level improvements, DN-DETR [20] introduces query denoising training to mitigate the instability of bipartite graph matching, which is further enhanced by DINO [54].
在目标检测领域,DETR 提出了一种基于编码器-解码器 Transformer 架构的端到端目标检测模型,但该模型存在训练收敛缓慢的问题。为了解决这一问题,后续研究工作 [55, 19, 49, 45, 20, 26, 24, 54] 主要通过优化 DETR 中的可学习查询(learnable queries)来加快训练收敛速度。例如,Anchor DETR [45] 直接将二维参考点作为查询,DAB-DETR [24] 则进一步探索了查询的作用,并提出使用四维锚框作为查询。与这些模型级别的改进不同,DN-DETR [20] 引入了查询去噪训练机制以缓解二分图匹配过程中的不稳定性,而该机制在 DINO [54] 中得到了进一步增强。
Additionally, similar research has been explored in other tasks [22, 13, 37]. For example, EaTR [13] formulates a video as a set of event units and treats video-specific event units as dynamic moment queries in video grounding tasks. MTR++ [37] introduces distinct learnable intention queries generated by the k-means clustering algorithm to handle trajectory prediction across different motion modes in motion prediction tasks.
此外,类似的查询优化思想也被应用于其他任务中 [22, 13, 37]。例如,EaTR [13] 将视频建模为一组事件单元,并在视频定位任务中将这些视频特定的事件单元作为动态时刻查询使用。MTR++ [37] 则通过 K-means 聚类算法生成具有差异性的可学习意图查询,用于处理多种运动模式下的轨迹预测任务。
- DETR训练收敛速度慢 (slow training convergence)。
- 优化可学习查询(Learnable Query Optimization)就是改进这些“查询”的设计或者初始化方式,让它们能更快、更准确地帮助模型找到物体,从而加快训练速度。
- Anchor DETR 让查询Query 直接代表了图片中的2D 参考点。模型学习的就是这些查询对应的参考点应该在图片的哪个位置最有可能找到物体。这样,查询就有了明确的空间意义,有助于模型更快定位。
- DAB-DETR 更进一步,让查询代表了 4D 锚框。一个 4D 锚框通常代表一个潜在的物体框的位置(x, y)和大小(宽, 高)。所以,查询直接代表了模型对物体可能框的位置和大小的初始猜测。这为模型提供了一个更强的起点来搜索和细化物体框。
- DN-DETR 和 DINO 关注的是 DETR 训练中“二分图匹配”(bipartite graph matching)的步骤(这个步骤负责把模型的预测结果和真实的物体框进行匹配,以计算误差并进行学习)的不稳定性。它们引入了查询去噪训练 (query denoising training) 的技术,简单说,就是在训练时给输入数据(比如查询或物体框)加一些“噪声”,然后让模型学习去“还原”它们,这有助于稳定二分图匹配的过程,从而加快收敛。这种方法改进的是训练的策略,而不是查询本身代表的含义或结构。
- “查询Query”这种概念,并不仅仅局限于目标检测,也被用在了其他类型的 AI 任务中。比如视频定位 (video grounding):根据一段文字描述(比如“男人在跑步机上跑步”),在一段视频里找到对应的视频片段(时刻),运动预测 (motion prediction):预测一个物体(比如汽车、行人)接下来会怎么移动。
- EaTR 这个模型在video grounding任务中,把视频看作是一系列事件单元(比如每个事件单元代表视频里发生的一小段动作)。它把这些“与视频相关的事件单元”当作动态时刻查询 (dynamic moment queries) 来用。这些查询帮助模型去搜索和定位视频中与文字描述最匹配的那个“时刻”。“动态”可能意味着这些查询会根据视频内容的变化而调整。
- MTR++ 这个模型在motion prediction任务中,需要处理物体不同的运动模式 (motion modes),比如直行、左转、减速、停车等。它引入了有差异性的可学习意图查询 (distinct learnable intention queries)。这些查询不是随机的,而是代表了物体可能的不同“意图”或“模式”。比如一个查询可能代表“想要左转”的意图,另一个代表“想要直行”的意图。这些查询被设计或初始化成彼此不同,每个查询都试图捕捉一种典型的运动模式。模型最初是通过 k-means 这种聚类算法,分析大量真实的运动轨迹数据,把相似的运动轨迹归为一类(就是一个“模式”),然后用这些模式的中心来初始化这些有差异性的查询。通过使用这些代表不同运动意图的查询,MTR++ 模型能够预测出物体多种可能的未来轨迹,每条轨迹对应一种不同的运动意图或模式,这比只预测一条轨迹更有用。
特征提取部分
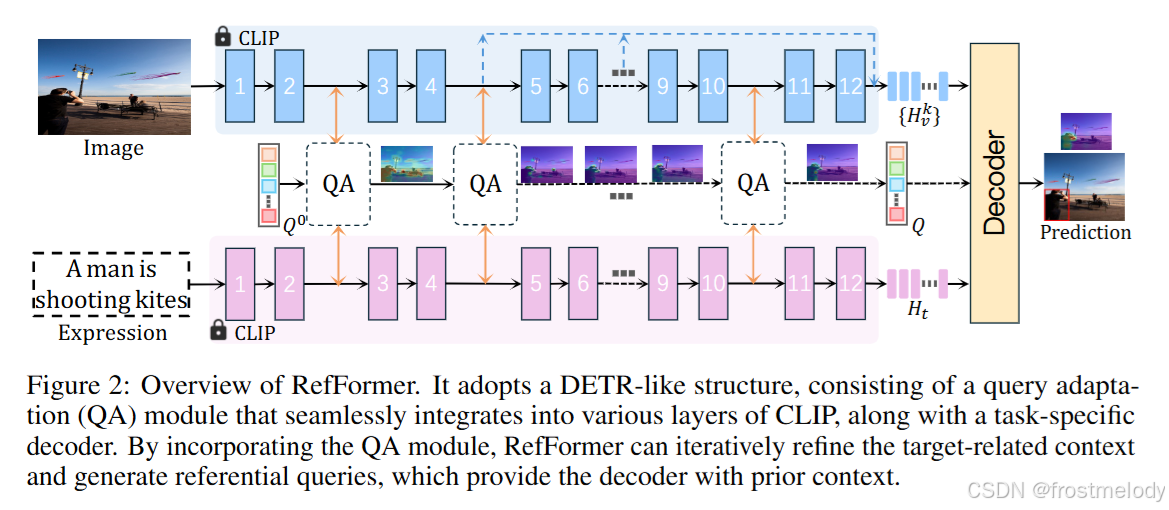
考虑到 CLIP 在视觉-语言对齐方面令人印象深刻的能力,我们将其作为我们方法的主干backbone,用于提取图像和文本表示,并在训练期间保持参数冻结。特征提取过程表示如下:
图片特征提取
图像编码器: 对于一个输入图像 V ∈ R H × W × 3 V \in \mathbb{R}^{H \times W \times 3} V∈RH×W×3,它被分割成 N N N 个不重叠的图像块(patch),每个块的大小为 P × P P \times P P×P,其中 N v = H × W P 2 N_v = \frac{H \times W}{P^2} Nv=P2H×W。接下来,这些图像块被展平(flattened)为一组向量,表示为 { x v i ∈ R P 2 ⋅ 3 } i = 1 N \{x_v^i \in \mathbb{R}^{P^2 \cdot 3}\}_{i=1}^N {xvi∈RP2⋅3}i=1N。然后,这些向量通过一个线性投影层 ϕ e ( ⋅ ) \phi_e(\cdot) ϕe(⋅) 变换为 token 嵌入(token embeddings)。此外,一个分类 token x c l s ∈ R D x_{cls} \in \mathbb{R}^D xcls∈RD 被添加到 token 嵌入的开头。随后,位置嵌入 E v E^v Ev 被加入,并应用层归一化(layer normalization, LN)。这个过程可以表示如下:
Z v 0 = L N ( [ x c l s , ϕ e ( X v ) ] + E v ) (1) Z_v^0 = LN([x_{cls}, \phi_e(X_v)] + E^v) \tag{1} Zv0=LN([xcls,ϕe(Xv)]+Ev)(1)
其中 [ ; ] [;] [;] 表示连接(concatenate)操作。然后,token 序列 Z v 0 Z_v^0 Zv0 被输入到 L L L 个 transformer 层。每个 transformer 层包含两个子模块:多头自注意力(multi-head self-attention, MHSA)和多层感知器(multilayer perceptron, MLP),每个子模块之前都进行了层归一化。
Z ˉ v i = M H S A ( L N ( Z v i − 1 ) ) + Z v i − 1 , i = 1 , . . . , L (2) \bar{Z}_v^i = MHSA(LN(Z_v^{i-1})) + Z_v^{i-1}, \quad i=1,...,L \tag{2} Zˉvi=MHSA(LN(Zvi−1))+Zvi−1,i=1,...,L(2)
Z v i = M L P ( L N ( Z ˉ v i ) ) + Z ˉ v i (3) Z_v^i = MLP(LN(\bar{Z}_v^i)) + \bar{Z}_v^i \tag{3} Zvi=MLP(LN(Zˉvi))+Zˉvi(3)
其中 Z v i ∈ R N × D Z_v^i \in \mathbb{R}^{N \times D} Zvi∈RN×D 表示第 i i i 个 transformer 层的输出。
文本特征提取
文本编码器: 给定一个指代表达 T t T_t Tt,它首先使用小写字节对编码(lower-cased byte pair encoding)表示 X t X_t Xt 转换为一系列词嵌入(word embeddings)。词嵌入会用 [SOS] 和 [EOS] token 包围起来,生成一个长度为 N t N_t Nt 的序列。与图像编码器类似,这些 token 会与位置嵌入 E t E_t Et 相加,并通过 L L L 个 transformer 层来提取文本表示:
Z ˉ t i = M H S A ( L N ( Z t i − 1 ) ) + Z t i − 1 , i = 1 , . . . , L (4) \bar{Z}_t^i = MHSA(LN(Z_t^{i-1})) + Z_t^{i-1}, \quad i=1,...,L \tag{4} Zˉti=MHSA(LN(Zti−1))+Zti−1,i=1,...,L(4)
Z t i = M L P ( L N ( Z ˉ t i ) ) + Z ˉ t i (5) Z_t^i = MLP(LN(\bar{Z}_t^i)) + \bar{Z}_t^i \tag{5} Zti=MLP(LN(Zˉti))+Zˉti(5)
其中 Z t 0 = [ x s o s ; X t ; x e o s ] + E t Z_t^0 = [x_{sos}; X_t; x_{eos}] + E_t Zt0=[xsos;Xt;xeos]+Et,表示文本编码器中的词嵌入层。
方法部分
Query Adaptation Module 查询自适应模块 (QA)
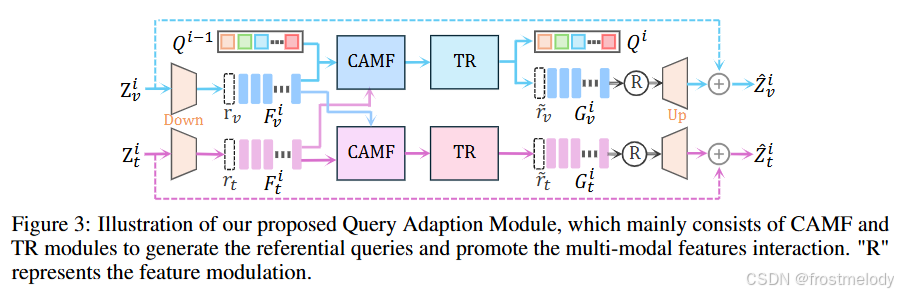
QA 模块:(如图 3 所示),该模块可以生成参照查询,为解码器提供与目标相关的上下文,从而增强解码器的 grounding 能力。重要的是,我们的方法将多级特征整合到查询学习过程中,使查询能够捕获更全面的目标对象信息,并可以逐层细化。此外,QA 还可以作为适配器,无需对整个骨干网络的参数进行微调。
降维投影:考虑到从骨干网络的第 i i i 层获得的图像和语言表示 Z v i Z_v^i Zvi 和 Z t i Z_t^i Zti,我们首先使用 MLP 层 ϕ v d i ( ⋅ ) \phi_{vd}^i(\cdot) ϕvdi(⋅) 和 ϕ t d i ( ⋅ ) \phi_{td}^i(\cdot) ϕtdi(⋅) 将它们投影到较低维度的特征,以减少计算内存:
F v i = ϕ v d i ( Z v i ) , F t i = ϕ t d i ( Z t i ) (6) F_v^i = \phi_{vd}^i(Z_v^i), \quad F_t^i = \phi_{td}^i(Z_t^i) \tag{6} Fvi=ϕvdi(Zvi),Fti=ϕtdi(Zti)(6)
条件聚合和多模态融合 (CAMF): 我们随机初始化 N q N_q Nq 个可学习查询 Q ∈ R N q × D l Q \in \mathbb{R}^{N_q \times D_l} Q∈RNq×Dl,其中 D l D_l Dl 表示投影后的维度。这些查询经过专门设计,用于捕获潜在目标对象的上下文。接下来,我们将这些查询与图像特征连接起来,并将它们连同语言特征一起输入到 CAMF 块中。具体来说,CAMF 块主要由一个交叉注意力层组成,该层分别以图像和查询特征 [ Q ; F v ] [Q; F_v] [Q;Fv] 和语言特征 F t F_t Ft 作为查询和键/值。这种方法不仅使我们能够将表达条件融入可学习查询 Q Q Q,还可以从其他模态中提取相关信息,从而促进目标相关跨模态特征的融合。此外,我们引入了两个可学习的调节 token r v , r t ∈ R D l r_v, r_t \in \mathbb{R}^{D_l} rv,rt∈RDl 来调节每个 QA 的最终输出。这个过程可以形式化如下:
r ˉ v , Q ˉ c i , F ˉ v i = MHCA ( [ [ r v ; Q ; F v ] ] , F t i , F t i ) (7) \bar{r}_v, \bar{Q}_c^i, \bar{F}_v^i = \text{MHCA}([[r_v; Q; F_v]], F_t^i, F_t^i) \tag{7} rˉv,Qˉci,Fˉvi=MHCA([[rv;Q;Fv]],Fti,Fti)(7)
Q ^ c i = LN ( Q ˉ c i ) + Q i − 1 , F ^ v i = LN ( F ˉ v i ) + F v i (8) \hat{Q}_c^i = \text{LN}(\bar{Q}_c^i) + Q^{i-1}, \quad \hat{F}_v^i = \text{LN}(\bar{F}_v^i) + F_v^i \tag{8} Q^ci=LN(Qˉci)+Qi−1,F^vi=LN(Fˉvi)+Fvi(8)
r ˉ t , F ˉ t i = MHCA ( [ [ r t ; F t ] ] , F v i , F v i ) , F ^ t i = LN ( F ˉ t i ) + F t i (9) \bar{r}_t, \bar{F}_t^i = \text{MHCA}([[r_t; F_t]], F_v^i, F_v^i), \quad \hat{F}_t^i = \text{LN}(\bar{F}_t^i) + F_t^i \tag{9} rˉt,Fˉti=MHCA([[rt;Ft]],Fvi,Fvi),F^ti=LN(Fˉti)+Fti(9)
其中 Q i − 1 Q^{i-1} Qi−1 表示从前一个 QA 输出的可学习查询,而 Q 0 Q^0 Q0 是随机初始化的。符号 [ ; ] [;] [;] 表示连接concat操作,而 MHCA ( ⋅ , ⋅ , ⋅ ) \text{MHCA}(\cdot, \cdot, \cdot) MHCA(⋅,⋅,⋅) 和 LN ( ⋅ ) \text{LN}(\cdot) LN(⋅) 分别表示多头交叉注意力层和层归一化。
目标相关上下文细化 (TR): 接下来,我们将查询 Q ^ c \hat{Q}_c Q^c 和多模态增强特征图 F ^ v i \hat{F}_v^i F^vi 和 F ^ t i \hat{F}_t^i F^ti 输入到 TR 块中。首先,我们使用聚合了条件的查询 Q ^ c \hat{Q}_c Q^c 与多模态增强图像特征图 F ^ v i \hat{F}_v^i F^vi 进行交互,以细化其中的目标相关视觉上下文。
Q v i = MHCA ( Q ^ c i , F ^ v i , F ^ v i ) , Q i = LN ( MLP ( Q v i ) ) + Q ^ c i (10) Q_v^i = \text{MHCA}(\hat{Q}_c^i, \hat{F}_v^i, \hat{F}_v^i), \quad Q^i = \text{LN}(\text{MLP}(Q_v^i)) + \hat{Q}_c^i \tag{10} Qvi=MHCA(Q^ci,F^vi,F^vi),Qi=LN(MLP(Qvi))+Q^ci(10)
此外,对于聚合了其他模态信息的特征图 F ^ v i \hat{F}_v^i F^vi 和 F ^ t i \hat{F}_t^i F^ti,我们使用自注意力进一步增强它们的目标相关上下文语义:
r ˉ v , F ~ v i = MHSA ( [ r ˉ v ; F ^ v ] , F ^ v i , F ^ v i ) , G v i = LN ( MLP ( F ~ v i ) ) + F ^ v i (11) \bar{r}_v, \tilde{F}_v^i = \text{MHSA}([\bar{r}_v; \hat{F}_v], \hat{F}_v^i, \hat{F}_v^i), \quad G_v^i = \text{LN}(\text{MLP}(\tilde{F}_v^i)) + \hat{F}_v^i \tag{11} rˉv,F~vi=MHSA([rˉv;F^v],F^vi,F^vi),Gvi=LN(MLP(F~vi))+F^vi(11)
r ˉ t , F ~ t i = MHSA ( [ r ˉ t ; F ^ t ] , F ^ t i , F ^ t i ) , G t i = LN ( MLP ( F ~ t i ) ) + F ^ t i (12) \bar{r}_t, \tilde{F}_t^i = \text{MHSA}([\bar{r}_t; \hat{F}_t], \hat{F}_t^i, \hat{F}_t^i), \quad G_t^i = \text{LN}(\text{MLP}(\tilde{F}_t^i)) + \hat{F}_t^i \tag{12} rˉt,F~ti=MHSA([rˉt;F^t],F^ti,F^ti),Gti=LN(MLP(F~ti))+F^ti(12)
上采样投影: 最后,我们利用 MLP 将图像和语言特征的通道维度恢复到其原始大小。然后,这些特征以残差方式作为输入传递给骨干网络的下一层。在此之前,我们利用调节 token 来调节特征 G v G_v Gv 和 G t G_t Gt,这有助于防止多模态信号 overpowering 原始信号。
Z ^ v i = ϕ v u i ( G v i × σ ( r ~ v ) ) + Z v i , Z ^ t i = ϕ t u i ( G t i × σ ( r ~ t ) ) + Z t i (13) \hat{Z}_v^i = \phi_{vu}^i (G_v^i \times \sigma(\tilde{r}_v)) + Z_v^i, \hat{Z}_t^i = \phi_{tu}^i (G_t^i \times \sigma(\tilde{r}_t)) + Z_t^i \tag{13} Z^vi=ϕvui(Gvi×σ(r~v))+Zvi,Z^ti=ϕtui(Gti×σ(r~t))+Zti(13)
其中 ϕ v u i ( ⋅ ) \phi_{vu}^i (\cdot) ϕvui(⋅) 和 ϕ t u i ( ⋅ ) \phi_{tu}^i (\cdot) ϕtui(⋅) 表示 MLP 层,而 σ ( ⋅ ) \sigma (\cdot) σ(⋅) 表示 sigmoid 函数。
最后,通过迭代执行上述过程,查询 Q Q Q 可以逐步聚焦于目标相关上下文,并生成参照查询,为解码器提供先验上下文。
上采样投影这一步是把之前经过处理(融合了图像和语言信息)的特征,通过一种叫做 MLP(多层感知机,可以简单理解为一个小型神经网络)的方式,把它们的维度或大小恢复到和原始特征一样的水平。
然后,这些恢复后的特征并不会直接替换掉原始特征,而是以一种叫做“残差连接”的方式加回到骨干网络(主网络)的对应层中。这就像是把处理过的信息作为一种“补充”或“调整”加到原始信息上,保留了原始信息的底子。
关键点是“调节 token”: 在把处理过的特征加回原始特征之前,会用一个叫做“调节 token”的东西去调整(modulate)这些处理过的特征 ( G v G_v Gv 和 G t G_t Gt)。
为什么需要这个调节 token? 这是为了控制经过多模态融合后的信息对原始信息的影响程度。有时候,多模态信息可能会太“强”,直接加回去会压制或破坏原始的图像/语言信息。调节 token 就像一个“门控”或“权重”,它可以学习如何适当地调整多模态信号的强度,确保它能有效地融入原始信号,而不是完全取代或干扰原始信号。这样可以更好地平衡不同来源的信息。
总的来说:这一步就是将融合了多模态信息的特征,通过维度恢复和残差连接的方式加回主网络,并且利用调节 token 来精细控制这种融合的强度,以达到更好的效果。
Decoding with Referential Query 使用参照查询进行解码
语言引导的多级融合: 通过在 CLIP 的不同层插入 QA 模块,可以使用多级图像特征图自适应地更新参照查询。此外,为了增强解码器中的图像特征,我们在语言引导下聚合多级视觉特征,以获得语言感知的多级图像特征。具体来说,给定一个多级图像特征集 { Z ^ v k } \{ \hat{Z}_v^k \} {Z^vk} (包括低、中和高层),其中 k ∈ K k \in \mathcal{K} k∈K 表示选定的层索引,我们使用 MHCA 将语言特征 Z t l a s t Z_t^{last} Ztlast (文本编码器的最终输出) 注入到每个级别的图像特征中:
H s o s = ϕ m t ( Z t l a s t ) , H v k = ϕ m v ( Z ^ v k ) (14) H_{sos} = \phi_{mt}(Z_t^{last}), \quad H_v^k = \phi_{mv}(\hat{Z}_v^k) \tag{14} Hsos=ϕmt(Ztlast),Hvk=ϕmv(Z^vk)(14)
H ^ v k = MHCA ( H v k , H s o s , H s o s ) + H v k , k ∈ K (15) \hat{H}_v^k = \text{MHCA}(H_v^k, H_{sos}, H_{sos}) + H_v^k, \quad k \in \mathcal{K} \tag{15} H^vk=MHCA(Hvk,Hsos,Hsos)+Hvk,k∈K(15)
其中 ϕ m t ( ⋅ ) \phi_{mt}(\cdot) ϕmt(⋅) 和 ϕ m v ( ⋅ ) \phi_{mv}(\cdot) ϕmv(⋅) 表示用于将特征映射到相同维度的线性投影函数。此外, H s o s H_{sos} Hsos 表示 H t H_t Ht 中的 [SOS] token,它提取文本的全局信息。随后,通过简单的连接concat生成多级语言感知图像特征,然后通过线性投影函数 ϕ v m l ( ⋅ ) \phi_{vml}(\cdot) ϕvml(⋅) 映射到原始维度:
H ˉ v m l = Concat ( { H ^ v k } ) , k ∈ K (16) \bar{H}_{vml} = \text{Concat}(\{ \hat{H}_v^k \}), \quad k \in \mathcal{K} \tag{16} Hˉvml=Concat({H^vk}),k∈K(16)
H v m l = ϕ v m l ( H ˉ v m l ) (17) H_{vml} = \phi_{vml}(\bar{H}_{vml}) \tag{17} Hvml=ϕvml(Hˉvml)(17)
解码: 接下来,我们首先初始化与参照查询 Q 大小相同的查询 Q’,并将它们相加以利用 Q 中的先验上下文。请注意,为了避免在初始阶段来自 Q’ 的干扰,我们将 Q’ 初始化为一个全零矩阵。然后,我们将查询与图像特征连接起来,与语言特征进行交互,以聚合条件信息并生成多模态特征图 H m m H_{mm} Hmm。这可以表示为:
O ˉ c , H ˉ m m = MHCA ( [ ϕ q ( Q ) + Q ′ ; H v m l ] , H t , H t ) (18) \bar{O}_c, \bar{H}_{mm} = \text{MHCA}([\phi_q(Q) + Q'; H_{vml}], H_t, H_t) \tag{18} Oˉc,Hˉmm=MHCA([ϕq(Q)+Q′;Hvml],Ht,Ht)(18)
O c = LN ( O ˉ c ) + O ˉ c , H m m = LN ( H ˉ m m ) + H ˉ m m (19) O_c = \text{LN}(\bar{O}_c) + \bar{O}_c, \quad H_{mm} = \text{LN}(\bar{H}_{mm}) + \bar{H}_{mm} \tag{19} Oc=LN(Oˉc)+Oˉc,Hmm=LN(Hˉmm)+Hˉmm(19)
其中 ϕ q ( ⋅ ) \phi_q(\cdot) ϕq(⋅) 是 MLP 层,用于调节查询 Q 的重要性。当重要性趋近于零时,查询退化为普通查询。然后,我们将查询 O c O_c Oc 和多模态特征图 H m m H_{mm} Hmm 输入到 MHCA 层中,以提取目标嵌入 O ∈ R N q × D O \in \mathbb{R}^{N_q \times D} O∈RNq×D。这可以表示为:
O ˉ = MHCA ( O c , H m m , H m m ) (20) \bar{O} = \text{MHCA}(O_c, H_{mm}, H_{mm}) \tag{20} Oˉ=MHCA(Oc,Hmm,Hmm)(20)
O = LN ( ϕ r ( O ˉ ) ) + O ˉ (21) O = \text{LN}(\phi_r(\bar{O})) + \bar{O} \tag{21} O=LN(ϕr(Oˉ))+Oˉ(21)
其中 ϕ r ( ⋅ ) \phi_r(\cdot) ϕr(⋅) 表示线性投影函数。
Grounding Head: 我们在目标嵌入 O O O 之上构建了两个 MLP ( ϕ b o x ( ⋅ ) \phi_{box}(\cdot) ϕbox(⋅) 和 ϕ c l s ( ⋅ ) \phi_{cls}(\cdot) ϕcls(⋅))。最终输出包括目标对象的预测中心坐标,表示为 b = ( x , y , h , w ) ∈ R 4 b = (x, y, h, w) \in \mathbb{R}^4 b=(x,y,h,w)∈R4,以及包含目标对象的预测置信度分数 y ∈ R 2 y \in \mathbb{R}^2 y∈R2:
b = ϕ b o x ( O ) , y = ϕ c l s ( O ) (22) b = \phi_{box}(O), y = \phi_{cls}(O)\tag{22} b=ϕbox(O),y=ϕcls(O)(22)
训练目标
与 DETR 类似,我们采用二分匹配来找到预测 { b , y } \{b, y\} {b,y} 与地面真实目标 { b t g t , y t g t } \{b_{tgt}, y_{tgt}\} {btgt,ytgt} 之间的最佳匹配。在我们的例子中,类别预测是包含目标对象的查询的置信度预测。为了监督训练,我们使用框预测损失 (L1 和 GIoU) 以及匹配后的交叉熵损失。
L d e t = λ i o u L i o u ( b g t , b ) + λ L 1 ∣ ∣ b g t − b ∣ ∣ + λ c e L c e ( y g t , y ) (23) \mathcal{L}_{det} = \lambda_{iou} \mathcal{L}_{iou}(b_{gt}, b) + \lambda_{L1} ||b_{gt} - b|| + \lambda_{ce} \mathcal{L}_{ce}(y_{gt}, y)\tag{23} Ldet=λiouLiou(bgt,b)+λL1∣∣bgt−b∣∣+λceLce(ygt,y)(23)
其中 λ \lambda λ 表示相应的损失权重。此外,为了鼓励每个 QA 模块中的参照查询有效地聚焦于目标相关上下文,我们还引入了类似于上述目标函数的辅助损失 L a u x \mathcal{L}_{aux} Laux 来对其进行监督。最终的训练目标可以定义为:
L f i n a l = L d e t + λ a u x L a u x (24) \mathcal{L}_{final} = \mathcal{L}_{det} + \lambda_{aux} \mathcal{L}_{aux}\tag{24} Lfinal=Ldet+λauxLaux(24)
其中 λ a u x \lambda_{aux} λaux 表示辅助损失的权重。
{ b , y } \{b, y\} {b,y}:模型的预测
- b b b: 这是模型“预测”出来的边界框 (bounding box)。所以 b ∈ R 4 b \in \mathbb{R}^4 b∈R4 表示这是一个四维向量。模型会预测出多个这样的边界框,因为在“解码”部分,模型会根据多个查询 (Queries) 生成多个潜在的目标位置预测。
- y y y: 这是模型对这个预测框的置信度 (confidence score)。这里的 y y y 是一个关于“这个查询(以及它对应的预测框)是否包含目标物体”的置信度预测。它表示模型有多确定这个框里确实是语言描述的目标物体。 y ∈ R 2 y \in \mathbb{R}^2 y∈R2 可能表示一个二分类的输出,比如一个数值表示是目标物体的概率,另一个表示不是的概率。
- 所以, { b , y } \{b, y\} {b,y} 就代表了模型做出的一组预测:一个边界框和它对应的置信度。因为模型会预测多个潜在目标,所以实际上模型会输出多组 { b , y } \{b, y\} {b,y}。
二分匹配 (Bipartite Matching)
- 模型一次会输出多个预测框 { b 1 , y 1 } , { b 2 , y 2 } , … , { b N , y N } \{b_1, y_1\}, \{b_2, y_2\}, \dots, \{b_N, y_N\} {b1,y1},{b2,y2},…,{bN,yN} (其中 N N N 是模型预测框的数量)。但图片中只有一个真实的目标框 b t g t b_{tgt} btgt。怎么知道哪个预测框对应的是这个真实目标呢?
- 二分匹配就是用来解决这个问题的。它会找到一个最佳的匹配方式,将模型的预测框与真实的目标框(或“无目标”这个类别)一一对应起来。这样,我们才能知道应该用哪个预测框 b b b 和哪个预测置信度 y y y 去和真实的 b t g t b_{tgt} btgt 和 y t g t y_{tgt} ytgt 计算损失。
主要损失 L d e t \mathcal{L}_{det} Ldet:检测损失
- 这是用来衡量模型最终预测(也就是 Grounding Head 输出的 { b , y } \{b, y\} {b,y})与地面真实目标 { b t g t , y t g t } \{b_{tgt}, y_{tgt}\} {btgt,ytgt} 之间的差异。它由三部分组成:
- L i o u ( b g t , b ) \mathcal{L}_{iou}(b_{gt}, b) Liou(bgt,b):GIoU 损失。衡量预测框 b b b 和真实框 b g t b_{gt} bgt 的重叠程度和相对位置。越接近,损失越小。这有助于模型预测出更准确的框的位置和形状。
- ∣ ∣ b g t − b ∣ ∣ L 1 ||b_{gt} - b||_{L1} ∣∣bgt−b∣∣L1:L1 损失。直接计算预测框坐标和真实框坐标之间的绝对差值之和。也是用来惩罚框位置和大小的偏差。
- L c e ( y g t , y ) \mathcal{L}_{ce}(y_{gt}, y) Lce(ygt,y):交叉熵损失。衡量预测置信度 y y y 和真实置信度 y t g t y_{tgt} ytgt 之间的差异。如果模型预测的置信度与真实情况(比如,被匹配到真实目标时预测高分,未匹配到时预测低分)相符,损失就小。
- 公式中的 λ i o u , λ L 1 , λ c e \lambda_{iou}, \lambda_{L1}, \lambda_{ce} λiou,λL1,λce 是权重,用来调整这三部分损失在总损失中的重要性。
辅助损失 L a u x \mathcal{L}_{aux} Laux
- 作用: 主要损失 L d e t \mathcal{L}_{det} Ldet 只监督模型最后的输出。但这个模型有很多中间层(特别是 QA 模块),这些中间层也在处理信息并生成查询。辅助损失的作用就是给这些中间层的输出也提供监督信号。
- 为什么需要辅助损失? 如果只看最终结果,中间层可能会学到一些对最终预测没有直接贡献,甚至是有害的东西。通过在中间层也计算一个损失,并让它向着正确方向优化,可以确保模型从早期阶段就开始学习聚焦于目标相关的上下文,使得整个模型的训练过程更稳定、更有效,并可能提升最终性能。
- 具体内容: 论文中提到 L a u x \mathcal{L}_{aux} Laux “类似于上述目标函数”,这意味着可能在每个 QA 模块的输出(或者某种基于 QA 输出的预测)上,也计算一个类似于 L d e t \mathcal{L}_{det} Ldet 的损失,比如预测一个临时的框和置信度,并与地面真实目标进行比较。这强制要求每个 QA 层产生的查询都能更好地指向目标物体。
- λ a u x \lambda_{aux} λaux:辅助损失的权重,用来平衡它与主要损失的重要性。
扩展到密集 Grounding
除了对象级别的 Grounding,我们的方法可以通过加入一个分割头轻松扩展到密集 Grounding 任务。具体来说,类似于 MaskFormer,我们利用 MLP 将目标嵌入 O O O 转换为掩码嵌入 M ∈ R N q × D M \in \mathbb{R}^{N_q \times D} M∈RNq×D。二值掩码预测 s ∈ [ 0 , 1 ] H × W s \in [0, 1]^{H \times W} s∈[0,1]H×W 然后通过掩码嵌入 M M M 和多模态特征图 H m m H_{mm} Hmm 之间的点积计算得到,接着是一个 sigmoid 激活。在训练过程中,我们使用掩码预测损失 (Focal loss 和 Dice loss),其定义如下:
L s e g = λ f o c a l L f o c a l ( s g t , s ) + λ d i c e L d i c e ( s g t , s ) (25) \mathcal{L}_{seg} = \lambda_{focal} \mathcal{L}_{focal}(s_{gt}, s) + \lambda_{dice} \mathcal{L}_{dice}(s_{gt}, s) \tag{25} Lseg=λfocalLfocal(sgt,s)+λdiceLdice(sgt,s)(25)
其中 s g t s_{gt} sgt 表示地面真实掩码。
“密集 Grounding”(Dense Grounding)是一个更精细的任务。它的目标不仅仅是用一个框把目标物体围起来,而是要预测出一个像素级别的掩码(segmentation mask)。这个掩码就像是把目标物体的精确轮廓勾勒出来,指出图片中的每一个像素点是属于目标物体还是背景。
- 增加“分割头”(Segmentation Head): 原来的模型有一个“Grounding Head”,用来预测边界框 b b b 和置信度 y y y。现在为了做分割,模型在 Grounding Head 的位置 又增加了一个专门负责预测分割掩码的模块,就叫做“分割头”。
- 利用“目标嵌入 O O O”: 之前的步骤中,模型通过一系列计算,最后得到了“目标嵌入” O O O 。这些 O O O 是模型对目标物体的高度抽象表示,包含了它认为目标物体可能在哪里、长什么样等信息。现在,这个新的分割头就利用了这些已经学到的目标嵌入 O O O 作为输入。
- 将 O O O 转换为“掩码嵌入” M M M: 分割头里的第一步是使用一个 MLP将目标嵌入 O O O 转换成“掩码嵌入” M M M。这是一个专门为生成掩码而准备的特征表示。虽然 O O O 包含了目标信息,但 M M M 是把这些信息调整和组织成最适合用来预测像素级别掩码的形式。
- 计算掩码预测 s s s: 这是核心步骤。模型通过计算掩码嵌入 M M M 和之前生成的多模态特征图 H m m H_{mm} Hmm 之间的点积(dot product)来得到像素级别的预测 s s s。
- 多模态特征图 H m m H_{mm} Hmm: 这个 H m m H_{mm} Hmm 是融合了图像信息和语言信息的特征图,它保留了图像的空间结构(特征的位置对应图片中的位置)。
- 点积的意义: 点积可以看作是一种相似度计算。模型对每个潜在的目标(对应一个掩码嵌入 M M M),会拿着这个 M M M 和 H m m H_{mm} Hmm 中的每一个像素位置对应的特征计算点积。如果某个像素位置的特征与这个目标对应的掩码嵌入 M M M “很相似”,点积的值就会比较高,说明这个像素很可能属于这个目标物体。反之则点积值低。
- Sigmoid 激活: 点积计算出来的原始值可能很大或很小,通过 sigmoid 函数将其压缩到 [0, 1] 的范围内。这样,每个像素位置的输出值就表示该像素属于目标物体的概率。这就是最终的二值掩码预测 s s s,它的尺寸和原始图像(或某个尺度的特征图)相同( H × W H \times W H×W),每个位置的值代表属于目标的概率。
- 训练时的损失函数 L s e g \mathcal{L}_{seg} Lseg: 既然现在预测的是像素掩码,训练时用来衡量好坏的标准也不同了。不再使用边界框损失,而是使用专门用于分割任务的损失函数。
- 真实掩码 s g t s_{gt} sgt: 这是数据集中为密集 Grounding 任务提供的真实标注,是一个像素级别的图,准确地标出了目标物体的每一个像素。
- 掩码预测损失 L s e g \mathcal{L}_{seg} Lseg: 包括两种常用的分割损失:
- Focal Loss ( L f o c a l \mathcal{L}_{focal} Lfocal): 这种损失函数特别适合处理像素类别不平衡的问题(比如图像中背景像素远多于目标物体像素)。它可以让模型更关注那些难以区分的像素。
- Dice Loss ( L d i c e \mathcal{L}_{dice} Ldice): 这种损失函数衡量预测掩码 s s s 和真实掩码 s g t s_{gt} sgt 之间的重叠程度。重叠得越多,损失越小。
- 总的掩码预测损失 L s e g \mathcal{L}_{seg} Lseg 是这两种损失的加权求和 ( λ f o c a l , λ d i c e \lambda_{focal}, \lambda_{dice} λfocal,λdice 是权重)。训练时,模型会尝试最小化这个 L s e g \mathcal{L}_{seg} Lseg,以便预测的掩码 s s s 尽可能接近真实的 s g t s_{gt} sgt。
总结一下: 扩展到密集 Grounding 并不是重新设计一个模型,而是在原来模型的基础上,利用它已经学到的目标特征 O O O 和多模态融合特征 H m m H_{mm} Hmm,增加一个专门的分割头。这个分割头通过 MLP 将 O O O 变成掩码嵌入 M M M,然后用 M M M 和 H m m H_{mm} Hmm 计算点积来预测像素级别的掩码。同时,训练时改用或增加专门的分割损失来指导模型学习预测准确的像素掩码。本质上,它是复用了模型前面学习到的理解图像和语言的能力,并在这个基础上,通过一个额外的模块和相应的损失函数,将其应用于更精细的像素级别预测任务。
讨论
如图 5 所示,QA 模块中的注意力图展示了参照查询如何捕获目标相关上下文的细化过程。最初,注意力图看起来比较嘈杂,但逐渐聚焦于目标相关上下文,例如图 (a) 中的沙发。通过引入参照查询,解码器中的注意力图准确地集中在目标对象上。此外,需要注意的是,由于 QA 模块中的特征维度较低,参照查询可能不会精确地聚焦在目标对象上,但它仍然捕获了目标相关信息。

在这项工作中,我们的目标是探索如何进一步优化查询的学习过程。为了减少由普通查询带来的学习困难,我们引入了一个简单的查询自适应模块,以自适应地捕获目标相关上下文并迭代地对其进行细化。如图 5 所示,每个查询自适应模块产生的注意力图与我们的目标一致:逐步聚焦于目标相关上下文,并为解码器提供先验上下文。值得注意的是,虽然“多级”、“适配器”和“自注意力”可能在其他研究领域得到广泛应用,但我们的方法旨在整合它们来解决视觉 Grounding 任务中的挑战,而不是设计一个特定的模块来单独实现上述功能。
实验部分
数据集和评估指标
RefCOCO/RefCOCO+/RefCOCOg: RefCOCO [53] 包含 19,994 张图片,其中有 50,000 个参照对象,分为训练集、验证集、testA 集和 testB 集。类似地,RefCOCO+ [53] 包含 19,992 张图片,其中有 49,856 个参照对象和 141,564 个参照表达。与 RefCOCO 相比,它包含更多属性而非绝对位置,并且具有相同的划分。RefCOCOg [31] 包含 25,799 张图片,其中有 49,856 个参照对象和表达。遵循一种常见的划分版本 [32],即训练集、验证集和测试集。
Flickr30k: Flickr30k Entities [33] 包含 31,783 张图片和 158k 个带有 427k 标注短语的字幕。我们按照 [7] 的方法将图片分为 29,783 张用于训练,1000 张用于验证,1000 张用于测试,并在测试集上报告性能。
ReferItGame: ReferItGame [18] 包含 20,000 张图片,其中有 120,072 个参照表达,对应 19,987 个参照对象。我们按照 [7] 的方法将数据集分为训练集、验证集和测试集,并在测试集上报告性能。
评估指标: 对于参照表达理解 (REC),我们使用 Prec@0.5 评估协议来评估准确率,这与之前的工作一致。在这种评估中,如果预测的边界框与其地面真实边界框的 Intersection-over-Union (IoU) 大于 0.5,则认为该预测是正确的。对于参照表达分割 (RES),我们报告预测的分割掩码和地面真实掩码之间的 Mean IoU (MIoU)。
实现设置细节
根据 Transvg(2021年)和Dynamic mdetr(2023年),输入图像的分辨率被调整为 640 × 640。我们使用预训练的 CLIP 作为骨干网络来提取图像和语言特征,并在训练期间冻结其参数。模型使用 AdamW 优化器进行端到端优化,训练 40 个 epoch,批大小为 32。我们将学习率设置为 1e-4,权重衰减设置为 1e-2。实验在 V100 GPU 上进行。损失权重 λ i o u \lambda_{iou} λiou、 λ L 1 \lambda_{L1} λL1、 λ c e \lambda_{ce} λce 和 λ a u x \lambda_{aux} λaux 分别设置为 3.0、1.0、1.0 和 0.1。对于密集 Grounding,我们将参数 λ f o c a l \lambda_{focal} λfocal 和 λ d i c e \lambda_{dice} λdice 分别设置为 5.0 和 1.0。
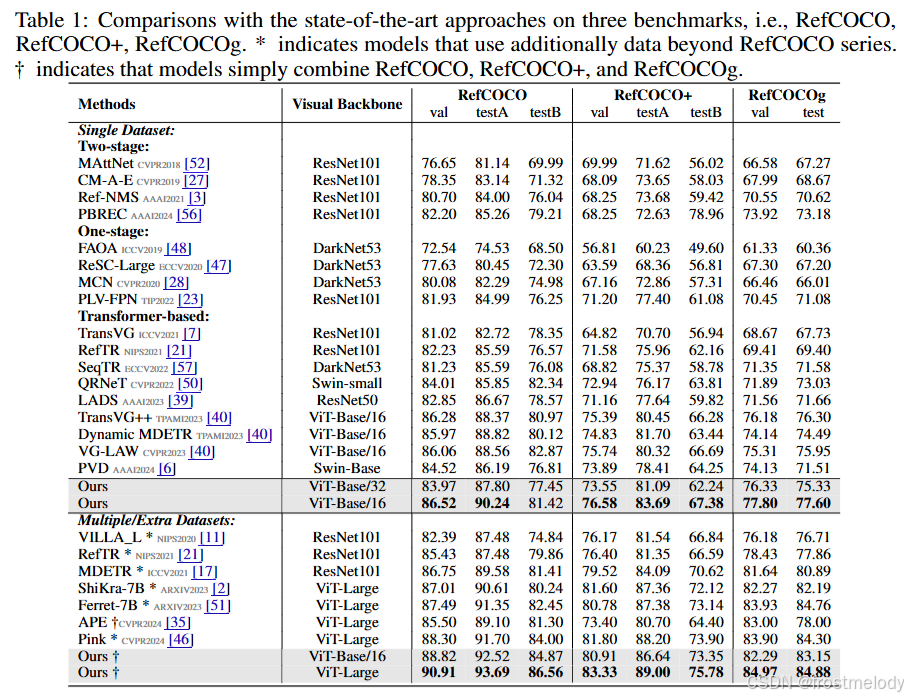
主实验结果
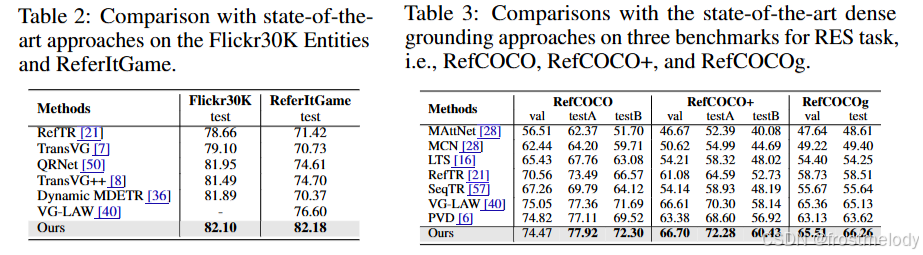
消融实验结果
在 RefCOCOg 数据集上进行消融研究,以验证我们提出的方法中每个部分的有效性。
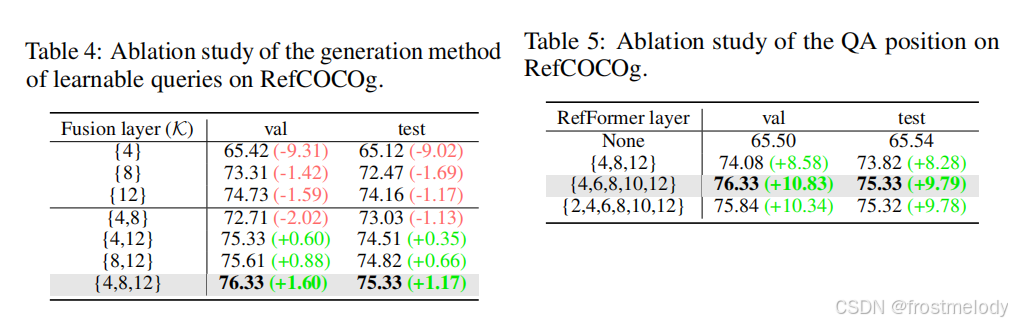
- QA 位置的影响: 如表 5 所示,首先,我们可以观察到移除 QA 会导致性能急剧下降,这表明了 QA 的有效性。然后我们探索了 QA 在 CLIP 中不同位置的影响,以确定 QA 应该放置在哪里进行消融研究:{4, 8, 12} 和 {4, 6, 8, 10, 12},以及 {2, 4, 6, 8, 10, 12}。结果表明,当我们使用 {4, 6, 8, 10, 12} 配置时性能最佳。因此,我们在实验中默认使用此位置。
- 多级融合层的影响: 在表 4 中,我们分析了融合层在解码器中的影响。我们首先进行了只使用单级图像特征的实验,然后进行多级特征的实验。结果表明,利用多级特征显著提高了性能,这表明低级和中级特征对高级特征形成了补充。此外,使用 {4, 8, 12} 实现了最佳性能,这也是我们在实验中采用的配置。
- 辅助损失的影响: 在表 6 的第二行,我们通过有无辅助损失进行实验,结果证明了辅助损失的有效性。通过使用辅助损失,参照查询可以更有效地捕获目标相关的视觉上下文。
- 可学习查询的影响: 在表 6 的第三行,我们验证了可学习查询的有效性。我们用 QA 模块生成的随机初始化查询或自然语言embedding替换了可学习查询,同时保持其他模块不变。我们可以观察到引入先验查询带来了显著的性能提升。这一结果表明,先验查询有助于解码器更准确地定位目标对象。此外,我们研究了参照查询的准确性,它们旨在为解码器提供先验信息。由于 QA 模块的通道维度较低,参照查询可能无法准确预测目标的坐标。
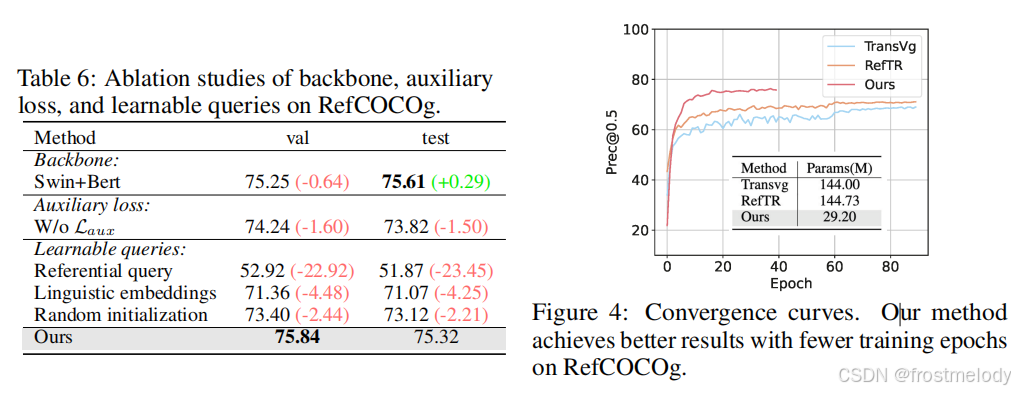
- 收敛曲线: 图 4 展示了我们提出的方法与开源 DETR 类视觉 Grounding 方法的收敛曲线。值得注意的是,我们的方法展示了加速的训练收敛速度,将训练时间缩短了一半,同时性能也优于其他现有方法。
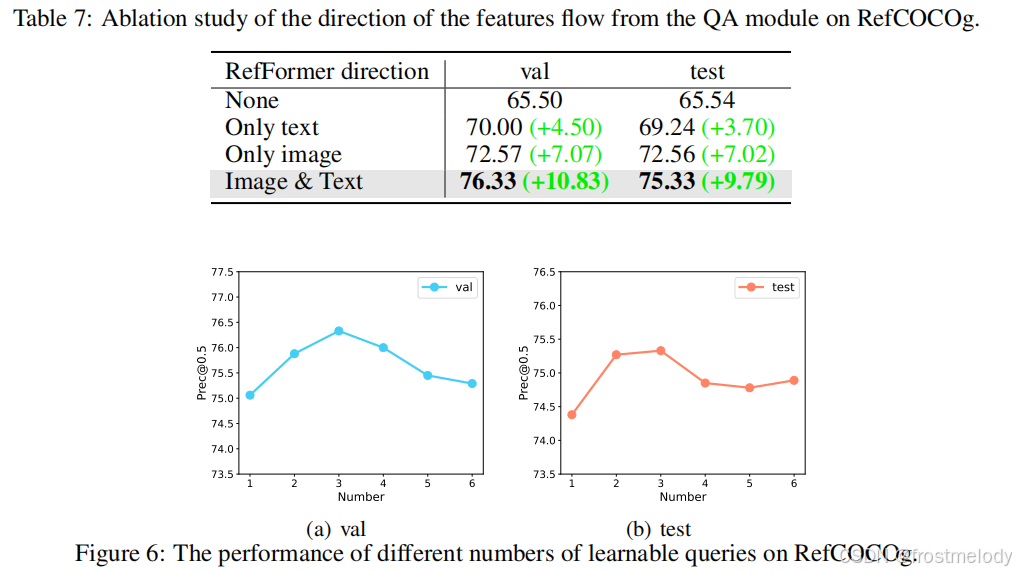
- RefFormer 方向的影响: 在 RefFormer 中,QA 模块可以作为适配器,将特定知识注入到冻结的 CLIP 模型中。在表 7 中,我们研究了 QA 模块的特征流方向。我们发现使用双向方法可以实现最佳性能。通过 QA 模块,语言特征逐步聚合相关的视觉上下文信息。正如 CARIS: Context-aware referring image segmentation 所指出的,将丰富的视觉上下文整合到语言特征中有助于实现强大的视觉-语言对齐,并更好地指示目标对象。
- 可学习查询数量的影响: 我们在图 6 中展示了根据可学习查询数量 N q N_q Nq 的 Prec@0.5 性能。当我们采用 N q = 3 N_q = 3 Nq=3 时,性能最佳。然而,进一步增加只会使指标略有改善,因为大量的 N q N_q Nq 增加了模型的难度。因此,我们在实验中默认将 N q = 3 N_q = 3 Nq=3。
可视化实验
由于篇幅限制,我们在此展示额外的可视化结果。如图 7 所示,参照查询逐渐聚焦于目标对象,并有效地为解码器提供了目标相关的上下文。这些结果证明了我们提出方法的有效性。

总结
总结与讨论
本文提出了一种新颖的方法,称为 RefFormer,它可以无缝地集成到 CLIP 中。RefFormer 不仅可以生成参照查询,为解码器提供与目标相关的上下文,还可以作为适配器,保留 CLIP 的原始知识并降低训练成本。大量的实验证明了我们方法的有效性,可视化结果展示了我们提出的 RefFormer 的细化过程。
局限性: 尽管我们的方法是专门为 REC 任务设计的,并在 REC 中超越了现有的 SOTA(State-Of-The-Art,最新水平)方法,但在 RES 任务方面仍有很大的改进空间。这是因为我们尚未针对 RES 任务对我们的方法进行专门优化。
其他知识附录
附1:在预定义锚框上使用滑动窗口进行密集预测
在一张照片里找到所有的猫。你并不知道猫可能在哪里,也不知道猫是大是小,是躺着(长宽比大)还是蹲着(长宽比接近1:1)。
传统两阶段目标检测框架通常包括候选区域生成阶段(Region Proposal Stage)和目标分类与定位阶段(Detection Stage)。在第一阶段,模型使用如选择性搜索(Selective Search)或区域建议网络(Region Proposal Network, RPN)等方法,从整幅图像中快速生成一组具有较高目标可能性的候选区域(Region Proposals)(即坐标、置信度分数(objectness score):表示该区域包含某种目标的可能性;锚框(anchor boxes)索引:表示该候选框是从哪个预设锚框偏移出来的)),这些区域可能包含目标物体的轮廓或结构特征。在第二阶段,检测器对这些候选区域进行进一步的特征提取与分类,同时回归出更精确的目标边界框,从而实现目标的最终识别与定位。
“单阶段 + 锚框 + 滑动窗口 + 密集预测”的方法:
与两阶段方法不同,检测器只经过一次前向传播,直接输出最终结果(边界框 + 类别),无需候选区域生成。
每个特定位置预设多个不同尺寸与长宽比的框,称为锚框(anchors)或默认框(default boxes),模型需要为每个锚框预测:
- 是否包含目标(分类分支)
- 如果有,目标类别是什么
- 该锚框需要偏移多少才能拟合真实目标(回归分支)
- 类似于每个锚框都问:“如果我这里有个物体,我该变成什么形状、属于哪一类?”
-
预定义锚框 (Pre-defined Anchor Boxes):
- 不同大小和形状的矩形框(比如一个小的正方形模板,一个大的正方形模板,一个高的长方形模板,一个宽的长方形模板等等)。
- 在开始找猫之前,你先把这些模板密密麻麻地铺满整张照片。你可以在照片上每隔一定的距离(比如每10个像素)就放一套这样的模板。所以整张照片上会有非常多非常多的、各种大小和形状的模板框。这些就是“预定义锚框”。 因为对象的大小和形状变化很大,提前准备好各种可能的尺寸和比例,是为了能“套住”各种不同的对象。
-
滑动窗口 (Sliding Window):
- 虽然实现上是卷积网络全图处理,但本质上可以看作在特征图上以滑动窗口的方式遍历每个位置,并在这些位置做预测:
- 每个位置相当于一个小区域(感受野)在“观察图像”
- 每个区域对应多个锚框,每个锚框输出一组预测
-
密集预测 (Dense Predictions):
- 当这个“滑动窗口”或者说网络的处理区域移动到图片上的某个位置时,它会同时检查覆盖在这个位置上的所有预定义锚框。
- 对于这个位置上的每一个预定义锚框,网络都会进行预测:
- 预测 1: 这个锚框里有没有我们要找的对象(比如猫)?如果有,它是猫的概率有多大?
- 预测 2: 如果里面有猫,这个锚框的位置和大小需要调整多少,才能更精确地框住这只猫?
- 因为这个检查和预测过程发生在图片上所有被锚框覆盖的位置,并且在每个位置都要检查所有预设的锚框,所以产生的预测结果数量非常庞大,几乎覆盖了图片上的每一个角落和各种可能的形状。这就是“密集预测”。典型的做法是在不同层级的特征图上进行预测(多尺度特征融合,如 FPN)。换句话说,相比于“精挑细选”候选框,两阶段方法的“少量精看”,单阶段是“眼睛到处看,每个地方都问一句”。
- 做什么? 就是在图片上密密麻麻地放一堆各种大小形状的模板(锚框),然后网络系统地(通过滑动窗口的方式)检查图片上的每一个地方,对于每个地方的每一个模板,都预测一下“这里有没有猫,这个模板需要怎么改才能准确框住猫”。
- 为什么要这么做?
- 系统地搜索: 这种方法的好处在于它非常系统和全面。通过预设各种尺寸和比例的锚框并检查图片上的每一个位置,它几乎穷尽了对象可能出现的所有位置和大小的可能性。
- 单阶段: 相比于需要先找候选区域的两阶段方法,这种方法将“找可能区域”和“判断是不是对象并精修”合并成了一个步骤,通常可以更快一些,流程也更简单。
| 特性 | 两阶段(Faster R-CNN) | 单阶段(YOLO/SSD) |
|---|---|---|
| 检测速度 | 慢(多阶段) | 快(端到端) |
| 检测精度 | 高(尤其是小目标) | 相对略低 |
| 推理复杂度 | 高 | 低 |
| 工程部署 | 相对复杂 | 更轻量、适合实时场景 |
局限性:
这种方法有个缺点:它主要是在处理局部信息(看每个小窗口里的锚框),很难有效地理解对象之间的关系(比如猫和椅子是“坐”的关系,两只猫是“挨着”的关系),或者对象与大背景的联系。在视觉定位任务中,语言描述常常包含这些复杂的对象关系,如果方法不能理解这些关系,就很难准确地找到指定的对象,所以性能会受到影响,被称为“次优”。而像 DETR 那样不依赖锚框,使用全局注意力机制的方法,就更容易捕捉到这些复杂的关系。
附2:注意力池化(Attention Pooling)
注意力池化就像一个“智能”的筛选器,它会“阅读”序列中的所有向量,然后根据每个向量的内容判断它的重要性,最后把它们“混合”起来,但重要的向量在混合中占的比例更高。
注意力池化是一种加权平均的方法,用来将一个包含多个向量的序列(比如语言编码器输出的每一个词元的上下文嵌入向量序列)压缩成一个单一的固定长度向量。它的核心思想是:不是简单地平均所有向量,而是学习给序列中不同的向量分配不同的重要性权重,然后根据这些权重进行加权求和。
为什么需要它?
当你有一系列向量(比如,句子中每个词经过编码后的向量),你想用一个单一的向量来代表整个序列的意义。简单的做法可以是取平均值或最大值(这就是前面提到的平均池化和最大池化)。但这样做的缺点是,它们对序列中的所有元素一视同仁(平均池化)或者只关注最突出的元素(最大池化),无法灵活地根据上下文或任务需求来动态地决定哪些元素更重要。
注意力池化解决了这个问题,它让模型自己学习去“注意”序列中哪些部分更关键,从而在生成最终表示时给予这些关键部分更高的权重。
具体是如何做的?
假设我们有一个由 n n n 个向量组成的输入序列 H = [ h 1 , h 2 , . . . , h n ] H = [h_1, h_2, ..., h_n] H=[h1,h2,...,hn],其中 h i h_i hi 是序列中第 i i i 个元素的向量表示(比如第 i i i 个词的上下文嵌入)。注意力池化生成一个输出向量 O O O 的过程如下:
-
计算每个向量的“得分” (Scoring):
- 对于序列中的每一个向量 h i h_i hi,通过一个小型的神经网络层(通常是一个全连接层)计算出一个标量值 s i s_i si。这个 s i s_i si 可以被看作是 h i h_i hi 对于最终表示的原始重要性得分。
- 这个计算过程可以简单表示为: s i = score ( h i ) s_i = \text{score}(h_i) si=score(hi)。 score \text{score} score 函数通常包含一些可学习的权重和偏置。一个常见的形式是先进行线性变换和非线性激活,再映射到单个得分: s i = v T tanh ( W h i + b ) s_i = v^T \text{tanh}(W h_i + b) si=vTtanh(Whi+b),其中 W , b , v W, b, v W,b,v 都是模型需要学习的参数。
-
将得分转换为“注意力权重” (Normalizing Scores into Attention Weights):
- 原始得分 s 1 , s 2 , . . . , s n s_1, s_2, ..., s_n s1,s2,...,sn 的值范围是不定的,也不能直接作为权重。我们需要将它们转换成一组正数,并且这些正数加起来等于 1。
- 这通常通过 Softmax 函数来实现。Softmax 函数会将所有得分进行指数化,然后除以它们的总和,得到每个向量的注意力权重 α i \alpha_i αi:
α i = exp ( s i ) ∑ j = 1 n exp ( s j ) \alpha_i = \frac{\exp(s_i)}{\sum_{j=1}^{n} \exp(s_j)} αi=∑j=1nexp(sj)exp(si) - 这样得到的 α i \alpha_i αi 就是归一化后的注意力权重。 α i \alpha_i αi 值越大,说明对应的向量 h i h_i hi 越重要。
-
进行加权求和 (Weighted Sum):
- 最后,用计算出的注意力权重 α i \alpha_i αi 对原始输入向量 h i h_i hi 进行加权求和,得到最终的输出向量 O O O:
O = ∑ i = 1 n α i h i O = \sum_{i=1}^{n} \alpha_i h_i O=i=1∑nαihi - 这个输出向量 O O O 就是通过注意力机制从整个序列中提取出的固定长度的表示,它倾向于包含那些被赋予更高注意力权重的向量的信息。
- 最后,用计算出的注意力权重 α i \alpha_i αi 对原始输入向量 h i h_i hi 进行加权求和,得到最终的输出向量 O O O:
优势:
- 可学习性: 模型的神经网络会学习如何计算得分 s i s_i si,这意味着模型可以根据训练任务的需要,自动学习哪些输入向量(比如句子中的哪些词)是更重要的。
- 动态性: 注意力权重是根据当前的输入序列动态计算的,同一个词在不同句子中的重要性可能不同,模型能够捕捉这种差异。
- 更好的表示能力: 生成的固定长度向量 O O O 能够更精确地反映序列中最重要的信息,从而比简单的平均或最大池化有更强的表示能力。