强化学习基础
强化学基本概念
1.1 相关名词
1.Action Space 可以选择的动作: {left,right,up,down}
2.Policy 策略函数:输入 State,输出在这个 State 下执行 Action 的条件概率,一般用 π 来表示
π ( l e f t ∣ s t ) = 0.1 π ( u p ∣ s t ) = 0.2 π ( r i g h t ∣ s t ) = 0.7 \begin{array}{l} \pi\left(l e f t \mid s_{t}\right)=0.1 \\ \pi\left(u p \mid s_{t}\right)=0.2 \\ \pi\left(r i g h t \mid s_{t}\right)=0.7 \end{array} π(left∣st)=0.1π(up∣st)=0.2π(right∣st)=0.7
policy 的表达式为:
π θ ( τ ) = π ( s 1 ) π θ ( a 1 ∣ s 1 ) π ( s 2 ∣ s 1 , a 1 ) π θ ( a 2 ∣ s 2 ) π ( s 3 ∣ s 2 , a 2 ) ⋯ = π ( s 1 ) ∏ t = 1 T π θ ( a t ∣ s t ) π ( s t + 1 ∣ s t , a t ) \begin{array}{l} \pi _{\theta}(\tau) \\ \quad=\pi\left(s_{1}\right) \pi_{\theta}\left(a_{1} \mid s_{1}\right) \pi\left(s_{2} \mid s_{1}, a_{1}\right) \pi_{\theta}\left(a_{2} \mid s_{2}\right) \pi\left(s_{3} \mid s_{2}, a_{2}\right) \cdots \\ \quad=\pi\left(s_{1}\right) \prod_{t=1}^{T} \pi_{\theta}\left(a_{t} \mid s_{t}\right) \pi\left(s_{t+1} \mid s_{t}, a_{t}\right) \end{array} πθ(τ)=π(s1)πθ(a1∣s1)π(s2∣s1,a1)πθ(a2∣s2)π(s3∣s2,a2)⋯=π(s1)∏t=1Tπθ(at∣st)π(st+1∣st,at)
τ \tau τ 代表状态-动作轨迹, s1 为初始状态的概率, π θ ( s 2 ∣ s 1 , a 1 ) \pi_{\theta}\left(s_{2} \mid s_{1},a_{1}\right) πθ(s2∣s1,a1) 代表在某种策略下在 s1 状态,执行 a1 动作最终跳转到 s2 状态的概率
3.Trajectory 轨迹,一连串状态和动作的序列:{s0,a0,s1,a1…}
有时 s t + 1 s_{t+1} st+1 的值是确定的,比如大语言模型,输入不变输出结果是一样的,有时 s t + 1 s_{t+1} st+1 的状态是服从概率分布的
s t + 1 = f ( s t , a t ) s t + 1 = P ( ⋅ ∣ s t , a t ) \begin{array}{l} s_{t+1}=f\left(s_{t}, a_{t}\right)\\ s_{t+1}=P\left(\cdot \mid s_{t}, a_{t}\right) \end{array} st+1=f(st,at)st+1=P(⋅∣st,at)
4.Return 汇报:从当前时间点到游戏结束的 Reward 总和
其中 Reward 和 Action 是已知的
R ˉ θ = ∑ τ R ( τ ) p θ ( τ ) = E τ ∼ p θ ( τ ) [ R ( τ ) ] \bar{R}_{\theta}=\sum_{\tau} R(\tau) p _{\theta}(\tau)=E_{\tau \sim p_{\theta}(\tau)}[R(\tau)] Rˉθ=τ∑R(τ)pθ(τ)=Eτ∼pθ(τ)[R(τ)]
上面的公式如何理解

5.策略梯度
通过上面的步骤可以看出,我们的目的是希望训练一个 θ 使得 R 的期望是最大的,所以这里使用梯度上升方法
∇ R ˉ θ = ∑ τ R ( τ ) ∇ p θ ( τ ) \nabla \bar{R}_{\theta}=\sum_{\tau} R(\tau) \nabla p_{\theta}(\tau) ∇Rˉθ=τ∑R(τ)∇pθ(τ)
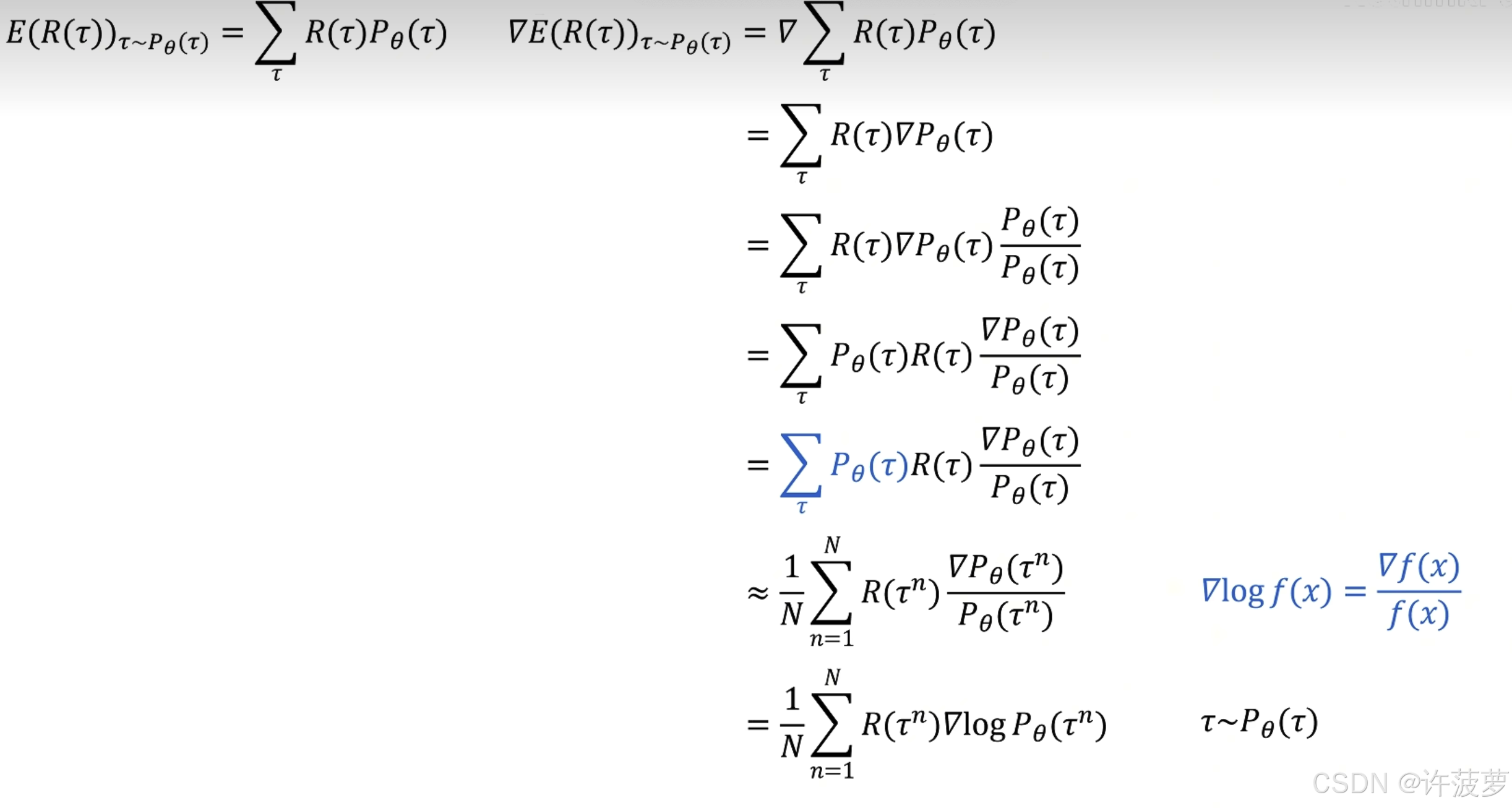
这张图说明了当 R >0 那么就会增加在该状态下执行该动作的概率,如果 R <0 就会减小在该状态下执行该动作的概率。
策略梯度的损失函数:
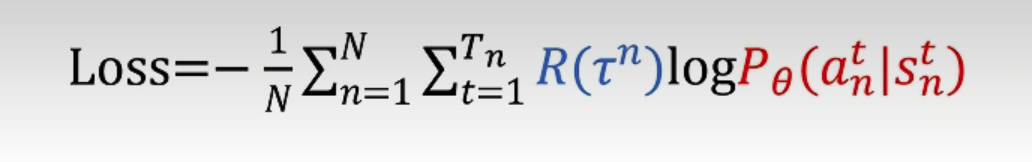
1.2 需要添加的 Tips
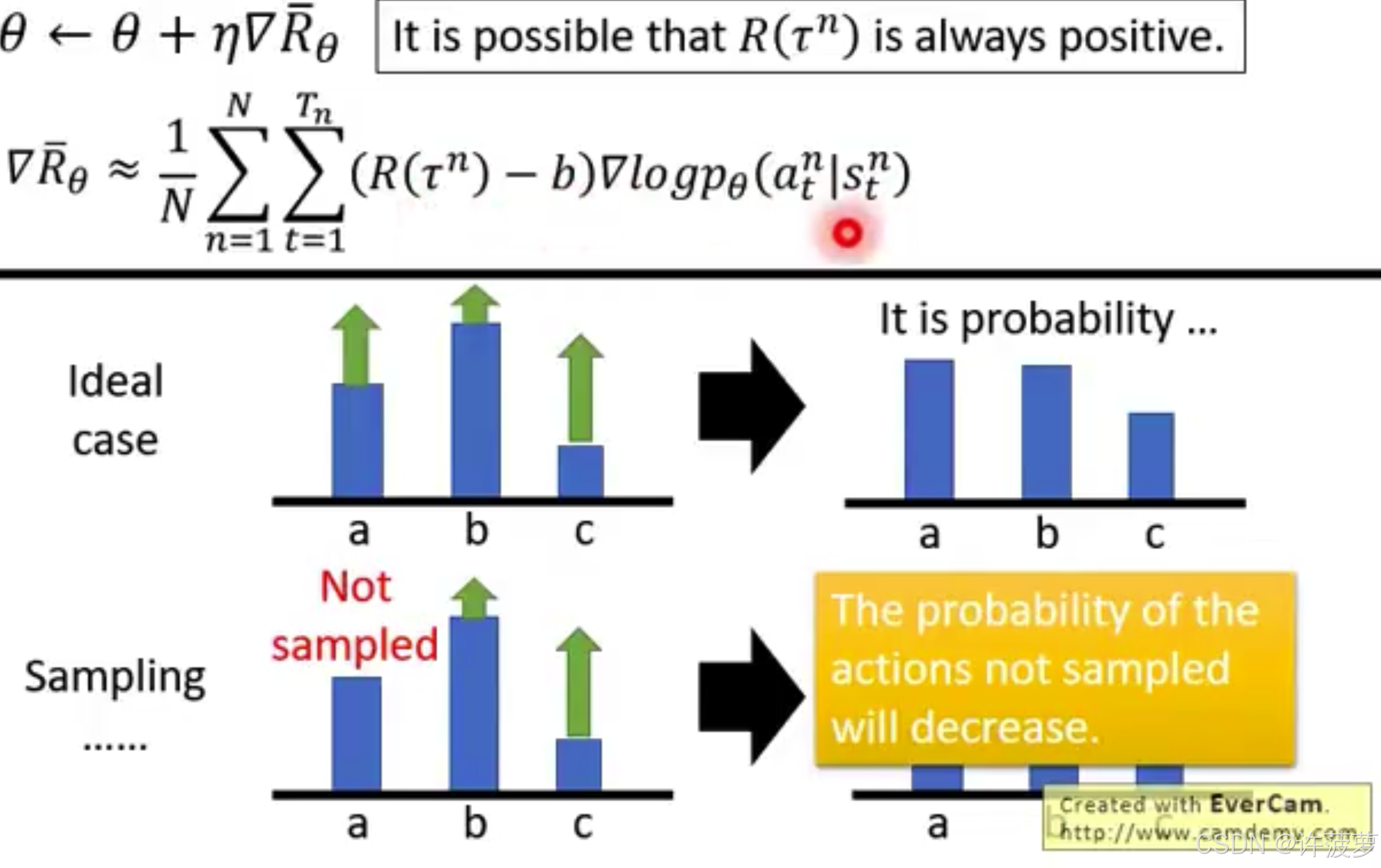
1.2.1 Add Baseline
在很多游戏中 Reward 是 >0 的,在正常情况下,对于更有效的步数它的概率会更大,但是在训练过程中,我们是进行采样计算的,也就是对于一些没有采样的数据它的概率会更小,但这并不是因为它不有效,所以为了区分在 Reward 是 >0 时哪个 action 更有效,让无效的 action 的 probability < 0 ,所以给 Reward - b 造成负数情况
∇ R ˉ θ ≈ 1 N ∑ n = 1 N ∑ t = 1 T n ( R ( τ n ) − b ) ∇ log p θ ( a t n ∣ s t n ) b ≈ E [ R ( τ ) ] \nabla \bar{R}_{\theta} \approx \frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_{n}}\left(R\left(\tau^{n}\right)-b\right) \nabla \log p_{\theta}\left(a_{t}^{n} \mid s_{t}^{n}\right) \quad b \approx E[R(\tau)] ∇Rˉθ≈N1n=1∑Nt=1∑Tn(R(τn)−b)∇logpθ(atn∣stn)b≈E[R(τ)]
1.2.2 Assign Suitable Credit
在多个 trajectory 中,某一个 trajectory 的 Return 高不代表这个 trajectory 中每一个 (s,a) 都是高 Reward 的, 如下图所示, (sb,a2) 
的 Reward 为 0 ,第一个 trajectory 的 Return 为 +3,不代表 (sb,a2) 就是有效的,但是在 trajectory 1 中会对所有的 (s,a) 乘一个较高的系数。在第二个 trajectory 中由于最终的 Return 并不理想所以给相同的 (sb,a2) 乘了一个 -7 的系数
所以在这里不再将所有 Reward 的总和 R(n) 作为评价一个 action 的 probability ,而是将从该动作及该动作之后的所有动作的 Reward 作为该动作的 probability ,并且在该步骤越后面的 state 它的贡献就越小,那么最后公式变为:
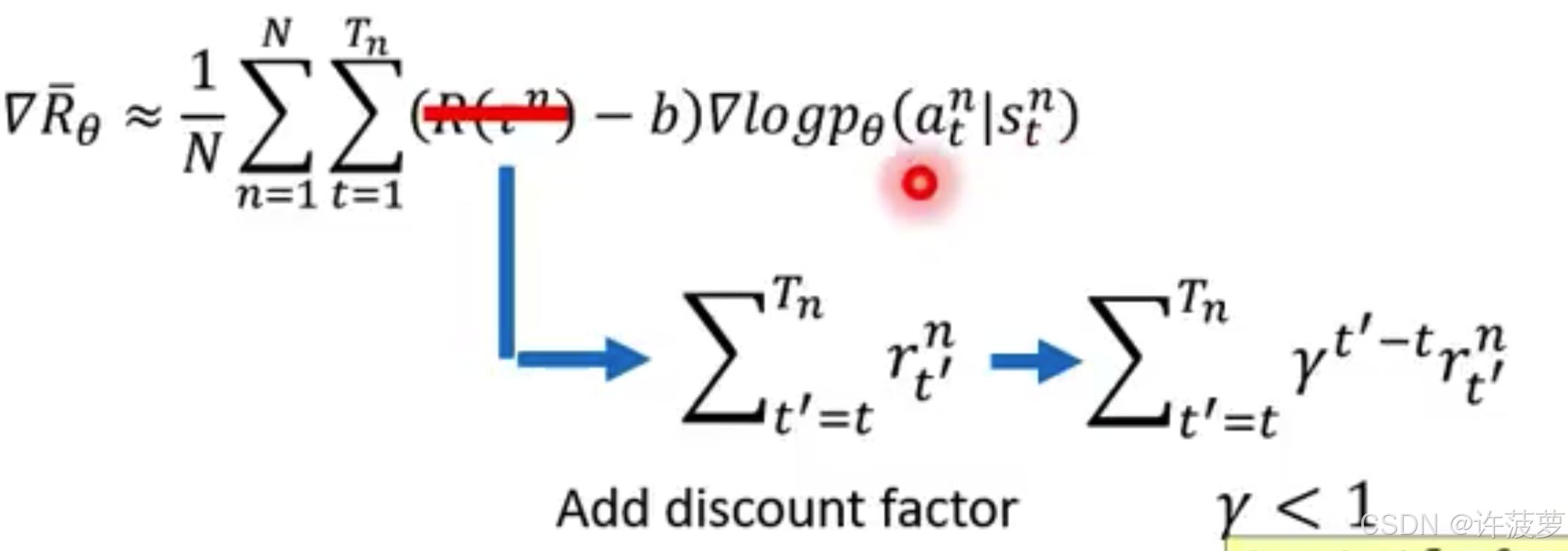
R t n = ∑ t ′ = t T n γ t ′ − t r t ′ n R_t^n = \sum_{t'=t}^{T_n} \gamma^{t'-t} r_{t'}^n Rtn=t′=t∑Tnγt′−trt′n
r t ′ n r_{t'}^n rt′n 代表在第 n 个回合时间 t ′ t' t′ 上的奖励,这个也是最终我们要求的东西
γ t ′ − t \gamma^{t'-t} γt′−t 代表该奖励的系数, γ \gamma γ 是衰减系数,随着时间越靠后衰减系数越大
1.3 on/off policy

行为策略(behavior policy),行为策略是一个选择 action 的策略,行为策略通常是探索性的,因为智能体需要在环境中采取不同的行动,告诉 agent 如何选择动作。
目标策略(target policy),在行为策略产生的数据中不断学习,训练,最终生成可以应用的策略,也就是如何让 Return 最大化,
On-policy 方法:要求智能体学习和优化的是当前正在执行的策略。也就是说,用于生成数据的策略(行为策略)和需要优化的策略(目标策略)是同一个策略
举个例子:
假如我是一名老师,我的目标是让班级中的同学成绩越来越好。如果是 on-policy 的方法,对于小明我会使用一种方式教导他,对于小红我需要重新调整策略训练小红,因为小明和小红完全不一样的状况(处在不同概率分布),这样训练比较麻烦,对于不同情况的数据重新更新网络
Off-policy 方法:智能体通过行为策略来进行探索,目标策略则是基于这些探索来进行评估和优化的
假如我是一名老师,我的目标是让班级中的同学成绩越来越好。如果是 off-policy 的方法,在训练小红是会根据小明和小红之间的差距(概率分布上的差距)对训练小红的方式进行调整,而不是重新去训练小红
由上图所示,在 on-policy 这种方法中存在一个缺点,由于行为策略和目标策略 (π(θ)) 是相同的,在一个实验(Episode) 之后 θ 会进行更新,那么我们行为策略中采样策略也会更新,在下一轮 Episode 又会对数据进行重新的采样训练
1.4 重要采样
求 f(x) 的期望值公式为 :
E x ∼ p ( x ) [ f ( x ) ] = ∑ x f ( x ) ⋅ p ( x ) \mathbb{E}_{x \sim p(x)}[f(x)] = \sum_{x} f(x) \cdot p(x) Ex∼p(x)[f(x)]=x∑f(x)⋅p(x)
p(x) 为 f(x) 的概率分布,p(x) 为在某种采样环境下的概率分布。以拟合轨迹的例子来说,所有场景下的轨迹表示函数为 f(x) = x,x~p(x),p(x) 往往是正态分布。但是现实生活中轨迹的概率分布要复杂的多,很难得到所有数据的 p(x) ,比如弯道,十字路口等,所以 q(x) 代表 x 在某种采样状态下的概率分布
通过下图可以看到,我们可以用 x~q(x) 的这组数据进行采样, 用 p ( x ) q ( x ) \frac{p(x)}{q(x)} q(x)p(x) 作为这组数据对于期望的权重
E x ∼ p ( x ) [ f ( x ) ] = ∑ x f ( x ) ⋅ p ( x ) = ∑ x f ( x ) ⋅ p ( x ) ⋅ q ( x ) q ( x ) (引入重要性权重) = ∑ x f ( x ) ⋅ p ( x ) q ( x ) ⋅ q ( x ) = E x ∼ q ( x ) [ f ( x ) ⋅ p ( x ) q ( x ) ] (重要性采样) \begin{aligned} \mathbb{E}_{x \sim p(x)}[f(x)] &= \sum_x f(x) \cdot p(x) \\ &= \sum_x f(x) \cdot p(x) \cdot \frac{q(x)}{q(x)} \quad \text{(引入重要性权重)} \\ &= \sum_x f(x) \cdot \frac{p(x)}{q(x)} \cdot q(x) \\ &= \mathbb{E}_{x \sim q(x)}\left[f(x) \cdot \frac{p(x)}{q(x)}\right] \quad \text{(重要性采样)} \end{aligned} Ex∼p(x)[f(x)]=x∑f(x)⋅p(x)=x∑f(x)⋅p(x)⋅q(x)q(x)(引入重要性权重)=x∑f(x)⋅q(x)p(x)⋅q(x)=Ex∼q(x)[f(x)⋅q(x)p(x)](重要性采样)
1.5 GAE 优势函数
1.动作价值函数
R t n R_t^{n} Rtn 每次都是一次随机采样,方差大,训练不稳定
Q θ ( s , a ) Q_θ(s,a) Qθ(s,a) 代表在 state 下做出动作 a 得到回报的期望,称作动作价值函数
以马里奥这个游戏来说得到的回报 R R R 依靠每一步的动作-状态的回报,采样比较随机,如果某一个动作或者某一个状态没有被采样到就会导致训练不稳定
所以需要得到回报的期望 Q Q Q 降低不稳定
2.状态价值函数
V θ ( s ) V_{θ}(s) Vθ(s) 代表在 state 下获取的回报的期望,称作状态价值函数
G t G_{t} Gt 是从时间步 t 开始直到终止的回报之和:
G t = R t + 1 + γ R t + 2 + ⋯ + γ T − 1 R T G_t = R_{t+1} + \gamma R_{t+2} + \cdots + \gamma^{T-1} R_T Gt=Rt+1+γRt+2+⋯+γT−1RT
在策略确定的情况下存在等式:
V θ ( s t + 1 ) = E a ∼ π [ Q θ ( s t + 1 , a ) ] V_{\theta}\left(s_{t+1}\right)=E_{a \sim \pi}\left[Q_{\theta}\left(s_{t+1}, a\right)\right] Vθ(st+1)=Ea∼π[Qθ(st+1,a)]
3.优势函数
优势函数计算在某个 state 下执行动作 a ,相比于其他动作可以带来多少优势
A θ ( s , a ) = Q θ ( s , a ) − V θ ( s ) A_\theta(s, a) = Q_\theta(s, a) - V_\theta(s) Aθ(s,a)=Qθ(s,a)−Vθ(s)
那么就可以将目标函数中的 R R R 替换为优势函数 A A A
∇ θ J ( θ ) = 1 N ∑ n = 1 N ∑ t = 1 T n A θ ( s n t , a n t ) ∇ θ log π θ ( a n t ∣ s n t ) \nabla_\theta J(\theta) = \frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_n} A_\theta(s_n^t, a_n^t) \nabla_\theta \log \pi_\theta(a_n^t | s_n^t) ∇θJ(θ)=N1n=1∑Nt=1∑TnAθ(snt,ant)∇θlogπθ(ant∣snt)
将优势函数转换为价值函数表达:
Q θ ( s t , a ) = r t + γ ⋅ V θ ( s t + 1 ) Q_\theta(s_t, a) = r_t + \gamma \cdot V_\theta(s_{t+1}) Qθ(st,a)=rt+γ⋅Vθ(st+1)
A θ ( s t , a ) = r t + γ ⋅ V θ ( s t + 1 ) − V θ ( s t ) A_\theta(s_t, a) = r_t + \gamma \cdot V_\theta(s_{t+1}) - V_\theta(s_t) Aθ(st,a)=rt+γ⋅Vθ(st+1)−Vθ(st)
对优势函数进行多次采样:
A θ 1 ( s t , a ) = r t + γ V θ ( s t + 1 ) − V θ ( s t ) A θ 2 ( s t , a ) = r t + γ r t + 1 + γ 2 V θ ( s t + 2 ) − V θ ( s t ) A θ 3 ( s t , a ) = r t + γ r t + 1 + γ 2 r t + 2 + γ 3 V θ ( s t + 3 ) − V θ ( s t ) ⋮ A θ T ( s t , a ) = ∑ k = 0 T γ k r t + k − V θ ( s t ) \begin{aligned} A_\theta^1(s_t, a) &= r_t + \gamma V_\theta(s_{t+1}) - V_\theta(s_t) \\ A_\theta^2(s_t, a) &= r_t + \gamma r_{t+1} + \gamma^2 V_\theta(s_{t+2}) - V_\theta(s_t) \\ A_\theta^3(s_t, a) &= r_t + \gamma r_{t+1} + \gamma^2 r_{t+2} + \gamma^3 V_\theta(s_{t+3}) - V_\theta(s_t) \\ &\ \, \vdots \\ A_\theta^T(s_t, a) &= \sum_{k=0}^{T} \gamma^k r_{t+k} - V_\theta(s_t) \end{aligned} Aθ1(st,a)Aθ2(st,a)Aθ3(st,a)AθT(st,a)=rt+γVθ(st+1)−Vθ(st)=rt+γrt+1+γ2Vθ(st+2)−Vθ(st)=rt+γrt+1+γ2rt+2+γ3Vθ(st+3)−Vθ(st) ⋮=k=0∑Tγkrt+k−Vθ(st)
上标 n 代表第一步第二步第 n 步
那么整个过程的优势函数就是将每一步的优势价值进行累加:
A θ G A E ( s t , a ) = ( 1 − λ ) ( A θ 1 + λ A θ 2 + λ 2 A θ 3 + ⋯ ) = ( 1 − λ ) ∑ n = 1 ∞ λ n − 1 A θ n ( s t , a ) \begin{aligned} A_{\theta}^{GAE}(s_t, a) &= (1 - \lambda)\left(A_{\theta}^1 + \lambda A_{\theta}^2 + \lambda^2 A_{\theta}^3 + \cdots\right) \\ &= (1 - \lambda)\sum_{n=1}^{\infty} \lambda^{n-1} A_{\theta}^n(s_t,a) \end{aligned} AθGAE(st,a)=(1−λ)(Aθ1+λAθ2+λ2Aθ3+⋯)=(1−λ)n=1∑∞λn−1Aθn(st,a)
展开后的累加结果为
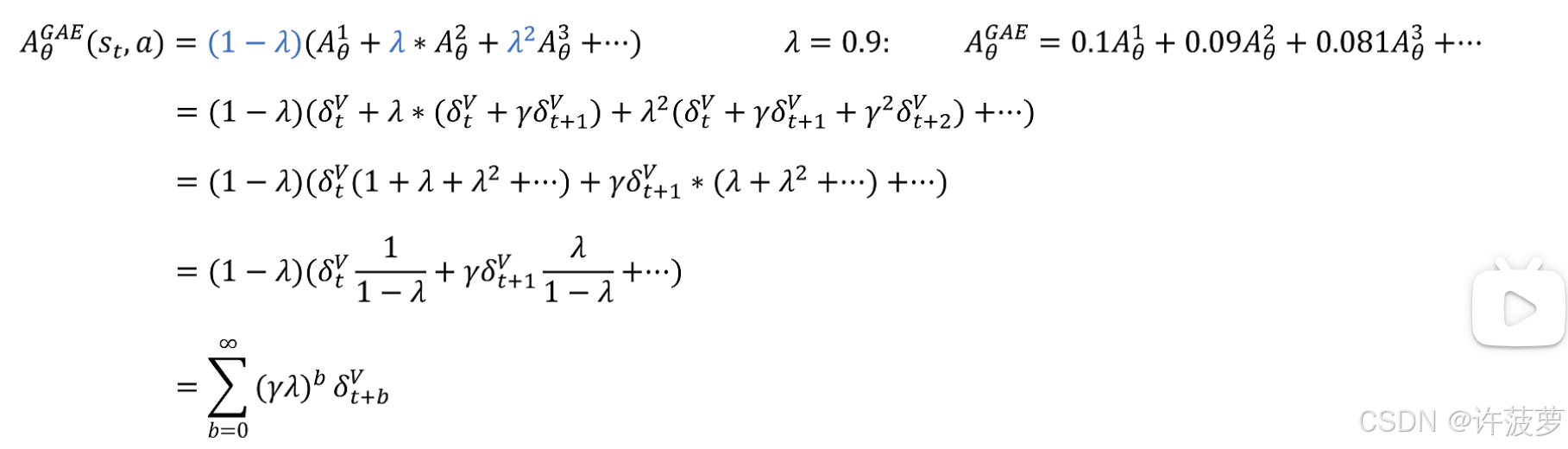
1.6 策略梯度的目标函数
参考文章
Q-learning、DQN 及 DQN 改进算法都是基于价值(value-based)的方法,其中 Q-learning 是处理有限状态的算法,而 DQN 可以用来解决连续状态的问题。在强化学习中,除了基于值函数的方法,还有一支非常经典的方法,那就是基于策略(policy-based)的方法。对比两者,基于值函数的方法主要是学习值函数,然后根据值函数导出一个策略,学习过程中并不存在一个显式的策略;而基于策略的方法则是直接显式地学习一个目标策略。策略梯度是基于策略的方法的基础
基于策略的方法首先需要将策略参数化,假设目标策略 p θ p_{θ} pθ是一个随机性策略,我们可以用一个线性模型或者神经网络模型来为这样一个策略函数建模,输入某个状态,然后输出一个动作的概率分布。
对每条轨迹的概率和每条轨迹的奖励期望如下表示
R ˉ θ = ∑ τ R ( τ ) p θ ( τ ) \bar{R}_{\theta} = \sum_{\tau} R(\tau) p_{\theta}(\tau) Rˉθ=τ∑R(τ)pθ(τ)
我们的目标是要寻找一个最优策略并最大化这个策略在环境中的期望回报。我们将策略学习的目标函数定义为
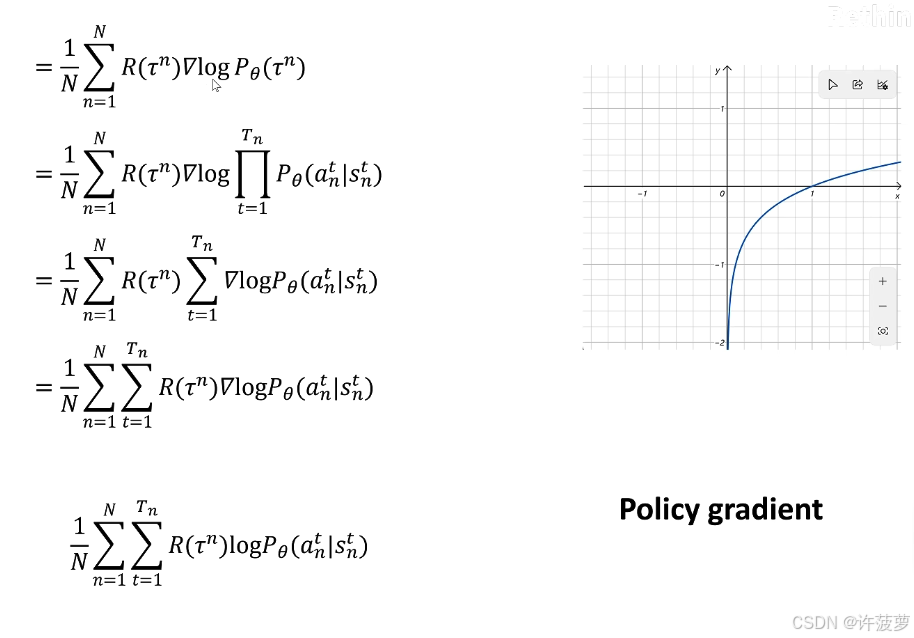
∇ R ˉ θ = ∑ τ R ( τ ) ∇ p θ ( τ ) = ∑ τ R ( τ ) p θ ( τ ) ∇ p θ ( τ ) p θ ( τ ) = ∑ τ R ( τ ) p θ ( τ ) ∇ log p θ ( τ ) = E τ ∼ p θ ( τ ) [ R ( τ ) ∇ log p θ ( τ ) ] ≈ 1 N ∑ n = 1 N R ( τ n ) ∇ log p θ ( τ n ) = 1 N ∑ n = 1 N ∑ t = 1 T n R ( τ n ) ∇ log p θ ( a t n ∣ s t n ) \begin{align*} \nabla \bar{R}_{\theta} &= \sum_{\tau} R(\tau) \nabla p_{\theta}(\tau) \\ &= \sum_{\tau} R(\tau) p_{\theta}(\tau) \frac{\nabla p_{\theta}(\tau)}{p_{\theta}(\tau)} \\ &= \sum_{\tau} R(\tau) p_{\theta}(\tau) \nabla \log p_{\theta}(\tau) \\ &= \mathbb{E}_{\tau \sim p_{\theta}(\tau)} \left[ R(\tau) \nabla \log p_{\theta}(\tau) \right] \\ &\approx \frac{1}{N} \sum_{n=1}^{N} R(\tau^n) \nabla \log p_{\theta}(\tau^n) \\ &= \frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_n} R(\tau^n) \nabla \log p_{\theta}(a_t^n \mid s_t^n) \end{align*} ∇Rˉθ=τ∑R(τ)∇pθ(τ)=τ∑R(τ)pθ(τ)pθ(τ)∇pθ(τ)=τ∑R(τ)pθ(τ)∇logpθ(τ)=Eτ∼pθ(τ)[R(τ)∇logpθ(τ)]≈N1n=1∑NR(τn)∇logpθ(τn)=N1n=1∑Nt=1∑TnR(τn)∇logpθ(atn∣stn)
相当于根据每条轨迹的概率和每条轨迹的奖励计算一个数学期望,最终将求该期望的最大值
1.8 蒙特卡洛策略评估(MC)
参考资料
蒙特卡罗学习是指在不清楚MDP状态转移概率及即时奖励的情况下,直接从经历完整的Episode来学习状态价值,通常情况下某状态的价值等于在多个Episode中以该状态算得到的所有收获的平均。
以走迷宫为例:
尽量穷举所有能走到终点的路径,计算 V(s) 在所有路径中的平均值
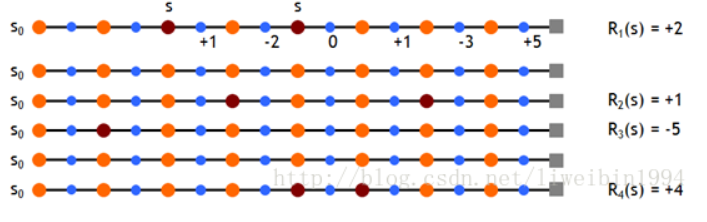
举例:

每次更新 V 时都采用增量计算法,增量计算方法如下:
μ k = 1 k ∑ j = 1 k x j = 1 k ( x k + ∑ j = 1 k − 1 x j ) = 1 k ( x k + ( k − 1 ) μ k − 1 ) = μ k − 1 + 1 k ( x k − μ k − 1 ) \begin{align*} \mu_k &= \frac{1}{k} \sum_{j=1}^{k} x_j \\ &= \frac{1}{k} \left( x_k + \sum_{j=1}^{k-1} x_j \right) \\ &= \frac{1}{k} \left( x_k + (k - 1)\mu_{k-1} \right) \\ &= \mu_{k-1} + \frac{1}{k} (x_k - \mu_{k-1}) \end{align*} μk=k1j=1∑kxj=k1(xk+j=1∑k−1xj)=k1(xk+(k−1)μk−1)=μk−1+k1(xk−μk−1)
μ k \mu_k μk 代表第 k 次样本的期望, x j x_j xj 代表在 j 样本后面的均值,期望可近似于均值,不断地展开后得到上式结果
这里将 x k x_k xk 看做本次轨迹的 G t G_t Gt 将 μ k − 1 \mu_{k-1} μk−1 看做上一轮计算的 V ( s ) V(s) V(s),将 1 k \frac{1}{k} k1 看做系数 α \alpha α 那么通过增量法可得到下面的公式:
V ( S t ) ← V ( S t ) + α ( G t − V ( S t ) ) V(S_t) \leftarrow V(S_t) + \alpha (G_t - V(S_t)) V(St)←V(St)+α(Gt−V(St))
那么最终该条轨迹的 V ( s ) V(s) V(s) 可以使用上面的式子进行更新。那么从根本上讲就是不断的拿期望值(上一次的 V ( s ) V(s) V(s)) 更新真实价值 G ( t ) G(t) G(t) ,从而让这一次计算的期望帧更准确
1.9 时序差分策略评估(TD)
使用蒙特卡洛法更新 V ( t ) V(t) V(t) 时需要将整个 episode 全部走完才能算出来 Gt,但是时序差分用的是离开该状态时的即时奖励与下一个状态的预估状态价值乘以折扣因子组成
因为存在公式:
V ( S t ) = E π [ G t ∣ S t ] V(S_t) = \mathbb{E}_{\pi} \left[ G_t \mid S_t \right] V(St)=Eπ[Gt∣St]
所以当数据稳定时, V ( s t ) V(st) V(st) 是无限接近于 G ( t ) G(t) G(t) 的
那么 G ( t ) G(t) G(t) 就可以近似表达为:
R t + 1 + γ V ( S t + 1 ) R_{t+1} + \gamma V(S_{t+1}) Rt+1+γV(St+1)
最终 V(t) 就可以更新为:
V ( S t ) ← V ( S t ) + α ( R t + 1 + γ V ( S t + 1 ) − V ( S t ) ) V(S_t) \leftarrow V(S_t) + \alpha \left( R_{t+1} + \gamma V(S_{t+1}) - V(S_t) \right) V(St)←V(St)+α(Rt+1+γV(St+1)−V(St))
这里的 V ( s t + 1 ) V(st+1) V(st+1) 代表在第 t 步学习到的 V ( s t + 1 ) V(st+1) V(st+1),而不是上一次采样计算的
PPO
目标函数
这里将策略梯度中奖励换成优势函数:
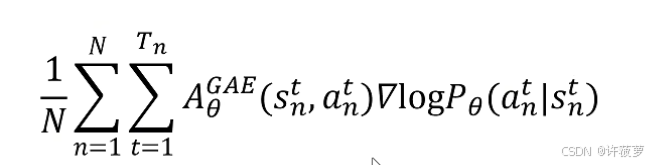
对于网络设计来说,如下图所示,我们训练行为策略和目标策略的参数几乎相同,对于行为策略来说只是在最后一层网络添加行为策略网络
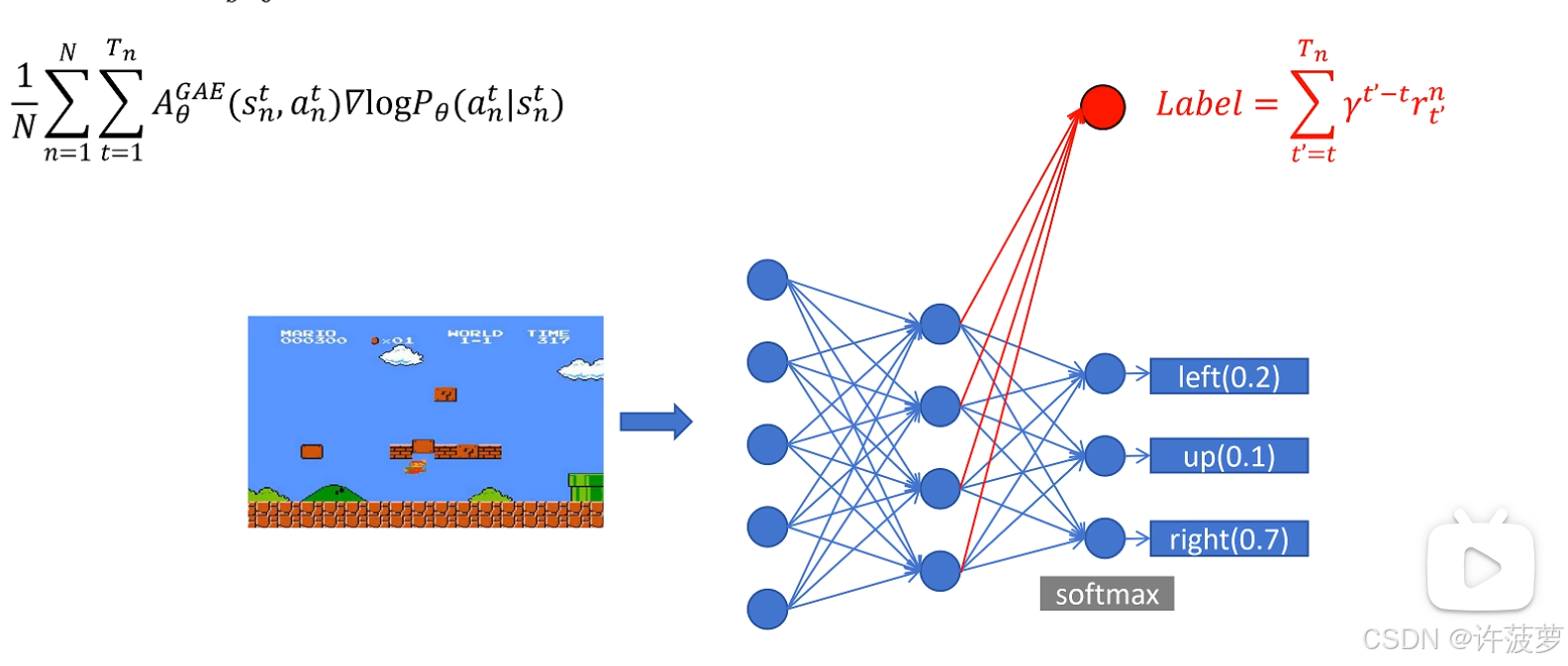
根据前面的重要性采样:
这里使用参考策略 θ ′ \theta' θ′ 进行采样,用他更新训练参数的 θ \theta θ ,这里的 A θ ′ G A E A_{\theta'}^{GAE} Aθ′GAE 可以理解为 “小明” 的优势函数,这里相当于拿训练小明的方式训练整个班级
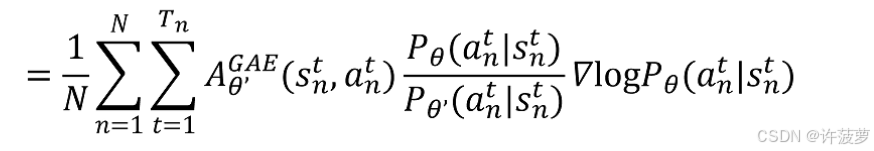
在该公式中重要性采样的系数为: P θ ( a n t ∣ s n t ) P θ ′ ( a n t ∣ s n t ) \frac{P_{\theta}\left(a_{n}^{t} \mid s_{n}^{t}\right)}{P_{\theta^{\prime}}\left(a_{n}^{t} \mid s_{n}^{t}\right)} Pθ′(ant∣snt)Pθ(ant∣snt)
对该公式进行去 log 的计算

同理可以推导出损失函数
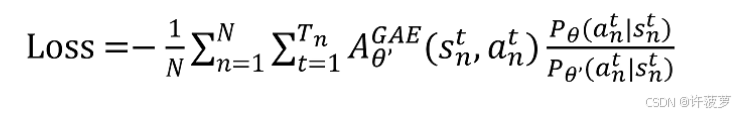
防止参考差距过大
在进行行为策略时需要对该策略加入一个约束,防止参考采样和真实数据分布差距太大,所以这里添加 KL 散度。当两个分布一致时 KL 越小,分布相差越大,KL 越大
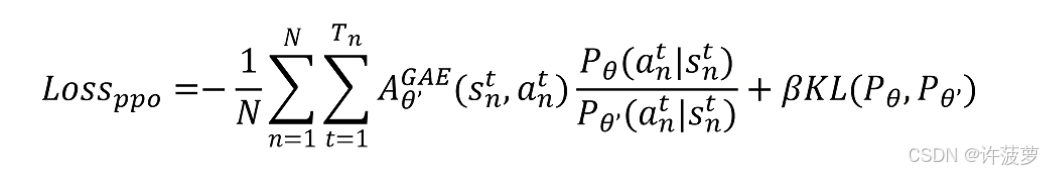
PPO2 使用的是截断函数 clip 代替 KL 散度
在公式的右侧会将重要采样的系数与 (1- ε \varepsilon ε) 和 (1+ ε \varepsilon ε) 之间进行截断,选择中间那个值,这样也有效避免了重要采样系数过大或者过小的现象。这里取最小值也是为了希望 loss 尽可能稳定
Sarsa 方法
该方法就像是将时序差分方法中的 V 替换成了 Q,求状态价值函数
Q ( S t , A t ) ← Q ( S t , A t ) + α [ R t + 1 + γ Q ( S t + 1 , A t + 1 ) − Q ( S t , A t ) ] Q(S_t, A_t) \leftarrow Q(S_t, A_t) + \alpha \left[ R_{t+1} + \gamma Q(S_{t+1}, A_{t+1}) - Q(S_t, A_t) \right] Q(St,At)←Q(St,At)+α[Rt+1+γQ(St+1,At+1)−Q(St,At)]
更新 Q 表格流程:
a.初始化一个 Q 表格
b.对于每一个回合的每一步
- 在状态 S 执行动作 A,进入到状态 S’ 并获得奖励 R
- 基于 Q 表格,通过某种策略,选取要执行的动作 A’
- 基于 Q(S’,A’) 更新 Q(S,A)—>如上面公式
- 在状态 S‘ 执行动作 A’
- …
- 走到终点
c.完成 Q 表格
该方法是一个同策略的方法,因为在状态 S 计算的 A‘ 的动作在下一步一定会执行
Q Learning
Q ( S t , A t ) ← Q ( S t , A t ) + α [ R t + 1 + γ max a Q ( S t + 1 , a ) − Q ( S t , A t ) ] Q(S_{t}, A_{t}) \gets Q(S_{t}, A_{t}) + \alpha \left[ R_{t+1} + \gamma \max_{a} Q(S_{t+1}, a) - Q(S_{t}, A_{t}) \right] Q(St,At)←Q(St,At)+α[Rt+1+γamaxQ(St+1,a)−Q(St,At)]
更新 Q 表格的流程:
a.初始化一个 Q 表格
b.对于每一个回合的每一步
- 在状态 S 执行动作 A,进入到状态 S’ 并获得奖励 R
- 基于 Q 表格,通过某种策略,选取要执行的动作 A’
- 基于 Q(S’) 中的最大值更新 Q(S,A)—>如上面公式
- 在状态 S‘ 执行动作 A’
- …
- 走到终点
c.完成 Q 表格
该方法是一个异策略方法,因为这一步更新 Q(S,A) 的那个 max(Q(S’,a)),所以在 S’ 状态下走的是 A‘ 这个动作而不是 a 这个动作
DQN
但是在普通的Q-learning中,当状态和动作空间是离散且维数不高时可使用Q-Table储存每个状态动作对的Q值,而当状态和动作空间是高维连续时,使用Q-Table不动作空间和状态太大十分困难。
所以在此处可以把Q-table更新转化为一函数拟合(深度学习)问题,通过拟合一个函数function来代替Q-table产生Q值,使得相近的状态得到相近的输出动作。
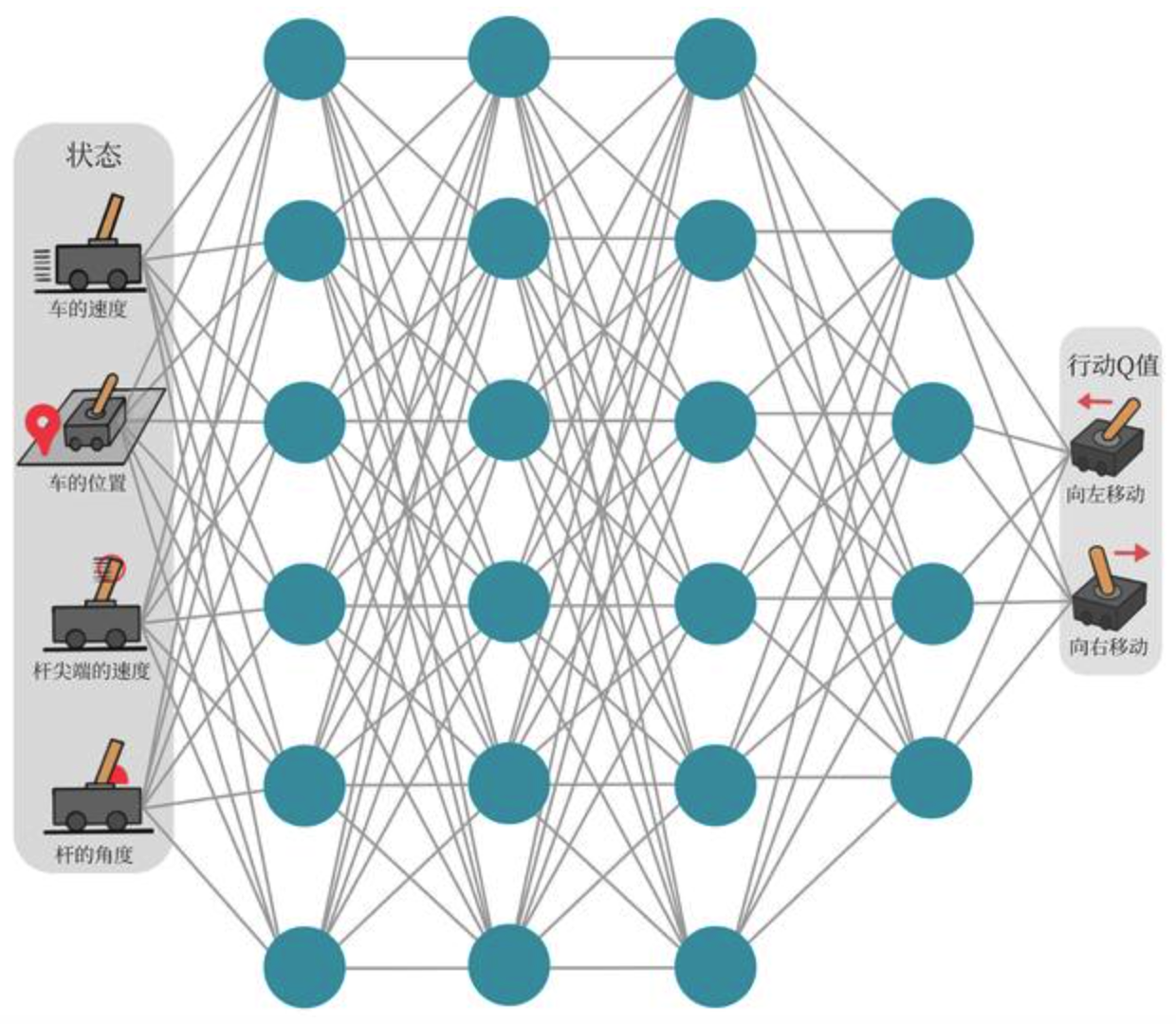
1.DQN 损失函数
Q-learning 的更新规则为:
Q ( S t , A t ) ← Q ( S t , A t ) + α [ R t + 1 + γ max a Q ( S t + 1 , a ) − Q ( S t , A t ) ] Q(S_{t}, A_{t}) \gets Q(S_{t}, A_{t}) + \alpha \left[ R_{t+1} + \gamma \max_{a} Q(S_{t+1}, a) - Q(S_{t}, A_{t}) \right] Q(St,At)←Q(St,At)+α[Rt+1+γamaxQ(St+1,a)−Q(St,At)]
对于上面式子来说,α 中的公式越小也就说明这一组数据的 Q(s,a) 非常接近,网络学习的越稳定,那么也就是当 [ R t + 1 + γ max a Q ( S t + 1 , a ) − Q ( S t , A t ) ] \left[ R_{t+1} + \gamma \max_{a} Q(S_{t+1}, a) - Q(S_{t}, A_{t}) \right] [Rt+1+γmaxaQ(St+1,a)−Q(St,At)] 该公式的值越小越好,那么就可以很自然的得到损失函数:
ω ∗ = arg min ω 1 2 N ∑ i = 1 N [ Q ω ( s i , a i ) − ( r i + γ max a ′ Q ω ( s i ′ , a ′ ) ) ] 2 \omega^* = \mathop{\arg\min}\limits_{\omega} \frac{1}{2N} \sum_{i=1}^N \left[ Q_\omega(s_i, a_i) - \left( r_i + \gamma \max_{a'} Q_\omega(s_i', a') \right) \right]^2 ω∗=ωargmin2N1i=1∑N[Qω(si,ai)−(ri+γa′maxQω(si′,a′))]2
2.经验回放
在 Q-learning 当中一条轨迹包含多个状态和多个动作如:
第一条轨迹: ( s 1 1 , a 1 1 , r 1 1 , s 2 1 ) − − − > ( s 2 1 , a 2 1 , r 2 1 , s 2 1 ) − − − > ( s 3 1 , a 3 1 , r 3 1 , s 4 1 ) (s_{1}^{1},a_{1}^{1},r_{1}^{1},s_{2}^{1})--->(s_{2}^{1},a_{2}^{1},r_{2}^{1},s_{2}^{1})--->(s_{3}^{1},a_{3}^{1},r_{3}^{1},s_{4}^{1}) (s11,a11,r11,s21)−−−>(s21,a21,r21,s21)−−−>(s31,a31,r31,s41)
第二条轨迹: ( s 1 2 , a 3 2 , r 1 2 , s 2 2 ) − − − > ( s 2 2 , a 1 2 , r 2 2 , s 2 2 ) − − − > ( s 3 2 , a 1 2 , r 3 2 , s 4 2 ) (s_{1}^{2},a_{3}^{2},r_{1}^{2},s_{2}^{2})--->(s_{2}^{2},a_{1}^{2},r_{2}^{2},s_{2}^{2})--->(s_{3}^{2},a_{1}^{2},r_{3}^{2},s_{4}^{2}) (s12,a32,r12,s22)−−−>(s22,a12,r22,s22)−−−>(s32,a12,r32,s42)
…
在 Q-learning 更新 Q 表格时会将整条轨迹一起进行计算为了更好的贴合深度学习进行训练,DQN 算法采用了经验回放(experience replay)方法,具体做法为维护一个回放缓冲区,将每次从环境中采样得到的四元组数据(状态、动作、奖励、下一状态)存储到回放缓冲区中
在训练时就可以将每一个元祖进行单独训练,从而提高样本使用效率
3.目标网络
从损失函数中可以看到我们的目标是训练一个网络让前后两个 Q 差值越来越小
ω ∗ = arg min ω 1 2 N ∑ i = 1 N [ Q ω ( s i , a i ) − ( r i + γ max a ′ Q ω ( s i ′ , a ′ ) ) ] 2 \omega^* = \mathop{\arg\min}\limits_{\omega} \frac{1}{2N} \sum_{i=1}^N \left[ Q_\omega(s_i, a_i) - \left( r_i + \gamma \max_{a'} Q_\omega(s_i', a') \right) \right]^2 ω∗=ωargmin2N1i=1∑N[Qω(si,ai)−(ri+γa′maxQω(si′,a′))]2
但是每当 w 的权重更新,两个 Q 公式中的值都会更新,这就会造成网络的不稳定为了解决这一问题,DQN 便使用了目标网络(target network)的思想:既然训练过程中 Q 网络的不断更新会导致目标不断发生改变,不如暂时先将 TD 目标中的 Q 网络固定住。
L ( ω ) = 1 2 [ Q ω ( s , a ) − ( r + γ max a ′ Q ω − ( s ′ , a ′ ) ) ] 2 \mathcal{L}(\omega) = \frac{1}{2} \left[ Q_\omega(s, a) - \left( r + \gamma \max_{a'} Q_{\color{red}{\omega^-}}(s', a') \right) \right]^2 L(ω)=21[Qω(s,a)−(r+γa′maxQω−(s′,a′))]2
训练网络 Q ω ( s , a ) Q_\omega(s, a) Qω(s,a) 在训练中的每一步都会更新,而目标网络的参数每隔 C C C 步才会与训练网络同步一次,即 ω − ← ω \omega^- \leftarrow \omega ω−←ω。这样做使得目标网络相对于训练网络更加稳定。

DQN 的优化
Double DQN
计算目标 Q 的公式如下:
r + γ max a ′ Q ω − ( s ′ , a ′ ) r+\gamma \max _{a^{\prime}} Q_{\omega^{-}}\left(s^{\prime}, a^{\prime}\right) r+γa′maxQω−(s′,a′)
计算出来的结果主要受两个因素的影响,
(1)在 s’ 状态下选择的最优动作 a ∗ = arg max a ′ Q ω − ( s ′ , a ′ ) a^{*}=\arg \max _{a^{\prime}} Q_{\omega^{-}}\left(s^{\prime}, a^{\prime}\right) a∗=argmaxa′Qω−(s′,a′)
(2)该动作对应的价值 Q ,如果由于网络在计算时产生误差,导致某个 a’ 下的 Q(s’,a’) 过大,则会导致更新当前 Q(s,a) 时的 Q 过大,而该 Q 还会进行下一个 state 的计算,最终的结果导致累计误差越来越大,Q 网络也被过高估计
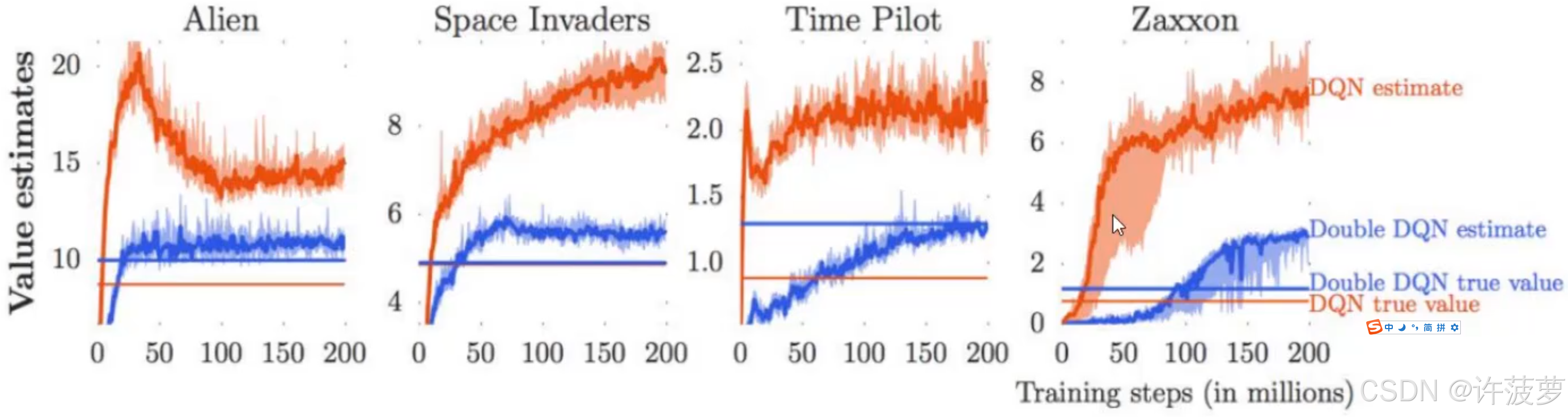
如上图所示,橙色的线为 DQN 的结果,横着的线为真实结果,上面的线为预测结果,很明显预测结果偏高
为了解决这一问题,需要一个单独的网络学习选择网络为 a max a ′ Q ∗ ( s ′ , a ′ ) \max _{a^{\prime}} Q_{*}\left(s^{\prime}, a^{\prime}\right) maxa′Q∗(s′,a′),那么最终的网络为两个
Q ω − ( s ′ , arg max a ′ Q ω ( s ′ , a ′ ) ) Q_{\omega^{-}}\left(s^{\prime}, \arg \max _{a^{\prime}} Q_{\omega}\left(s^{\prime}, a^{\prime}\right)\right) Qω−(s′,arga′maxQω(s′,a′))
即利用一套神经网络 Q ω Q_{\omega^{}} Qω的输出选取价值最大的动作,但在使用该动作的价值时,用另一套神经网络 Q ω − Q_{\omega^{-}} Qω−计算该动作的价值,让 Q 计算的更稳定一些
举例 DQN 被高估的场景:



Dueling DQN
Dueling DQN 是深度Q网络(DQN)的一种改进版本,它通过引入优势函数(Advantage Function)和价值函数(Value Function)来更有效地学习Q值。
两个函数的含义:

所以:
A θ ( s , a ) = Q θ ( s , a ) − V θ ( s ) A_{\theta}(s, a)=Q_{\theta}(s, a)-V_{\theta}(s) Aθ(s,a)=Qθ(s,a)−Vθ(s)
在某个状态下得到的价值 - 在这个状态下价值的期望 = 这个 action 的优势

举个例子:


如何当 Dueling DQN 更稳定:

参考文档
动手学强化学习
bilibili: 零基础学习强化学习 ppo
李宏毅强化学习