自然语言处理——语言转换
一、自然语言处理概念
自然语言处理(NLP)是计算机科学、人工智能和语言学的交叉领域,主要研究如何使计算机能够理解和处理人类语言。
二、模型介绍
在进行语言转换时我们要用到2种语言模型:
2.1统计语言模型:
是自然语言处理中的一个重要概念,它基于统计方法来对语言进行建模,用于计算一个句子或一段文本出现的概率,统计语言模型旨在通过对大量文本数据的统计分析,学习语言的结构和规律,从而预测一个句子或词语序列在给定语言中的合理性或出现概率。
问题:
(1)、由于参数空间的爆炸式增长,它无法处理(N>3)的数据。
(2)、没有考虑词与词之间内在的联系性。例如,考虑"the cat is walking in the bedroom"这句话。如果我们在训练语料中看到了很多类似“the dog is walking in the bedroom”或是“the cat is running in the bedroom”这样的句子;那么,哪怕我们此前没有见过这句话"the cat is walking in the bedroom",也可以从“cat”和“dog”(“walking”和“running”)之间的相似性,推测出这句话的概率。
2.2神经语言模型
神经语言模型(Neural Language Model,简称 NLM)是一种基于神经网络的语言模型,旨在克服传统统计语言模型的一些局限性,能够更好地处理自然语言中的复杂语义和句法关系。
词嵌入embedding
one-hot 编码
在处理自然语言时,通常将词语或者字做向量化,例如one-hot编码,例如我们有一句话为:“我爱北京天安门”,我们分词后对其进行one-hot编码,结果可以是:

问题
如果需要对语料库中的每个字进行one-hot编码如何实现?
1、统计语料库中所有的词的个数,例如4960个词。
2、按顺序依次给每个词进行one-hot编码,例如第1个词为:[0,0,0,0,0,0,0,….,1],最后1个词为: [1,0,0,0,0,0,0,….,0]
矩阵为非常稀疏,出现维度灾难。例如有一句话为“我爱北京天安门”,传入神经网络输入层的数据为:

如何解决维度灾难问题 ?
通过神经网络训练,将每个词都映射到一个较短的词向量上来。
例如有一句话为“我爱北京天安门”,通过神经网络训练后的数据为:

word2vec
CBOW
以上下文词汇预测当前词,即𝜔𝑡−2、𝜔𝑡−1、 𝜔𝑡+1、𝜔𝑡+2
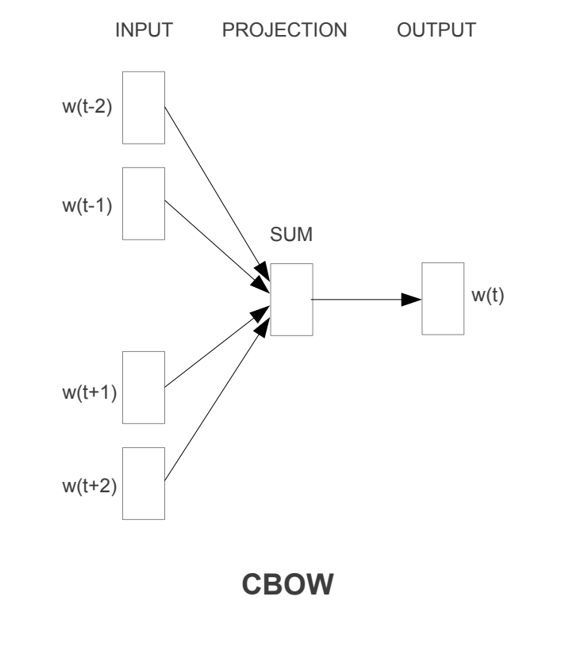

当语料库中句子足够多时,可以将每个词的特征学习下来。
我 命 ____ 我 不 -> 输入 我命 我不 结果 由
SkipGram
以当前词预测其上下文词汇,即用预测𝜔𝑡−2、𝜔𝑡−1、 𝜔𝑡+1、𝜔𝑡+2
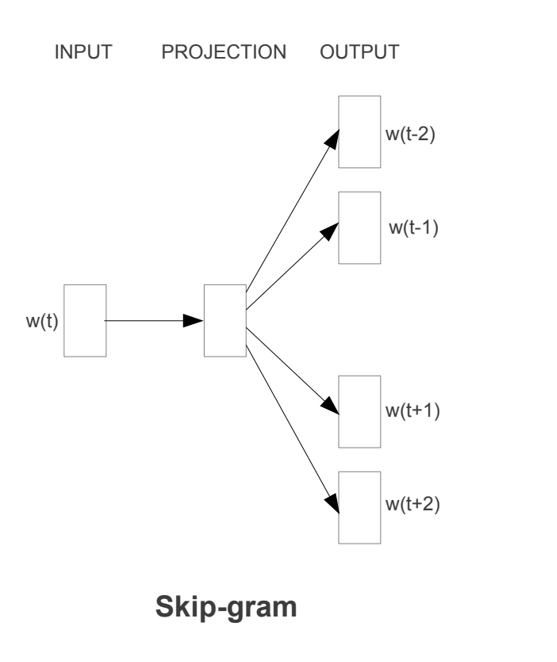
模型的训练过程:
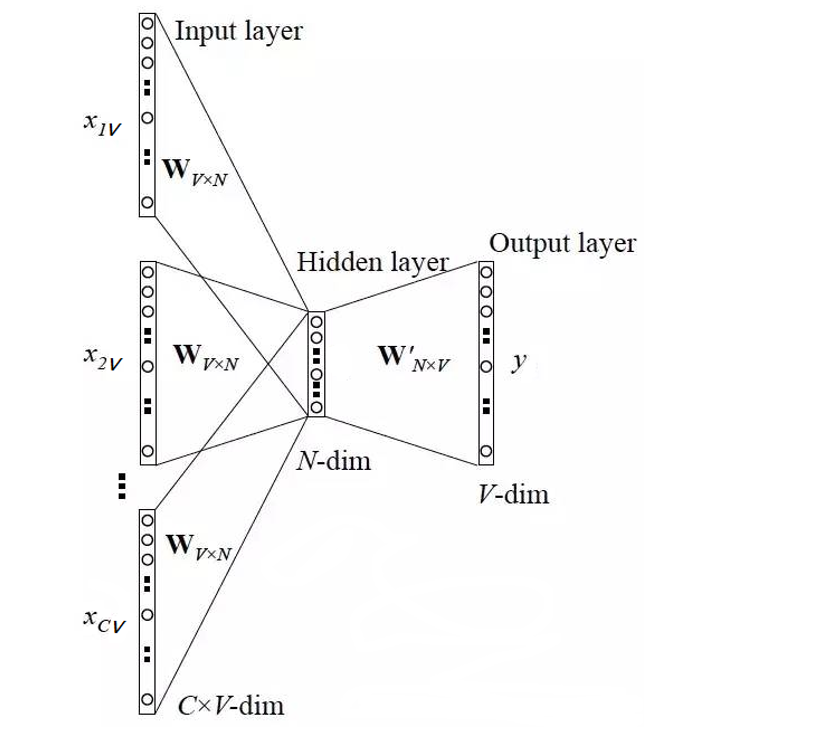
1、当前词的上下文词语的one-hot编码输入到输入层。
2、这些词分别乘以同一个矩阵WV*N后分别得到各自的1*N 向量。
3、将多个这些1*N 向量取平均为一个1*N 向量。
4、将这个1*N 向量乘矩阵 W’V*N ,变成一个1*V 向量。
5、将1*V 向量softmax归一化后输出取每个词的概率向量1*V
6、将概率值最大的数对应的词作为预测词。
7、将预测的结果1*V 向量和真实标签1*V 向量(真实标签中的V个值中有一个是1,其他是0)计算误差
8、在每次前向传播之后反向传播误差,不断调整 WV*N和 W’V*N矩阵的值。
假定语料库中一共有4960个词,则词编码为4960个01组合现在压缩为300维

三、总结与展望
自然语言处理中的语言转换技术在过去几十年取得了显著进展,从早期基于规则和统计的方法,发展到如今基于深度学习的强大模型,为人们的生活和工作带来了极大的便利。然而,这些技术仍然面临诸多挑战,如提高语音识别的准确率、改善机器翻译的质量、实现更自然的文本风格转换等。未来,随着深度学习技术的不断发展,以及与其他领域如知识图谱、强化学习的融合,语言转换技术有望取得更大突破。通过将知识图谱融入机器翻译模型,可以更好地处理语义歧义,提高翻译的准确性;利用强化学习让语音合成模型根据用户反馈不断优化生成的语音,使其更加自然流畅。相信在不久的将来,自然语言处理中的语言转换技术将在更多领域得到应用,进一步推动人工智能技术的发展和人类社会的进步。